Kyuubi Gateway通過提供JDBC/ODBC介面,支援SQL查詢和BI工具(如Tableau、Power BI)無縫串連Serverless Spark,實現高效的資料訪問與分析。同時,其多租戶資源隔離能力能夠滿足企業級應用的需求。
建立Kyuubi Gateway
-
進入Gateway頁面。
-
在左側導覽列,選擇EMR Serverless > Spark。
-
在Spark頁面,單擊目標工作空間名稱。
-
在EMR Serverless Spark頁面,單擊左側導覽列中的。
-
在Kyuubi Gateway頁面,單擊建立Kyuubi Gateway。
-
在建立Kyuubi Gateway頁面,配置以下資訊,單擊创建。
參數
說明
名称
建立Gateway的名稱。僅支援小寫字母、數字、短劃線(-),並且開頭和結尾必須是字母或者數字。
Kyuubi Gateway 资源
預設
2 CPU, 8 GB。支援的規格及其推薦並發上限如下:
-
1 CPU, 4 GB:10 -
2 CPU, 8 GB:20 -
4 CPU, 16 GB:30 -
8 CPU, 32 GB:45 -
16 CPU, 64 GB:85 -
32 CPU, 128 GB:135
說明如果Spark配置項數量過多,將導致Spark任務的瞬時提交並發度下降。
Kyuubi 版本
當前Gateway使用的Kyuubi版本。
說明如果数据目录中使用DLF(之前稱為DLF 2.5),則Kyuubi 版本必須選擇為1.9.2-0.0.1及之後的版本。
引擎版本
當前Gateway使用的引擎版本。引擎版本號碼含義等詳情請參見引擎版本介紹。
关联队列
建立的Gateway將部署在所選隊列。通過Gateway提交Spark任務時,將使用Gateway建立者的身份提交任務。
认证方式
僅支援Token方式。
在您建立Gateway之後,需要為其產生一個唯一的鑒權Token,以便在之後的請求中使用該Token進行身分識別驗證和存取控制。建立Token的具體操作,請參見Gateway管理。
服务高可用
開啟服務高可用後,將部署3台或以上Kyuubi Server以達到高可用。
開啟該開關後,還需配置以下參數:
-
Kyuubi Server 部署数量:Kyuubi伺服器數量。
-
Zookeeper 集群地址:高可用Kyuubi Gateway依賴於Zookeeper叢集,請填寫Zookeeper叢集地址,多個節點請以英文逗號(,)分隔,並確保網路互連。例如,
zk1:2181,zk2:2181,zk3:2181。
网络连接
選擇已建立的網路連接,以便直接存取VPC內的資料來源或外部服務。有關建立網路連接的具體操作,請參見EMR Serverless Spark與其他VPC間網路互連。
公网 Endpoint
預設關閉。開啟該功能後,則系統將通過公網Endpoint訪問Kyuubi。否則預設通過內網Endpoint訪問Kyuubi。
Kyuubi 配置
填寫Kyuubi配置資訊,預設以空格符分隔,例如:
kyuubi.engine.pool.size 1。僅支援以下Kyuubi配置。
kyuubi.engine.pool.size kyuubi.engine.pool.size.threshold kyuubi.engine.share.level kyuubi.engine.single.spark.session kyuubi.session.engine.idle.timeout kyuubi.session.engine.initialize.timeout kyuubi.engine.security.token.max.lifetime kyuubi.session.engine.check.interval kyuubi.session.idle.timeout kyuubi.session.engine.request.timeout kyuubi.session.engine.login.timeout kyuubi.backend.engine.exec.pool.shutdown.timeout kyuubi.backend.server.exec.pool.shutdown.timeout kyuubi.backend.server.exec.pool.keepalive.time kyuubi.frontend.thrift.login.timeout kyuubi.operation.status.polling.timeout kyuubi.engine.pool.selectPolicy kyuubi.authentication kyuubi.kinit.principal kyuubi.kinit.keytab kyuubi.authentication.ldap.* kyuubi.hadoop.proxyuser.hive.hosts kyuubi.hadoop.proxyuser.hive.groups kyuubi.hadoop.proxyuser.kyuubi.hosts kyuubi.hadoop.proxyuser.kyuubi.groups kyuubi.ha.*Spark 配置
填寫Spark配置資訊,預設以空格符分隔。除
spark.kubernetes.*類型的參數外,其他參數均支援。例如:spark.sql.catalog.paimon.metastore dlf。 -
-
在Kyuubi Gateway頁面,單擊已建立Kyuubi Gateway操作列的启动。
管理Token
-
在Kyuubi Gateway頁面,單擊目標Gateway操作列的Token 管理。
-
單擊创建 Token。
-
在创建 Token對話方塊中,配置以下資訊,單擊确定。
參數
說明
名称
建立Token的名稱。
过期时间
設定該Token的到期時間。設定的天數應大於或等於1。預設情況下為開啟狀態,365天后到期。
指派至
在下拉框中,選擇您在访问控制中添加的RAM使用者或者RAM角色。
指定分配Token的RAM使用者或RAM角色,用於在串連Kyuubi Gateway提交Spark任務時訪問DLF。
-
複製Token資訊。
重要Token建立完成後,請務必立即複製新Token的資訊,後續不支援查看。如果您的Token到期或遺失,請選擇建立Token或重設Token。
串連Kyuubi Gateway
在串連Kyuubi Gateway時,請根據您的實際情況替換JDBC URL中的資訊:
-
<endpoint>:您在总览頁簽擷取的Endpoint資訊。 -
<port>:連接埠號碼。使用外網網域名稱訪問時連接埠號碼為443,使用內網網域名稱訪問時連接埠號碼為80。 -
<token>:您在Token 管理頁簽複製的Token資訊。 -
<tokenname>:Token名稱。您可以在Token 管理頁簽擷取。 -
<UserName/RoleName>:您在访问控制中添加的RAM使用者或RAM角色。
使用Beeline串連
在串連Kyuubi Gateway時,請確保您使用的Beeline版本與Kyuubi服務端版本相容。如果您未安裝Beeline,詳情請參見Getting Started - Apache Kyuubi。
請根據数据目录頁面Catalog的預設使用方式,選擇以下對應的操作方式。
使用DLF(之前稱為DLF 2.5)
beeline -u "jdbc:hive2://<endpoint>:<port>/;transportMode=http;user=<UserName/RoleName>;httpPath=cliservice/token/<token>"使用其他Catalog
beeline -u "jdbc:hive2://<endpoint>:<port>/;transportMode=http;httpPath=cliservice/token/<token>"使用Beeline串連時支援修改會話參數,例如beeline -u "jdbc:hive2://<endpoint>:<port>/;transportMode=http;httpPath=cliservice/token/<token>;#spark.sql.shuffle.partitions=100;spark.executor.instances=2;"。
使用Java串連
-
更新pom.xml。
使用適當版本的依賴項以替換
hadoop-common和hive-jdbc。<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.3.9</version> </dependency> </dependencies> -
編寫Java代碼,串連Kyuubi Gateway。
請根據数据目录頁面Catalog的預設使用方式,選擇以下對應的操作方式。
使用DLF(之前稱為DLF 2.5)
import org.apache.hive.jdbc.HiveStatement; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; public class Main { public static void main(String[] args) throws Exception { String url = "jdbc:hive2://<endpoint>:<port>/;transportMode=http;httpPath=cliservice/token/<token>;user=<UserName/RoleName>"; Class.forName("org.apache.hive.jdbc.HiveDriver"); Connection conn = DriverManager.getConnection(url); HiveStatement stmt = (HiveStatement) conn.createStatement(); String sql = "select * from students;"; System.out.println("Running " + sql); ResultSet res = stmt.executeQuery(sql); ResultSetMetaData md = res.getMetaData(); String[] columns = new String[md.getColumnCount()]; for (int i = 0; i < columns.length; i++) { columns[i] = md.getColumnName(i + 1); } while (res.next()) { System.out.print("Row " + res.getRow() + "=["); for (int i = 0; i < columns.length; i++) { if (i != 0) { System.out.print(", "); } System.out.print(columns[i] + "='" + res.getObject(i + 1) + "'"); } System.out.println(")]"); } conn.close(); } }使用其他Catalog
import org.apache.hive.jdbc.HiveStatement; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; public class Main { public static void main(String[] args) throws Exception { String url = "jdbc:hive2://<endpoint>:<port>/;transportMode=http;httpPath=cliservice/token/<token>"; Class.forName("org.apache.hive.jdbc.HiveDriver"); Connection conn = DriverManager.getConnection(url); HiveStatement stmt = (HiveStatement) conn.createStatement(); String sql = "select * from students;"; System.out.println("Running " + sql); ResultSet res = stmt.executeQuery(sql); ResultSetMetaData md = res.getMetaData(); String[] columns = new String[md.getColumnCount()]; for (int i = 0; i < columns.length; i++) { columns[i] = md.getColumnName(i + 1); } while (res.next()) { System.out.print("Row " + res.getRow() + "=["); for (int i = 0; i < columns.length; i++) { if (i != 0) { System.out.print(", "); } System.out.print(columns[i] + "='" + res.getObject(i + 1) + "'"); } System.out.println(")]"); } conn.close(); } }
使用Python串連
-
執行以下命令,安裝PyHive和Thrift包。
pip3 install pyhive thrift -
編寫Python指令碼,串連Kyuubi Gateway。
以下是一個Python指令碼樣本,展示如何串連到Kyuubi Gateway並顯示資料庫列表。
請根據数据目录頁面Catalog的預設使用方式,選擇以下對應的操作方式。
使用DLF(之前稱為DLF 2.5)
from pyhive import hive if __name__ == '__main__': cursor = hive.connect('<endpoint>', port="<port>", scheme='http', username='<UserName/RoleName>', password='<token>').cursor() cursor.execute('show databases') print(cursor.fetchall()) cursor.close()使用其他Catalog
from pyhive import hive if __name__ == '__main__': cursor = hive.connect('<endpoint>', port="<port>", scheme='http', username='<tokenname>', password='<token>').cursor() cursor.execute('show databases') print(cursor.fetchall()) cursor.close()
使用REST API串連
Kyuubi Gateway提供了開源相容的REST API,支援通過HTTP協議與Kyuubi服務進行互動。目前僅支援以下API路徑:
-
/api/v1/sessions/* -
/api/v1/operations/* -
/api/v1/batches/*
本文通過以下樣本為您介紹如何使用REST API串連Kyuubi Gateway。
-
樣本1:啟動Session並進行SQL查詢。
-
建立Session並指定Spark配置。
請根據数据目录頁面Catalog的預設使用方式,選擇以下對應的操作方式。
說明-
spark.emr.serverless.kyuubi.engine.queue用於指定Spark任務運行時所使用的隊列。請根據實際情況替換<dev_queue>為具體的隊列名。 -
<UserName/Rolename>:替換為實際的使用者名稱或角色名稱。 -
<password>:僅作為預留位置,可填寫任意值。
使用DLF(之前稱為DLF 2.5)
curl -X 'POST' \ 'http://<endpoint>:<port>/api/v1/sessions/token/<token>' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -u '<UserName/Rolename>:<password>' \ -d '{ "configs": { "set:hivevar:spark.emr.serverless.kyuubi.engine.queue": "<dev_queue>" } }'使用其他Catalog
curl -X 'POST' \ 'http://<endpoint>:<port>/api/v1/sessions/token/<token>' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "configs": { "set:hivevar:spark.emr.serverless.kyuubi.engine.queue": "<dev_queue>" } }'返回如下類似資訊。其中,
identifier表示Kyuubi的Session Handle,用於唯一標識一個會話。本文中將以<sessionHandle>指代該值。{"identifier":"619e6ded-xxxx-xxxx-xxxx-c2a43f6fac46","kyuubiInstance":"0.0.0.0:10099"} -
-
建立Statement。
使用DLF(之前稱為DLF 2.5)
curl -X 'POST' \ 'http://<endpoint>:<port>/api/v1/sessions/<sessionHandle>/operations/statement/token/<token>' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -u '<UserName/RoleName>:<password>' \ -d '{ "statement": "select * from test;", "runAsync": true, "queryTimeout": 0, "confOverlay": { "additionalProp1": "string", "additionalProp2": "string" } }'使用其他Catalog
curl -X 'POST' \ 'http://<endpoint>:<port>/api/v1/sessions/<sessionHandle>/operations/statement/token/<token>' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "statement": "select * from test;", "runAsync": true, "queryTimeout": 0, "confOverlay": { "additionalProp1": "string", "additionalProp2": "string" } }'返回如下類似資訊。這裡的
identifier表示Kyuubi的Operation Handle,用於唯一標識一個具體的操作。本文中將以<operationHandle>指代該值。{"identifier":"a743e8ff-xxxx-xxxx-xxxx-a66fec66cfa4"} -
擷取Statement狀態。
使用DLF(之前稱為DLF 2.5)
curl --location -X 'GET' \ 'http://<endpoint>:<port>/api/v1/operations/<operationHandle>/event/token/<token>' \ -H 'accept: application/json' \ -u '<UserName/RoleName>:<password>'使用其他Catalog
curl --location -X 'GET' \ 'http://<endpoint>:<port>/api/v1/operations/<operationHandle>/event/token/<token>' \ -H 'accept: application/json' -
擷取Statement結果。
使用DLF(之前稱為DLF 2.5)
curl --location -X 'GET' \ 'http://<endpoint>:<port>/api/v1/operations/<operationHandle>/rowset/token/<token>/?maxrows=100&fetchorientation=FETCH_NEXT' \ -H 'accept: application/json' \ -u '<UserName/RoleName>:<password>'使用其他Catalog
curl --location -X 'GET' \ 'http://<endpoint>:<port>/api/v1/operations/<operationHandle>/rowset/token/<token>/?maxrows=100&fetchorientation=FETCH_NEXT' \ -H 'accept: application/json'
-
-
樣本2:使用batches介面提交批作業。
通過REST API提交一個Spark批處理任務到Kyuubi Gateway。Kyuubi Gateway會根據請求中的參數啟動一個Spark應用程式,並執行指定的任務。
在本樣本中,除過替換
<endpoint>、<port>、<token>等資訊外,還需單擊spark-examples_2.12-3.3.1.jar,直接下載測試JAR包。說明該JAR包是Spark內建的一個簡單樣本,用於計算圓周率π的值。
使用DLF(之前稱為DLF 2.5)
curl --location \ --request POST 'http://<endpoint>:<port>/api/v1/batches/token/<token>' \ --user '<UserName/RoleName>:<password>' \ --form 'batchRequest="{ \"batchType\": \"SPARK\", \"className\": \"org.apache.spark.examples.SparkPi\", \"name\": \"kyuubi-spark-pi\", \"resource\": \"oss://bucket/path/to/spark-examples_2.12-3.3.1.jar\" }";type=application/json'使用其他Catalog
curl --location \ --request POST 'http://<endpoint>:<port>/api/v1/batches/token/<token>' \ --form 'batchRequest="{ \"batchType\": \"SPARK\", \"className\": \"org.apache.spark.examples.SparkPi\", \"name\": \"kyuubi-spark-pi\", \"resource\": \"oss://bucket/path/to/spark-examples_2.12-3.3.1.jar\" }";type=application/json'
使用Apache Superset串連
Apache Superset是一個現代資料探索和可視化平台,具有豐富的圖表形態。更多Superset資訊,請參見Superset。
使用Superset串連Kyuubi Gateway前,請確保已安裝0.20.0及以上版本的thrift包。如未安裝,可執行以下命令安裝:
pip install thrift==0.20.0-
啟動Superset,進入Superset介面。更多啟動操作資訊,請參見Superset文檔。
-
在頁面右上方單擊DATABASE,進入Connect a database頁面。
-
在Connect a database頁面,選擇Apache Spark SQL。
-
在SQLAlchemy URI欄位,根據訪問方式填寫對應的串連串。
公網訪問
hive+https://<username>:<token>@<endpoint>:443/<db_name>VPC內網訪問
hive+http://<username>:<token>@<endpoint>:80/<db_name>參數說明如下:
參數
說明
username
使用者名稱,可填寫任意值。
Token
訪問Token。
Endpoint
Kyuubi Gateway的訪問端點,需要區分公網endpoint與內網endpoint。
db_name
資料庫名稱。
-
單擊Connect完成串連配置。
使用HUE串連
使用HUE串連Kyuubi Gateway前,請確保已安裝thrift 0.20.0版本。如未安裝,可執行以下命令安裝:
pip install thrift==0.20.0-
編輯Hue設定檔
/etc/hue/hue.conf,根據您的訪問方式添加以下配置。公網訪問
[[[sparksql]]] name = Spark Sql interface=sqlalchemy options='{"url": "hive+https://<username>:<token>@<endpoint>:443/"}'VPC內網訪問
[[[sparksql]]] name = Spark Sql interface=sqlalchemy options='{"url": "hive+http://<username>:<token>@<endpoint>:80/"}'參數說明如下:
參數
說明
username
使用者名稱,可填寫任意值。
Token
訪問Token。
Endpoint
Kyuubi Gateway的訪問端點。
-
重啟Hue服務。
sudo service hue restart -
登入Hue Web UI,在左側導覽列選擇Query > Editor > SparkSql,驗證串連是否成功。
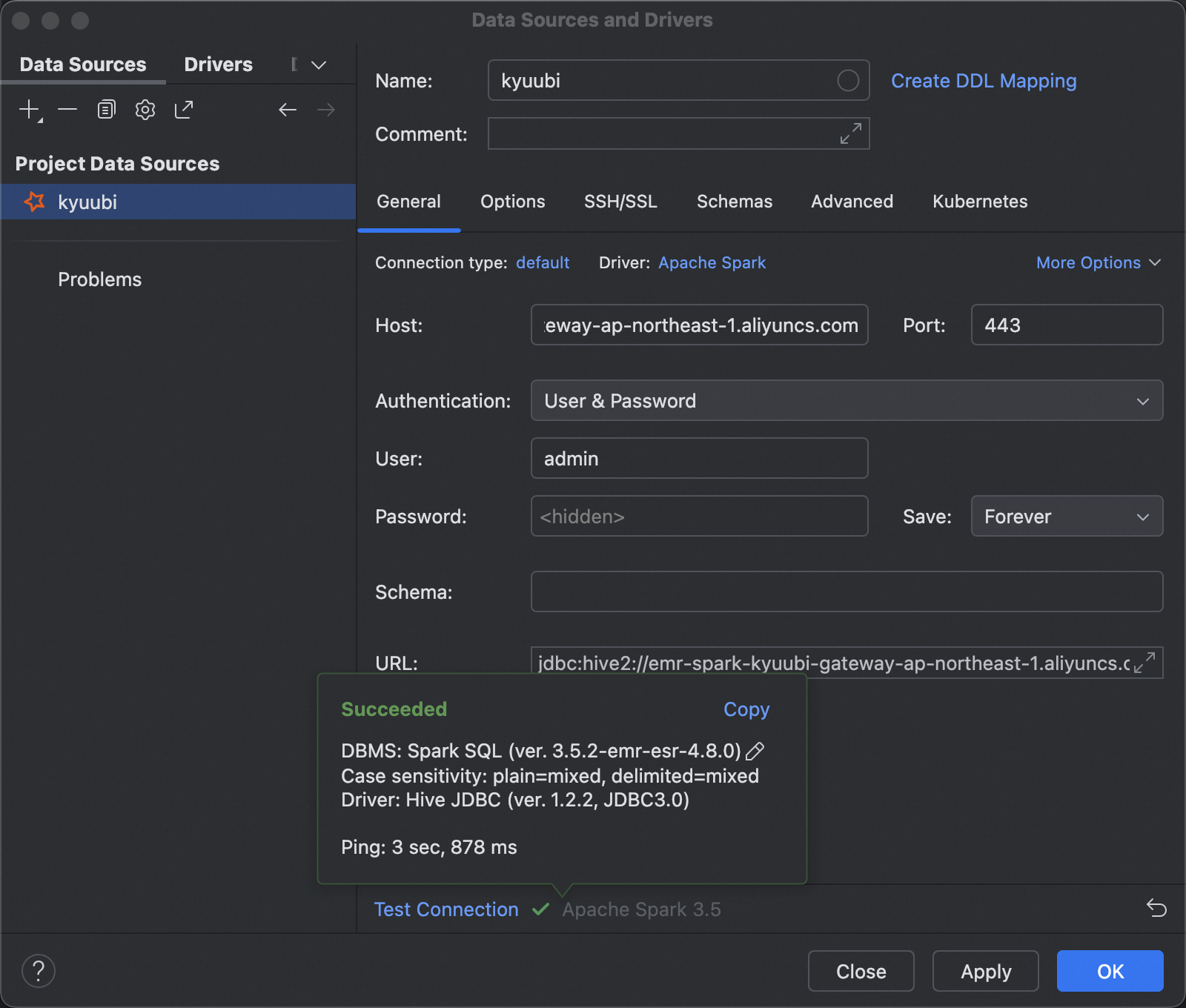
使用DataGrip串連
使用DataGrip串連Kyuubi Gateway前,請確保已下載Apache Spark JDBC Driver(ver. 1.2.2,用於Spark 3.x相容)。
-
開啟DataGrip,建立新專案。
-
在右側Database Explorer面板中,單擊+ > Data Source > Other > Apache Spark。
-
在Data Sources and Drivers對話方塊中,配置以下參數。
參數
說明
Name
自訂串連名稱。
Authentication
選擇No auth或User & Password(使用者名稱可任意填寫)。
Driver
選擇Apache Spark ver. 1.2.2。
URL
公網訪問
jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>VPC內網訪問
jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>其中,
<endpoint>為Kyuubi Gateway的訪問端點,<token>為訪問Token。 -
單擊Test Connection驗證串連。
-
單擊OK儲存配置。
配置並串連高可用Kyuubi Gateway
-
打通網路連接。
參見EMR Serverless Spark與其他VPC間網路互連打通網路連接,確保您的用戶端能夠訪問目標VPC內的Zookeeper叢集。例如,阿里雲MSE或EMR on ECS的Zookeeper組件。
-
啟用Kyuubi Gateway的高可用。
在建立或者編輯Kyuubi Gateway時,開啟了服务高可用並配置了相關參數,並且网络连接選擇了已打通的網路連接。
-
串連高可用Kyuubi Gateway。
完成上述配置後,Kyuubi Gateway將通過Zookeeper實現高可用。您可以通過REST API或JDBC串連來驗證其可用性。
在串連Kyuubi Gateway時,請根據您的實際情況替換JDBC URL中的資訊:
-
<endpoint>:您在总览頁簽擷取的Endpoint資訊。 -
<port>:連接埠號碼。使用外網網域名稱訪問時連接埠號碼為443,使用內網網域名稱訪問時連接埠號碼為80。 -
<token>:您在Token 管理頁簽複製的Token資訊。 -
<tokenname>:Token名稱。您可以在Token 管理頁簽擷取。 -
<UserName/RoleName>:您在访问控制中添加的RAM使用者或RAM角色。
通過以下樣本為您介紹如何串連高可用Kyuubi Gateway。
使用Beeline串連
-
單擊kyuubi-hive-jdbc-1.9.2.jar,下載JDBC Driver JAR。
-
替換JDBC Driver JAR。
-
備份並移動原有的JDBC Driver JAR包。
mv /your_path/apache-kyuubi-1.9.2-bin/beeline-jars /bak_path說明如果您使用的是EMR on ECS,則Kyuubi的預設路徑為
/opt/apps/KYUUBI/kyuubi-1.9.2-1.0.0/beeline-jars。如果不確定Kyuubi的安裝路徑,可以通過env | grep KYUUBI_HOME命令尋找。 -
替換為新的JDBC Driver JAR包。
cp /download/serverless-spark-kyuubi-hive-jdbc-1.9.2.jar /your_path/apache-kyuubi-1.9.2-bin/beeline-jars
-
-
使用Beeline串連。
/your_path/apache-kyuubi-1.9.2-bin/bin/beeline -u 'jdbc:hive2://<endpoint>:<port>/;transportMode=http;httpPath=cliservice/token/<token>'
使用Java串連
-
單擊serverless-spark-kyuubi-hive-jdbc-shaded-1.9.2.jar,下載shaded包。
-
安裝JDBC Driver到Maven倉庫。
執行以下命令,將Serverless Spark提供的JDBC Driver安裝到本地Maven倉庫。
mvn install:install-file \ -Dfile=/download/serverless-spark-kyuubi-hive-jdbc-shaded-1.9.2.jar \ -DgroupId=org.apache.kyuubi \ -DartifactId=kyuubi-hive-jdbc-shaded \ -Dversion=1.9.2-ss \ -Dpackaging=jar -
修改
pom.xml檔案。在專案的
pom.xml中添加以下依賴。<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.kyuubi</groupId> <artifactId>kyuubi-hive-jdbc-shaded</artifactId> <version>1.9.2-ss</version> </dependency> </dependencies> -
編寫Java範例程式碼。
import org.apache.kyuubi.jdbc.hive.KyuubiStatement; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; public class Main { public static void main(String[] args) throws Exception { String url = "jdbc:hive2://<endpoint>:<port>/;transportMode=http;httpPath=cliservice/token/<token>"; Class.forName("org.apache.kyuubi.jdbc.KyuubiHiveDriver"); Connection conn = DriverManager.getConnection(url); KyuubiStatement stmt = (KyuubiStatement) conn.createStatement(); String sql = "select * from test;"; ResultSet res = stmt.executeQuery(sql); ResultSetMetaData md = res.getMetaData(); String[] columns = new String[md.getColumnCount()]; for (int i = 0; i < columns.length; i++) { columns[i] = md.getColumnName(i + 1); } while (res.next()) { System.out.print("Row " + res.getRow() + "=["); for (int i = 0; i < columns.length; i++) { if (i != 0) { System.out.print(", "); } System.out.print(columns[i] + "='" + res.getObject(i + 1) + "'"); } System.out.println(")]"); } conn.close(); } }
-
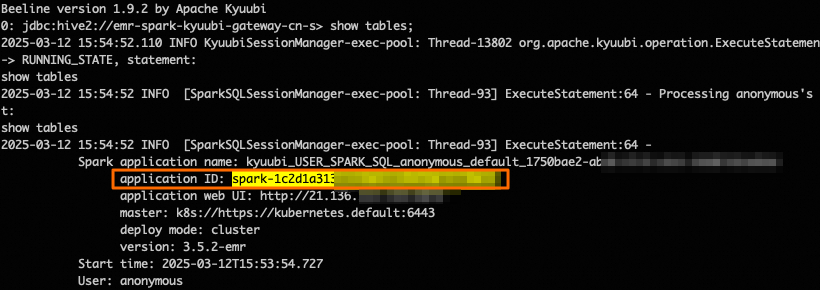
查看Kyuubi提交的Spark工作清單
通過Kyuubi提交的Spark任務,您可以在任务历史功能表列的Kyuubi Application頁簽中查看詳細的任務資訊,包括应用 ID、应用名称、Application 狀態以及启动时间等。這些資訊可以協助您快速瞭解和管理Kyuubi提交的Spark任務。
-
在Kyuubi Gateway頁面,單擊目標Kyuubi Gateway的名稱。
-
單擊右上方Application 列表。

在該頁面,您可以查看通過該Kyuubi提交的所有Spark任務的詳細資料。其中,应用 ID(spark-xxxx)由Spark引擎產生,與Kyuubi用戶端串連時輸出的Application ID完全一致,用於唯一標識任務執行個體。