本文為您介紹如何將同步至MaxCompute的使用者資訊表ods_user_info_d及訪問日誌資料ods_raw_log_d,通過DataWorks的MaxCompute節點加工得到目標使用者畫像資料,閱讀本文後,您可以瞭解如何通過DataWorks+MaxCompute產品組合來計算和分析已同步的資料,完成數倉簡單資料加工情境。
前提條件
開始本案例前,請先完成同步資料中的操作。
一、搭建資料加工鏈路
在同步資料階段,已經成功將資料同步至MaxCompute,本階段需要對資料進行進一步加工,以輸出基本使用者畫像資料。
在Data Studio左側導覽列單擊
 ,進入資料開發頁面,然後在專案目錄地區找到已建立好的工作流程,單擊進入工作流程編排頁。
,進入資料開發頁面,然後在專案目錄地區找到已建立好的工作流程,單擊進入工作流程編排頁。本教程節點名稱樣本及作用如下:
節點類型
節點名稱
節點作用
 MaxCompute SQL
MaxCompute SQLdwd_log_info_di使用內建函數、自訂函數(
getregion)等完成原始日誌ods_raw_log_d資料拆分寫入dwd_log_info_di表多個欄位。MaxCompute SQLdws_user_info_all_di對使用者基本資料表(
ods_user_info_d)和初步加工後的日誌資料表(dwd_log_info_di)進行匯總,將資料寫入dws_user_info_all_di表中。MaxCompute SQLads_user_info_1d對
dws_user_info_all_di表中資料進一步加工,將資料寫入ads_user_info_1d表,產出基本使用者畫像。手動拖拽連線,配置各節點的上遊節點。最終效果如下:

二、註冊自訂函數
為了後續資料處理任務的順利進行,您需要註冊MaxCompute自訂函數(getregion),將同步資料階段同步至MaxCompute的日誌資料結構拆解成表格。
本教程已為您提供用於將IP解析為地區的函數所需資源,您僅需將其下載至本地,並在DataWorks註冊函數前,將函數涉及的資源上傳至DataWorks空間即可。
該函數僅為本教程使用(IP資源範例),若需在正式業務中實現IP到地理位置的映射功能,需前往專業IP網站擷取相關IP轉換服務。
上傳資源(ip2region.jar)
- 說明
ip2region.jar資源範例僅為教程使用。 在Data Studio頁面左側導覽列單擊
 ,進入資源管理頁面,單擊
,進入資源管理頁面,單擊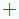 > 建立資源 > MaxCompute Jar,設定資源名稱後,進入資源上傳頁面。說明
> 建立資源 > MaxCompute Jar,設定資源名稱後,進入資源上傳頁面。說明資源名稱無需與上傳的檔案名稱保持一致。
檔案來源選擇本地,單擊檔案內容後的點擊上傳,選擇已下載至本地的
ip2region.jar。資料來源選擇準備環境階段綁定的MaxCompute計算資源。
在節點工具列單擊儲存,然後單擊發布,根據發布面板提示,將資源發布至開發環境和生產環境對應的MaxCompute專案中。
註冊函數(getregion)
在資源管理頁面,單擊
> 建立函數 > MaxCompute Function,設定資源名稱後,進入註冊函數頁面(本教程函數命名為getregion)。在註冊函數頁面,配置相關參數。以下為本教程所需配置的關鍵參數,未說明參數保持預設即可。
參數
描述
函數類型
選擇
OTHER。資料來源
選擇準備環境階段綁定的MaxCompute計算資源。
類名
輸入
org.alidata.odps.udf.Ip2Region。資源清單
選擇
ip2region.jar。描述
IP地址轉換地區。
命令格式
輸入
getregion('ip')。參數說明
IP地址。
在節點工具列單擊的儲存,然後單擊發布,根據發布面板提示,將函數發布至開發環境和生產環境對應的MaxCompute專案中。
三、配置資料加工節點
資料加工需要將每層加工邏輯通過MaxCompute SQL調度實現,本教程已提供完整的資料加工SQL範例程式碼,您需要依次為dwd_log_info_di、dws_user_info_all_di和ads_user_info_1d節點配置。
配置dwd_log_info_di節點
在本節點的範例程式碼中,利用建立的函數處理上遊表ods_raw_log_d欄位的SQL代碼,並將其寫入dwd_log_info_di表中。
在Data Studio左側導覽列單擊
,進入資料開發頁面,然後在專案目錄地區找到已建立好的工作流程,單擊進入工作流程編排頁。在工作流程編排頁面中,滑鼠移至上方至
dwd_log_info_di節點上,單擊開啟節點。將如下代碼粘貼至節點編輯頁面。
配置調試參數。
在MaxCompute SQL節點編輯頁面右側單擊回合組態,配置以下參數,用於在步驟四調試運行中使用回合組態的相關參數測試回合。
配置項
配置說明
計算資源
選擇準備環境階段綁定的MaxCompute計算資源以及其對應的計算配額。
資源群組
選擇準備環境階段購買的Serverless資源群組。
指令碼參數
無需配置。本教程提供的範例程式碼中統一使用
${bizdate}表示業務日期,在步驟四調試運行工作流程時,設定本次運行值為具體常量(例如20250223),任務運行將會使用此常量替換任務中定義的變數。(可選)配置調度屬性。
本教程調度配置相關參數保持預設即可,您可以在MaxCompute SQL頁面右側單擊調度配置。調度配置中參數的詳細說明,詳情可參見節點調度配置。
調度參數:本教程已在工作流程調度參數中統一配置,工作流程內部節點無需配置,在任務或代碼中可直接使用。
調度策略:您可以在延時執行時間參數中指定子節點在工作流程執行後,延遲多久再執行,本教程不設定。
在節點工具列單擊儲存。
配置dws_user_info_all_di節點
本節點對使用者基本資料表(ods_user_info_d)和初步加工後的日誌資料表(dwd_log_info_di)進行匯總,將資料寫入dws_user_info_all_di表中。
在工作流程編排頁面中,滑鼠移至上方至
dws_user_info_all_di節點上,單擊開啟節點。將如下代碼粘貼至節點編輯頁面。
配置調試參數。
在MaxCompute SQL節點編輯頁面右側單擊回合組態,配置以下參數,用於在步驟四調試運行中使用回合組態的相關參數測試回合。
配置項
配置說明
計算資源
選擇準備環境階段綁定的MaxCompute計算資源以及其對應的計算配額。
資源群組
選擇準備環境階段購買的Serverless資源群組。
指令碼參數
無需配置。本教程提供的範例程式碼中統一使用
${bizdate}表示業務日期,在步驟四調試運行工作流程時,設定本次運行值為具體常量(例如20250223),任務運行將會使用此常量替換任務中定義的變數。(可選)配置調度屬性。
本教程調度配置相關參數保持預設即可,您可以在MaxCompute SQL頁面右側單擊調度配置。調度配置中參數的詳細說明,詳情可參見節點調度配置。
調度參數:本教程已在工作流程調度參數中統一配置,工作流程內部節點無需配置,在任務或代碼中可直接使用。
調度策略:您可以在延時執行時間參數中指定子節點在工作流程執行後,延遲多久再執行,本教程不設定。
在節點工具列單擊儲存。
配置ads_user_info_1d節點
本節點對dws_user_info_all_di表中資料進一步加工,將資料寫入ads_user_info_1d表,產出基本使用者畫像。
在工作流程編排頁面中,滑鼠移至上方至
ads_user_info_1d節點上,單擊開啟節點。將如下代碼粘貼至節點編輯頁面。
配置調試參數。
在MaxCompute SQL節點編輯頁面右側單擊回合組態,配置以下參數,用於在步驟四調試運行中使用回合組態的相關參數測試回合。
配置項
配置說明
計算資源
選擇準備環境階段綁定的MaxCompute計算資源以及其對應的計算配額。
資源群組
選擇準備環境階段購買的Serverless資源群組。
指令碼參數
無需配置。本教程提供的範例程式碼中統一使用
${bizdate}表示業務日期,在步驟四調試運行工作流程時,設定本次運行值為具體常量(例如20250223),任務運行將會使用此常量替換任務中定義的變數。(可選)配置調度屬性。
本教程調度配置相關參數保持預設即可,您可以在MaxCompute SQL頁面右側單擊調度配置。調度配置中參數的詳細說明,詳情可參見節點調度配置。
調度參數:本教程已在工作流程調度參數中統一配置,工作流程內部節點無需配置,在任務或代碼中可直接使用。
調度策略:您可以在延時執行時間參數中指定子節點在工作流程執行後,延遲多久再執行,本教程不設定。
在節點工具列單擊儲存。
四、加工資料
加工資料。
在工作流程工具列中,單擊運行,設定各節點定義的參數變數在本次運行中的取值(本教程使用
20250223,您可以按需修改),單擊確定後,等待運行完成。查詢資料加工結果。
在Data Studio左側導覽列單擊
 ,進入資料開發頁面,然後在個人目錄地區,單擊
,進入資料開發頁面,然後在個人目錄地區,單擊 ,建立一個尾碼為
,建立一個尾碼為.sql的檔案(檔案名稱自訂即可)。在頁面底部如下位置確認語言模式是否為
MaxCompute SQL。
在SQL編輯視窗中輸入如下SQL語句,查看最終結果表
ads_user_info_1d的記錄數,確認是否產生資料加工結果。-- 此處您需要修改分區過濾條件為您當前操作的實際業務日期。本教程中,前文配置的調試參數bizdate(業務日期)為20250223。 SELECT count(*) FROM ads_user_info_1d WHERE dt='業務日期';上述命令查詢存在資料,即表示資料加工已完成。
如果沒有資料,請確保運行工作流程時,配置的本次運行值與此處查詢時
dt指定的業務日期一致,您可以單擊工作流程,單擊右側的運行歷史,在運行記錄右側操作列單擊查看,然後在工作流程的作業記錄中確認運行工作流程時業務日期的取值(partition=[pt=xxx])。
五、發布工作流程
任務需要發布至生產環境後才可自動調度運行,您可以參考如下步驟,將工作流程發布至生產環境。
本教程已在工作流程調度配置中統一配置了調度參數,發布前無需再為每個節點單獨配置調度參數。
在Data Studio左側導覽列單擊
,進入資料開發頁面,然後在專案目錄地區找到已建立好的工作流程,單擊進入工作流程編排頁面。單擊節點工具列中的發布,開啟發布面板。
單擊開始發布生產,在彈出的發布方式確認視窗內,根據實際需求選擇發布方式:
全量發布:發布當前工作流程以及內部的所有任務。
增量發布:僅發布當前工作流程,以及所儲存內容相較於當前所有發布環境基準存在變更的內部任務節點,適用於迭代最佳化,小範圍更新等情境。
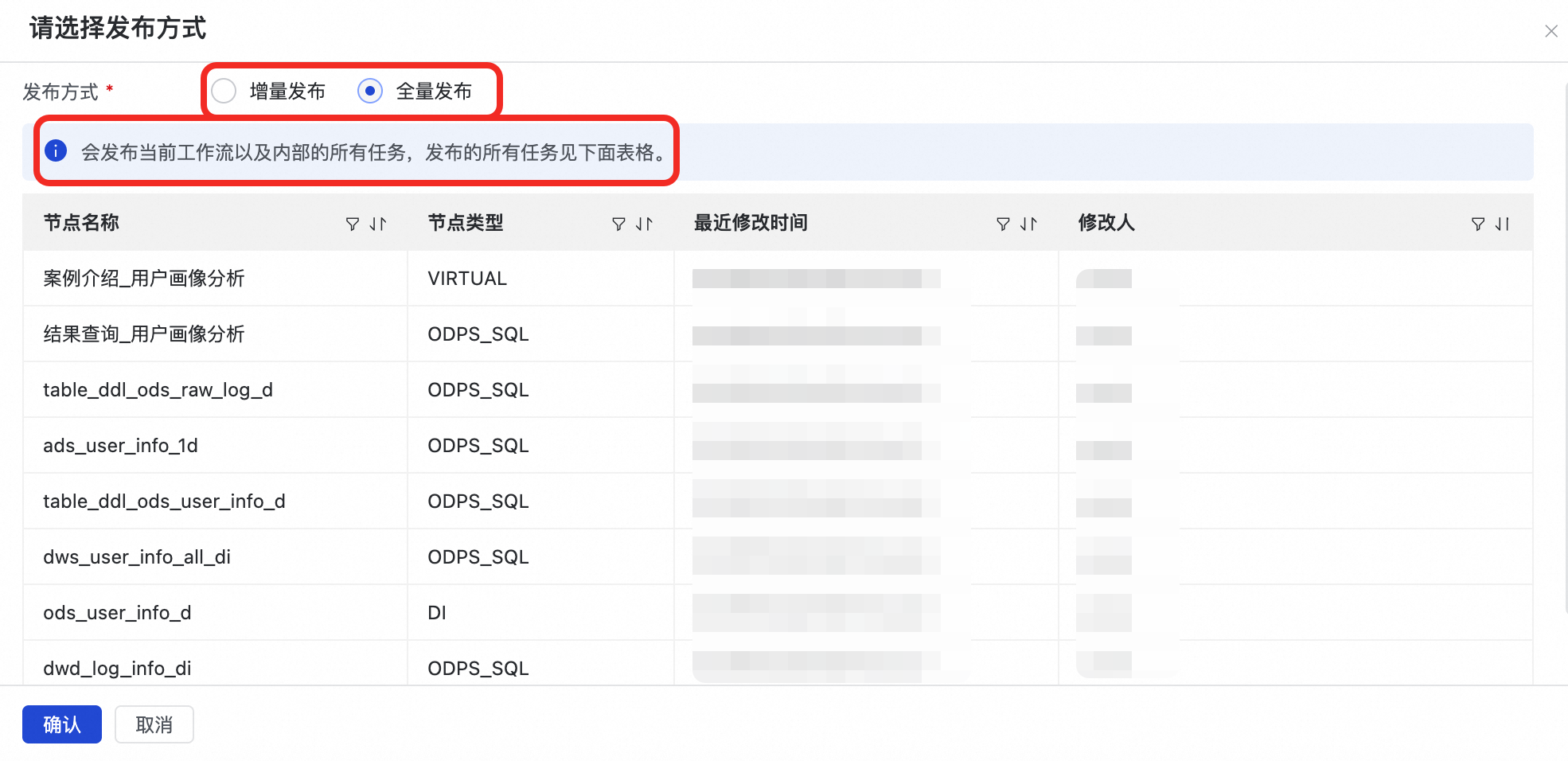
確認發布方式後,系統將自動執行發布流程,依次將工作流程和所選任務節點發布到開發環境和生產環境;在發布到生產環境環節,需單擊確認發布完成最終操作。
六、在生產環境運行任務
任務發布後,在次日才會產生執行個體運行,您可以通過補資料來對發行流程進行補資料操作,以便查看任務在生產環境是否可以運行,詳情可參見補資料執行個體營運。
任務發布成功後,單擊右上方的營運中心。
您也可以單擊左上方的
 表徵圖,選擇。
表徵圖,選擇。單擊左側導覽列中的,進入周期任務頁面,單擊
workshop_start虛節點。在右側的DAG圖中,按右鍵
workshop_start節點,選擇。勾選需要補資料的任務,設定業務日期,單擊提交並跳轉。
在補資料頁面單擊重新整理,直至SQL任務全部運行成功即可。