在資料同步過程中,未經處理資料可能存在格式不一、資訊冗餘或非結構化等問題。DataWorks離線同步任務內建的資料處理功能,可在資料同步鏈路中直接對資料進行清洗、AI輔助處理和向量化轉換,以簡化ETL架構。
使用限制
僅啟用了新版資料開發的工作空間可用。
僅支援使用Serverless資源群組。
當前僅部分單表離線的通道開通了此功能。
開啟資料處理能力會額外消耗部分計算資源(CU),請關注您的資源配額。
配置入口
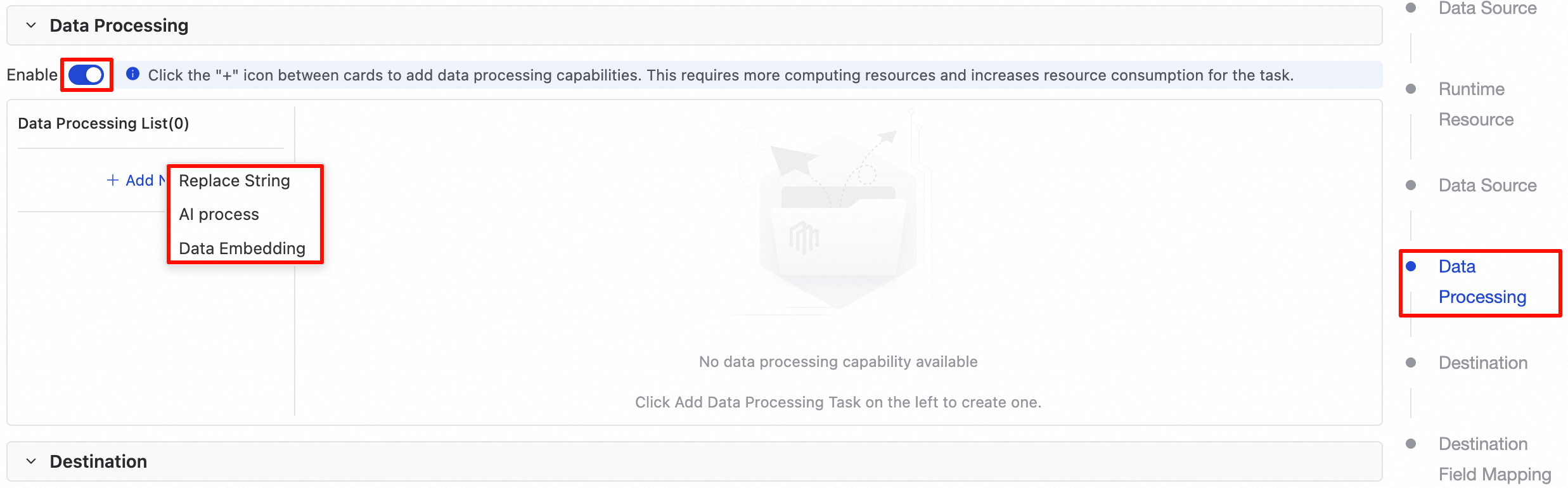
建立或編輯的離線同步任務配置頁面,向下滾動至資料處理地區。
預設情況下,該功能為關閉狀態。請單擊開啟開關,以啟用資料處理模組的配置。
功能介紹
開啟資料處理模組後,您可以按需添加以下一種或多種處理規則。
1. 字串替換
字串替換是最基礎也是最常用的資料清洗功能,支援為當前任務的不同欄位設定多條替換規則。
嚮導模式配置說明
單擊資料處理列表下的+添加節點按鈕,選擇字串替換,可以新增一條替換規則。各配置項說明如下:
配置項 | 說明 |
名稱 | 為該條替換規則自訂一個易於識別的名稱。 |
描述 | (可選)對該規則的用途進行詳細描述。 |
欄位名 | 單擊+新增規則按鈕,新增一條欄位規則。從源表欄位的下拉式清單中選擇一個欄位,應用此規則。 |
要替換的內容 | 輸入需要被尋找和替換的原始字串。 |
替換為 | 輸入您希望替換成的新字串。 |
| 開關按鈕,用於開啟Regex,支援Regex方式尋找需要被替換的原始字串。 |
| 開關按鈕,用於控制要替換的內容在尋找時是否區分字母大小寫。預設不區分大小寫。 |
支援添加多條規則,以實現對不同欄位、不同內容的精細化替換。例如,您可以建立一條規則將gender欄位中的'男'替換為'1',同時建立另一條規則將status欄位中的'active'替換為'valid'。
資料輸出預覽
完成規則配置後,單擊資料處理地區右上方的資料輸出預覽。
在彈出的對話方塊中配置輸入資料。支援以下兩種方式:
自動擷取:系統預設從上遊節點的輸出擷取資料。可單擊重新擷取上遊輸出重新整理資料。
手動構造:單擊 +手工構造資料,在資料行中為各欄位輸入自訂值,或測試特定邊界條件(如
NULL或Null 字元串)。
單擊預覽結果地區的預覽按鈕。
系統將執行已配置的所有處理規則,並在下方顯示處理結果。對比結果與預期,可判斷規則配置是否正確。
此處的預覽結果僅供調試和參考,最終的執行結果以任務實際運行時為準。
指令碼模式配置說明
指令碼模式下如需支援資料處理,需在JSON指令碼的steps模組中新增"category": "map", "stepType": "stringreplace"的JSONObject,指令碼模式的通用配置流程參見:指令碼模式配置。
{
"category": "map",
"stepType": "stringreplace",
"parameter": {
"condition": [
{
"name": "<需處理的欄位名>",
"replaceString": "<要替換的內容>",
"replaceByString": "<替換後的新內容>",
"useRegex": false,
"caseSensitive": false
}
]
},
"displayName": "<規則名稱>",
"description": "<規則描述>"
}2. AI輔助處理
此功能通過調用內建的大語言模型,對指定欄位的內容進行智能化的加工和處理,賦予資料更豐富的業務價值。
核心應用情境:
內容摘要:從大段文本(如產品評論、新聞內容)中提取核心摘要。
資訊提取:從非結構化文本中抽取出關鍵資訊,如姓名、地址、連絡方式等。
文本翻譯:將欄位內容翻譯成指定語言。
情感分析:判斷文本的情感傾向(如正面、負面、中性)。
配置與使用:
在添加節點時,選擇AI輔助處理。關於此功能的詳細配置方法和典型應用案例,請參見:AI輔助處理。
3. 資料向量化
資料向量化是將文本或其他類型的資料通過Embedding模型轉換為高維數學向量的過程。這些向量能夠捕捉資料的語義資訊,是構建檢索增強產生(RAG)、語義搜尋、推薦系統等AI應用的關鍵步驟。
核心應用情境:
構建知識庫:將文檔、工單、產品說明等文本資料向量化後存入向量資料庫,作為大模型的外部知識庫。
個人化推薦:基於使用者和物品的向量表示,計算相似性,實現精準推薦。
配置與使用:
在添加節點時,選擇資料向量化,選擇需要處理的欄位和使用的Embedding模型。關於此功能的詳細配置方法和實戰案例,請參見:向量化處理。