阿里雲DataWorksData Integration推出Embedding向量化功能,支援將分散在OSS、MaxCompute、HDFS等異構來源中的資料幫浦並轉化為向量,寫入Milvus、Elasticsearch、Opensearch等向量庫,以及Hologres向量表等具備向量儲存能力的目標端,能夠大幅簡化ETL流程,高效實現知識向量化,助力RAG等AI情境落地。
為什麼使用 Embedding
隨著大語言模型(LLM)技術的持續演化,對企業而言,將私人知識深度整合至模型體系,是實現其在實際業務情境中有效落地並創造價值的關鍵。檢索增強產生(RAG)由此成為重要的技術路徑之一,通過將資料編碼為向量表示,並結合向量資料庫進行高效檢索,為大模型提供精準、權威且動態更新的領域知識支援。
您的業務資料可能散落在OSS、MaxCompute、HDFS、MySQL、Oracle 或訊息佇列等眾多異構資料來源中,需要將這些異構資料來源的資料做好Embedding向量化,然後將向量化的結果再寫入各種具備向量儲存能力的目標端中(比如 Milvus、OpenSearch、 Elasticsearch等向量庫或Hologres向量表)。此過程不僅需要編寫繁瑣的ETL指令碼,還需要適配各種源端資料來源類型,資料將曆經抽取、轉換、向量化(Embedding)及寫入等多個階段,流程鏈路長且耦合度高,導致模型迭代周期顯著延長。
功能介紹
DataWorksData Integration支援Embedding向量化功能,在同一條資料通道內一站式完成抽取、向量化與寫入向量資料庫,實現端到端的自動化處理。該能力顯著降低開發複雜度,縮短知識更新延遲,助力RAG、智能客服、搜尋推薦等情境實現高效的知識接入。
Data Integration離線同步資料Embedding向量化同步能力,支援兩種配置模式:
使用限制
-
僅啟用了新版資料開發的工作空間可用。
-
僅支援使用Serverless資源群組。
-
當前僅部分離線同步的通道開通了此功能。
計費說明
使用了AI輔助處理的Data Integration任務,除Data Integration任務本身涉及的費用外:Data Integration情境費用,還涉及調用大模型產生的費用。其中:
-
阿里雲DataWorks模型服務計費說明見:Serverless資源群組計費-大模型服務。
-
阿里雲百鍊平台計費說明見:模型推理(調用)計費。
-
阿里雲PAI模型市場計費說明見:模型線上服務(EAS)計費說明。
準備工作
-
已建立啟用了新版資料開發的工作空間。
-
已建立Serverless資源群組並綁定至工作空間。
-
已準備AI輔助處理所需的大模型服務,根據選擇的大模型服務商不同,需做如下準備:
-
阿里雲DataWorks模型服務:已在大模型服務管理中完成模型部署,並啟動模型服務。
-
阿里雲百鍊平台:已開通阿里雲的大模型服務平台百鍊並擷取API Key。
-
阿里雲PAI模型市場:已開通人工智慧平台PAI並擷取模型服務的Token。
-
-
已建立離線同步任務所需的資料來源與資料去向資料來源。
本教程以MaxCompute同步至Milvus為例,因此需要先建立MaxCompute資料來源和Milvus資料來源。
測試資料準備
本教程示範的表資料來自公開資料集(電商網站商品評論情感預測資料集),將商品的使用者評論做向量化處理,然後同步到Milvus中進行後續的相似性檢索。
-
資料來源MaxCompute側:建立測試表並插入測試資料。
-
資料去向Milvus側:建立目標表用於接收向量化後的資料。表結構如下:
目標表特性為自動ID表。
欄位名
類型
描述
id
Int64
主鍵,自動遞增。
sentence
VarChar(32)
儲存原始文本。
sentence_e
FloatVector(128)
向量欄位,用於相似性搜尋,使用COSINE度量。
嚮導模式配置
本教程以源端MaxCompute(ODPS)將資料讀取並做Embedding向量化後同步到Milvus為例,介紹如何在Data Integration中使用嚮導模式配置離線同步任務。
一、建立離線同步節點
-
進入DataWorks工作空間列表頁,在頂部切換至目標地區,找到目標工作空間,單擊操作列的快速進入> Data Studio,進入Data Studio。
-
在專案目錄單擊
 ,選擇,配置數據來源與去向(本教程來源為MaxCompute、去向為Milvus)、節點名称,單擊確認。
,選擇,配置數據來源與去向(本教程來源為MaxCompute、去向為Milvus)、節點名称,單擊確認。
二、配置離線同步任務
-
配置基本資料。
-
数据源:選擇資料來源和資料去向對應的資料來源。
-
運行資源:執行離線同步任務所使用的資源群組,選擇當前工作空間已綁定且與資料來源連通的資源群組。
如果無可用的資料來源和運行資源,請確保已完成準備工作。
-
-
配置數據來源。
以下為本教程MaxCompute資料來源需配置的關鍵參數,如果使用其他資料來源,配置可能存在差異,請根據實際情況配置。
本教程中,表選擇
test_tb,過濾方式選擇分區過濾,分區條件設定為split=dev,分區不存在時選擇忽略不存在分區,任務正常執行。參數
說明
Tunnel資源組
Tunnel Quota,預設選擇
公用傳輸資源,即MaxCompute的免費quota。MaxCompute的資料轉送資源選擇,具體請購買與使用獨享Data Transmission Service資源群組。重要如果獨享Tunnel Quota因欠費或到期不可用,任務在運行中將會自動切換為
公用傳輸資源。錶
選擇待同步的資料來源表。
如果無可選的來源表,請確保已完成測試資料準備。
過濾方式
支援分區過濾和數據過濾:
-
如果來源表是分區表,您可以按分區選擇同步資料的範圍。
-
如果來源表是非分區表,您可以設定
WHERE過濾語句,選擇同步資料的範圍。
您可以單擊數據預覽,查看配置是否正確。
資料預覽彈窗將以表格形式展示來源表的資料,本教程中包含
sentence(評論文本)、label(情感標籤)和dataset(資料集來源)三列。 -
-
配置數據處理。
-
開啟資料處理開關,然後在數據處理列表中單擊,添加資料向量化處理節點。
-
配置資料向量化節點。名稱填寫
sentence2emb,模型名稱選擇text-embedding-v4,向量化欄位選擇sentence,向量化結果欄位填寫sentence_e,向量維度設定為128,並勾選NULL值轉為空白字串。關鍵參數解釋如下:說明-
資料向量化節點效能取決於配置的模型效能,阿里雲百鍊平台提供的QWen模型有QPS限制,阿里雲PAI模型市場需要您自己在PAI EAS上部署模型,其效能表現取決於部署模型使用的資源規格。
-
在參數確定的情況下,Embedding模型產生的向量結果是確定性。因此DataWorksData Integration在同步的過程中針對相同的向量化未經處理資料進行了LFU Cache(Least Frequently Used)最佳化,避免相同的資料重複調用Embedding模型,以提升處理效能,降低Embedding成本。
參數
描述
模型提供商
大模型供應商,目前支援如下模型供應商:阿里雲DataWorks模型服務、阿里百鍊平台、阿里雲PAI模型市場。
模型名稱
Embedding模型名稱,按需選擇。
模型 API Key
訪問模型的API KEY,請前往模型供應商擷取。
-
阿里雲百鍊平台:擷取百鍊API Key。
-
阿里雲PAI模型市場:前往部署的EAS任務,進入線上調試,擷取Headers Authorization的參數值,將其作為API KEY填寫到此處。
模型 Endpoint
模型提供商選擇阿里雲PAI模型市場時,需要配置訪問模型的訪問點(Endpoint API地址)。
批處理大小
向量化批處理大小,取決於Embedding模型是否支援批處理,批處理有助於提升Embedding效能,降低Embedding成本。預設為10。
選擇需要向量化的字段
定義需要將哪些列進行向量化,指定向量化後輸出的欄位名,Data Integration支援對來源單個欄位或者多個欄位拼接組合做向量化。
向量化結果字段
源表來源欄位向量化後定義的向量化欄位名稱。
向量維度
輸出的向量維度,配置的Embedding模型必須支援定義的向量維度。預設為1024。
NULL值轉為空字符串
由於大模型做向量化時不允許傳入的資料為NULL,因此如果源表資料存在NULL,支援將其轉為空白字串處理,避免向量化異常。預設不勾選。
拼接字段名
做向量化時,是否需要拼接欄位名稱到文本中一起做向量化。選中時,還需要配置字段名拼接符。預設不勾選。
是否跳過空值字段
多個欄位拼接進行向量化時,是否要跳過空值欄位。預設選中,跳過空值欄位。
-
-
資料輸出預覽。
您可以單擊資料向量化節點配置地區右上方的數據輸出預覽,然後預覽向量化後的結果,確認配置是否正確。
您也可以單擊離線同步編輯頁面頂部的模擬運行,預覽向量化後的結果。
預覽結果中,新增的 sentence_e 列顯示每條句子對應的向量嵌入值(浮點數序列)。
-
-
配置數據去向。
以下為本教程Milvus資料來源需配置的關鍵參數,如果使用其他資料來源,配置可能存在差異,請根據實際情況配置。
本教程中,集合設為 Milvus_Collection,寫入模式選擇 insert,單次寫入的資料條數設為 1024,集合建立模式選擇忽略。
參數
說明
集合
用於接收向量資料的Collection。
分區鍵
可選,如果Collection配置了分區,您可以為接收的向量資料指定分區。
寫入模式
-
upsert:
-
當表未設定自動ID時:根據主鍵更新 Collection 中的某個 Entity。
-
當表設定自動ID時:將 Entity 中的主鍵替換為自動產生的主鍵,並插入資料。
-
-
insert:多用於自動ID表插入資料,milvus自動產生主鍵。
非自動ID表使用
insert會導致資料重複。
-
-
配置去向字段映射。
當配置完資料來源、資料處理和資料去向後,離線同步將自動產生欄位對應關係,由於目標端為無固定結構資料來源,預設按同行映射執行,因此,需要單擊來源字段或目標字段後的编辑,調整欄位對應順序,或者刪減不需要的欄位,以確保映射關係正確。
例如,本教程手動刪除不需要映射的欄位,調整後的映射關係如下。
來源欄位 sentence 映射到目標欄位 sentence(類型 VarChar,maxLength 32),來源欄位 sentence_e 映射到目標欄位 sentence_e(類型 FloatVector,dimension 128)。
-
更多高級配置。
單擊節點配置頁面右側的高級配置,你可以按需設定任務並發數、同步速率、髒資料策略等參數。
三、調試運行
-
單擊離線同步節點編輯頁面右側的回合組態,設定調試運行使用的資源組和腳本參數,然後單擊頂部工具列的運行,測試同步鏈路是否成功運行。
-
您可以前往Milvus側,查看資料去向Collection中的資料是否符合預期。
四、調度配置與發布
單擊離線同步任務右側的調度配置,設定周期運行所需的調度配置參數後,單擊頂部工具列的发布,進入發布面板,根據頁面提示完成發布。
指令碼模式配置
本教程以源端MaxCompute(ODPS)將資料讀取並做Embedding向量化後同步到Milvus為例,介紹如何在Data Integration中使用指令碼模式配置離線同步任務。
一、建立離線同步節點
-
進入DataWorks工作空間列表頁,在頂部切換至目標地區,找到目標工作空間,單擊操作列的快速進入> Data Studio,進入Data Studio。
-
在專案目錄單擊
,選擇,配置數據來源與去向(本教程來源為MaxCompute、去向為Milvus)、節點名称,單擊確認。
二、配置同步指令碼
-
單擊離線同步節點頂部工具列的
 ,切換為指令碼編輯模式。
,切換為指令碼編輯模式。 -
配置MaxCompute到Milvus的離線同步任務。
請根據附錄1:指令碼模式格式說明,配置離線同步任務的JSON指令碼。本樣本配置的指令碼如下:
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "odps", "parameter": { "partition": [ "split=dev" ], "datasource": "MaxCompute_Source", "successOnNoPartition": true, "tunnelQuota": "default", "column": [ "sentence" ], "enableWhere": false, "table": "test_tb" }, "name": "Reader", "category": "reader" }, { "category": "flatmap", "stepType": "embedding-transformer", "parameter": { "modelProvider": "bailian", "modelName": "text-embedding-v4", "embeddingColumns": { "sourceColumnNames": [ "sentence" ], "embeddingColumnName": "sentence_e" }, "apiKey": "sk-****", "dimension": 128, "nullAsEmptyString": true }, "displayName": "sentence2emb", "description": "" }, { "stepType": "milvus", "parameter": { "schemaCreateMode": "ignore", "enableDynamicSchema": true, "datasource": "Milvus_Source", "column": [ { "name": "sentence", "type": "VarChar", "elementType": "None", "maxLength": "32" }, { "name": "sentence_e", "type": "FloatVector", "dimension": "128", "elementType": "None", "maxLength": "65535" } ], "writeMode": "insert", "collection": "Milvus_Collection", "batchSize": 1024, "columnMapping": [ { "sourceColName": "sentence", "dstColName": "sentence" }, { "sourceColName": "sentence_e", "dstColName": "sentence_e" } ] }, "name": "Writer", "category": "writer" } ], "setting": { "errorLimit": { "record": "0" }, "speed": { "concurrent": 2, "throttle": false } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }-
Reader與Writer部分的參數解釋,請參見MaxCompute資料來源和Milvus資料來源。
-
如果您使用其他類型資料來源和去向,請參見資料來源列表。
-
資料向量化處理節點指令碼部分各參數說明如下:
參數
描述
是否必填
modelProvider
大模型供應商,目前支援如下模型供應商:
-
dataworksModelService:通過DataWorks大模型服務部署的模型服務。
-
bailian:阿里雲百鍊平台,支援QWen模型。
-
paiModelGallery:阿里雲PAI模型市場,支援BGE-M3模型。
是
modelName
Embedding模型名稱。
-
modelProvider為bailian時,可選擇
text-embedding-v4、text-embedding-v3。 -
modelProvider為paiModelGallery時,可選擇
bge-m3。
是
apiKey
訪問模型的API KEY,請前往模型供應商擷取。
是
endpoint
modelProvider為paiModelGallery時,需要配置訪問模型的訪問點(Endpoint API地址)。
否
batchSize
向量化批處理大小,取決於Embedding模型是否支援批處理,批處理有助於提升Embedding效能,降低Embedding成本。預設為10。
否
embeddingColumns
定義需要將哪些列進行向量化,指定向量化後輸出的欄位名,Data Integration支援對來源單個欄位或者多個欄位拼接組合做向量化。
例如:
{ "embeddingColumns": { "sourceColumnNames": [ "col1", "col2" ], "embeddingColumnName": "my_vector" } }是
appendDelimiter
將多個欄位值拼接為一個文本進行向量化時的拼接符。預設值
\n。否
skipEmptyValue
多個欄位拼接進行向量化時,是否要跳過空值欄位。預設False。
否
dimension
輸出的向量維度,配置的Embedding模型必須支援定義的向量維度。預設為1024。
否
nullAsEmptyString
由於大模型做Embedding時不允許傳入的資料為NULL,因此如果源表資料存在NULL,支援將其轉為空白字串處理,避免向量化異常。預設
False。否
appendFieldNameEnable
做向量化時,是否要將未經處理資料和欄位名拼接在一起做向量化。開啟時,還需要配置appendFieldNameDelimiter。預設
False。否
appendFieldNameDelimiter
拼接欄位名稱時的拼接符,僅在開啟appendFieldNameEnable時生效。
否
-
-
-
類比運行。
您可以單擊離線同步節點編輯頁面頂部的模擬運行,然後依次單擊開始採集、預覽,查看向量化後的結果,確認配置是否正確。在彈窗中設定採樣條數為3,單擊開始採集擷取輸入資料。輸入資料表格包含 sentence、label、dataset 三列。預覽結果中新增 sentence_e 列,展示每條文本經 embedding 轉換後產生的浮點數向量,輸入資料中發現髒資料 0 條。確認無誤後單擊確定。
-
更多高級配置。
單擊節點配置頁面右側的高級配置,你可以按需設定任務並發數、同步速率、髒資料策略等參數。
三、調試運行
-
單擊離線同步節點編輯頁面右側的回合組態,設定調試運行使用的資源組和腳本參數,然後單擊頂部工具列的運行,測試同步鏈路是否成功運行。
-
您可以前往Milvus側,查看資料去向Collection中的資料是否符合預期。
四、調度配置與發布
單擊離線同步任務右側的調度配置,設定周期運行所需的調度配置參數後,單擊頂部工具列的发布,進入發布面板,根據頁面提示完成發布。
附錄1:指令碼模式格式說明
指令碼模式的基本結構如下:
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "xxx",
"parameter": {
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "xxx",
"parameter": {
},
"name": "transformer1",
"category": "map/flatmap"
},
{
"stepType": "xxx",
"parameter": {
},
"name": "transformer2",
"category": "map/flatmap"
},
{
"stepType": "xxx",
"parameter": {
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
}
}steps裡定義了每個處理的運算元,至少需要一個Reader,一個Writer,中間可以有若干個Transformer轉換運算元。假設您配置的並發度為2,那麼一個Job將會有兩條並行的資料處理流,每個Reader、Transformer、Writer都屬於任務配置中的一個step。
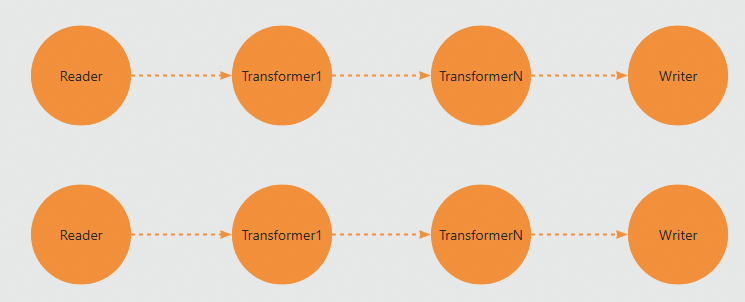
steps定義了每個運算元的類型和參數,資料同步及處理過程嚴格遵循每個step在JSON配置裡的順序執行。
Data Integration支援的各種資料來源讀、寫通道詳細參數配置,詳見:支援的資料來源及同步方案。
附錄2:OSS同步至Milvus案例
本案例從OSS中同步JSONLine格式資料,經過JSON解析處理,對JSON中指定部分欄位進行向量化,最終同步到Milvus,完整JSON配置樣本如下:
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "oss",
"parameter": {
"datasource": "${OSS資料來源名稱}",
"column": [
{
"name": "chunk_text",
"index": 0,
"type": "string"
}
],
"fieldDelimiter": ",",
"encoding": "UTF-8",
"fileFormat": "jsonl",
"object": [
"embedding/chunk1.jsonl"
]
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "json-extracting",
"parameter": {
"column": [
{
"name": "text",
"fromColumn": "chunk_text",
"jsonPath": "$.text",
"type": "STRING",
"nullOrInvalidDataAction": "DIRTY_DATA"
}
]
},
"name": "jsonextract",
"category": "flatmap"
},
{
"stepType": "embedding-transformer",
"parameter": {
"modelProvider": "bailian",
"modelName": "text-embedding-v4",
"apiKey": "${填寫需要訪問的AK}",
"embeddingColumns": {
"sourceColumnNames": [
"text"
],
"embeddingColumnName": "my_vector"
},
"batchSize": 8,
"dimension": 1024
},
"name": "embedding",
"category": "flatmap"
},
{
"stepType": "milvus",
"parameter": {
"schemaCreateMode": "ignore",
"enableDynamicSchema": true,
"datasource": "${Milvus資料來源名稱}",
"column": [
{
"name": "my_vector",
"type": "FloatVector",
"dimension": "1024",
"elementType": "None",
"maxLength": "65535"
},
{
"name": "text",
"type": "VarChar",
"elementType": "None",
"maxLength": "65535"
}
],
"collection": "yunshi_vector_07171130",
"writeMode": "insert",
"batchSize": 1024,
"columnMapping": [
{
"sourceColName": "my_vector",
"dstColName": "my_vector"
},
{
"sourceColName": "text",
"dstColName": "text"
}
]
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"concurrent": 1
}
}
}