該功能在DataWorksData Integration鏈路中,原生整合了AI大模型處理能力。它將傳統的資料同步從簡單的“搬運”升級為智能的“加工”,允許使用者在資料從源到端的傳輸過程中,即時調用AI模型對流經的資料進行內容分析、處理與增強,在資料流轉的過程中釋放非結構化資料的隱藏價值。
功能介紹
-
適用客戶:適用於需要在資料同步過程中對資料進行進階分析和處理的企業使用者,特別是那些希望利用AI技術提升資料品質、挖掘資料價值的公司。
-
無縫嵌入同步鏈路:將AI處理作為Data Integration中的一個內建處理環節,與源端讀取、目標端寫入無縫銜接。
-
支援豐富的NLP任務:可對同步中的文本資料進行多種自然語言處理(NLP),如:情感分析、摘要產生、關鍵詞提取、文本翻譯。
使用情境
|
行業領域 |
典型應用 |
|
客戶服務 / 電子商務 |
即時分析使用者評論、客服工單的情感傾向,自動提取核心問題與反饋要點。 |
|
合規 / 法律 / 科研 |
在同步過程中,對政策檔案、法律合約、科研論文進行自動摘要和關鍵資訊提取。 |
|
製造 / 供應鏈 / 醫學 |
智能分析裝置日誌、供應鏈反饋或醫患溝通記錄,實現風險預警和服務品質最佳化。 |
|
跨語言協作 |
將來自全球各地的社交媒體評論、新聞資訊或業務文檔,在同步時自動翻譯成統一語言,便於集中分析。 |
準備工作
-
已建立使用資料開發(Data Studio)(新版)的工作空間。
-
已準備AI輔助處理所需的大模型服務,根據選擇的大模型服務商不同,需做如下準備:
-
阿里雲DataWorks模型服務:已在大模型服務管理中完成模型部署,並啟動模型服務。
-
阿里雲百鍊平台:已開通阿里雲的大模型服務平台百鍊並擷取API Key。
-
阿里雲PAI模型市場:已開通人工智慧平台PAI並擷取模型服務的Token。
-
-
離線同步任務支援手動設定資料來源資訊或使用已有資料來源。
-
確保工作空間已綁定資源群組,且資源群組已與資料來源連通。
計費說明
使用了AI輔助處理的Data Integration任務,除Data Integration任務本身涉及的費用外:Data Integration情境費用,還涉及調用大模型產生的費用。其中:
-
阿里雲DataWorks模型服務計費說明見:Serverless資源群組計費-大模型服務。
-
阿里雲百鍊平台計費說明見:模型推理(調用)計費。
-
阿里雲PAI模型市場計費說明見:模型線上服務(EAS)計費說明。
案例說明
本案例以Hologres為例,介紹Hologres單表離線同步至Hologres時,如何使用AI輔助處理功能,將資料來源表中feedback_info列的資料翻譯為英文並同步至目標表。
一、建立離線同步任務
-
進入DataWorks工作空間列表頁,在頂部切換至目標地區,找到目標工作空間,單擊操作列的,進入Data Studio。
-
在左側導覽列單擊
 ,進入資料開發頁面,在專案目錄右側單擊
,進入資料開發頁面,在專案目錄右側單擊 ,選擇,進入建立節點對話方塊。
,選擇,進入建立節點對話方塊。 -
設定節點路徑、資料來源去向和節點名稱後,單擊確認,建立離線同步節點。
本文以Hologres同步至Hologres為例,介紹離線同步任務中的AI輔助處理功能。
二、配置同步任務
建立離線同步節點後,會自動進入任務編輯頁面,您需要在此頁面配置如下資訊:
1、資料來源
分別配置資料同步任務的資料來源和資料去向。
-
類型:建立離線同步任務步驟中已選擇的資料來源和去向的資料來源類型,不支援修改,如需修改請重新建立離線同步任務。
-
資料來源:選擇已綁定至工作空間的Hologres資料來源,或者在下拉中選擇新增資料來源。
2、運行資源
-
選擇同步任務所使用的資源群組。如果使用Serverless資源群組,您還可以為該任務分配資源佔用(CU)。
-
選擇資源群組後,Data Integration將自動檢測資源群組與資料來源、資料去向的連通性,您也可以手動單擊連通性檢查。

3、資料來源
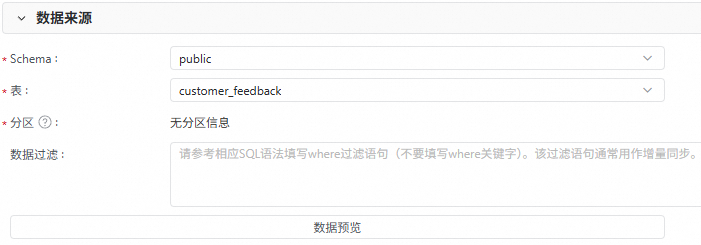
配置資料來源具體待同步的表資訊,如Schema、表、分區和資料過濾條件等。您可以單擊資料預覽,查看待同步的具體資料。
4、資料處理
-
在資料處理地區,您可以開啟資料處理能力,資料處理能力需要更多的計算資源,會增加任務的資源佔用開銷。
-
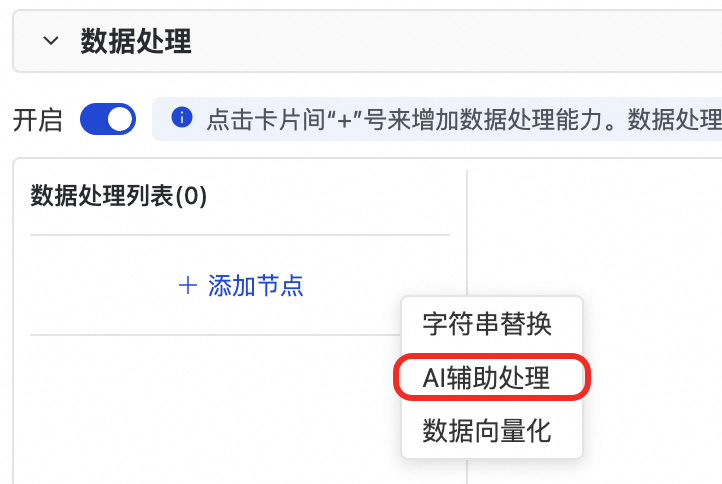
單擊添加節點,選擇AI輔助處理。
-
配置AI輔助處理相關資訊。
關鍵參數解釋如下:
參數
描述
模型供應商
模型Endpoint
選擇阿里雲PAI模型市場,填寫模型的調用Endpoint。擷取地址,詳見測試服務調用。
模型名稱
負責智能資料處理的模型,按需選擇。
API Key
訪問模型的API KEY,請前往模型供應商擷取。
-
阿里雲百鍊平台:擷取百鍊API Key。
-
阿里雲PAI模型市場:前往部署的EAS任務,進入線上調試,擷取Token,將其作為API KEY填寫到此處。
處理工作描述
請使用自然語言描述對來源欄位的處理,欄位名以
#{column_name}格式書寫。例如,本案例中,此處填寫請將'#{feedback_info}'翻譯成英文。寫入欄位
此處請輸入儲存結果欄位的名稱,如果對應欄位不存在,將自動新增一個欄位。
說明本案例的樣本配置中,會將來源表的
feedback_info欄位翻譯成英文,並儲存到feedback_processed欄位中。 -
-
您可以單擊AI輔助處理地區右上方的資料輸出預覽,查看輸出的最終資料效果。
-
(可選)您可以配置多個先後按順序執行的資料處理流程。
5、資料去向
-
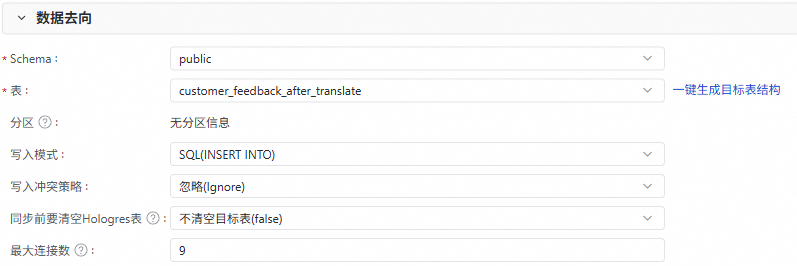
配置資料同步的目標表資訊,例如Schema、表名、分區等。
-
您可以單擊一鍵產生目標表結構,快速產生目標表。
-
如果目標端中已存在表用於接收資料,則按需選擇即可。
-
-
配置寫入模式以及寫入衝突策略。
-
配置同步前是否要清空Hologres表中的已有資料。
-
(可選)配置最大串連數。
最大串連數僅在寫入模式為
SQL(INSERT INTO)下生效,在開啟任務時請確保Hologres執行個體有充足的空閑串連。一個任務最多使用9個串連。
6、去向欄位對應
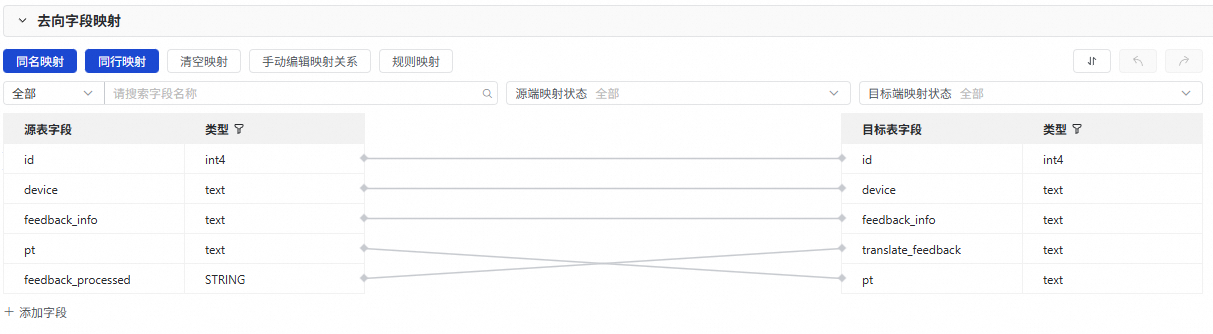
配置完成資料來源、資料處理和資料去向後,會在此處展示來源與去向表間的欄位對應關係,預設為同名映射和同行映射,你也可以按需進行調整。
本案例中除了將源表已有欄位(id、device、feedback_info、pt)同名映射外,還需要手動將源表中儲存翻譯後結果的feedback_processed欄位,映射至目標表的translate_feedback欄位中。
三、調試任務
-
在離線同步任務的編輯視窗右側,單擊回合組態,配置調試本節點使用的資源群組和相關指令碼參數。
-
單擊節點頂部工具列的儲存,然後單擊運行,等待運行結束,查看運行結果是否成功,您可以前往目標端資料庫查看錶資料是否符合預期。
四、調度配置
若離線同步節點需要周期性調度執行,您需要在節點右側的調度配置中設定調度策略,配置相關的節點調度屬性。
五、節點發布
請單擊節點工具列的發布表徵圖喚起發布流程,通過該流程將任務發布至生產環境。只有在發布至生產環境後,才會進行周期性調度。
後續操作:任務營運
節點發布後,您可以在發布流程中單擊補資料或去營運。