Hive輸出組件用於向Hive資料來源寫入資料。同步其他資料來源的資料至Hive資料來源的情境中,完成來源資料源的資訊配置後,需要配置Hive輸出組件寫入資料的目標資料來源。本文為您介紹如何配置Hive輸出組件。
使用限制
Hive輸出組件支援寫入檔案格式為orc、parquet、text、Hudi(Hudi格式僅支援Cloudera Data Platform7.x的Hive計算源或資料來源)、Iceberg(Iceberg格式僅支援E-MapReduce5.x的Hive計算源或資料來源)、Paimon(Paimon格式僅支援E-MapReduce5.x的Hive計算源或資料來源)的Hive資料表。不支援ORC格式的事務表、Kudu表整合。
Kudu表Data Integration請使用Impala輸出組件。更多資訊,請參見配置Impala輸出組件。
前提條件
已建立Hive資料來源。具體操作,請參見建立Hive資料來源。
進行Hive輸出組件屬性配置的帳號,需具備該資料來源的同步讀許可權。如果沒有許可權,則需要申請資料來源許可權。具體操作,請參見申請資料來源許可權。
操作步驟
在Dataphin首頁頂部功能表列,選擇研發 > Data Integration。
在整合頁面頂部功能表列選擇專案(Dev-Prod模式需要選擇環境)。
在左側導覽列中單擊離線整合,在離線整合列表中單擊需要開發的離線管道,開啟該離線管道的配置頁面。
單擊頁面右上方的組件庫,開啟組件庫面板。
在組件庫面板左側導覽列中需選擇輸出,在右側的輸出組件列表中找到Hive組件,並拖動該組件至畫布。
單擊並拖動目標輸入、轉換或流程組件的
 表徵圖,將其串連至當前Hive輸出組件上。
表徵圖,將其串連至當前Hive輸出組件上。單擊Hive輸出組件卡片中的
 表徵圖,開啟Hive輸出配置對話方塊。
表徵圖,開啟Hive輸出配置對話方塊。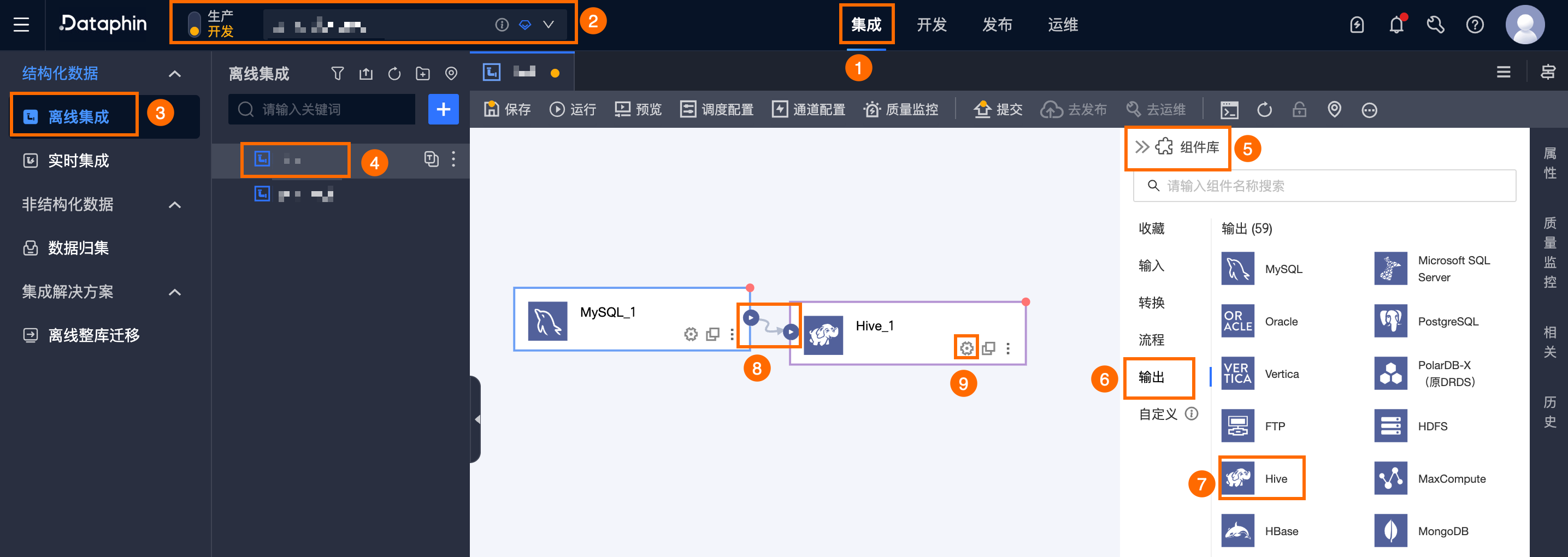
在Hive輸出配置對話方塊,配置參數。
Hive表與Hudi表所需配置的參數不同。
輸出目標表選擇為Hive表
參數
描述
基本設定
步驟名稱
即Hive輸出組件的名稱。Dataphin自動產生步驟名稱,您也可以根據業務情境修改。命名規則如下:
只能包含中文、字母、底線(_)、數字。
不能超過64個字元。
資料來源
在資料來源下拉式清單中,展示所有Hive類型的資料來源,包括您已擁有同步寫入權限的資料來源和沒有同步寫入權限的資料來源。單擊
 表徵圖,可複製當前資料來源名稱。
表徵圖,可複製當前資料來源名稱。對於沒有同步寫入權限的資料來源,您可以單擊資料來源後的申請,申請資料來源的同步寫入權限。具體操作,請參見申請資料來源許可權。
如果您還沒有Hive類型的資料來源,單擊建立資料來源,建立資料來源。具體操作,請參見建立Hive資料來源。
表
選擇輸出資料的目標表(Hive表)。 可輸入表名關鍵字進行搜尋,或輸入準確表名後單擊精準尋找。選擇表後,系統將自動進行表狀態檢測。單擊
 表徵圖,可複製當前所選表的表名稱。
表徵圖,可複製當前所選表的表名稱。如果Hive資料來源中沒有資料同步的目標表,則您可以通過一鍵建表的功能,簡單快速的產生目標表。詳細操作步驟如下:
單擊一鍵建表。Dataphin會自動為您匹配建立目標表的代碼,包括目標表名稱(預設為來源表名)、欄位類型(基於Dataphin欄位做了初步的轉換)等資訊。
資料湖表格式選擇為不選擇或Iceberg。
說明僅當所選資料來源或當前專案所使用的計算源開啟資料湖表格式,且選擇為Iceberg時,此處支援選擇Iceberg。
執行引擎選擇為Hive或Spark。
說明僅當資料湖表格式選擇為Iceberg時,支援選擇執行引擎。若所選資料來源已配置Spark,則展示並預設選擇Spark;若未配置,則僅展示並選擇Hive。
DDL根據所選的資料湖表格式以及執行引擎自動產生,您可在此基礎上進行修改,完成後單擊建立。目標表建立成功後,Dataphin自動將建立的目標表作為輸出資料的目標表。
說明如果開發環境存在同名的表,Dataphin會報已存在該表的錯誤。
沒有匹配項時,也支援根據手動輸入的表名進行整合。
生產表缺失策略
生產表不存在時的處理策略,可選擇不處理或自動建立,預設為自動建立。若選擇不處理,則任務發布時不進行生產表建立;若選擇自動建立,則任務發布時在目標環境建立同名表。
不處理:若目標表不存在,則提交時會提示目標表不存在,但仍可正常發布。此時,使用者需自行在生產環境建立目標表,才可執行任務。
自動建立:需編輯建表語句,預設填充所選表的建表語句,使用者可進行調整。建表語句中的表名使用預留位置
${table_name},且僅支援填寫該預留位置,實際執行時將替換為真實表名。若目標表不存在,則先按照建表語句進行建表,若建表失敗,則發布時檢查結果為失敗,您可根據錯誤提示修改建表語句,修改完成後再次進行發布。若目標表已存在,則不執行建表。
說明僅Dev-Prod模式專案中支援配置此項。
檔案編碼
選擇檔案儲存體在Hive的編碼方式。檔案編碼包括UTF-8和GBK。
載入策略
向目標資料來源(Hive資料來源)寫入資料時,資料寫入表中的策略。載入策略包括覆蓋所有資料、追加資料、僅覆蓋整合任務寫入的資料,適用情境說明如下:
覆蓋所有資料:會先刪除目標表或分區下的所有資料,再新增以表名開頭的資料檔案。
追加資料:直接向目標表追加寫入資料。
僅覆蓋整合任務寫入的資料:會先刪除目標表或分區下以表名開頭的資料檔案(通過SQL等其他方式寫入的資料不會被刪除)。
NULL值替換(非必填)
僅支援
textfile資料存放區格式的來源表。填寫需要替換為NULL的字串。例如,填寫\N時,系統會將\N字串替換為NULL。欄位分隔符號(非必填)
僅支援
textfile資料存放區格式的來源表。填寫欄位之間分隔字元。如果您沒有填寫,則系統預設為使用\u0001作為分隔字元。壓縮格式(非必填)
選擇檔案的壓縮格式。根據Hive中資料存放區格式不同,支援選擇壓縮格式不同:
資料存放區格式為orc:支援選擇的壓縮格式包括zlib、snappy。
資料存放區格式為parquet:支援選擇的壓縮格式包括snappy、gzip。
資料存放區格式為textfile:支援選擇的壓縮格式包括gzip、bzip2、 lzo、lzo_deflate、hadoop-snappy和zlib。
欄位分隔符號處理(非必填)
僅支援
textfile資料存放區格式的輸出表。資料中存在預設或自行配置的欄位分隔符號時,可以配置欄位分隔符號處理策略,防止資料寫入錯誤。可以選擇保留、去除或替換為。行分隔字元處理(非必填)
僅支援
textfile資料存放區格式的輸出表。資料中存在預設或自行配置的欄位分隔符號時,可以配置行分隔字元號處理策略,預設以\n作為行分隔字元,如資料中存在分行符號\r、\n,可選擇處理策略,防止資料寫入錯誤。可以選擇保留、去除或替換為。Hadoop參數配置(非必填)
用於調整寫入參數,針對不同的表類型可以填寫不同的參數,多個參數間用英文逗號隔開(,),格式為
{"key1":"value1", "key2":"value2"}。例如:輸出表格式為orc且欄位較多的情境下可根據記憶體大小來調整{"hive.exec.orc.default.buffer.size"}參數,記憶體足夠時可嘗試調大該配置提高寫入效能,記憶體不足時可嘗試調小該配置減少GC時間提高寫入效能,預設為16384Byte(16KB),建議不超過262144Byte(256KB)。分區
如果所選的目標表是分區表,那麼需要填寫分區資訊。例如,
state_date=20190101,也支援參數的方式以便每天增量寫入資料。例如,state_date=${bizdate}。準備語句(非必填)
資料匯入前對資料庫執行的SQL指令碼。
比如為了滿足服務的持續可用性,當前步驟寫資料執行前先建立目標表Target_A,執行寫入到目標表Target_A,當前步驟寫資料執行完成後,對資料庫中持續提供服務的表Service_B重新命名成Temp_C,然後將表Target_A重新命名為Service_B,最後刪除Temp_C。
結束語句(非必填)
資料匯入後對資料庫執行的SQL指令碼。
欄位對應
輸入欄位
根據上遊組件的輸出,為您展示輸入欄位。
輸出欄位
輸出欄位地區展示了已選中表的所有欄位。
重要為了保證資料寫入Hive時資料不會出錯,輸出欄位必須和輸入組件的欄位全部映射。
映射關係
根據上遊的輸入和目標表的欄位,可以手動選擇欄位對應。映射關係包括同行映射和同名映射。
同名映射:對欄位名稱相同的欄位進行映射。
同行映射:源表和目標表的欄位名稱不一致,但欄位對應行的資料需要映射。只映射同行的欄位。
輸出目標表選擇為Hudi表
參數
描述
基本設定
步驟名稱
即Hive輸出組件的名稱。Dataphin自動產生步驟名稱,您也可以根據業務情境修改。命名規則如下:
只能包含中文、字母、底線(_)、數字。
不能超過64個字元。
資料來源
在資料來源下拉式清單中,展示所有Hive類型的資料來源,包括您已擁有同步寫入權限的資料來源和沒有同步寫入權限的資料來源。單擊
表徵圖,可複製當前資料來源名稱。對於沒有同步寫入權限的資料來源,您可以單擊資料來源後的申請,申請資料來源的同步寫入權限。具體操作,請參見申請資料來源許可權。
如果您還沒有Hive類型的資料來源,單擊建立資料來源,建立資料來源。具體操作,請參見建立Hive資料來源。
表
選擇輸出資料的目標表(Hudi表)。 可輸入表名關鍵字進行搜尋,或輸入準確表名後單擊精準尋找。選擇表後,系統將自動進行表狀態檢測。單擊
表徵圖,可複製當前所選表的表名稱。如果Hive資料來源中沒有資料同步的目標表,則您可以通過一鍵建表的功能,簡單快速地產生目標表。詳細操作步驟如下:
單擊一鍵建表。Dataphin會自動為您匹配建立目標表的代碼,包括目標表名稱(預設為來源表名)、欄位類型(基於Dataphin欄位做了初步的轉換)等資訊。
資料湖表格式選擇為Hudi。
Hudi表類型:可選擇MOR(merge on read)或COW(copy on write),預設為MOR(merge on read)。
主鍵欄位(非必填):輸入主鍵欄位,多個欄位間使用半形逗號(,)分隔。
擴充屬性(非必填):輸入Hudi官方支援的配置屬性,格式為
k=v。說明如果開發環境存在同名的表,單擊建立後,Dataphin會報已存在該表的錯誤。
沒有匹配項時,也支援根據手動輸入的表名進行整合。
執行引擎選擇為Hive或Spark。
說明僅當資料湖表格式選擇為Hudi時,支援選擇執行引擎。執行引擎預設為Hive,若所選資料來源已開啟Spark,則支援選擇Spark。
DDL根據所選的資料湖表格式以及執行引擎自動產生,您可在此基礎上進行修改,完成後單擊建立。
生產表缺失策略
生產表不存在時的處理策略,可選擇不處理或自動建立,預設為自動建立。若選擇不處理,則任務發布時不進行生產表建立;若選擇自動建立,則任務發布時在目標環境建立同名表。
不處理:若目標表不存在,則提交時會提示目標表不存在,但仍可正常發布。此時,使用者需自行在生產環境建立目標表,才可執行任務。
自動建立:需編輯建表語句,預設填充所選表的建表語句,使用者可進行調整。建表語句中的表名使用預留位置
${table_name},且僅支援填寫該預留位置,實際執行時將替換為真實表名。若目標表不存在,則先按照建表語句進行建表,若建表失敗,則發布時檢查結果為失敗,您可根據錯誤提示修改建表語句,修改完成後再次進行發布。若目標表已存在,則不執行建表。
說明僅Dev-Prod模式專案中支援配置此項。
分區
如果所選的目標表是分區表,那麼需要填寫分區資訊。例如,
state_date=20190101,也支援參數的方式以便每天增量寫入資料。例如,state_date=${bizdate}。載入策略
向目標資料來源(Hive資料來源)寫入資料時,資料寫入表中的策略,包括覆蓋資料、追加資料、更新資料。
覆蓋資料:使用新增資料覆蓋已有資料。
追加資料:直接向目標表追加寫入資料。
更新資料:按主鍵更新,不存在時則插入資料。
說明通過SQL等其他方式寫入的資料不會被刪除。
BulkInsert
適用於巨量資料量的批量快速同步情境,通常用於初始資料的匯入。
說明僅當載入策略選擇為追加策略或覆蓋策略時,支援配置此項,且預設為開啟。
分批寫入
通過分批的方式將資料寫入目標表,開啟後還需配置分批比例。
分批比例
占JVM總記憶體比例,預設為0.2,可填寫0.01~0.50之間的兩位小數。
Hadoop參數配置(非必填)
用於調整寫入參數,針對不同的表類型可以填寫不同的參數,多個參數間用英文逗號隔開(,),格式為
{"key1":"value1", "key2":"value2"}。可使用{"hoodie.parquet.compression.codec":"snappy"}參數將壓縮格式調整為snappy。欄位對應
輸入欄位
根據上遊組件的輸出,為您展示輸入欄位。
輸出欄位
輸出欄位地區展示了已選中表的所有欄位。
說明Hudi表無需映射所有欄位。
映射關係
根據上遊的輸入和目標表的欄位,可以手動選擇欄位對應。映射關係包括同行映射和同名映射。
同名映射:對欄位名稱相同的欄位進行映射。
同行映射:源表和目標表的欄位名稱不一致,但欄位對應行的資料需要映射。只映射同行的欄位。
輸出目標表為Paimon表
參數
描述
基本設定
步驟名稱
即Hive輸出組件的名稱。Dataphin自動產生步驟名稱,您也可以根據業務情境修改。命名規則如下:
只能包含中文、字母、底線(_)、數字。
不能超過64個字元。
資料來源
在資料來源下拉式清單中,展示所有Hive類型的資料來源,包括您已擁有同步寫入權限的資料來源和沒有同步寫入權限的資料來源。單擊
表徵圖,可複製當前資料來源名稱。對於沒有同步寫入權限的資料來源,您可以單擊資料來源後的申請,申請資料來源的同步寫入權限。具體操作,請參見申請資料來源許可權。
如果您還沒有Hive類型的資料來源,單擊建立資料來源,建立資料來源。具體操作,請參見建立Hive資料來源。
表
選擇輸出資料的目標表(Paimon表)。 可輸入表名關鍵字進行搜尋,或輸入準確表名後單擊精準尋找。選擇表後,系統將自動進行表狀態檢測。單擊
表徵圖,可複製當前所選表的表名稱。如果Hive資料來源中沒有資料同步的目標表,則您可以通過一鍵建表的功能,簡單快速的產生目標表。詳細操作步驟如下:
單擊一鍵建表。Dataphin會自動為您匹配建立目標表的代碼,包括目標表名稱(預設為來源表名)、欄位類型(基於Dataphin欄位做了初步的轉換)等資訊。
資料湖表格式選擇為不選擇、Iceberg或Paimon。
說明僅當所選資料來源或當前專案所使用的計算源開啟資料湖表格式,且選擇為Iceberg時,此處支援選擇Iceberg。
執行引擎選擇為Hive或Spark。
說明僅當資料湖表格式選擇為Iceberg或Paimon時,支援選擇執行引擎。若所選資料來源已配置Spark,則展示並預設選擇Spark;若未配置,則僅展示並選擇Hive。
Paimon表類型可選擇MOR(merge on read)、COW(copy on write)或MOW(merge on write),預設選擇MOR。
說明僅當資料湖表格式選擇為Paimon時,支援配置Paimon表類型。
DDL根據所選的資料湖表格式以及執行引擎自動產生,您可在此基礎上進行修改,完成後單擊建立。目標表建立成功後,Dataphin自動將建立的目標表作為輸出資料的目標表。
說明如果開發環境存在同名的表,單擊建立後,Dataphin會報已存在該表的錯誤。
沒有匹配項時,也支援根據手動輸入的表名進行整合。
生產表缺失策略
生產表不存在時的處理策略,可選擇不處理或自動建立,預設為自動建立。若選擇不處理,則任務發布時不進行生產表建立;若選擇自動建立,則任務發布時在目標環境建立同名表。
不處理:若目標表不存在,則提交時會提示目標表不存在,但仍可正常發布。此時,使用者需自行在生產環境建立目標表,才可執行任務。
自動建立:需編輯建表語句,預設填充所選表的建表語句,使用者可進行調整。建表語句中的表名使用預留位置
${table_name},且僅支援填寫該預留位置,實際執行時將替換為真實表名。若目標表不存在,則先按照建表語句進行建表,若建表失敗,則發布時檢查結果為失敗,您可根據錯誤提示修改建表語句,修改完成後再次進行發布。若目標表已存在,則不執行建表。
說明僅Dev-Prod模式專案中支援配置此項。
載入策略
向目標資料來源(Hive資料來源)寫入資料時,資料寫入表中的策略。載入策略包括追加資料、覆蓋資料、更新資料,適用情境說明如下:
追加資料:直接向目標表追加寫入資料。
覆蓋資料:使用新增資料覆蓋已有資料。
更新資料:按主鍵更新,不存在則插入。
NULL值替換(非必填)
僅支援
textfile資料存放區格式的來源表。填寫需要替換為NULL的字串。例如,填寫\N時,系統會將\N字串替換為NULL。欄位分隔符號(非必填)
僅支援
textfile資料存放區格式的來源表。填寫欄位之間分隔字元。如果您沒有填寫,則系統預設為使用\u0001作為分隔字元。欄位分隔符號處理(非必填)
僅支援
textfile資料存放區格式的輸出表。資料中存在預設或自行配置的欄位分隔符號時,可以配置欄位分隔符號處理策略,防止資料寫入錯誤。可以選擇保留、去除或替換為。行分隔字元處理(非必填)
僅支援
textfile資料存放區格式的輸出表。資料中存在預設或自行配置的欄位分隔符號時,可以配置行分隔字元號處理策略,預設以\n作為行分隔字元,如資料中存在分行符號\r、\n,可選擇處理策略,防止資料寫入錯誤。可以選擇保留、去除或替換為。Hadoop參數配置(非必填)
用於調整寫入參數,針對不同的表類型可以填寫不同的參數,多個參數間用英文逗號隔開(,),格式為
{"key1":"value1", "key2":"value2"}。例如:輸出表格式為orc且欄位較多的情境下可根據記憶體大小來調整{"hive.exec.orc.default.buffer.size"}參數,記憶體足夠時可嘗試調大該配置提高寫入效能,記憶體不足時可嘗試調小該配置減少GC時間提高寫入效能,預設為16384Byte(16KB),建議不超過262144Byte(256KB)。分區
如果所選的目標表是分區表,那麼需要填寫分區資訊。例如,
state_date=20190101,也支援參數的方式以便每天增量寫入資料。例如,state_date=${bizdate}。欄位對應
輸入欄位
根據上遊組件的輸出,為您展示輸入欄位。
輸出欄位
輸出欄位地區展示了已選中表的所有欄位。
重要為了保證資料寫入Hive時資料不會出錯,輸出欄位必須和輸入組件的欄位全部映射。
映射關係
根據上遊的輸入和目標表的欄位,可以手動選擇欄位對應。映射關係包括同行映射和同名映射。
同名映射:對欄位名稱相同的欄位進行映射。
同行映射:源表和目標表的欄位名稱不一致,但欄位對應行的資料需要映射。只映射同行的欄位。
單擊確認,完成Hive輸出組件的屬性配置。