通過建立Hive資料來源能夠實現Dataphin讀取Hive的業務資料或向Hive寫入資料。本文為您介紹如何建立Hive資料來源。
背景資訊
Hive是基於Hadoop的一個資料倉儲工具,可以將結構化的資料檔案映射為一張資料庫表,並提供SQL查詢功能。Hive用於轉化HQL或SQL語句為MapReduce、Tez等程式。如果您使用的是Hive,在對接Dataphin進行資料開發或將Dataphin的資料寫入至Hive的情境中,您需要先完成Hive資料來源的建立。
使用限制
在Aliyun E-MapReduce5.x Hadoop計算引擎下,若您需要使用基於OSS建立的Hive外部表格進行離線整合。您需要進行相關配置後才可以正常使用。配置說明,請參見使用基於OSS建立的Hive外部表格進行離線整合。
使用Hive資料來源作為整合的輸入輸出組件時,請確認Dataphin的IP地址已在Hive的網路白名單中,以確保Dataphin能夠訪問Hive中的資料。
請確保Dataphin的應用叢集與調度叢集與Hive服務、HDFS的NameNode(包括webUI、IPC)和DataNode、KDC Server、中繼資料庫或Hive Meta Store、Zookeeper的連通性。
許可權說明
僅支援具備建立資料來源許可權點的自訂全域角色和超級管理員、資料來源管理員、板塊架構師、專案系統管理員角色建立資料來源。
操作步驟
在Dataphin首頁頂部功能表列中,選擇管理中心 > 資料來源管理。
在資料來源頁面,單擊+建立資料來源。
在建立資料來源頁面的巨量資料儲存地區,選擇Hive。
如果您最近使用過Hive,也可以在最近使用地區選取項目Hive。同時,您也可以在搜尋方塊中,輸入Hive的關鍵詞,快速篩選。
在建立Hive資料來源頁面中,配置資料來源串連參數。
Hive資料來源配置參數中,整合配置是為了支援Data Integration,即時研發配置是為了支援即時研發的情境,而中繼資料庫配置是基礎的配置,用來擷取中繼資料。
說明通常情況下,生產資料來源和開發資料來源需配置為非同一個資料來源,以實現開發資料來源與生產資料來源的環境隔離,降低開發資料來源對生產資料來源的影響。但Dataphin也支援配置成同一個資料來源,即相同參數值。
Hive資料來源基本資料配置
參數
描述
資料來源名稱
填寫資料來源名稱。命名規則如下:
只能包含中文、英文字母大小寫、數字、底線(_)或短劃線(-)。
長度不能超過64個字元。
資料來源編碼
配置資料來源編碼後,您可以在Flink_SQL任務中通過
資料來源編碼.表名稱或資料來源編碼.schema.表名稱的格式引用資料來源中的表;如果需要根據所處環境自動訪問對應環境的資料來源,請通過${資料來源編碼}.table或${資料來源編碼}.schema.table的變數格式訪問。更多資訊,請參見Dataphin資料來源表開發方式。重要資料來源編碼配置成功後不支援修改。
資料來源編碼配置成功後,才能在資產目錄和資產清單的對象詳情頁面進行資料預覽。
Flink SQL中,目前僅支援MySQL、Hologres、MaxCompute、Oracle、StarRocks、Hive、SelectDB、GaussDB(DWS)資料來源。
版本
選擇Hive資料來源的版本。Dataphin支援以下版本:
CDH5.x Hive 1.1.0
Aliyun EMR3.x Hive 2.3.5
Aliyun EMR5.x Hive 3.1.x
CDH6.x Hive 2.1.1
FusionInsight 8.x Hive 3.1.0
CDP7.x Hive 3.1.3
亞信DP5.x Hive 3.1.0
Amazon EMR
資料來源描述
對資料來源的簡單描述,128個字元以內。
資料湖表格式
選擇開啟或關閉資料湖表格式,預設為關閉,開啟後可選擇表格式。
當版本選擇為CDP7.x Hive3.1.3時,表格式僅支援Hudi。
當版本選擇為Aliyun EMR5.x Hive3.1.x時,表格式可選擇Iceberg和Paimon。
說明僅當版本選擇為CDP7.x Hive3.1.3或Aliyun EMR5.x Hive3.1.x時,支援配置此項。
開啟模組
整合:開啟後,Hive資料來源可用於Data Integration。
即時研發:開啟後,Hive資料來源可用於即時研發。
說明CDH6.x Hive 2.1.1、CDP7.x Hive 3.1.3、亞信DP5.x Hive 3.1.0版本支援開啟即時研發。
版本選擇為Aliyun EMR5.x Hive3.1.x,且資料湖表格式選擇了Paimon時,支援開啟即時研發。
資料來源配置
選擇資料來源的配置環境:
如果業務資料來源區分生產資料來源和開發資料來源,則選擇生產+開發資料來源。
如果業務資料來源不區分生產資料來源和開發資料來源,則選擇生產資料來源。
標籤
您可根據標籤給資料來源進行分類打標,如何建立標籤,請參見管理資料來源標籤。
生產/開發資料來源配置
不同Hive版本所需配置的資料來源參數不同。
除Amazon EMR外的其他版本
Hive配置
中繼資料擷取方式:支援中繼資料庫、HMS、DLF三種來源資料擷取方式。擷取方式不同,所需配置資訊不同。
中繼資料庫
說明當開啟模組中僅選中即時研發時,中繼資料擷取方式僅支援中繼資料庫。
參數
說明
資料庫類型
請根據叢集中使用的中繼資料庫類型,選擇對應的資料庫類型。Dataphin支援選擇MySQL。MySQL資料庫類型支援MySQL 5.1.43、MySQL 5.6/5.7和MySQL 8版本。
JDBC URL
填寫目標資料庫的JDBC串連地址。串連地址格式為
jdbc:mysql://host:port/dbname。使用者名稱、密碼
填寫登入Hive的使用者名稱和密碼。
Hive JDBC URL
填寫Hive的JDBC串連地址。支援配置以下三種類型的串連地址:
Hive Server:串連地址格式為
jdbc:hive://host:port/dbname。ZooKeeper:例如
jdbc:hive2://zk01:2181,zk02:2181,zk03:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2。Hive已開啟Kerberos:串連地址格式為
jdbc:hive2://host:port/dbname;principal=hive/_HOST@xx.com。
說明當版本選擇為E-MapReduce3.x、E-MapReduce5.x、Cloudera Data Platform時,開啟Kerberos認證後,JDBC URL中不支援填寫多個IP地址。
HMS
參數
說明
認證方式
HMS擷取方式支援無認證、LDAP、Kerberos三種認證方式。Kerberos認證方式需上傳Keytab File檔案及配置Principal。
hive-site.xml
上傳Hive的hive-site.xml設定檔。
說明若開啟即時研發,則即時研發中也將複用該設定檔。
Hive JDBC URL
填寫Hive的JDBC串連地址。支援配置以下三種類型的串連地址:
Hive Server:串連地址格式為
jdbc:hive://host:port/dbname。ZooKeeper:例如
jdbc:hive2://zk01:2181,zk02:2181,zk03:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2。Hive已開啟Kerberos:串連地址格式為
jdbc:hive2://host:port/dbname;principal=hive/_HOST@xx.com。
DLF
說明僅Aliyun EMR5.x Hive 3.1.x版本支援DLF擷取方式。
參數
說明
Endpoint
填寫叢集在DLF資料中心所在地區的Endpoint。如何擷取,請參見DLF Region和Endpoint對照表。
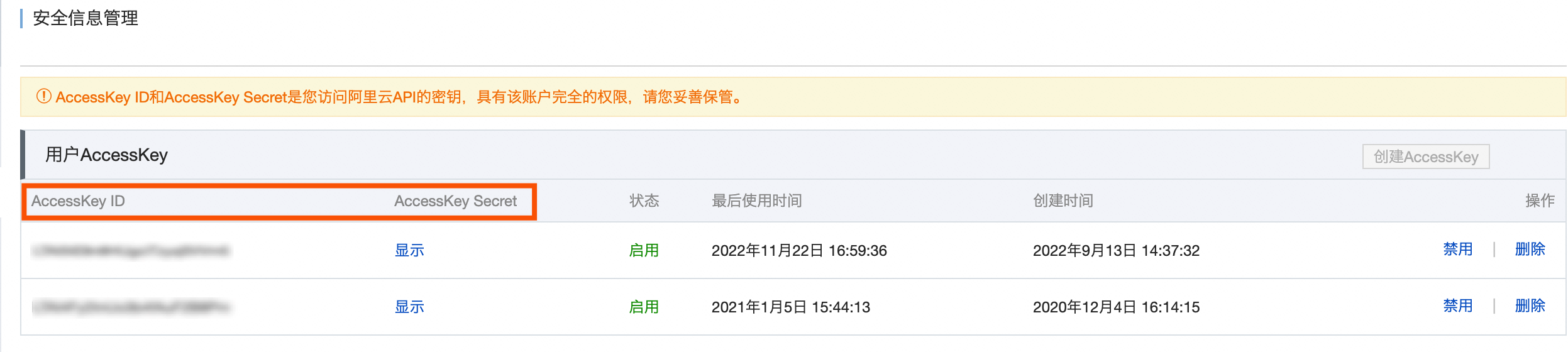
AccessKey ID、AccessKey Secret
填寫叢集所在帳號的AccessKey ID和AccessKey Secret。
您可在使用者資訊管理頁面,擷取帳號的AccessKey ID和AccessKey Secret。
hive-site.xml
上傳Hive的hive-site.xml設定檔。
說明若開啟即時研發,則即時研發中也將複用該設定檔。
Hive JDBC URL
填寫Hive的JDBC串連地址。支援配置以下三種類型的串連地址:
Hive Server:串連地址格式為
jdbc:hive://host:port/dbname。ZooKeeper:例如
jdbc:hive2://zk01:2181,zk02:2181,zk03:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2。Hive已開啟Kerberos:串連地址格式為
jdbc:hive2://host:port/dbname;principal=hive/_HOST@xx.com。
整合
說明開啟模組中選擇整合後,支援配置整合模組。
整合配置
支援HDFS、OSS-HDFS叢集儲存兩種方式。儲存方式不同,所需配置資訊不同。
HDFS
參數
描述
NameNode
NameNode是HDFS叢集中中繼資料的管理者,單擊新增,在新增NameNode對話方塊,配置NameNode節點資訊。
Web UI Port:訪問Hadoop叢集中各個組件的Web介面的連接埠。
IPC Port:處理序間通訊(IPC)的連接埠。
Web UI Port和IPC Port在CDH5環境下預設是
50070和8020,您可根據實際情況填寫對應的連接埠。說明Web UI Port和IPC Port其中一個填寫正確時,可以正常完成測試連接。
設定檔
上傳Hadoop的設定檔
hdfs-site.xml和core-site.xml,設定檔可在Hadoop叢集匯出。說明開啟資料湖表格式並選擇Hudi作為表格式後,若即時研發使用Hive資料來源並採用dp-hudi Connector,則還需上傳
hive-site.xml設定檔。開啟Kerberos
Kerberos是一種基於對稱金鑰技術的身份認證協議,可以為其他服務提供身份認證功能,且支援SSO(即用戶端身份認證後,可以訪問多個服務,例如HBase和HDFS)。
如果Hadoop叢集有Kerberos認證,則需要完成以下配置。
Kerberos配置方式
KDC Server:KDC伺服器位址,輔助完成Kerberos認證。
說明支援配置多個KDC Server服務地址,使用英文逗號(,)分隔。
Krb5檔案配置:需要上傳Krb5檔案進行Kerberos認證。
HDFS配置
HDFS Keytab File:上傳keytab認證檔案,您可以在HDFS Server上擷取keytab檔案。
HDFS Principal:填寫HDFS Keytab File檔案對應的Principal名,例如
xxx/hdfsclient@xxx.xxx。
Hive配置
JDBC URL:填寫Hive的JDBC串連地址。支援配置以下三種串連地址:
Hive Server的串連地址,格式為
jdbc:hive://host:port/dbname。ZooKeeper的串連地址。例如
jdbc:hive2://zk01:2181,zk02:2181,zk03:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2。開啟Kerberos的串連地址,格式為
jdbc:hive2://host:port/dbname;principal=hive/_HOST@xx.com。
說明當版本選擇為E-MapReduce3.x、E-MapReduce5.x、Cloudera Data Platform時,開啟Kerberos認證後,JDBC URL中不支援填寫多個IP地址。
Hive Keytab File:上傳keytab認證檔案,您可以在Hive Server上擷取keytab檔案。
Hive Principal:填寫Hive Keytab File檔案對應的Principal名,例如
xxx/hdfsclient@xxx.xxx。
關閉Kerberos
如果Hadoop叢集無Kerberos認證,則需要完成以下配置。
JDBC URL:填寫Hive的JDBC串連地址。支援配置以下三種串連地址:
Hive Server的串連地址,格式為
jdbc:hive://hodt:port/dbname。ZooKeeper的串連地址。例如
jdbc:hive2://zk01:2181,zk02:2181,zk03:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2。開啟Kerberos的串連地址,格式為
jdbc:hive2://host:port/dbname;principal=hive/_HOST@xx.com。說明當版本選擇為E-MapReduce3.x、E-MapReduce5.x、Cloudera Data Platform時,開啟Kerberos認證後,JDBC URL中不支援填寫多個IP地址。
使用者名稱、密碼:填寫登入Hive使用者名稱和密碼。
說明為保證任務正常運行,需確保所填寫的使用者有訪問Hive資料的許可權。
OSS-HDFS
說明僅Aliyun EMR5.x Hive3.1.x版本支援OSS-HDFS叢集儲存。
參數
描述
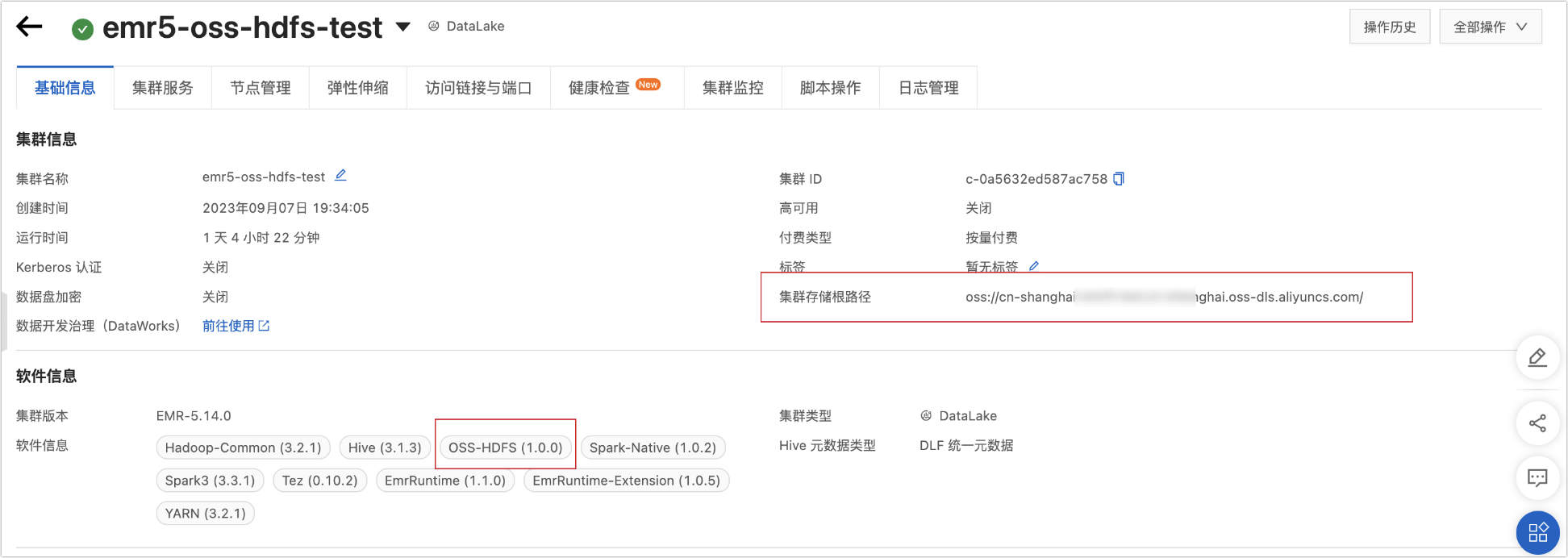
叢集儲存
可以通過以下方式查看叢集儲存類型。
未建立叢集:可以通過E-MapReduce5.x Hadoop叢集建立頁面查看所建立的叢集儲存類型。如下圖所示:

已建立叢集:可以通過E-MapReduce5.x Hadoop叢集的詳情頁查看所建立的叢集儲存類型。如下圖所示:
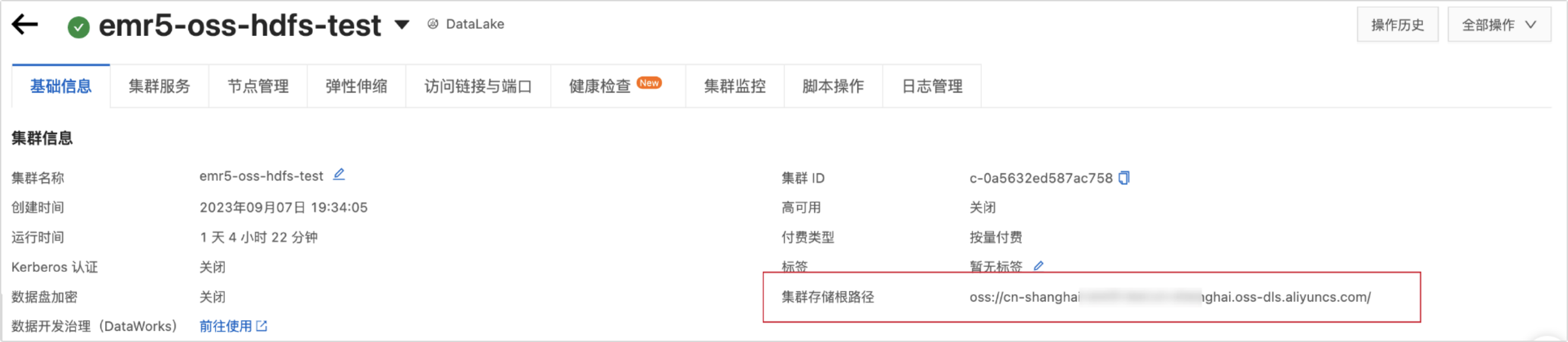
叢集儲存根目錄
填寫叢集儲存根目錄。可以通過查看E-MapReduce5.x Hadoop叢集資訊擷取進行。如下圖所示:
 重要
重要若填寫的路徑中包括Endpoint,則Dataphin預設使用該Endpoint;若不包含,則使用core-site.xml中配置的Bucket層級的Endpoint;若未配置Bucket層級的Endpoint,則使用core-site.xml中的全域Endpoint。更多資訊請參見阿里雲OSS-HDFS服務(JindoFS 服務)Endpoint配置。
設定檔
上傳叢集的
core-site.xml和hive-metastore-site.xml設定檔,設定檔可在Hadoop叢集匯出。AccessKey ID、AccessKey Secret
填寫訪問叢集OSS的AccessKey ID和AccessKey Secret。請使用已有AccessKey或者參考建立AccessKey重新建立。
重要此處填寫的配置優先順序高於core-site.xml中配置的AccessKey。
為降低AccessKey泄露的風險,AccessKey Secret只在建立時顯示一次,後續無法查看。請務必妥善保管。
開啟Kerberos
Kerberos是一種基於對稱金鑰技術的身份認證協議,可以為其他服務提供身份認證功能,且支援SSO(即用戶端身份認證後,可以訪問多個服務,例如HBase和HDFS)。
如果Hadoop叢集有Kerberos認證,則需要完成以下配置。
Kerberos配置方式
Krb5檔案配置:需要上傳Krb5檔案進行Kerberos認證。
Hive配置
JDBC URL:填寫Hive的JDBC串連地址。支援配置以下三種串連地址:
Hive Server的串連地址,格式為
jdbc:hive://host:port/dbname。ZooKeeper的串連地址。例如
jdbc:hive2://zk01:2181,zk02:2181,zk03:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2。開啟Kerberos的串連地址,格式為
jdbc:hive2://host:port/dbname;principal=hive/_HOST@xx.com。說明當版本選擇為E-MapReduce3.x、E-MapReduce5.x、Cloudera Data Platform時,開啟Kerberos認證後,JDBC URL中不支援填寫多個IP地址。
Hive Keytab File:上傳keytab認證檔案,您可以在Hive Server上擷取keytab檔案。
Hive Principal:填寫Hive Keytab File檔案對應的Principal名,例如
xxx/hdfsclient@xxx.xxx。
關閉Kerberos
如果Hadoop叢集無Kerberos認證,則需要完成以下配置。
JDBC URL:填寫Hive的JDBC串連地址。支援配置以下三種串連地址:
Hive Server的串連地址,格式為
jdbc:hive://hodt:port/dbname。ZooKeeper的串連地址。例如
jdbc:hive2://zk01:2181,zk02:2181,zk03:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2。開啟Kerberos的串連地址,格式為
jdbc:hive2://host:port/dbname;principal=hive/_HOST@xx.com。
使用者名稱、密碼:填寫登入Hive使用者名稱和密碼。
說明為保證任務正常運行,需確保所填寫的使用者有訪問Hive資料的許可權。
Spark配置
說明當版本選擇為CDP7.x Hive3.1.3,且資料湖表格式選擇Hudi時,支援Spark配置。
當版本選擇為Aliyun EMR5.x Hive3.1.x,且資料湖表格式選擇Iceberg或Paimon時,支援Spark配置。
參數
描述
Spark
可選擇開啟或關閉,預設為開啟,開啟後還需配置下方參數。
說明當資料湖表格式已選擇Paimon時,不支援關閉Spark。
服務類型
可選擇Kyuubi或Livy,預設為Kyuubi。
Spark JDBC URL
輸入JDBC串連地址,格式為
jdbc:hive2://{host}:{port}/{database name}。認證方式
可選擇無認證、LDAP或Kerberos。
使用者名稱、密碼
輸入鑒權使用者名稱和密碼,為保證任務正常執行,請確保該使用者擁有所需資料許可權。
說明當認證方式選擇為無認證時,需輸入使用者名稱;當認證方式選擇為LDAP時,需輸入使用者名稱和密碼。
Spark Keytab File
上傳keytab認證檔案,您可以在Spark Server上擷取keytab檔案。
說明當認證方式選擇為Kerberos時,支援配置此項。
Spark Principal
填寫Spark Keytab File檔案對應的Principal名,例如
xxx/hadooppclient@xxx.xxx。說明當認證方式選擇為Kerberos時,支援配置此項。
即時研發
說明僅CDH6.x Hive 2.1.1、CDP7.x Hive 3.1.3、亞信DP5.x Hive 3.1.0版本支援開啟即時研發。開啟模組中選擇即時研發時,支援配置即時研發模組。
設定檔:上傳hive-site.xml檔案。Flink SQL任務將忽略整合中的認證資訊,而使用Flink引擎的認證資訊訪問Hive資料來源。
Amazon EMR
參數
描述
主節點公有DNS
通過公有DNS擷取VPC私人DNS,Hive及 Spark均通過私人DNS串連,格式為
ec2-{public_ip}.{region}.compute.amazonaws.com。密鑰檔案(*pem)
訪問主節點ec2的金鑰組(建立EMR叢集時所設定的金鑰組)。
設定檔
可自行上傳相關叢集設定檔(core-site.xml、yarn-site.xml、hive-site.xml、hdfs-site.xml),或單擊擷取叢集配置(需先填寫主節點公有DNS並上傳密鑰檔案),從主節點下載相關檔案。
Database
填寫Amazon EMR計算引擎的Database名稱。
引擎類型
可選擇Hive或Spark,預設選擇Hive。選擇Hive後,還需輸入Hive JDBC URL;選擇Spark還需輸入 Spark JDBC URL。
Hive JDBC URL:輸入Hive的JDBC串連地址,或自動擷取串連地址(需先填寫主節點公有DNS並上傳密鑰檔案)。Hive JDBC URL格式為
jdbc:hive2//host1:port1,host2:post2/,無需填寫Database name。Spark JDBC URL:輸入Spark的JDBC串連地址,格式為
jdbc:hive2//{host:port}/{database name}。
使用者名稱
Hive或Spark的指定使用者名稱,此使用者名稱將設定為JDBC的
username。叢集儲存
當前僅可選擇HDFS。
中繼資料擷取方式
可選擇HMS或Amazon Glue。
HMS:預設選擇HMS。
Amazon Glue:選擇Amazon Glue後,還需配置Glue Region Code、Glue AccessKey ID、Glue AccessKey Secret。
Glue Region Code:輸入Amazon Glue的Region Code,例如ap-northeast-3,us-east-1,us-west-1。
Glue AccessKey ID、Glue AccessKey Secret:輸入Amazon Glue的訪問AccessKey ID和AccessKey Secret。
選擇預設資源群組,該資源群組用於運行與當前資料來源相關任務,包括資料庫SQL、離線整庫遷移、資料預覽等。
進行測試連接或直接單擊確定進行儲存,完成Hive資料來源的建立。
單擊測試連接,系統將測試資料來源是否可以和Dataphin進行正常的連通。若直接單擊確定,系統將自動對所有已選中的叢集進行測試連接,但即使所選中的叢集均串連失敗,資料來源依然可以正常建立。