Hive輸入組件用於讀取Hive資料來源的資料。同步Hive資料來源的資料至其他資料來源的情境中,您需要先配置Hive輸入組件讀取的資料來源,再配置資料同步的目標資料來源。本文為您介紹如何配置Hive輸入組件。
使用限制
Hive輸入組件支援資料格式為orc、parquet、text、rc、seq、iceberg(iceberg格式僅支援E-MapReduce5.x的Hive計算源或資料來源)的Hive資料表。不支援ORC格式的事務表、Kudu表整合。
Kudu表Data Integration請使用Impala輸入組件。更多資訊,請參見配置Impala輸入組件。
前提條件
已建立Hive資料來源。具體操作,請參見建立Hive資料來源。
進行Hive輸入組件屬性配置的帳號,需具備該資料來源的同步讀許可權。如果沒有許可權,則需要申請資料來源許可權。具體操作,請參見申請資料來源許可權。
操作步驟
在Dataphin首頁頂部功能表列,選擇研發 > Data Integration。
在整合頁面頂部功能表列選擇專案(Dev-Prod模式需要選擇環境)。
在左側導覽列中單擊離線整合,在離線整合列表中單擊需要開發的離線管道,開啟該離線管道的配置頁面。
單擊頁面右上方的組件庫,開啟組件庫面板。
在組件庫面板左側導覽列中需選擇輸入,在右側的輸入組件列表中找到Hive組件,並拖動該組件至畫布。
單擊Hive輸入組件卡片中的
 表徵圖,開啟Hive輸入配置對話方塊。
表徵圖,開啟Hive輸入配置對話方塊。在Hive輸入配置對話方塊中,配置參數。
參數
描述
步驟名稱
即Hive輸入組件的名稱。Dataphin自動產生步驟名稱,您也可以根據業務情境修改。命名規則如下:
只能包含中文、字母、底線(_)、數字。
不能超過64個字元。
資料來源
在資料來源下拉式清單中,展示所有Hive類型的資料來源,包括您已擁有同步讀許可權的資料來源和沒有同步讀許可權的資料來源。 單擊
 表徵圖,可複製當前資料來源名稱。
表徵圖,可複製當前資料來源名稱。對於沒有同步讀許可權的資料來源,您可以單擊資料來源後的申請,申請資料來源的同步讀許可權。具體操作,請參見申請資料來源許可權。
如果您還沒有Hive類型的資料來源,單擊建立資料來源,建立資料來源。具體操作,請參見建立Hive資料來源。
表
選擇資料同步的來源表。單擊
 表徵圖,可複製當前所選表的名稱。說明
表徵圖,可複製當前所選表的名稱。說明選擇的表為Hudi表或Paimon表時,僅支援配置分區。
分區
支援讀取靜態分區或定界分割,靜態分區如
ds=20230101或者ds1=2023,ds2=01;定界分割如/*query*/ds >=20230101 and ds <= 20230107。說明選擇的表為Hudi表或Paimon表時,不支援讀取定界分割。
分區不在時
可選擇以下策略,處理當指定分區不存在時的情境:
置任務失敗:終止該任務共置失敗。
置任務成功,無寫入資料:任務正常運行成功,目標表中不寫入資料。
檔案編碼
選擇讀取檔案的儲存在Hive的編碼方式。檔案編碼包括UTF-8和GBK。
NULL值替換
僅支援
textfile資料存放區格式的來源表。填寫需要替換為NULL的字串。例如,填寫\N時,系統會將\N字串替換為NULL。壓縮格式
非必填項,如果檔案有壓縮,請選擇對應的壓縮格式,以便Dataphin進行解壓處理。orc表預設選擇zlib格式,如需其他解壓格式需指定。其他格式表無預設格式。系統支援的壓縮格式包括zlib、hadoop-snappy、lz4、none。
欄位分隔符號
欄位分隔符號通常是在建立表時指定的。例如,使用
ROW FORMAT DELIMITED FIELDS TERMINATED BY語句定義。請填寫讀取表的欄位分割符,如果您沒有填寫分隔字元,則Dataphin預設為\u0001。輸出欄位
輸出欄位地區展示了已選中表及篩選條件命中的所有欄位。如果不需要將某些欄位輸出至下遊組件,則您可以刪除對應的欄位:
說明當計算引擎為Hadoop時,Hadoop輸入組件的輸出欄位支援查看欄位的分類分級,非Hadoop計算引擎則不支援。
單個刪除欄位情境:如果需要刪除少量的欄位,則可以單擊操作列下的
 表徵圖,刪除多餘的欄位。
表徵圖,刪除多餘的欄位。大量刪除欄位情境:如果需要刪除大批量欄位,則可以單擊欄位管理,在欄位管理對話方塊選擇多個欄位後,單擊
 左移動表徵圖,將已選的輸入欄位移入到未選的輸入欄位並單擊確定,完成欄位的大量刪除。
左移動表徵圖,將已選的輸入欄位移入到未選的輸入欄位並單擊確定,完成欄位的大量刪除。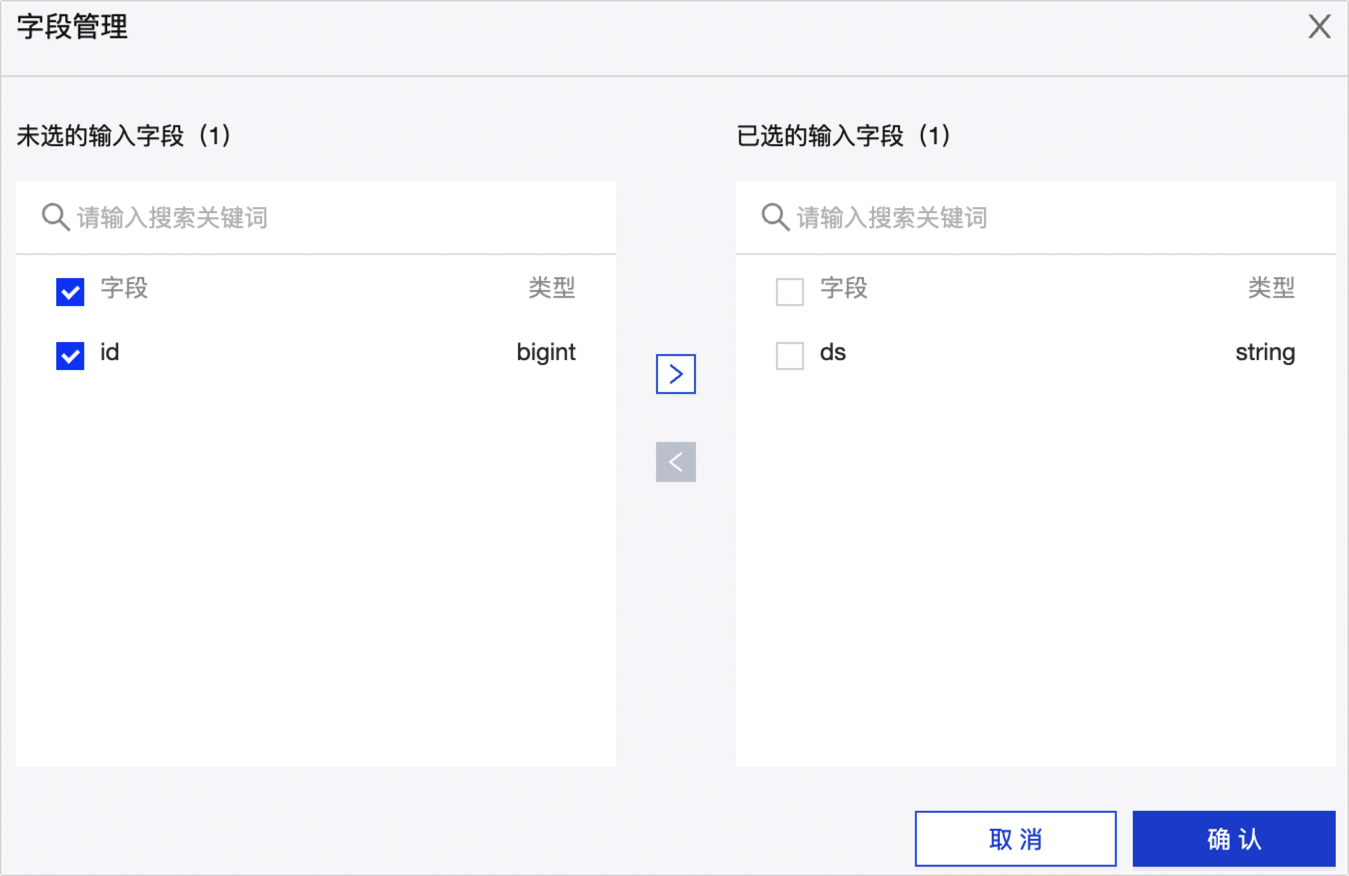
單擊確認,完成Hive輸入組件的屬性配置。