通過Gateway with Inference Extension組件,您可以在部署使用OpenAI API格式的產生式AI推理服務後,基於請求中的模型名稱指定請求路由策略,包括流量灰階、流量鏡像、流量熔斷等。本文介紹如何通過Gateway with Inference Extension組件實現基於模型名稱的推理服務路由。
閱讀本文前,請確保您已經瞭解InferencePool和InferenceModel的相關概念。
本文內容依賴1.4.0及以上版本的Gateway with Inference Extension。
背景資訊
OpenAI相容API
OpenAI相容API是指一類在介面、參數和響應格式上與OpenAI官方API(如GPT-3.5、GPT-4等)高度相容的產生式大語言模型(LLM)推理服務API。相容性通常體現在以下方面:
介面結構:使用相同的HTTP要求方法(如 POST)、端點格式和認證方式(如 API 金鑰)。
參數支援:支援與OpenAI API類似的參數,例如model、prompt、temperature、max_tokens等。
響應格式:返回與OpenAI相同的JSON結構,例如包含choices、usage和id欄位。
目前,主流的第三方LLM服務和vLLM、SgLang等主流LLM推理引擎均支援提供OpenAI相容API,以保持使用者在遷移和使用體驗上的一致性。
情境說明
對於產生式AI推理服務來說,使用者請求的模型名稱是請求中重要的中繼資料,基於請求中模型名稱進行路由策略的指定是通過網關暴露推理服務時的常見使用情境。但對於提供OpenAI相容API的LLM推理服務來說,請求的模型名稱資訊位於請求體中,而普通的路由策略並不支援基於請求體進行路由。
Gateway with Inference Extension支援在OpenAI相容API下基於模型名稱指定路由策略。通過解析並提取請求體中的模型名稱,並將其附加到要求標頭中,提供開箱即用的基於模型名稱的路由能力。使用時,只需要在HTTPRoute資源中,通過匹配X-Gateway-Model-Name要求標頭,即可實現基於模型名稱的路由能力、無需用戶端進行改造。
本文樣本將示範如何在同一個網關執行個體上,基於請求中的模型名稱對Qwen-2.5-7B-Instruct和DeepSeek-R1-Distill-Qwen-7B兩個推理服務進行路由:當請求qwen模型時,將請求路由到qwen推理服務;當請求deepseek-r1模型時,將請求路由到deepseek-r1服務。以下為路由的主要流程:
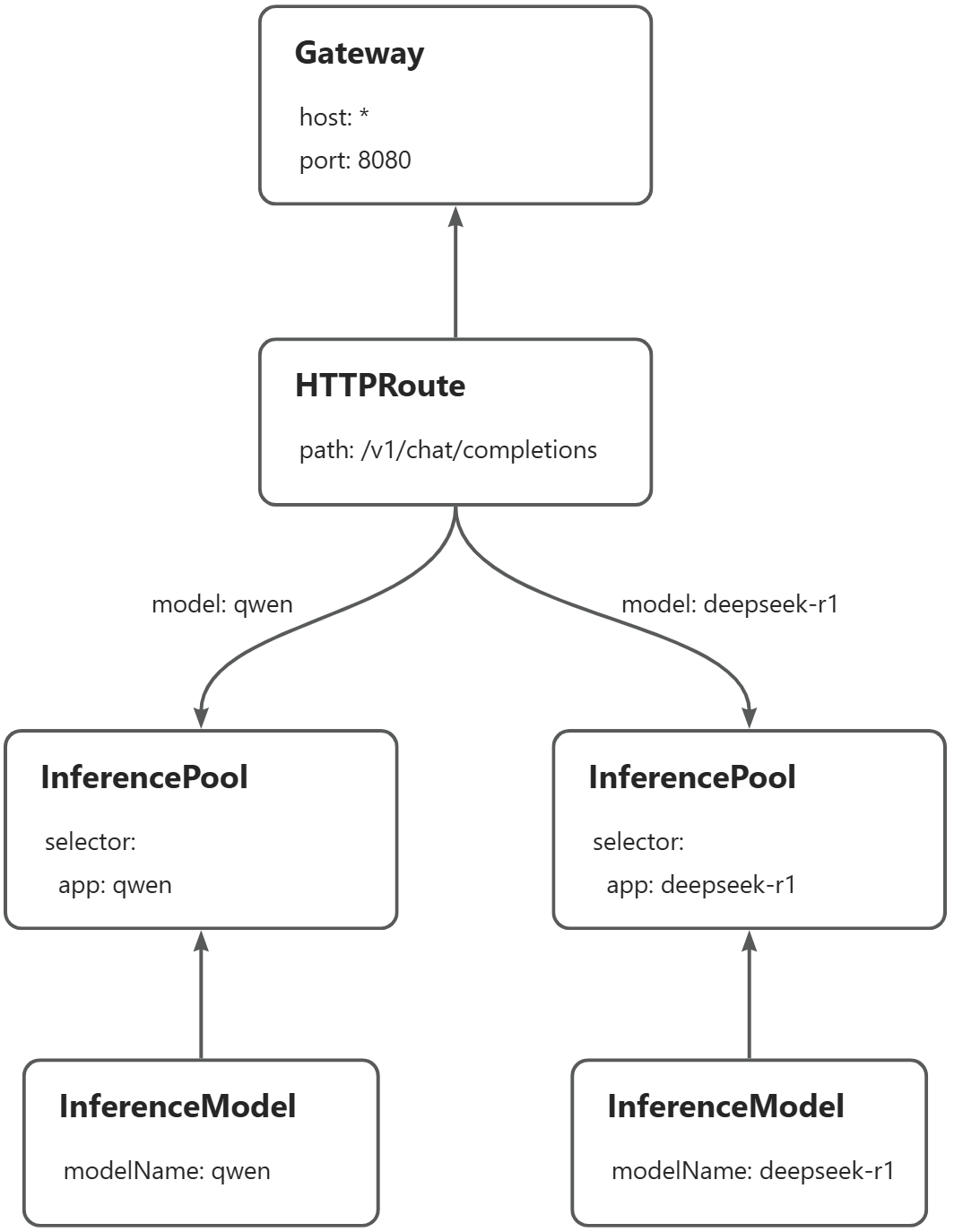
前提條件
已建立帶有GPU節點池的ACK託管叢集。您也可以在ACK託管叢集中安裝ACK Virtual Node組件,以使用ACS GPU算力。
已安裝1.4.0版本的Gateway with Inference ExtensionGateway with Inference Extension並勾選啟用Gateway API推理擴充。操作入口,請參見安裝組件。
操作步驟
步驟一:部署樣本推理服務
建立vllm-service.yaml。
部署樣本推理服務。
kubectl apply -f vllm-service.yaml
步驟二:部署推理路由
本步驟建立InferencePool資源和InferenceModel資源。
建立inference-pool.yaml。
apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferencePool metadata: name: qwen-pool namespace: default spec: extensionRef: group: "" kind: Service name: qwen-ext-proc selector: app: qwen targetPortNumber: 8000 --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceModel metadata: name: qwen spec: criticality: Critical modelName: qwen poolRef: group: inference.networking.x-k8s.io kind: InferencePool name: qwen-pool targetModels: - name: qwen weight: 100 --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferencePool metadata: name: deepseek-pool namespace: default spec: extensionRef: group: "" kind: Service name: deepseek-ext-proc selector: app: deepseek-r1 targetPortNumber: 8000 --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceModel metadata: name: deepseek-r1 spec: criticality: Critical modelName: deepseek-r1 poolRef: group: inference.networking.x-k8s.io kind: InferencePool name: deepseek-pool targetModels: - name: deepseek-r1 weight: 100部署推理路由。
kubectl apply -f inference-pool.yaml
步驟三:部署網關和網關路由規則
建立inference-gateway.yaml。
apiVersion: gateway.networking.k8s.io/v1 kind: GatewayClass metadata: name: inference-gateway spec: controllerName: gateway.envoyproxy.io/gatewayclass-controller --- apiVersion: gateway.networking.k8s.io/v1 kind: Gateway metadata: name: inference-gateway spec: gatewayClassName: inference-gateway listeners: - name: llm-gw protocol: HTTP port: 8080 --- apiVersion: gateway.envoyproxy.io/v1alpha1 kind: ClientTrafficPolicy metadata: name: client-buffer-limit spec: connection: bufferLimit: 20Mi targetRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway --- apiVersion: gateway.envoyproxy.io/v1alpha1 kind: BackendTrafficPolicy metadata: name: backend-timeout spec: timeout: http: requestTimeout: 24h targetRef: group: gateway.networking.k8s.io kind: Gateway name: inference-gateway建立inference-route.yaml
在
HTTPRoute指定的路由規則中,請求體中的模型名稱會被自動解析到X-Gateway-Model-Name要求標頭。apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: inference-route spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: inference-gateway sectionName: llm-gw rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: qwen-pool weight: 1 matches: - headers: - type: Exact name: X-Gateway-Model-Name value: qwen - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: deepseek-pool weight: 1 matches: - headers: - type: Exact name: X-Gateway-Model-Name value: deepseek-r1部署網關和網關規則。
kubectl apply -f inference-gateway.yaml kubectl apply -f inference-route.yaml
步驟四:驗證網關效果
擷取網關IP。
export GATEWAY_IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}')請求qwen模型。
curl -X POST ${GATEWAY_IP}:8080/v1/chat/completions -H 'Content-Type: application/json' -d '{ "model": "qwen", "temperature": 0, "messages": [ { "role": "user", "content": "who are you?" } ] }'預期輸出:
{"id":"chatcmpl-475bc88d-b71d-453f-8f8e-0601338e11a9","object":"chat.completion","created":1748311216,"model":"qwen","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"I am Qwen, a large language model created by Alibaba Cloud. I am here to assist you with any questions or conversations you might have! How can I help you today?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":33,"total_tokens":70,"completion_tokens":37,"prompt_tokens_details":null},"prompt_logprobs":null}請求deepseek-r1模型。
curl -X POST ${GATEWAY_IP}:8080/v1/chat/completions -H 'Content-Type: application/json' -d '{ "model": "deepseek-r1", "temperature": 0, "messages": [ { "role": "user", "content": "who are you?" } ] }'預期輸出:
{"id":"chatcmpl-9a143fc5-8826-46bc-96aa-c677d130aef9","object":"chat.completion","created":1748312185,"model":"deepseek-r1","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"Alright, someone just asked, \"who are you?\" Hmm, I need to explain who I am in a clear and friendly way. Let's see, I'm an AI created by DeepSeek, right? I don't have a physical form, so I don't have a \"name\" like you do. My purpose is to help with answering questions and providing information. I'm here to assist with a wide range of topics, from general knowledge to more specific inquiries. I understand that I can't do things like think or feel, but I'm here to make your day easier by offering helpful responses. So, I'll keep it simple and approachable, making sure to convey that I'm here to help with whatever they need.\n</think>\n\nI'm DeepSeek-R1-Lite-Preview, an AI assistant created by the Chinese company DeepSeek. I'm here to help you with answering questions, providing information, and offering suggestions. I don't have personal experiences or emotions, but I'm designed to make your interactions with me as helpful and pleasant as possible. How can I assist you today?","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":9,"total_tokens":232,"completion_tokens":223,"prompt_tokens_details":null},"prompt_logprobs":null}可以看到,兩個推理服務已經正常對外提供服務,外部請求可以根據請求名稱被路由到不同的推理服務。