AnalyticDB PostgreSQL版支援通過組合排序(適用於:查詢SQL的等值條件或範圍條件包含幾個固定列)或多維排序(適用於:查詢SQL包含的過濾條件不是固定的列)加速查詢。
背景資訊
您在建立表時,可以定義一個或多個列為排序鍵,當有資料寫入到表中,可以對該表按照排序鍵進行排序重組。
表排序後可以加速範圍過濾查詢,資料庫會對每固定行記錄每一列的min、max值。如果在查詢時使用範圍過濾條件,AnalyticDB PostgreSQL版的查詢引擎可以根據min、max值在對錶進行掃描(SCAN)時跳過不滿足過濾條件的資料區塊(Block)。
例如,一張表格儲存體了7年的資料,這張表的資料按照時間欄位排序儲存。如果您需要查詢一個月的資料,那麼只需要掃描 1/(7*12) 的資料,有98.8%的資料區塊在掃描時可以被過濾。但如果資料沒有按照時間排序的話,可能所有磁碟上的資料區塊都要被掃描。
AnalyticDB PostgreSQL版支援兩種排序方式:
組合排序(SORT):適用於過濾條件是排序鍵的首碼子集,例如查詢過濾條件包含首列排序鍵的情境。
多維排序(Multisort):給每一個排序鍵分配相同的權重,更適合於查詢條件包含任意過濾條件子集的情境。
如何選擇排序鍵
當您的查詢SQL的等值條件或範圍條件經常包含幾個固定列,可以考慮將這些列作為排序鍵,從而利用資料排序結合粗糙索引,加速這類SQL的查詢速度。一般情況下應該考慮使用組合排序。
當您的查詢SQL包含的過濾條件不是固定的列,可以使用多維排序來加速查詢。由於多維排序在排序過程中還需要進行一些額外的資料群組織工作,所以一般情況下多維排序的耗時會比組合排序的耗時更久。
說明多維排序最多支援8列。
當您的查詢SQL經常使用固定的列作為JOIN條件,可以將JOIN列同時設定為分布鍵和排序鍵,從而使用MergeJoin代替HashJoin,由於底層資料已經按照JOIN列排序,可以跳過MergeJoin耗時較高的排序階段。
組合排序和多維排序的效能對比
以下內容將對同樣的兩張表分別進行組合排序和多維排序,比較兩種排序方式在不同情境下對不同查詢的效能影響。
建立兩張測試表並設定表的排序鍵,表中包含4列,分別為id、num1、num2、value,其中id、num1、num2為排序鍵。語句如下:
CREATE TABLE test(id int, num1 int, num2 int, value varchar) with(APPENDONLY=TRUE, ORIENTATION=column) DISTRIBUTED BY(id) ORDER BY(id, num1, num2); CREATE TABLE test_multi(id int, num1 int, num2 int, value varchar) with(APPENDONLY=TRUE, ORIENTATION=column) DISTRIBUTED BY(id) ORDER BY(id, num1, num2);插入一千萬行測試資料,語句如下:
INSERT INTO test(id, num1, num2, value) select g, (random()*10000000)::int, (random()*10000000)::int, (array['foo', 'bar', 'baz', 'quux', 'boy', 'girl', 'mouse', 'child', 'phone'])[floor(random() * 10 +1)] FROM generate_series(1, 10000000) as g; INSERT INTO test_multi SELECT * FROM test;查詢兩張表中資料的總行數:
SELECT count(*) FROM test;返回資訊如下:
count ---------- 10000000 (1 row)SELECT count(*) FROM test_multi;返回資訊如下:
count ---------- 10000000 (1 row)
對兩張表分別進行組合排序和多維排序。
對test表進行組合排序:
SORT test;對test_multi表進行多維排序:
MULTISORT test_multi;等值查詢效能對比如下:
Q1查詢:過濾條件為首列排序鍵。
SELECT * FROM test WHERE id = 100000; SELECT * FROM test_multi WHERE id = 100000;Q2查詢:過濾條件為第二列排序鍵。
SELECT * FROM test WHERE num1 = 8766963; SELECT * FROM test_multi WHERE num1 = 8766963;Q3查詢:過濾條件為第二三列排序鍵。
SELECT * FROM test WHERE num1 = 100000 AND num2=2904114; SELECT * FROM test_multi WHERE num1 = 100000 AND num2=2904114;
效能對比結果如下:
排序模式
Q1
Q2
Q3
組合排序
0.026s
3.95s
4.21s
多維排序
0.55s
0.42s
0.071s
範圍查詢效能對比如下:
Q1查詢:過濾條件為首列排序鍵。
SELECT count(*) FROM test WHERE id>5000 AND id < 100000; SELECT count(*) FROM test_multi WHERE id>5000 AND id < 100000;Q2查詢:過濾條件為第二列排序鍵。
SELECT count(*) FROM test WHERE num1 >5000 AND num1 <100000; SELECT count(*) FROM test_multi WHERE num1 >5000 AND num1 <100000;Q3查詢:過濾條件為第二三列排序鍵。
SELECT count(*) FROM test WHERE num1 >5000 AND num1 <100000 AND num2 < 100000; SELECT count(*) FROM test_multi WHERE num1 >5000 AND num1 <100000 AND num2 < 100000;
效能對比結果:
排序方式
Q1
Q2
Q3
組合排序
0.07s
3.35s
3.64s
多維排序
0.44s
0.28s
0.047s
結論如下:
對於Q1查詢情境,由於包含排序鍵的首列,所以組合排序的效果較好,而多維排序則會相對效能弱一些。
對於Q2查詢情境,由於不包含排序鍵的首列,組合排序基本上失效了,而多維排序依然能維持比較穩定的效能提升。
對於Q3查詢情境,由於不包含排序鍵的首列,組合排序依然起不到很好的效果,並且由於比較條件的增加,需要額外的比較開銷,時間更長。而多維排序表現出更好的效能,這是因為在查詢時,過濾條件包含的多維排序鍵越多,效能越好。
排序加速計算
當您執行SORT <tablename>後,系統會對錶資料進行排序,當資料完成排序後,AnalyticDB PostgreSQL版即可利用資料的物理順序,將SORT運算元下推到儲存層進行計算加速。如果您的SQL可以利用底層的資料順序,則會從中獲得加速收益,該特性可以基於排序鍵加速SORT、AGG、JOIN運算元。
排序加速計算功能需要資料完全有序,當您寫入資料後需要重新執行
SORT <tablename>對資料進行排序。排序加速計算功能預設開啟。
以下樣本將在測試表far中執行同樣的查詢語句,對比排序加速前與排序加速後查詢時間的差距。
建立測試表far,語句如下:
CREATE TABLE far(a int, b int) WITH (APPENDONLY=TRUE, COMPRESSTYPE=ZSTD, COMPRESSLEVEL=5) DISTRIBUTED BY (a) --分布鍵 ORDER BY (a); --排序鍵寫入一百萬行資料,語句如下:
INSERT INTO far VALUES(generate_series(0, 1000000), 1);資料匯入完成後,對資料進行排序,語句如下:
SORT far;
查詢效能對比如下:
當前樣本的查詢時間僅供參考。查詢時間受到資料量、計算資源、網路狀況等多個因素影響,請以實際為準。
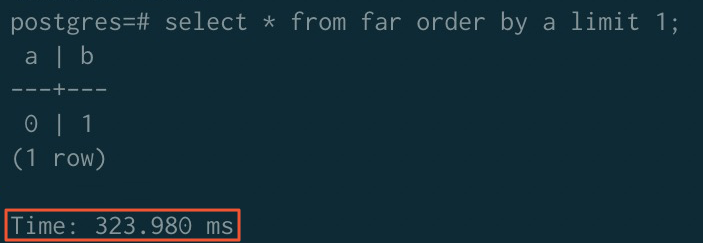
ORDER BY加速
排序加速前(未排序)
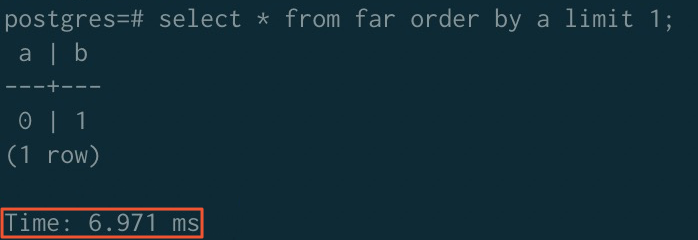
排序加速後
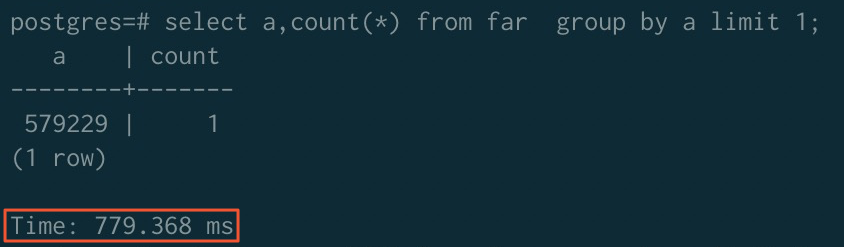
GROUP BY加速
排序加速前(未排序)
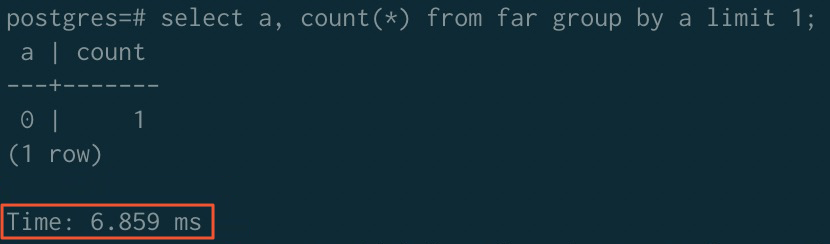
排序加速後
JOIN加速
排序加速前(未排序)
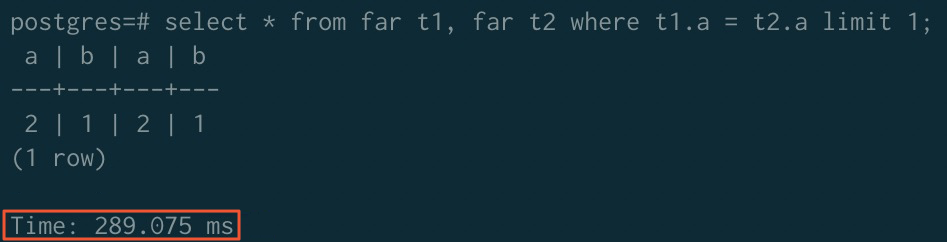
排序加速後
說明JOIN排序加速需要關閉ORCA功能,開啟mergejoin功能,語句如下:
SET enable_mergejoin TO on; SET optimizer TO off;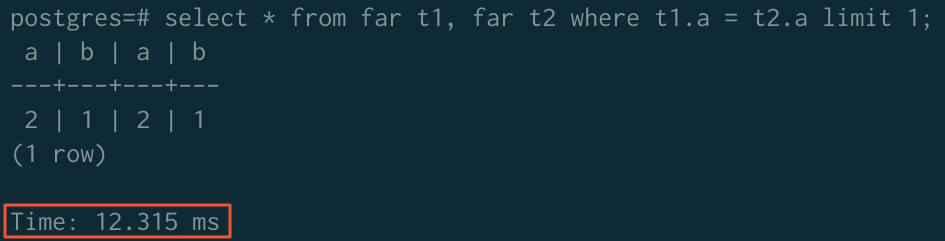
- | ORDER BY | GROUP BY | JOIN |
加速前 | 323.980 ms | 779.368 ms | 289.075 ms |
加速後 | 6.971 ms | 6.859 ms | 12.315 ms |