AnalyticDB Ray是AnalyticDB for MySQL推出的全託管Ray服務。該服務在開源Ray的基礎上進行了最佳化與增強,提升了核心效能並簡化了營運管理。AnalyticDB Ray主要適用於多模態處理、搜尋推薦、金融風控等複雜 AI 情境,旨在助力企業高效構建 Data + AI一體化架構,實現AI應用的規模化落地。
前提條件
叢集的產品系列為企業版、基礎版或湖倉版。
什麼是AnalyticDB Ray
開源 Ray 是一款專為 AI 與高效能運算設計的分散式運算架構,通過簡潔的 API 抽象實現高效的分布式調度,使用者僅需幾行代碼,即可將單機任務擴充至千節點叢集,能夠像調用本地函數一樣調度遠端資源。其內建模組(如Ray Tune、Ray Train和Ray Serve)與TensorFlow、PyTorch等無縫相容。在活躍的開源社區和Anyscale等企業的推動下,Ray已成為構建 AI 應用的重要工具。
儘管開源 Ray 提供了高度靈活的分散式運算能力,但在實際生產環境中,企業仍面臨分布式作業最佳化、資源精細化調度、叢集營運複雜以及系統穩定性與高可用性保障等挑戰。
為解決上述挑戰,AnalyticDB for MySQL推出全託管Ray服務——AnalyticDB Ray(下文簡稱ADB Ray)。ADB Ray基於開源Ray的豐富生態,通過多模態處理、具身智能、搜尋推薦、金融風控等典型情境的驗證,對Ray核心和服務能力進行了全面增強,最佳化了核心效能,簡化了叢集營運,並與AnalyticDB for MySQL湖倉平台無縫整合,助力企業構建Data + AI一體化架構,加速企業AI的規模化落地。
費用說明
建立Ray Cluster資源群組,會產生如下費用:
Worker磁盘空间會按照設定的儲存空間大小計費。
Worker资源类型為CPU時,會按照所使用ACU彈性資源群組計費。
Worker资源类型為GPU時,會按照GPU的規格、數量計費。
注意事項
Worker節點刪除、重啟會造成如下影響,建議在業務低峰期變更Ray Cluster資源群組的Worker配置,避免將作業調度至需要重啟的Worker節點上,以防止出現非預期的資料丟失和作業失敗的情況。
運行在Worker節點上的Driver、Actor和Task會失敗,但Ray會自動重新下發Actor和Task。
Ray分布式Object Storage Service中的資料丟失,如果有其他Task依賴重啟Worker上的資料,Task也會失敗。
資源群組變更:
刪除資源群組:如果有正在啟動並執行任務,刪除資源群組將導致該資源群組中啟動並執行任務中斷。
刪除Worker Group:刪除Ray Cluster資源群組中的Worker Group時,會導致Worker節點刪除。Worker節點刪除造成的影響,請參見Worker節點刪除的影響。
變更Worker個數:若變更後的Worker最大個數小於變更前的最小Worker個數,會導致Worker節點被刪除。Worker節點刪除造成的影響,請參見Worker節點刪除的影響。
變更其他配置:除最小Worker個數和最大Worker個數參數之外,其他的參數變更(例如:Head資源規格、Worker資源類型)都會導致Head節點或相應Worker Group中的Worker節點重啟。Worker節點重啟造成的影響,請參見Worker節點重啟的影響。
自動擴容:
Ray Cluster的擴容依賴於邏輯資源需求,而非實體資源利用率。因此,即使實體資源利用率很低,Ray Cluster也可能觸發自動擴容。
某些第三方應用程式會儘可能建立更多的Task以充分利用資源。在允許自動擴縮的情況下,會建立大量的Task,使得Ray快速地擴容到最大規模。因此,在運行第三方程式時,請瞭解其建立Task的內在邏輯,以避免產生額外的資源消耗。
容災機制:ADB Ray中配置了Redis容災機制,確保在Head節點重啟時,Ray Cluster狀態、Actor狀態和Task狀態均能夠恢複。
建立Ray服務
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊集群清單,然後單擊目的地組群ID。
在左側導覽列,單擊集群管理>資源管理,單擊資源組管理頁簽。然後在資源群組列表的右上方,單擊新增資源組。
為資源群組命名,選擇任務類型為AI,配置如下參數:
參數名稱
說明
部署類型
選擇RayCluster。
Head资源规格
Head負責管理Ray中繼資料、運行GCS服務(Global Control Store)、參與Task調度,但不執行Task。
Head資源規格即CPU核心數,可選擇small、m.xlarge、m.2xlarge等規格,各個規格所對應的CPU核心數與Spark資源規格一致,詳情請參見Spark資源規格列表。
重要Head主要負責為作業調度,請參照Ray Cluster的整體規模選擇Head規格。
Worker Group名称
Worker Group的名稱,您可以自訂。一個AI資源群組中可以配置多個不同名的Woker Group。
Worker资源类型
支援CPU和GPU兩種類型。
若您的業務涉及日常計算任務、多任務處理或複雜的邏輯運算建議您選擇CPU。
若您的業務涉及大量資料平行處理、機器學習或深度學習訓練建議您選擇GPU。
Worker资源规格
若Worker资源类型為CPU,Woker資源規格可選擇small、m.xlarge、m.2xlarge等規格,各個規格所對應的CPU核心數與Spark資源規格一致,詳情請參見Spark資源規格列表。
若Worker资源类型為GPU,由於涉及到GPU機型、庫存等問題,請提交工單聯絡支援人員協助選型。
Worker磁盘空间
磁碟空間主要用於儲存Ray日誌、臨時資料以及Ray分布式Object Storage Service的溢出資料。單位:GB,取值範圍是[30,2000]。預設100GB。
重要磁碟僅作為臨時儲存空間,請勿將其用作長期資料存放區。
最小Worker个数
最大Worker个数
最小Worker个数:一個Worker Group中至少需要啟動並執行Woker個數,最小為1。
最大Worker个数:一個Worker Group中最多需要啟動並執行Woker個數,最大為8。
Worker Group支援自動彈性,且每個Worker Group都能獨立彈性。當最小Woker個數和最大Woker個數不同時,AnalyticDB for MySQL會根據任務的Task個數在最小Woker個數和最大Woker個數之間動態地擴縮容Woker個數。若存在多個Worker Group,將會自動進行首選,從而避免單個Worker Group過載或閑置的情況。
分配单元
單個Worker節點上分配多少張GPU。例如配置單位為1/3,則表示每個Worker節點配置1/3張GPU。
重要僅Worker资源类型為GPU時,填寫該參數。
單擊確定。
串連並使用Ray服務
步驟一:擷取串連地址
在左側導覽列,單擊,單擊資源群組管理頁簽。
單擊對應資源群組操作列的,查看串連地址。
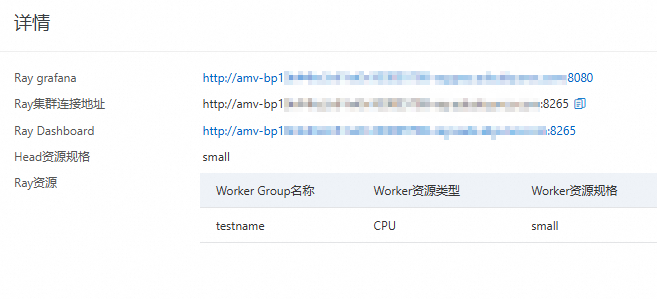
Ray grafana:Grafana視覺化檢視串連地址,單擊可跳轉至Grafana可視化頁面。
Ray叢集連結地址:內網串連地址。
Ray Dashboard:公網串連地址、Dashboard地址。單擊可跳轉至Ray可視化介面,可查看Ray Cluster資源群組狀態和作業狀態。
步驟二:提交作業
前提條件
已安裝Python環境,且Python版本為3.7及以上版本。
操作步驟
支援以下兩種方式提交作業:
通過CTL提交作業(推薦):使用CTL將指令檔打包上傳到Ray Cluster執行。入口程式在Ray Cluster中執行,需要消耗Ray Cluster資源群組的資源。
使用ray.init串連Ray Cluster執行作業:使用ray.init串連Ray Cluster,入口程式在本地執行,不消耗Ray Cluster資源群組的資源。且需要本地Ray版本Python版本與Ray Cluster版本一致,Ray Cluster版本變更時需要同步變更本地環境配置。
通過CTL提交作業
執行以下命令,安裝Ray。
pip3 install ray[default](可選)配置環境變數。
說明您可以配置全域環境變數來指定串連地址,或在提交作業時指定串連地址。
export RAY_ADDRESS="RAY_URL"參數說明:
RAY_URL:Ray串連地址。請填寫步驟一擷取的串連地址。提交作業。
重要提交作業時,系統會將
working-dir參數指定目錄下的所有檔案打包上傳至ray head執行。因此您需注意:working-dir參數指定的目錄盡量精簡,否則檔案過大可能導致上傳失敗。所有依賴的指令檔需全部放置在
working-dir參數指定目錄下,否則可能因缺少依賴檔案而無法執行。
若您已配置環境變數,請執行以下語句提交作業。
ray job submit --working-dir your_working_directory -- python your_python.py參數說明:
your_working_directory:指令檔所在的路徑。本文樣本指令檔路徑為/root/Ray。your_python.py:指令檔。本文樣本指令檔為scripts.py。
樣本:
ray job submit --working-dir /root/Ray -- python scripts.py若您未配置環境變數,請執行以下語句提交作業。
ray job submit --address ray_url --working-dir your_working_directory -- python your_python.py參數說明:
ray_url:Ray串連地址。請填寫步驟一擷取的串連地址。your_working_directory:指令檔所在的路徑。your_python.py:指令檔。本樣本指令檔為scripts.py。
樣本:
ray job submit --address http://amv-uf64gwe14****-rayo.ads.aliyuncs.com:8265 --working-dir /root/Ray -- python scripts.py
查詢作業運行狀態。
您可以通過如下兩種方式查看作業運行狀態:
通過命令查看:
ray job list通過可視化介面查看:
在資源群組管理頁面。單擊對應資源群組操作列的。
單擊Ray Dashboard地址進入可視化介面。
使用ray.init串連Ray Cluster執行作業
執行以下命令,安裝Ray。
pip3 install ray(可選)配置全域環境變數。
說明您可以配置全域環境變數來指定串連地址,或在指令檔中指定串連地址。
export RAY_ADDRESS="RAY_URL"參數說明:
RAY_URL:Ray串連地址。步驟一擷取的串連地址為dashboard地址,連接埠為8265,通過ray.init()串連ray時,需要將連接埠替換為10001、將協議替換為ray。例如,步驟一擷取的dashboard地址為
http://amv-uf64gwe14****-rayo.ads.aliyuncs.com:8265,此處需要替換為ray://amv-uf64gwe14****-rayo.ads.aliyuncs.com:10001。運行程式。
若您已配置全域環境變數,請執行以下命令運行程式。
python scripts.py若您未配置全域環境變數,請執行以下命令運行程式。
修改指令檔,指定串連地址。
ray.init(address="RAY_URL")參數說明:
RAY_URL:Ray串連地址。步驟一擷取的串連地址為dashboard地址,連接埠為8265,通過ray.init()串連ray時,需要將連接埠替換為10001、將協議替換為ray。例如,步驟一擷取的dashboard地址為
http://amv-uf64gwe14****-rayo.ads.aliyuncs.com:8265,此處需要替換為ray://amv-uf64gwe14****-rayo.ads.aliyuncs.com:10001。重要如果ray串連地址配置不正確,ray.init()將會啟動一個本地叢集執行程式。請注意查看輸出日誌以確定正確串連到ray叢集。
執行如下命令運行程式:
python scripts.py