本文介紹如何通過AnalyticDB for MySQLSpark和OSS構建、開放湖倉,並為您示範部署資源、資料準備、資料匯入、互動式分析以及任務調度的完整流程。
準備工作
部署資源
本教程將以OSS、MongoDB、RDS SQL Server和Azure Blob Storage四種資料來源為例,詳細介紹資料匯入的流程。如果您僅希望體驗某個特定資源的完整流程,您只需部署該資源即可,MongoDB、RDS SQL Server和Azure Blob Storage資料匯入時,需要依賴相關Jar包,且Jar包需上傳至OSS,因此還需部署OSS資源。
AnalyticDB for MySQL
AnalyticDB for MySQL叢集的產品系列為企業版、基礎版或湖倉版。
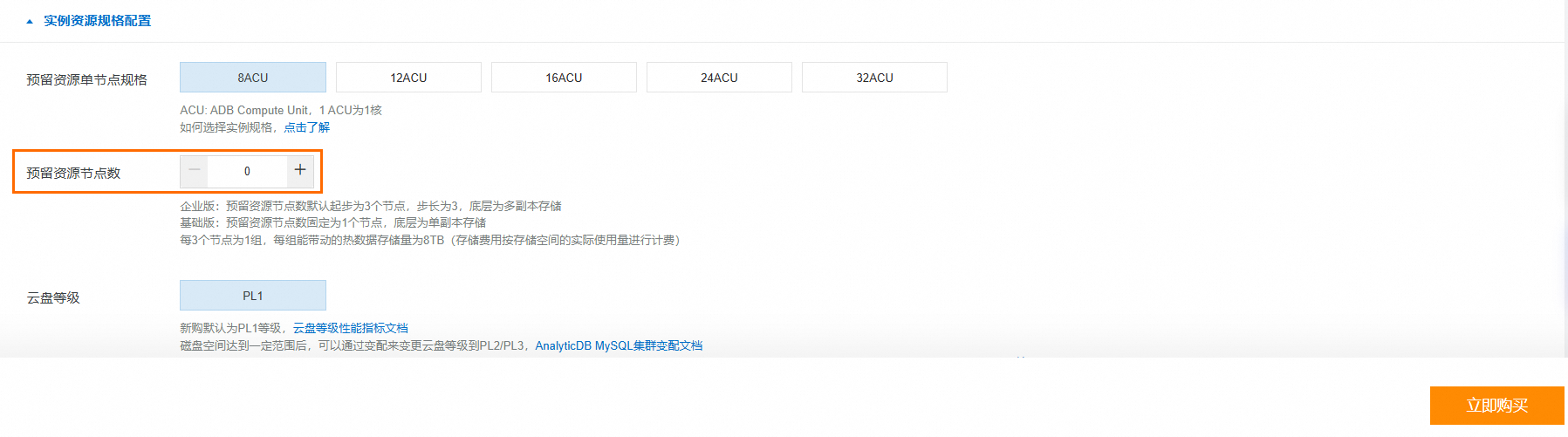
若您沒有符合上述條件的叢集,可以登入雲原生資料倉儲AnalyticDB MySQL控制台建立企業版或基礎版叢集。本教程僅涉及讀取外表資料,因此建立叢集時可將預留資源節點設定為0(如下圖)。具體操作,請參見建立叢集。
建立資料庫帳號。
如果是通過阿里雲帳號訪問,只需建立高許可權帳號。
如果是通過RAM使用者訪問,需要建立高許可權帳號和普通帳號、授予普通帳號相應的庫表許可權並將RAM使用者綁定到普通帳號上。

建立Job型資源群組和Spark引擎Interactive型資源群組。

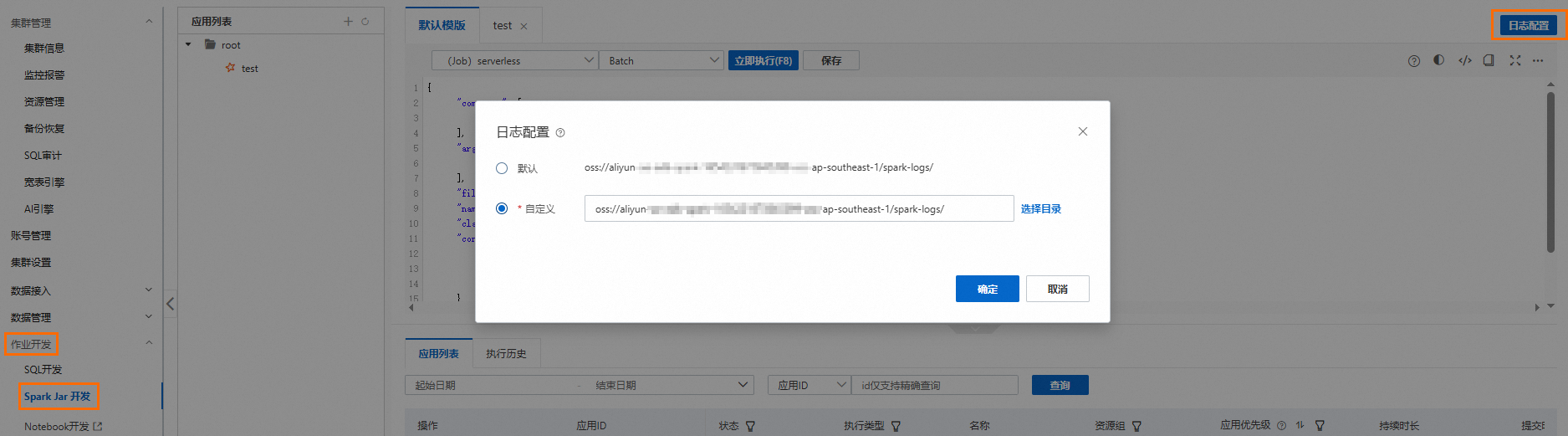
已配置Spark應用的日誌儲存地址。
登入雲原生資料倉儲AnalyticDB MySQL控制台,在頁面,單擊日誌配置,選擇預設路徑或自訂儲存路徑。自訂儲存路徑時不能將日誌儲存在OSS的根目錄下,請確保該路徑中至少包含一層檔案夾。
如果您需要使用RAM使用者登入控制台進行Spark作業開發,需要完成為RAM使用者授權。
使用Job型資源群組或Spark Interactive型資源群組,建立名為
test_db的資料庫,並指定OSS路徑,該資料庫下的所有表的資料存放區在該路徑下。CREATE DATABASE IF NOT exists test_db COMMENT 'demo database for lakehouse' LOCATION 'oss://testBucketName/test';
OSS
MongoDB(可選)
建立MongoDB執行個體,且MongoDB執行個體與AnalyticDB for MySQL叢集所屬同一交換器。
將交換器IP添加到MongoDB執行個體的白名單中。
在ApsaraDB for MongoDB控制台的基本資料頁面查看交換器ID。登入專用網路管理主控台,查看目標交換器的IP。
RDS SQL Server(可選)
建立RDS SQL Server執行個體,且RDS SQL Server執行個體與AnalyticDB for MySQL叢集所屬同一交換器。
將交換器IP添加到RDS SQL Server執行個體的白名單中。
在RDS SQL Server控制台的基本資料頁面查看交換器ID。登入專用網路管理主控台,查看目標交換器的IP。
Azure Blob Storage(可選)
產生樣本資料
OSS和Azure Blob Storage樣本資料
使用如下代碼批量產生1萬條資料,資料格式為Parquet。資料產生後,並將其分別儲存在OSS儲存空間或者Azure Blob Storage容器中。
import numpy as np
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
from faker import Faker
# 初始化Faker用於產生隨機資料
fake = Faker()
# 產生100,000行資料
def generate_data(num_rows=100000):
data = {
'id': np.arange(1, num_rows + 1),
'name': [fake.name() for _ in range(num_rows)],
'age': [np.random.randint(18, 80) for _ in range(num_rows)]
}
return pd.DataFrame(data)
# 產生DataFrame
df = generate_data()
# 顯式定義PyArrow Schema,限制整數長度
schema = pa.schema([
('id', pa.int32()), # 將id列限制為int32
('name', pa.string()),
('age', pa.int32()) # 將age列限制為int32
])
# 轉換Pandas DataFrame為PyArrow Table,並應用顯式Schema
table = pa.Table.from_pandas(df, schema=schema)
# 寫入Parquet檔案,指定Snappy壓縮
output_file = "test_tbl.parquet"
pq.write_table(table, output_file, compression='snappy')
print(f"Parquet 檔案已成功寫入:{output_file}")
print(f"已產生 {output_file},共 {len(df)} 行資料,使用 Snappy 壓縮。")MongoDB樣本資料
該樣本為某個電子銀行交易情境的範例資料產生指令碼,可以動態類比交易並將資料寫入MongoDB執行個體。
串連MongoDB執行個體,建立名為
test的資料庫,並在該資料庫中建立名為TransactionRecord的集合。使用如下代碼在
TransactionRecord的集合中隨機產生測試資料。from pymongo import MongoClient from datetime import datetime, timedelta import uuid import random import string import urllib.parse from faker import Faker fake = Faker() # Connect to MongoDB instance and create database/collection def connect_mongodb(uri,db_name,collection_name): try: # Connect to local MongoDB instance client = MongoClient(uri) # Create/Select database and collection db = client[db_name] # Check if collection exists and handle accordingly if collection_name not in db.list_collection_names(): # Collection doesn't exist, create it db.create_collection(collection_name) # Get the collection collection = db[collection_name] return client, db, collection except Exception as e: print(f"Connection failed: {e}") return None, None, None # Generate the username def generate_chinese_name(): surnames = ["李", "王", "張", "劉", "陳", "楊", "黃", "趙", "周", "吳", "徐", "孫", "馬", "朱"] names = ["偉", "芳", "娜", "秀英", "敏", "靜", "麗", "強", "磊", "軍", "洋", "勇", "豔", "傑", "娟", "濤", "明", "超", "秀蘭", "霞"] return random.choice(surnames) + random.choice(names) # Generate th bank account name def generate_bank_account(): return ''.join(random.choice(string.digits) for _ in range(16)) # 產生隨機的交易資料 def insert_transaction(collection, count=1): transaction_ids = [] # 定義可能的值列表 financial_institutions = ["中國銀行", "工商銀行", "建設銀行", "農業銀行", "招商銀行", "交通銀行"] main_channels = ["APP", "Web", "ATM", "Branch", "Phone"] sub_channels = ["Bank Transfer", "Third-party Payment", "Cash", "Check", "Direct Debit"] operation_types = ["Deposit", "Withdrawal", "Transfer", "Payment", "Loan"] digital_wallet_types = ["Alipay", "WeChat Pay", "UnionPay", "Apple Pay", "Samsung Pay", "None"] source_operations = ["User ID", "System Auto", "Admin", "API"] offer_categories = ["Cash Back", "Bonus", "Discount", "Loan", "Investment"] item_types = ["Deposit", "Investment", "Loan", "Insurance", "Fund"] prefixes = ["TX", "PAY", "DEP", "WD", "TR"] for _ in range(count): # 產生姓名 local_name = generate_chinese_name() english_first_name = fake.first_name() english_last_name = fake.last_name() # 產生交易金額和餘額變化 transaction_value = round(random.uniform(100, 10000), 2) pre_balance = round(random.uniform(1000, 100000), 2) post_balance = round(pre_balance + transaction_value, 2) # 產生信用額度變化 pre_credit = round(random.uniform(10000, 50000), 2) post_credit = round(pre_credit, 2) # 通常交易不會改變信用額度 # 產生交易明細金額 item1_value = round(transaction_value * 0.5, 2) item2_value = round(transaction_value * 0.3, 2) item3_value = round(transaction_value * 0.2, 2) # 產生錢包餘額 wallet_item1 = round(random.uniform(1000, 5000), 2) wallet_item2 = round(random.uniform(1000, 5000), 2) wallet_item3 = round(random.uniform(1000, 5000), 2) # 產生未結算餘額 unresolved_item1 = round(random.uniform(0, 1000), 2) unresolved_item2 = round(random.uniform(0, 1000), 2) unresolved_item3 = round(random.uniform(0, 1000), 2) # 產生唯一識別碼 record_id = str(uuid.uuid4()) timestamp_creation = datetime.now() # 構建完整的交易記錄 transaction_doc = { "record_id": record_id, "identifier_prefix": random.choice(prefixes), "user_id": f"user_{random.randint(10000, 99999)}", "transaction_value": transaction_value, "incentive_value": round(transaction_value * random.uniform(0.01, 0.2), 2), "financial_institution_name": random.choice(financial_institutions), "user_bank_account_number": generate_bank_account(), "account_reference": f"REF-{random.randint(100000, 999999)}", "account_group": random.randint(1, 5), "main_channel": random.choice(main_channels), "sub_channel": random.choice(sub_channels), "operation_type": random.choice(operation_types), "digital_wallet_type": random.choice(digital_wallet_types), "source_of_operation": random.choice(source_operations), "reference_id": f"ORD-{random.randint(100000, 999999)}", "pre_transaction_balance": pre_balance, "post_transaction_balance": post_balance, "pre_credit_limit": pre_credit, "post_credit_limit": post_credit, "product_reference": f"PROD-{random.randint(1000, 9999)}", "local_first_name": local_name[1:], "local_last_name": local_name[0], "english_first_name": english_first_name, "english_last_name": english_last_name, "campaign_id": f"CAM-{random.randint(1000, 9999)}", "offer_id": f"OFFER-{random.randint(10000, 99999)}", "offer_title": f"{random.choice(['Special', 'Premium', 'Standard', 'VIP'])} Offer", "offer_category": random.choice(offer_categories), "withdrawal_limit": round(random.uniform(5000, 20000), 2), "is_initial_transaction": random.random() < 0.1, # 10%機率是初始交易 "has_withdrawal_restrictions": random.random() < 0.2, # 20%機率有提款限制 "bonus_flag": random.random() < 0.3, # 30%機率是獎勵交易 "transaction_note": fake.sentence(), "timestamp_creation": timestamp_creation, "timestamp_expiration": timestamp_creation + timedelta(days=random.randint(30, 365)), "recovery_data": str(uuid.uuid4()), "transaction_breakdown": { "item_1": item1_value, "item_2": item2_value, "item_3": item3_value, "max_operation_count": random.randint(5, 20), "max_operation_value": round(transaction_value * 2, 2), "item_1_type": random.choice(item_types), "item_2_type": random.choice(item_types) }, "virtual_wallet_balance": { "item_1": wallet_item1, "item_2": wallet_item2, "item_3": wallet_item3 }, "unresolved_balance": { "item_1": unresolved_item1, "item_2": unresolved_item2, "item_3": unresolved_item3 } } # 插入文檔到集合 result = collection.insert_one(transaction_doc) print(f"已插入文檔,ID: {record_id}") transaction_ids.append(record_id) return transaction_ids[0] if count == 1 else transaction_ids # Update document with partial field modifications def update_transaction(collection, doc_id): # 首先查詢原始文檔,擷取交易金額以計算新的值 original_doc = collection.find_one({"record_id": doc_id}) if not original_doc: print("找不到要更新的文檔") return # 產生隨機的更新資料 # 更新交易分解 original_value = original_doc.get("transaction_value", 1000.0) new_item1_value = round(original_value * random.uniform(0.4, 0.6), 2) new_item2_value = round(original_value * random.uniform(0.2, 0.4), 2) new_item3_value = round(original_value - new_item1_value - new_item2_value, 2) # 更新錢包餘額 new_wallet_item1 = round(random.uniform(2000, 8000), 2) new_wallet_item2 = round(random.uniform(1500, 6000), 2) new_wallet_item3 = round(random.uniform(1000, 5000), 2) # 更新未解決餘額 new_unresolved_item1 = round(random.uniform(0, 500), 2) new_unresolved_item2 = round(random.uniform(0, 400), 2) new_unresolved_item3 = round(random.uniform(0, 300), 2) # 隨機播放一些其他欄位進行更新 random_fields_update = {} possible_updates = [ ("incentive_value", round(original_value * random.uniform(0.05, 0.25), 2)), ("withdrawal_limit", round(random.uniform(6000, 25000), 2)), ("transaction_note", fake.sentence()), ("has_withdrawal_restrictions", not original_doc.get("has_withdrawal_restrictions", False)), ("source_of_operation", random.choice(["User ID", "System Auto", "Admin", "API"])), ("bonus_flag", not original_doc.get("bonus_flag", False)), ] # 隨機播放2-4個欄位進行更新 for field, value in random.sample(possible_updates, random.randint(2, 4)): random_fields_update[field] = value # 構建更新資料 update_data = { "$set": { "transaction_breakdown": { "item_1": new_item1_value, "item_2": new_item2_value, "item_3": new_item3_value, "max_operation_count": random.randint(5, 20), "max_operation_value": round(original_value * 2, 2), "item_1_type": original_doc.get("transaction_breakdown", {}).get("item_1_type", "Deposit"), "item_2_type": original_doc.get("transaction_breakdown", {}).get("item_2_type", "Investment") }, "is_initial_transaction": False, "virtual_wallet_balance": { "item_1": new_wallet_item1, "item_2": new_wallet_item2, "item_3": new_wallet_item3 }, "unresolved_balance": { "item_1": new_unresolved_item1, "item_2": new_unresolved_item2, "item_3": new_unresolved_item3 }, "timestamp_update": datetime.now() } } for field, value in random_fields_update.items(): update_data["$set"][field] = value result = collection.update_one( {"record_id": doc_id}, update_data ) print(f"已修改 {result.modified_count} 條文檔") def delete_transaction(collection, doc_id): result = collection.delete_one({"record_id": doc_id}) print(f"Deleted {result.deleted_count} document") def find_transaction(collection, doc_id): doc = collection.find_one({"record_id": doc_id}) if doc: print("Found document:") print(doc) else: print("Document not found") if __name__ == "__main__": # MongoDB執行個體的資料庫名稱 username = "root" # MongoDB執行個體資料庫名稱的密碼 password = "****" encoded_username = urllib.parse.quote_plus(username) encoded_password = urllib.parse.quote_plus(password) # MongoDB執行個體的串連地址 uri = f'mongodb://root:****@dds-bp1dd******-pub.mongodb.rds.aliyuncs.com:3717' # MongoDB執行個體的資料庫名稱 db_name = 'test' # MongoDB執行個體的集合名稱 collection_name = 'transaction_record' client, db, collection = connect_mongodb(uri,db_name,collection_name) if collection is None: exit(1) try: # Insert multiple documents transaction_count = 10 # 可以修改為需要的數量 print(f"準備插入{transaction_count}條交易記錄...") transaction_ids = insert_transaction(collection, transaction_count) # 隨機播放一個交易ID進行更新和查詢 random_transaction_id = random.choice(transaction_ids) if isinstance(transaction_ids, list) else transaction_ids if random.uniform(0, 1) < 0.3: # 提高更新機率 # Update document print("更新一個交易記錄...") update_transaction(collection, random_transaction_id) # Verify update print("查詢更新後的交易記錄...") find_transaction(collection, random_transaction_id) if random.uniform(0, 1) < 0.1: # 保持刪除機率較低 print("刪除一個交易記錄...") delete_transaction(collection, random_transaction_id) # Verify deletion find_transaction(collection, random_transaction_id) finally: # Close connection if 'client' in locals(): client.close()
RDS SQL Server樣本資料
串連RDS SQL Server執行個體,建立名為
demo的資料庫。CREATE DATABASE demo;在
demo資料庫中建立名為rdstest的表。CREATE TABLE rdstest ( id INT PRIMARY KEY, name VARCHAR(100), age INT );插入測試資料。
INSERT INTO rdstest (id, name, age) VALUES (1, 'Alice', 25), (2, 'Bob', 30), (3, 'Charlie', 28), (4, 'Diana', 22), (5, 'Edward', 35), (6, 'Fiona', 40), (7, 'George', 27), (8, 'Hannah', 33), (9, 'Ian', 29), (10, 'Judy', 31), (11, 'Kevin', 26), (12, 'Linda', 34), (13, 'Mark', 23), (14, 'Nina', 21), (15, 'Oliver', 32), (16, 'Paula', 36), (17, 'Quentin', 38), (18, 'Rachel', 24), (19, 'Steve', 39), (20, 'Tina', 28);
資料匯入和ETL
本樣本分別以OSS、MongoDB、Azure Blob Storage、RDS SQL Server和AnalyticDB for MySQL內表資料來源為例,介紹匯入資料的流程。
OSS資料:通過Spark SQL大量匯入。
MongoDB資料:通過PySpark流式匯入。
Azure Blob Storage資料、RDS SQL Server資料和AnalyticDB for MySQL內表資料:通過PySpark大量匯入。
通過Spark SQL大量匯入資料
在本教程中,預設使用DELTALAKE作為表格式。如果您希望建立格式為Iceberg的OSS表,可以在建表時指定類型為ICEBERG(即USING iceberg)。
進入SQL開發。
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊叢集列表,然後單擊目的地組群ID。
在左側導覽列,單擊。
在SQLConsole視窗,選擇Spark引擎和Job型資源群組。
在
test_db庫中建立外表test_src_tbl。CREATE TABLE IF NOT exists test_db.test_src_tbl( id int, name string, age int ) USING parquet -- 資料準備章節中樣本資料所在的OSS路徑 LOCATION 'oss://testBucketName/test/test_tbl/' TBLPROPERTIES ('parquet.compress'='SNAPPY');查詢
test_src_tbl表資料,驗證資料是否成功讀取。SELECT * FROM test_db.test_src_tbl LIMIT 10;建立Delta表,並將OSS表資料匯入至Delta表中。
建立Delta表。
CREATE TABLE IF NOT EXISTS test_db.test_target_tbl ( id INT, name STRING, age INT ) USING DELTA;將外表資料匯入至Delta表。
INSERT INTO test_db.test_target_tbl SELECT * FROM test_db.test_src_tbl;
查詢資料是否匯入成功。
SELECT * FROM test_db.test_target_tbl LIMIT 10;查看目標表
demo.test_target_tbl資料存放區的OSS路徑。DESCRIBE DETAIL test_db.test_target_tbl;ETL加工資料。
若您想要修改執行作業所使用的ACU時,可以在SQL語句前添加對應參數修改單個作業所使用的ACU,或在建立資源群組時通過索引值對形式添加對應參數修改該資源群組內所有作業使用的ACU。
通過SET命令修改單個作業所使用的ACU
定義執行作業的Spark Executor節點個數為32,規格為medium(2核8 GB,使用ACU數量為2),此時該作業預設會被分配64ACU。
SET spark.executor.instances=32; SET spark.executor.resourceSpec = medium; -- 建立ETL目標表 CREATE TABLE IF NOT EXISTS test_db.etl_result_tbl ( id INT, name STRING, age INT, is_adult INT ) USING DELTA; -- 步驟 2: ETL(清洗+轉換) INSERT INTO test_db.etl_result_tbl SELECT id, name, age, CASE WHEN age >= 18 THEN 1 ELSE 0 END AS is_adult FROM test_db.test_target_tbl WHERE name IS NOT NULL;通過資源群組修改全域作業所使用的ACU
定義執行作業的Spark Executor節點個數為32,規格為medium(2核8 GB,使用ACU數量為2),此時該作業預設會被分配64ACU。
修改Job型資源群組,以下兩種方法任選一種即可。
在文字框配置中,以索引值對形式配置:
spark.executor.instances 32 spark.executor.resourceSpec medium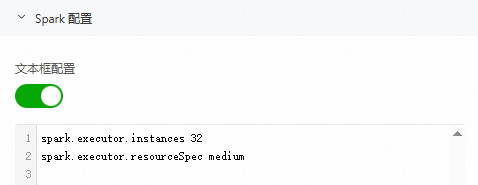
單擊
 按鈕,以prop-value形式配置:
按鈕,以prop-value形式配置: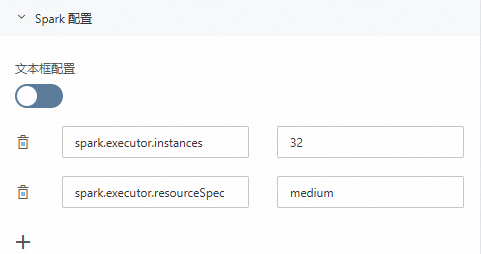
ETL加工資料。
-- 建立ETL目標表 CREATE TABLE IF NOT EXISTS test_db.etl_result_tbl ( id INT, name STRING, age INT, is_adult INT ) USING DELTA; -- ETL(清洗+轉換) INSERT INTO test_db.etl_result_tbl SELECT id, name, age, CASE WHEN age >= 18 THEN 1 ELSE 0 END AS is_adult FROM test_db.test_target_tbl WHERE name IS NOT NULL;
通過PySpark流式匯入資料
本章節基於DMS Notebook為您示範如何通過PySpark將MongoDB資料匯入至AnalyticDB for MySQL並儲存為Delta表。
下載AnalyticDB for MySQL Spark訪問MongoDB依賴的Jar包,並將其上傳至OSS中。
下載連結mongo-spark-connector_2.12-10.4.0.jar、mongodb-driver-sync-5.1.4.jar、bson-5.1.4.jar、bson-record-codec-5.1.4.jar和mongodb-driver-core-5.1.4.jar。
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊叢集列表,然後單擊目的地組群ID。
單擊。確保已完成如下準備工作,然後單擊進入DMS Notebook。

建立Notebook檔案,並匯入資料。
建立Spark叢集。
單擊
 按鈕,進入資源管理頁面,單擊計算叢集。
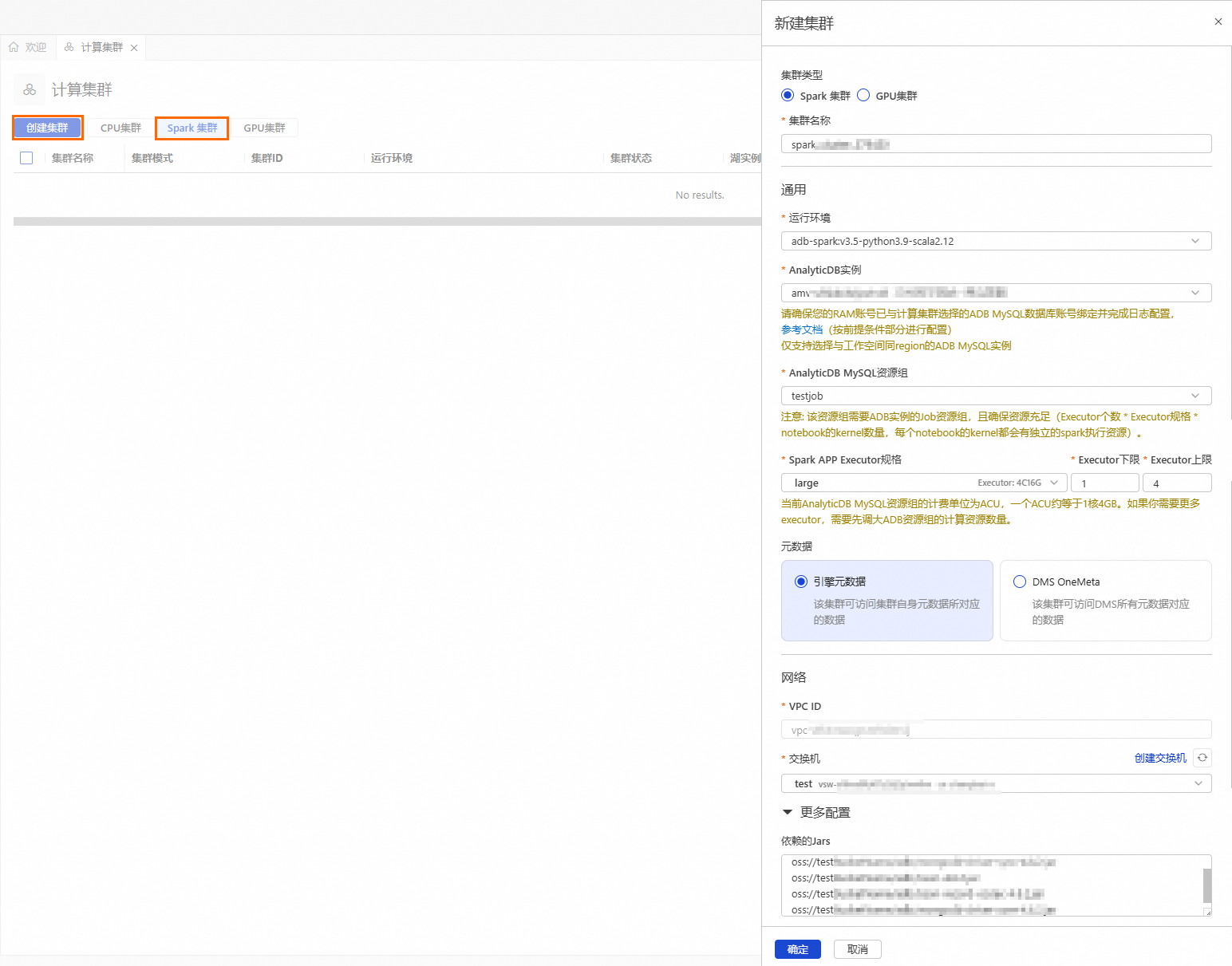
按鈕,進入資源管理頁面,單擊計算叢集。選擇Spark叢集頁簽,單擊建立叢集,並配置如下參數:
參數
說明
樣本值
叢集名稱
輸入便於識別使用情境的叢集名稱。
spark_test
運行環境
目前支援選擇如下鏡像:
adb-spark:v3.3-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB執行個體
在下拉框中選擇AnalyticDB for MySQL叢集。
amv-uf6i4bi88****
AnalyticDB MySQL資源群組
在下拉框中選擇Job型資源群組。
testjob
Spark APP Executor規格
選擇Spark Executor的資源規格。
不同型號的取值對應不同的規格,詳情請參見Spark應用配置參數說明的型號列。
large
交換器
選擇當前VPC下的交換器。
vsw-uf6n9ipl6qgo****
依賴的Jars
Jar包的OSS儲存路徑。此處需要填寫步驟1下載的Jar包所屬的OSS路徑。
如果您想在業務代碼中指定JAR包的OSS地址,此處可以不填寫。
oss://testBucketName/adb/mongo-spark-connector_2.12-10.4.0.jar oss://testBucketName/adb/mongodb-driver-sync-5.1.4.jar oss://testBucketName/adb/bson-5.1.4.jar oss://testBucketName/adb/bson-record-codec-5.1.4.jar oss://testBucketName/adb/mongodb-driver-core-5.1.4.jar
建立並啟動Notebook會話時,初次開機需要等待大約5分鐘。
參數
說明
樣本值
所屬叢集
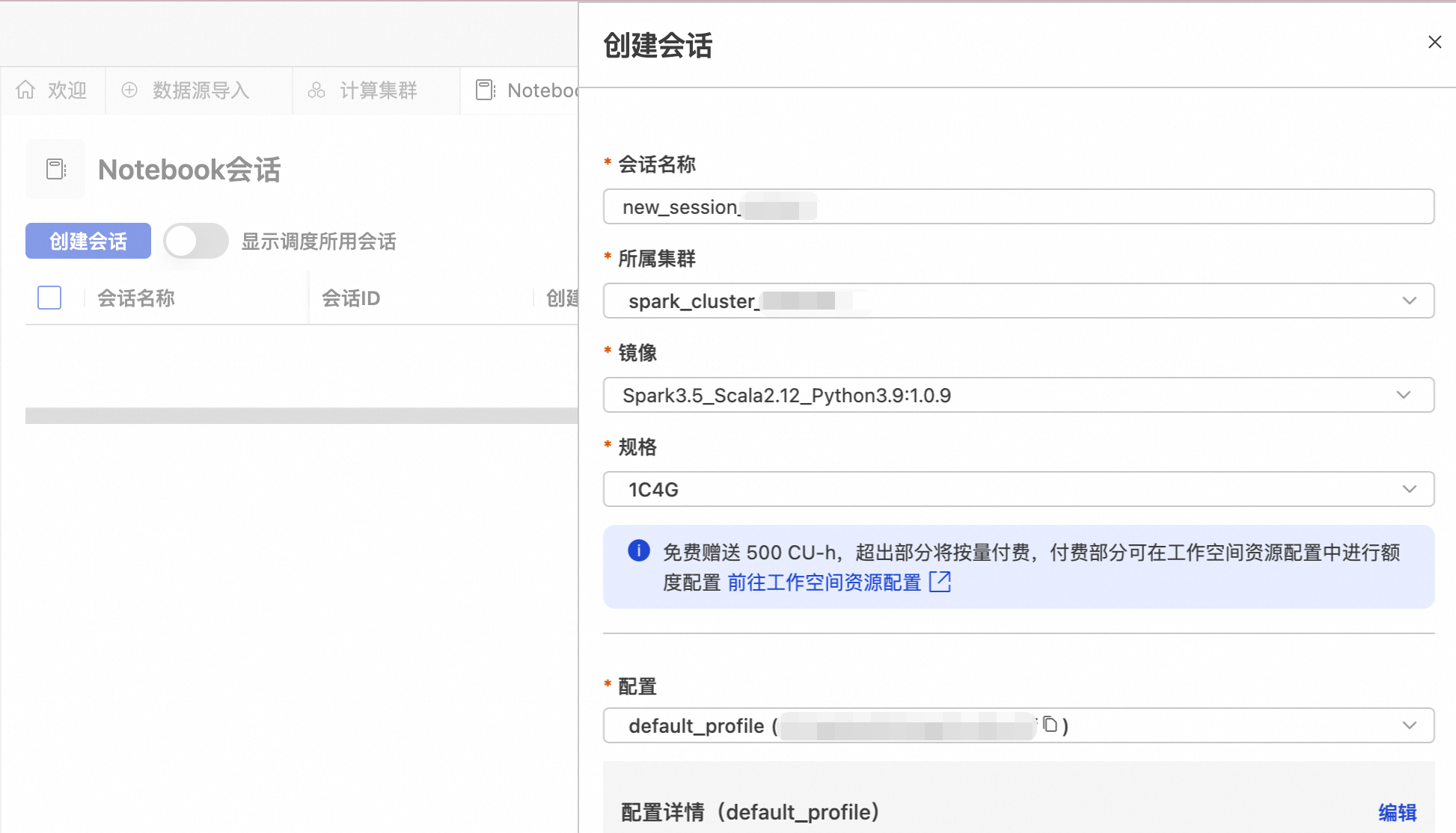
選擇步驟b建立的Spark叢集。
spark_test
會話名稱
您可自訂會話名稱。
new_session
鏡像
選擇鏡像規格。
Spark3.5_Scala2.12_Python3.9:1.0.9
規格
kernel的資源規格。
4C16G
配置
profile資源。
您可編輯profile的名稱、資源釋放時間長度、資料存放區位置、Pypi包管理和環境變數資訊。
重要資源釋放時間長度:當資源空閑時間超過設定的時間長度,則會自動釋放。資源釋放時間長度設定為0,表示資源永久不會自動釋放。
deault_profile
建立Notebook檔案。
單擊
 按鈕,然後單擊。
按鈕,然後單擊。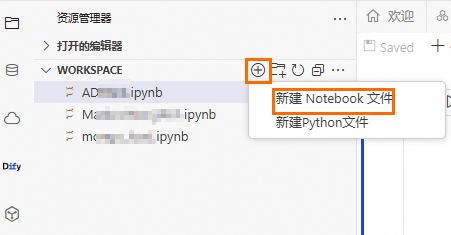
將Cell的語言類型設定為Python,執行以下代碼,將MongoDB執行個體中,
TransactionRecord集合的歷史資料大量匯入到AnalyticDB for MySQLtest庫的mongo_load_table_test表中。from pyspark.sql import SparkSession spark = SparkSession.builder.appName("AppLoadMongoDB") \ # 填寫步驟1下載的MongoDB依賴Jar包所儲存的OSS路徑 .config("spark.jars", "oss://testBucketName/mongodb/bson-5.1.4.jar,oss://testBucketName/mongodb/bson-record-codec-5.1.4.jar,oss://testBucketName/mongodb/mongo-spark-connector_2.12-10.4.0.jar,oss://testBucketName/mongodb/mongodb-driver-core-5.1.4.jar,oss://testBucketName/mongodb/mongodb-driver-sync-5.1.4.jar") \ .config("spark.driver.memory", "2g") \ .getOrCreate() # MongoDB執行個體的資料庫名稱 mongo_database_name = "test" # MongoDB執行個體的集合名稱 mongo_collection_name = "TransactionRecord" # MongoDB執行個體的串連地址 url = "mongodb://root:******@dds-uf667b******.mongodb.rds.aliyuncs.com:3717" df = spark.read \ .format("mongodb") \ .option("spark.mongodb.connection.uri", url) \ .option("spark.mongodb.database", mongo_database_name) \ .option("spark.mongodb.collection", mongo_collection_name) \ .load() df.printSchema() df.show(truncate=False) df.write.format("delta").mode(saveMode="append").saveAsTable("test_db.mongo_load_table_test")將Cell的語言類型設定為Python,執行以下代碼,將MongoDB執行個體中,
TransactionRecord集合的增量資料同步到AnalyticDB for MySQLtest庫的mongo_load_table_test表中。from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DoubleType, BooleanType, TimestampType, ArrayType schema = StructType([ StructField("record_id", StringType(), True), StructField("identifier_prefix", StringType(), True), StructField("user_id", StringType(), True), StructField("transaction_value", DoubleType(), True), StructField("incentive_value", DoubleType(), True), StructField("financial_institution_name", StringType(), True), StructField("user_bank_account_number", StringType(), True), StructField("account_reference", StringType(), True), StructField("account_group", IntegerType(), True), StructField("main_channel", StringType(), True), StructField("sub_channel", StringType(), True), StructField("operation_type", StringType(), True), StructField("digital_wallet_type", StringType(), True), StructField("source_of_operation", StringType(), True), StructField("reference_id", StringType(), True), StructField("pre_transaction_balance", DoubleType(), True), StructField("post_transaction_balance", DoubleType(), True), StructField("pre_credit_limit", DoubleType(), True), StructField("post_credit_limit", DoubleType(), True), StructField("product_reference", StringType(), True), StructField("local_first_name", StringType(), True), StructField("local_last_name", StringType(), True), StructField("english_first_name", StringType(), True), StructField("english_last_name", StringType(), True), StructField("campaign_id", StringType(), True), StructField("offer_id", StringType(), True), StructField("offer_title", StringType(), True), StructField("offer_category", StringType(), True), StructField("withdrawal_limit", DoubleType(), True), StructField("is_initial_transaction", BooleanType(), True), StructField("has_withdrawal_restrictions", BooleanType(), True), StructField("bonus_flag", BooleanType(), True), StructField("transaction_note", StringType(), True), StructField("timestamp_creation", TimestampType(), True), StructField("timestamp_expiration", TimestampType(), True), StructField("recovery_data", StringType(), True), StructField("transaction_breakdown", StructType([ StructField("item_1", DoubleType(), True), StructField("item_2", DoubleType(), True), StructField("item_3", DoubleType(), True), StructField("max_operation_count", IntegerType(), True), StructField("max_operation_value", DoubleType(), True), StructField("item_1_type", StringType(), True), StructField("item_2_type", StringType(), True) ]), True), StructField("virtual_wallet_balance", StructType([ StructField("item_1", DoubleType(), True), StructField("item_2", DoubleType(), True), StructField("item_3", DoubleType(), True) ]), True), StructField("unresolved_balance", StructType([ StructField("item_1", DoubleType(), True), StructField("item_2", DoubleType(), True), StructField("item_3", DoubleType(), True) ]), True) ]) # MongoDB執行個體的資料庫名稱 mongo_database_name = "test" # MongoDB執行個體的集合 mongo_collection_name = "TransactionRecord!" # MongoDB執行個體的串連地址 uri = "mongodb://root:******@dds-uf667b******.mongodb.rds.aliyuncs.com:3717" df = (spark.readStream \ .format("mongodb") \ .option("database", mongo_database_name) \ .option("collection", mongo_collection_name) \ .option("spark.mongodb.connection.uri",uri)\ .option("change.stream.publish.full.document.only", "true")\ .schema(schema) .load()) display(df) checkpoint_oss_location = "oss://testBucketNam/mongodb_checkpoint_v1/" query = df.writeStream \ .trigger(availableNow=True) \ .format(source="delta") \ .outputMode("append") \ .option("checkpointLocation", checkpoint_oss_location) \ .option("mergeSchema", "true") \ .toTable("test_db.mongo_load_table_test") query.awaitTermination()將Cell的語言類型設定為SQL,執行以下代碼,查看MongoDB執行個體資料是否成功寫入
mongo_load_table_test表。DESCRIBE test_db.mongo_load_table_test; DESCRIBE HISTORY test_db.mongo_load_table_test;將Cell的語言類型設定為SQL,執行以下代碼合并目標表中的小檔案,並根據timestamp_creation列進行排序,以最佳化查詢效能。
OPTIMIZE test_db.mongo_load_table_test ZORDER BY (timestamp_creation);
通過PySpark大量匯入資料
本章節基於DMS Notebook為您示範如何通過PySpark將Azure Blob Storge資料、RDS SQL Server資料和AnalyticDB for MySQL倉表資料匯入至AnalyticDB for MySQL並儲存為Delta表。
Azure Blob Storage資料匯入
下載AnalyticDB for MySQL Spark訪問Azure Blob Storage依賴的Jar包,並將其上傳至OSS中。
下載連結jetty-util-ajax-9.4.51.v20230217.jar、jetty-server-9.4.51.v20230217.jar、jetty-io-9.4.51.v20230217.jar、jetty-util-9.4.51.v20230217.jar、azure-storage-8.6.0.jar、hadoop-azure-3.3.0.jar和hadoop-azure-datalake-3.3.0.jar。
配置Spark公網環境。
公網NAT Gateway需要與AnalyticDB for MySQL執行個體為同一個地區。
- 重要
為保證成功讀取並匯入Azure Blob Storage資料,建立SNAT條目時指定的交換器需要跟後續建立Spark叢集的交換器一致。
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊叢集列表,然後單擊目的地組群ID。
單擊。確保已完成如下準備工作,然後單擊進入DMS Notebook。
建立Notebook檔案,並匯入資料。
建立Spark叢集。
單擊
按鈕,進入資源管理頁面,單擊計算叢集。選擇Spark叢集頁簽,單擊建立叢集,並配置如下參數:
參數
說明
樣本值
叢集名稱
輸入便於識別使用情境的叢集名稱。
spark_test
運行環境
目前支援選擇如下鏡像:
adb-spark:v3.3-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB執行個體
在下拉框中選擇AnalyticDB for MySQL叢集。
amv-uf6i4bi88****
AnalyticDB MySQL資源群組
在下拉框中選擇Job型資源群組。
testjob
Spark APP Executor規格
選擇Spark Executor的資源規格。
不同型號的取值對應不同的規格,詳情請參見Spark應用配置參數說明的型號列。
large
交換器
選擇當前VPC下的交換器。
vsw-uf6n9ipl6qgo****
依賴的Jars
Jar包的OSS儲存路徑。此處需要填寫步驟1下載的Jar包所屬的OSS路徑。
如果您想在業務代碼中指定JAR包的OSS地址,此處可以不填寫。
oss://testBucketName/jar_file/jetty-util-ajax-9.4.51.v20230217.jar, oss://testBucketName/jar_file/jetty-server-9.4.51.v20230217.jar, oss://testBucketName/jar_file/jetty-io-9.4.51.v20230217.jar, oss://testBucketName/jar_file/jetty-util-9.4.51.v20230217.jar, oss://testBucketName/jar_file/azure-storage-8.6.0.jar, oss://testBucketName/jar_file/hadoop-azure-3.3.0.jar, oss://testBucketName/jar_file/hadoop-azure-datalake-3.3.0.jar")
建立並啟動Notebook會話時,初次開機需要等待大約5分鐘。
參數
說明
樣本值
所屬叢集
選擇步驟b建立的Spark叢集。
spark_test
會話名稱
您可自訂會話名稱。
new_session
鏡像
選擇鏡像規格。
Spark3.5_Scala2.12_Python3.9:1.0.9
規格
kernel的資源規格。
4C16G
配置
profile資源。
您可編輯profile的名稱、資源釋放時間長度、資料存放區位置、Pypi包管理和環境變數資訊。
重要資源釋放時間長度:當資源空閑時間超過設定的時間長度,則會自動釋放。資源釋放時間長度設定為0,表示資源永久不會自動釋放。
deault_profile
建立Notebook檔案。
單擊
按鈕,然後單擊。將Cell的語言類型設定為Python,執行如下代碼,載入python依賴。
!pip install azure-storage-blob>=12.14.0 !pip install azure-identity將Cell的語言類型設定為Python,執行如下代碼,測試是否可以正常讀取Azure Blob Storage中的資料。
from azure.storage.blob import BlobServiceClient import azure.storage.blob # Azure Blob Storage的賬戶名稱 storage_account_name = 'storage****' # Azure Blob Storage賬戶的密鑰 azure_account_key = 'NPNe9B6DmxQpmA****' # Azure Blob Storage的容器名稱 container = 'azurename****' blob_service = BlobServiceClient( account_url=f"https://{storage_account_name}.blob.core.windows.net", credential=azure_account_key ) try: container_client = blob_service.get_container_client(container) if container_client.exists(): print(f"Azure Container {container} is accessible!") print(azure.storage.blob.__version__) blobs = container_client.list_blobs() #if azure.storage.blob.__version__ >= "12.14.0": # blobs = container_client.list_blobs(max_results=10) #else: # blobs = container_client.list_blobs() print("\nAzure Objects count: %s"%len(blobs)) else: print(f"Azure Container {container} access failed!") except Exception as e: print(f"Connection failed: {str(e)}")將Cell的語言類型設定為Python,執行如下代碼,建立Spark會話。
from datetime import datetime from datetime import date from pyspark.sql import SparkSession # Azure Blob Storage的賬戶名稱 storage_account_name = 'storage****' # Azure Blob Storage的容器名稱 container = 'azurename****' # Azure Blob Storage賬戶的密鑰 azure_account_key = 'NPNe9B6DmxQpmA****' spark = SparkSession.builder \ .appName("AzureBlobToOSS") \ .config("spark.jars", \ #步驟1下載的Azure Blob Storage依賴的Jar包所在的OSS路徑 "oss://testBucketName/jar_file/jetty-util-ajax-9.4.51.v20230217.jar,\ oss://testBucketName/jar_file/jetty-server-9.4.51.v20230217.jar,\ oss://testBucketName/jar_file/jetty-io-9.4.51.v20230217.jar,\ oss://testBucketName/jar_file/jetty-util-9.4.51.v20230217.jar,\ oss://testBucketName/jar_file/azure-storage-8.6.0.jar,\ oss://testBucketName/jar_file/hadoop-azure-3.3.0.jar,\ oss://testBucketName/jar_file/hadoop-azure-datalake-3.3.0.jar")\ .config("spark.hadoop.fs.azure", "org.apache.hadoop.fs.azure.NativeAzureFileSystem") \ .config("spark.hadoop.fs.azure.account.key.%s.blob.core.windows.net"%storage_account_name, azure_account_key) \ .getOrCreate() print("Spark Session has been created successfully!")將Cell的語言類型設定為Python,執行如下代碼,將Azure Blob Storage中的Parquet數匯入到AnalyticDB for MySQL
test_db庫的azure_load_table表中。from pyspark.sql import SparkSession from py4j.java_gateway import java_import import time from datetime import datetime # 請將test_tbl_2.parquet替換為Parquet樣本資料實際儲存路徑 parquet_path = f"wasbs://{container}@{storage_account_name}.blob.core.windows.net/test_tbl_2.parquet" df = spark.read.parquet(parquet_path) # 將資料匯入azure_load_table表 df.write.format("delta").mode("overwrite").saveAsTable('test_db.azure_load_table')在AnalyticDB for MySQL叢集中查詢資料是否匯入成功。
SELECT * FROM test_db.azure_load_table LIMIT 10;
RDS SQL Server資料匯入
下載AnalyticDB for MySQL Spark訪問RDS SQL Server依賴的Jar包。
解壓下載的驅動程式壓縮包,將jars檔案裡尾碼為jre8.jar的Jar包簡單上傳。
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊叢集列表,然後單擊目的地組群ID。
單擊。確保已完成如下準備工作,然後單擊進入DMS Notebook。
建立Notebook檔案,並匯入資料。
建立Spark叢集。
單擊
按鈕,進入資源管理頁面,單擊計算叢集。選擇Spark叢集頁簽,單擊建立叢集,並配置如下參數:
參數
說明
樣本值
叢集名稱
輸入便於識別使用情境的叢集名稱。
spark_test
運行環境
目前支援選擇如下鏡像:
adb-spark:v3.3-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB執行個體
在下拉框中選擇AnalyticDB for MySQL叢集。
amv-uf6i4bi88****
AnalyticDB MySQL資源群組
在下拉框中選擇Job型資源群組。
testjob
Spark APP Executor規格
選擇Spark Executor的資源規格。
不同型號的取值對應不同的規格,詳情請參見Spark應用配置參數說明的型號列。
large
交換器
選擇當前VPC下的交換器。
vsw-uf6n9ipl6qgo****
依賴的Jars
Jar包的OSS儲存路徑。此處需要填寫步驟1下載的Jar包所屬的OSS路徑。
如果您想在業務代碼中指定JAR包的OSS地址,此處可以不填寫。
oss://testBucketName/jar_file/mssql-jdbc-12.8.1.jre8.jar
建立並啟動Notebook會話時,初次開機需要等待大約5分鐘。
參數
說明
樣本值
所屬叢集
選擇步驟b建立的Spark叢集。
spark_test
會話名稱
您可自訂會話名稱。
new_session
鏡像
選擇鏡像規格。
Spark3.5_Scala2.12_Python3.9:1.0.9
規格
kernel的資源規格。
4C16G
配置
profile資源。
您可編輯profile的名稱、資源釋放時間長度、資料存放區位置、Pypi包管理和環境變數資訊。
重要資源釋放時間長度:當資源空閑時間超過設定的時間長度,則會自動釋放。資源釋放時間長度設定為0,表示資源永久不會自動釋放。
deault_profile
建立Notebook檔案。
單擊
按鈕,然後單擊。將Cell的語言類型設定為Python,執行如下代碼,讀取RDS SQL Server資料。
from pyspark.sql import SparkSession # 初始化 SparkSession spark = SparkSession.builder.appName("AppLoadSQLServer") \ .config("spark.jars", "oss://testBucketName/sqlserver/mssql-jdbc-12.8.1.jre8.jar") \ # 步驟1下載的Jar所在的OSS路徑 .config("spark.driver.memory", "2g") \ .getOrCreate() # RDS SQL Server資料庫名稱 database = "demo" # RDS SQL Server表名稱 table = "rdstest" # RDS SQL Server串連地址 sqlserver_url = "jdbc:sqlserver://rm-uf68v****.sqlserver.rds.aliyuncs.com:1433" # RDS SQL Server資料庫帳號 user = 'user' # RDS SQL Server資料庫帳號的密碼 password = 'pass****' df = spark.read \ .format("jdbc") \ .option("url", f"{sqlserver_url};databaseName={database};trustServerCertificate=true;encrypt=true;") \ .option("dbtable", table) \ .option("user", user) \ .option("password", password) \ .load() # 列印 Schema 和樣本資料 df.printSchema() df.show(truncate=False) # 儲存為 Delta表 df.write.format("delta").mode(saveMode="append").saveAsTable("test_db.rds_delta_test")
AnalyticDB for MySQL倉表資料匯入
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊叢集列表,然後單擊目的地組群ID。
單擊。確保已完成如下準備工作,然後單擊進入DMS Notebook。
建立Notebook檔案,並匯入資料。
建立Spark叢集。
單擊
按鈕,進入資源管理頁面,單擊計算叢集。選擇Spark叢集頁簽,單擊建立叢集,並配置如下參數:
參數
說明
樣本值
叢集名稱
輸入便於識別使用情境的叢集名稱。
spark_test
運行環境
目前支援選擇如下鏡像:
adb-spark:v3.3-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
adb-spark:v3.5-python3.9-scala2.12
AnalyticDB執行個體
在下拉框中選擇AnalyticDB for MySQL叢集。
amv-uf6i4bi88****
AnalyticDB MySQL資源群組
在下拉框中選擇Job型資源群組。
testjob
Spark APP Executor規格
選擇Spark Executor的資源規格。
不同型號的取值對應不同的規格,詳情請參見Spark應用配置參數說明的型號列。
large
交換器
選擇當前VPC下的交換器。
vsw-uf6n9ipl6qgo****
依賴的Jars
Jar包的OSS儲存路徑。此處需要填寫步驟1下載的Jar包所屬的OSS路徑。
如果您想在業務代碼中指定JAR包的OSS地址,此處可以不填寫。
oss://testBucketName/jar_file/mssql-jdbc-12.8.1.jre8.jar
建立並啟動Notebook會話時,初次開機需要等待大約5分鐘。
參數
說明
樣本值
所屬叢集
選擇步驟b建立的Spark叢集。
spark_test
會話名稱
您可自訂會話名稱。
new_session
鏡像
選擇鏡像規格。
Spark3.5_Scala2.12_Python3.9:1.0.9
規格
kernel的資源規格。
4C16G
配置
profile資源。
您可編輯profile的名稱、資源釋放時間長度、資料存放區位置、Pypi包管理和環境變數資訊。
重要資源釋放時間長度:當資源空閑時間超過設定的時間長度,則會自動釋放。資源釋放時間長度設定為0,表示資源永久不會自動釋放。
deault_profile
建立Notebook檔案。
單擊
按鈕,然後單擊。將Cell的語言類型設定為Python,執行如下代碼,讀取AnalyticDB for MySQL倉表資料。
from pyspark.sql import SparkSession # 初始化 SparkSession spark = SparkSession.builder.appName("AppLoadADBMSQL") \ .config("spark.driver.memory", "2g") \ .getOrCreate() # AnalyticDB for MySQL資料庫名稱 database = "demo" # AnalyticDB for MySQL表名稱 table = "test" # AnalyticDB for MySQL串連地址 url = "jdbc:mysql://amv-uf6i4b****.ads.aliyuncs.com:3306" # AnalyticDB for MySQL資料庫帳號 user = 'user' # AnalyticDB for MySQL資料庫帳號的密碼 password = 'pass****' # 批量讀取 AnalyticDB for MySQL 資料 df = spark.read \ .format("jdbc") \ .option("url", f"{url}/{database}") \ .option("dbtable", table) \ .option("user", user) \ .option("password", password) \ .load() # 列印 Schema 和樣本資料 df.printSchema() df.show(truncate=False) # 儲存為 Delta表 df.write.format("delta").mode(saveMode="append").saveAsTable("test_db.adb_delta_test")
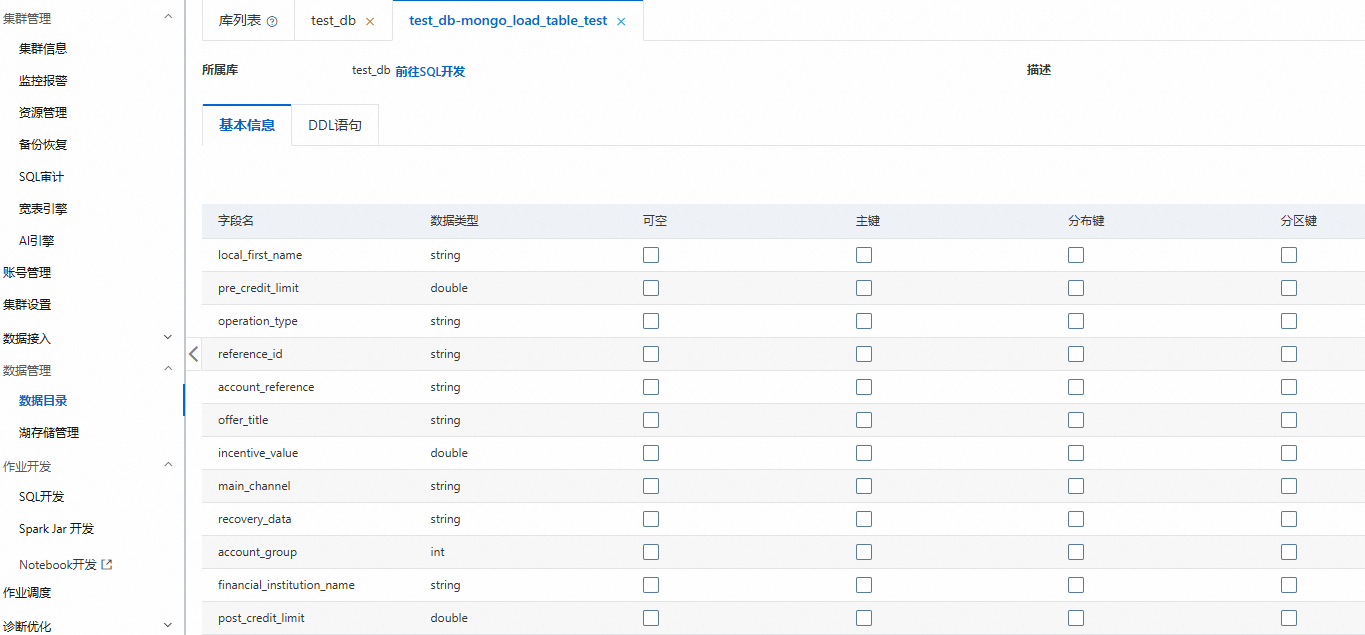
預覽資料目錄
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊叢集列表,然後單擊目的地組群ID。
在左側導覽列,單擊。
單擊目標資料庫和表,查看錶的詳細資料,例如:表類型、表格儲存體資料量、列名等。
互動式分析
如果您需要以互動式方式執行Spark SQL,並且對查詢效能有要求,可以使用Spark Interactive型資源群組作為執行查詢的資源群組。此外每個Spark Interactive型資源群組預設都有本機快取機制,當重複讀取OSS資料時,可以提升查詢效能。
通過控制台進行互動式查詢
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊叢集列表,然後單擊目的地組群ID。
在左側導覽列,單擊。
在SQLConsole視窗,選擇Spark引擎和Interactive型資源群組。
執行以下語句,進行互動式查詢:
SELECT COUNT(*) FROM test_db.etl_result_tbl;
通過應用程式進行互動式查詢
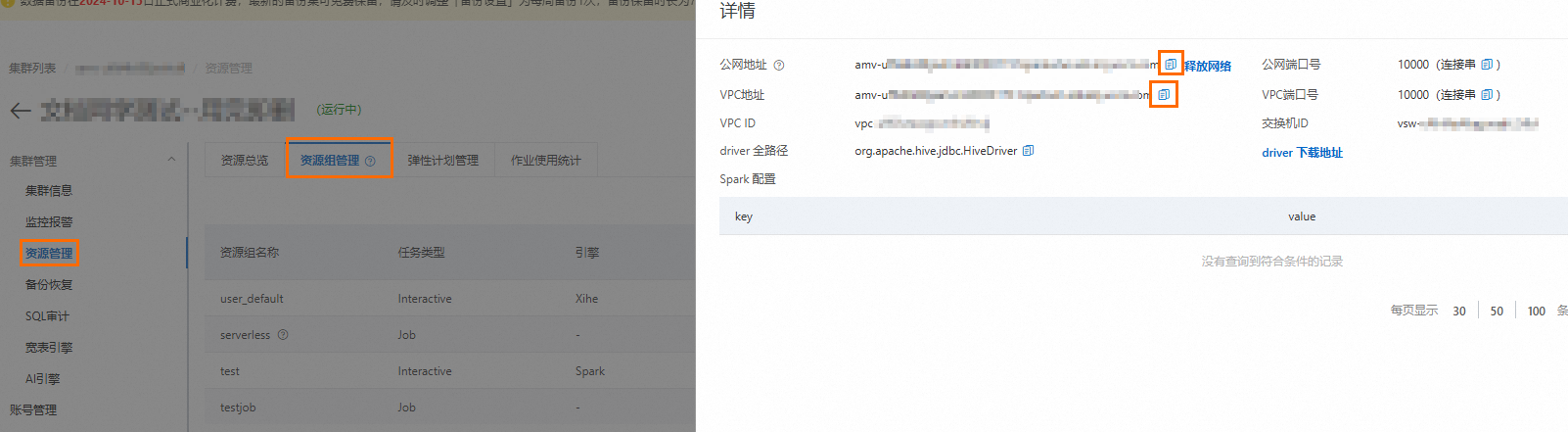
擷取Spark Interactive型資源群組的串連地址。
登入雲原生資料倉儲AnalyticDB MySQL控制台,在左上方選擇叢集所在地區。在左側導覽列,單擊叢集列表,在企業版、基礎版或湖倉版頁簽下,單擊目的地組群ID。
在左側導覽列,單擊,單擊資源群組管理頁簽。
單擊對應資源群組操作列的詳情,查看內網串連地址和公網串連地址。您可單擊
 按鈕,複製串連地址。
按鈕,複製串連地址。以下兩種情況,您需要單擊公網地址後的申請網路,手動申請公網串連地址。
提交Spark SQL作業的用戶端工具部署在本地或外部伺服器。
提交Spark SQL作業的用戶端工具部署在ECS上,且ECS與AnalyticDB for MySQL不屬於同一VPC。
安裝Python依賴。
Python版本為3.11及以上,使用如下命令安裝依賴:
pip install pyhive[hive_pure_sasl]>=0.7.0Python版本為3.11以下,使用如下命令安裝依賴:
pip install pyhive[hive]>=0.7.0
執行如下代碼:
from pyhive import hive from TCLIService.ttypes import TOperationState cursor = hive.connect( # Spark Interactive型資源群組串連地址 host='amv-uf6i4b****sparkwho.ads.aliyuncs.com', # Spark Interactive型資源群組的連接埠號碼,固定為10000 port=10000, # AnalyticDB for MySQL的資源群組名稱和資料庫帳號 username='testjob/user', # AnalyticDB for MySQL資料庫帳號的密碼 password='password****', auth='CUSTOM' ).cursor() # Spark SQL作業的業務代碼 cursor.execute('select count(*) from test_db.etl_result_tbl;') status = cursor.poll().operationState while status in (TOperationState.INITIALIZED_STATE, TOperationState.RUNNING_STATE): logs = cursor.fetch_logs() for message in logs: print(message) # If needed, an asynchronous query can be cancelled at any time with: # cursor.cancel() status = cursor.poll().operationState print(cursor.fetchall())
調度Spark SQL作業
Airflow開源調度工具,可以實現各類工作負載的DAG編排與調度。如果您希望使用Airflow調度Spark SQL作業,可以參考調度Spark SQL作業文檔通過Spark Airflow Operator、Spark-Submit命令列工具來調度Spark SQL任務。
DataWorks提供全鏈路巨量資料開發治理能力,且DataWorks資料開發(DataStudio)模組支援工作流程可視化開發和託管調度營運,能夠按照時間和依賴關係輕鬆實現任務的全面託管調度。如果您希望使用DataWorks調度Spark SQL作業,可以參考DataWorks調度Spark SQL作業文檔通過AnalyticDB Spark SQL節點調度Spark SQL任務。
除上述工具以外,若您希望使用其他調度工具(如DMS、DolphinScheduler或者Azkaban),請參考Spark調度文檔調度Spark SQL作業。