大模型服務啟動時需載入較大的模型檔案,若直接從 OSS 下載,可能因網路延遲和並發限制導致啟動緩慢、Auto Scaling延遲。ossfs 2.0 提供高吞吐順序寫入與智能緩衝能力,可顯著縮短模型載入時間。本文針對 safetensors 等主流架構,在單 GPU 與多 GPU 情境下,提供基於PV/PVC 的部署方案。
準備工作
叢集與組件版本:
已建立ACK託管叢集且CSI組件版本不低於v1.35.1。
本文介紹的部分大模型效能最佳化參數(如
memory_data_cache_size)依賴 ossfs 2.0 為 v2.0.5 及以上。CSI組件自v1.34.4版本起,已內建ossfs 2.0 v2.0.5版本。資源準備:
已建立OSS Bucket,用於儲存模型檔案。推薦選擇與叢集同地區的 Bucket,以降低跨地區訪問延遲。
已完成對OSS的訪問授權配置。推薦使用RRSA鑒權方式進行認證,以通過 RAM 角色授予最小的必要許可權。
階段一:準備模型資料
將模型檔案從 ModelScope 等外部倉庫下載至 OSS,以便快速啟動服務。ossfs 2.0 支援高吞吐順序寫入,配合 ECS 內網頻寬,實測寫入吞吐可達 20 Gbps(OSS 預設配置的上行頻寬上限),大幅縮短模型入庫時間。
1. 建立PV和PVC
以下 YAML 使用 RRSA 授權方式,將 OSS Bucket 掛載為 Kubernetes 靜態儲存卷。詳見使用ossfs 2.0靜態儲存卷。
otherOpts中配置的-o memory_data_cache_size=16g參數主要用於階段二:部署模型服務,對當前的模型下載任務無效能影響。
apiVersion: v1
kind: PersistentVolume
metadata:
# PV名稱
name: deepseek-r1
spec:
capacity:
# 定義儲存卷容量 (此值僅用於匹配PVC)
storage: 20Gi
# 訪問模式
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
csi:
# 使用ossfs 2.0用戶端時固定為此值
driver: ossplugin.csi.alibabacloud.com
# 與PV名稱(metadata.name)保持一致
volumeHandle: deepseek-r1
volumeAttributes:
fuseType: ossfs2
# OSS Bucket名稱
bucket: oss-models
# 掛載Bucket的根目錄或指定子目錄
path: /models/DeepSeek-R1-0528
# OSS Bucket所在地區的Endpoint
url: "http://oss-cn-hangzhou-internal.aliyuncs.com"
# ossfs 2.0用戶端配置參數,memory_data_cache_size參數對模型下載情境無影響
# 該參數用於後續模型部署階段使用
otherOpts: "-o memory_data_cache_size=16g"
authType: "rrsa"
# 此前建立或修改的RAM角色
roleName: "demo-role-for-rrsa"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
# PVC名稱
name: deepseek-r1
namespace: default
spec:
# 以下配置需要與PV一致
accessModes:
- ReadWriteMany
resources:
requests:
storage: 20Gi
storageClassName: ""
# 待綁定的PV
volumeName: deepseek-r1 2. 建立Job下載模型
以下Job使用ModelScope官方鏡像,通過 ossfs 2.0 將模型檔案直接寫入掛載的 OSS 目錄,避免本地磁碟中轉。
Job鏡像為ModelScope社區的Python 3.11 CPU環境鏡像。可按需在ModelScope社區擷取其他鏡像。
ECS 節點與 OSS 同地區時,預設通過內網進行傳輸,頻寬充足。ossfs 2.0 利用多線程順序寫入機制,可將資料流持續寫入 OSS,實測寫入吞吐可達 20 Gbps(OSS 預設配置的上行頻寬上限)。
關於支援內網傳輸的地區,請參見ModelScope社區。
使用ACS執行個體運行Job下載模型,還需在YAML中將環境變數
INTRA_CLOUD_ACCELERATION_REGION配置為當前地區。
apiVersion: batch/v1
kind: Job
metadata:
name: download-deepseek-r1
spec:
template:
spec:
containers:
- name: downloader
image: modelscope-registry.cn-hangzhou.cr.aliyuncs.com/modelscope-repo/modelscope:ubuntu22.04-py311-torch2.3.1-1.33.0
command: ["modelscope", "download"]
# 若使用ACS執行個體運行Job下載模型,需配置env:
#env:
# - name: INTRA_CLOUD_ACCELERATION_REGION
# value: cn-wulanchabu
args:
- "--model"
- "deepseek-ai/DeepSeek-R1-0528"
- "--local_dir"
- "/mnt/oss"
- "--max-workers=32"
volumeMounts:
- name: model-storage
mountPath: /mnt/oss
volumes:
- name: model-storage
persistentVolumeClaim:
# 引用已建立的 PVC
claimName: deepseek-r1
# Job 完成後不重啟
restartPolicy: Never
# 不重試(成功或失敗均只運行一次)
backoffLimit: 0 階段二:部署模型服務
模型檔案就緒後,服務啟動時需在首次載入時高效讀取大量小檔案(如 safetensors 分區),同時兼顧記憶體開銷與穩定性。
部署情境
當前 AI 模型種類豐富,檔案格式多樣,常見的包括 safetensors(安全高效)、PyTorch(通用性強)、GGUF(適用於本地推理)等。為充分發揮OSS上模型的載入效能,建議根據實際部署架構合理配置 ossfs 2.0。
在基於 GPU 數量劃分的典型部署情境下,ossfs 2.0配置建議如下:
單 GPU 部署情境
對於單卡 GPU 的模型部署,ossfs 2.0 預設掛載配置已具備良好的載入效能。
單機多 GPU 並發部署情境
在單機多卡並發載入同一模型時,多個進程會同時讀取同一模型檔案的不同分區,易導致頻寬放大問題。為解決此問題,ossfs 2.0 支援通過
--memory_data_cache_size掛載選項開啟固定大小的記憶體緩衝機制。啟用後,模型檔案僅從 OSS 下載一次,多進程共用本機快取資料,能顯著降低網路負載與載入延遲。說明ossfs 2.0 當前提供的記憶體緩衝模式主要用於最佳化多進程並發訪問同一檔案時的頻寬放大問題,進程內的快取資料將在最後一個檔案控制代碼關閉後同步釋放。該模式不影響讀取資料後載入到作業系統PageCache的快取資料,這部分資料緩衝行為和標準模式一致。詳細說明參見掛載選項說明。
通過合理配置 ossfs 2.0,可提升各類大模型在雲端的載入效率與部署穩定性。更多資訊,請參見部署safetensors模型和部署其他格式模型。
部署safetensors模型
測試環境
本文中的效能資料和配置建議基於以下測試環境:
叢集環境:ACK託管叢集Pro版,靈駿節點池(8 GPU、192 vCPU、2 TiB記憶體),OSS下載頻寬節流設定為100 Gbps。
軟體版本:
CSI 版本v1.34.4(內建ossfs2 v2.0.5.ack.1)
鏡像
registry-cn-hangzhou.ack.aliyuncs.com/ack-demo/ossfs-public:demo-env-python3.12.7-sglang0.5.5-cuda12.8,包含Python v3.12.7,sglang v0.5.5。重要此鏡像僅用於功能驗證,請勿直接用於生產環境。
PV/PVC準備:
部署方案
ossfs 2.0 針對隨機讀密集型負載(如 safetensors 檔案載入)提供兩種部署模式,分別最佳化不同維度效能瓶頸。
方案一(效能優先):PageCache預熱部署
適用於節點記憶體充足的生產環境。通過
postStart,在容器啟動前將全部模型檔案順序載入到節點的作業系統 PageCache,將網路隨機讀轉化為高效能的“順序讀預先載入 + 記憶體隨機訪問”,顯著減少OSS網路請求和延遲。方案二(記憶體最佳化):直接部署
適用於記憶體受限或需精細化控制資源佔用的情境。ossfs 2.0 利用主動預讀與記憶體緩衝(
memory_data_cache_size)協同加速,首次載入即生效,且不受系統 PageCache 回收策略影響。
PageCache預熱部署
使用此方案時,需關註:
記憶體規劃:此方案必須為Pod配置明確的
resources.limits.memory。該值需大於模型檔案總大小 + 模型服務進程自身開銷 + 作業系統及其他進程的冗餘記憶體。若limit不足,系統記憶體壓力會導致已預熱的PageCache被回收,使預熱失效。I/O隔離:請勿在模型服務節點上混部其他高 I/O 應用(如日誌採集、備份任務),以防因系統記憶體競爭導致預熱資料被提前回收。
部署配置與實現
預熱實現:預熱通過
postStart實現,會在主程式運行前執行指令碼,通過cat操作強制系統將模型檔案讀入PageCache。相關參數:
env中新增的MODEL_DIR和PRELOADER_CONC環境變數用於向postStart指令碼提供預熱目錄和並發數。PV複用:PageCache預熱過程為順序讀,效能穩定且不受
memory_data_cache_size參數影響,可直接複用階段一的建立的 PV/PVC,無需額外配置。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: demo-apply-deepseek-r1-with-prefetch
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: demo-apply-deepseek-r1-with-prefetch
template:
metadata:
labels:
app: demo-apply-deepseek-r1-with-prefetch
spec:
volumes:
- name: model-storage
persistentVolumeClaim:
# 引用此前建立的 PVC
claimName: deepseek-r1
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 15Gi
containers:
- command:
- sh
- -c
# --tp為模型TP切分的數量,tp值非1時對應部署情境中的單機多 GPU 並發部署
- "python3 -m sglang.launch_server --model-path /models/DeepSeek-R1-0528 --tp 8"
env:
# 定義模型檔案所在的目錄路徑。若未配置或目錄不存在,指令碼將跳過資料預熱
- name: MODEL_DIR
value: /models/DeepSeek-R1-0528
# 定義預熱指令碼的並發數,預設為 4
- name: PRELOADER_CONC
value: "4"
image: registry-cn-hangzhou.ack.aliyuncs.com/ack-demo/ossfs-public:demo-env-python3.12.7-sglang0.5.5-cuda12.8
name: sglang
ports:
- containerPort: 8000
name: http
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "CONC=${PRELOADER_CONC:-4}; if [ -d \"$MODEL_DIR\" ]; then find \"$MODEL_DIR\" -type f -print0 | xargs -0 -I {} -P \"$CONC\" sh -c 'cat \"{}\" > /dev/null'; fi"]
resources:
limits:
nvidia.com/gpu: "8"
# 需為Pod配置memory limit。請根據“模型檔案總大小 + 服務進程開銷 + 系統冗餘”進行精確估算
# memory: "800Gi"
requests:
nvidia.com/gpu: "8"
volumeMounts:
- mountPath: /models/DeepSeek-R1-0528
name: model-storage
- mountPath: /dev/shm
name: dshm直接部署
該方案不依賴作業系統 PageCache,Pod 的 requests.memory 與 limits.memory 可按模型服務自身需求設定,記憶體佔用更可控。
啟用
memory_data_cache_size後,模型初次載入即可獲得緩衝加速,且該加速效果獨立於系統 PageCache 狀態,抗幹擾能力強。為簡化配置,本樣本未設定記憶體限制。生產環境中,建議根據實際負載設定
limits.memory。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: demo-apply-deepseek-r1
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: demo-apply-deepseek-r1
template:
metadata:
labels:
app: demo-apply-deepseek-r1
spec:
volumes:
- name: model-storage
persistentVolumeClaim:
# 引用此前建立的 PVC
claimName: deepseek-r1
- name: dshm
emptyDir:
medium: Memory
sizeLimit: 15Gi
containers:
- command:
- sh
- -c
# --tp為模型TP切分的數量,tp值非1時對應部署情境中的單機多 GPU 並發部署情境
- "python3 -m sglang.launch_server --model-path /models/DeepSeek-R1-0528 --tp 8"
image: registry-cn-hangzhou.ack.aliyuncs.com/ack-demo/ossfs-public:demo-env-python3.12.7-sglang0.5.5-cuda12.8
name: sglang
ports:
- containerPort: 8000
name: http
resources:
limits:
nvidia.com/gpu: "8"
requests:
nvidia.com/gpu: "8"
volumeMounts:
- mountPath: /models/DeepSeek-R1-0528
name: model-storage
- mountPath: /dev/shm
name: dshm部署時間
為量化 ossfs 2.0 在效能與穩定性上的雙重優勢,基準對比採用已啟用 -o parallel_count=64 最佳化並發的 ossfs 1.0。測試資料可展開查看。
載入時間對比
該結果僅記錄了部署過程中模型載入的時間(越小越好),測試結果中不包含服務初始化以及後續的模型預熱等步驟。
ossfs 1.0在載入DeepSeek-R1-0528模型時會寫滿系統硬碟導致系統卡死,需額外配置800 GiB的本地磁碟以支援寫入。
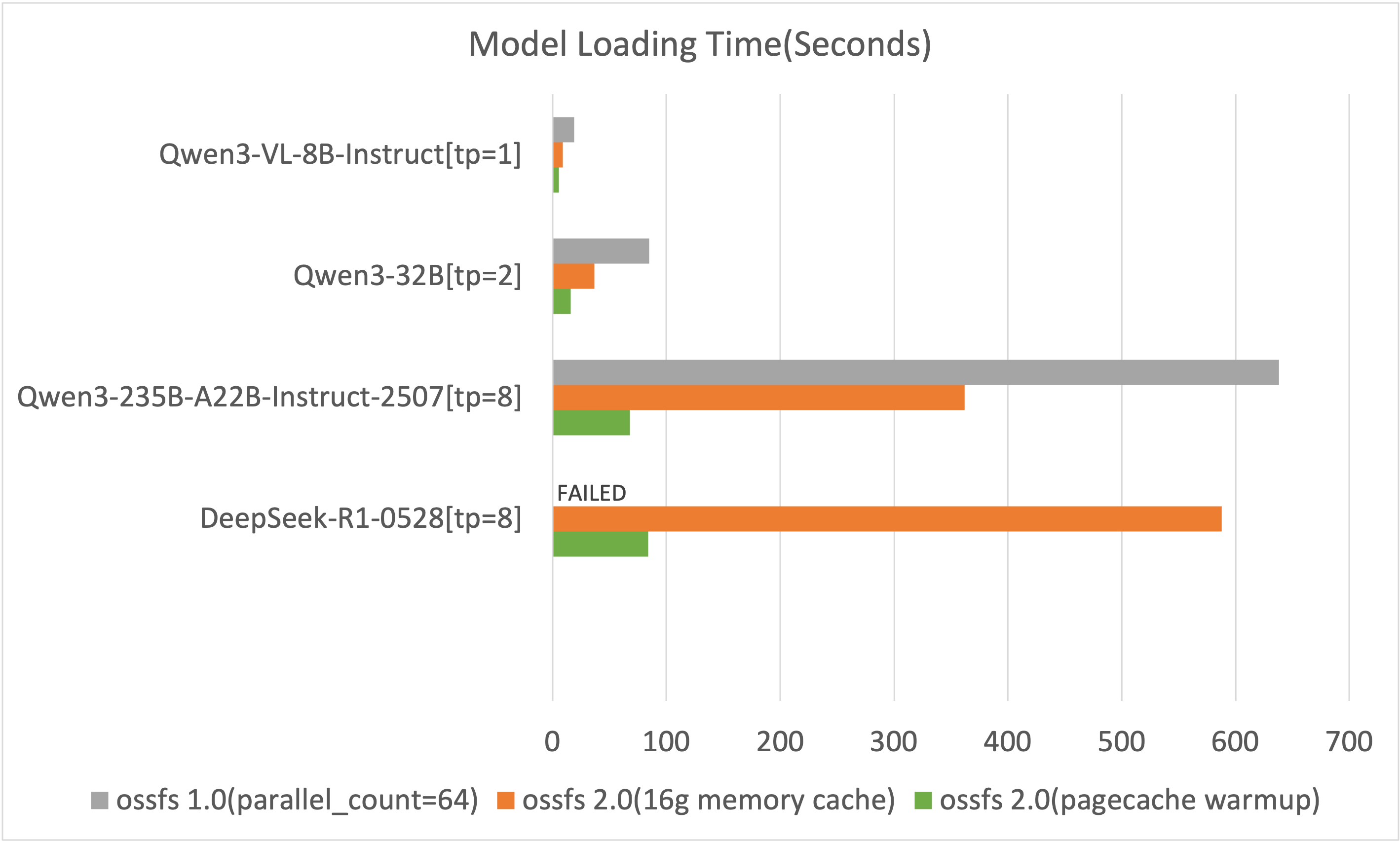
由上圖可知,ossfs 2.0相比1.0版本在模型載入時間上有顯著提升。
部署其他格式模型
GGUF模型部署
ossfs 2.0 在檔案開啟時會預分配記憶體進行資料預取,並在檔案關閉後歸還。但llama.cpp等架構在讀取GGUF模型時可能無法及時關閉已讀取的檔案控制代碼,導致預取記憶體被持續佔用而無法釋放,影響後續檔案的載入效率。
最佳化方案:
預熱部署方案(推薦):參見PageCache預熱部署,將模型完整載入到系統記憶體,規避檔案控制代碼和預取記憶體問題。
不限制預取記憶體方案:在PV的
otherOpts欄位中增加-o prefetch_chunks=-1。該配置會產生約
模型檔案數量 × 1.5 GiB的額外記憶體開銷,請在資源規劃時為此預留空間,確保節點有足夠的冗餘記憶體。PV配置樣本:
# ... PV spec... csi: volumeAttributes: fuseType: ossfs2 bucket: your-model-bucket path: /models/Your-GGUF-Model-Path url: "http://oss-cn-hangzhou-internal.aliyuncs.com" # 為GGUF模型解除預取記憶體限制 otherOpts: "-o prefetch_chunks=-1" # ... 其他認證相關配置 ...
備選方案:
若所用的GGUF模型較大且無法使用上述兩種方案,建議使用OSS Connector for AI/ML進行模型載入。
PyTorch模型部署
在多GPU情境下(如使用EasyRec部署PyTorch模型),每個GPU進程可能會獨立、順序地全量載入一次模型檔案,繼而導致對OSS的重複讀取,降低整體載入效率。
最佳化方案:
在PV的otherOpts欄位中增加-o memory_data_cache_size=4g(可根據模型大小調整)。ossfs 2.0 的共用快取機制可讓後續GPU進程直接從緩衝中讀取資料,從而有效避免對OSS的重複請求,加快整體模型載入速度。PV配置樣本:
# ... PV spec... csi: volumeAttributes: fuseType: ossfs2 bucket: your-model-bucket path: /models/Your-PyTorch-Model-Path url: "http://oss-cn-hangzhou-internal.aliyuncs.com" # 為PyTorch多GPU情境配置4GB共用快取 otherOpts: "-o memory_data_cache_size=4g" # ... 其他認證相關配置 ...
生產環境使用建議
用戶端選型:相較於ossfs 1.0,ossfs 2.0在順序讀寫效能上有顯著提升,更適合大模型部署情境。切換前請瞭解其使用限制,詳見ossfs 2.0。
記憶體資源規劃:本文介紹直接部署(
memory_data_cache_size)和PageCache預熱部署兩種加速方式均會佔用節點記憶體。生產環境中請務必提前規劃節點記憶體,確保有足夠資源供模型服務、ossfs 2.0進程及緩衝使用,避免因記憶體不足導致效能下降或Pod被驅逐。避免I/O幹擾:為保證PageCache預熱效果,請避免在模型服務節點上混部其他有大量檔案讀寫操作的應用,防止因系統記憶體競爭導致預熱資料被提前回收。
資料安全:刪除PV/PVC資源不會刪除OSS Bucket中的原始模型資料。但在操作時,請謹慎處理掛載路徑,避免因誤操作導致模型資料被意外覆蓋。
相關文檔
通過靜態PV和PVC將OSS Bucket 掛載為 ossfs 2.0 儲存卷,詳見使用ossfs 2.0靜態儲存卷。
如遇讀寫效能(如時延、吞吐)未達到預期的情況,可參見OSS儲存卷效能調優最佳實務定位並解決效能問題。