通過ossfs 2.0 的高吞吐順序寫入和智能緩衝機制,可顯著最佳化大模型在雲端的下載、儲存和部署效率,支援單GPU和多GPU並發部署情境下的高效模型載入。本文介紹如何通過ossfs 2.0下載模型以及safetensors模型在vllm/sglang架構下的部署調優實踐和部署其他類型模型的注意事項。
下載模型到OSS
ossfs 2.0 支援高吞吐的順序寫入能力,適用於大模型下載等大檔案上傳情境。使用ModelScope等工具通過ossfs 2.0可以將倉庫中的模型直接寫入到OSS Bucket中。
使用ossfs 2.0標準配置掛載OSS Bucket到指定目錄。具體配置樣本請參見常用配置樣本。
下載模型。
使用以下ModelScope命令將DeepSeek-R1-0528模型下載到ossfs 2.0的掛載點中。
modelscope download --model deepseek-ai/DeepSeek-R1-0528 --local_dir /mnt/oss/DeepSeek-R1-0528 --max-workers=32在ECS中使用ModelScope下載模型時會優先嘗試從內網倉庫下載模型。當ECS執行個體網路頻寬充足時,ossfs 2.0可高效利用網路資源,充分達到 OSS 預設配置的 20 Gbps 上行頻寬上限。
部署情境
當前 AI 模型種類豐富,檔案格式多樣,常見的包括 safetensors(安全高效)、PyTorch(通用性強)、GGUF(適用於本地推理)等。為充分發揮OSS上模型的載入效能,建議根據實際部署架構合理配置 ossfs 2.0。
在基於 GPU 數量劃分的典型部署情境下,ossfs 2.0配置建議如下:
單 GPU 部署情境
對於單卡 GPU 的模型部署,ossfs 2.0 預設掛載配置已具備良好的載入效能。
單機多 GPU 並發部署情境
在單機多卡並發載入同一模型時,多個進程會同時讀取同一模型檔案的不同分區,易導致頻寬放大問題。為解決此問題,ossfs 2.0 支援通過
--memory_data_cache_size掛載選項開啟固定大小的記憶體緩衝機制。啟用後,模型檔案僅從 OSS 下載一次,多進程共用本機快取資料,能顯著降低網路負載與載入延遲。說明ossfs 2.0 當前提供的記憶體緩衝模式主要用於最佳化多進程並發訪問同一檔案時的頻寬放大問題,進程內的快取資料將在最後一個檔案控制代碼關閉後同步釋放。該模式不影響讀取資料後載入到作業系統PageCache的快取資料,這部分資料緩衝行為和標準模式一致。詳細說明參見掛載選項說明。
通過合理配置 ossfs 2.0,可提升各類大模型在雲端的載入效率與部署穩定性。更多資訊,請參見部署safetensors模型和部署其他格式模型。
部署safetensors模型
safetensors 格式模型具有安全性高、載入速度快的特點,是當前主流的大模型儲存格式。ossfs 2.0 針對此類模型提供了最佳化的部署方案。
測試環境
測試環境:靈駿 8 GPU節點、192 vCPU、2 TiB記憶體、200 Gbps頻寬、OSS下載頻寬節流設定100 Gbps
軟體版本:ossfs 1.91.8、ossfs2 2.0.5、Python 3.12、SGLang 0.5.5
掛載方法
ossfs 1.0掛載命令
ossfs <bucket> /mnt/oss -o url=http://<endpoint> -o parallel_count=64ossfs 2.0設定檔及掛載命令
設定檔
建立設定檔
/etc/ossfs2.conf後,添加如下內容並儲存。請根據實際替換樣本中的Bucket名稱、Endpoint和AccessKey資訊。--oss_bucket=<bucket> --oss_endpoint=http://<endpoint> --oss_access_key_id=<ak> --oss_access_key_secret=<sk> # 配置16 GiB記憶體緩衝模式減少並發讀取帶來的頻寬放大 --memory_data_cache_size=16g掛載命令
ossfs2 mount /mnt/oss -c /etc/ossfs2.conf
部署方法
safetensors模型支援直接啟動模型服務或者通過PageCache預熱方式部署模型服務。
直接部署
適用於記憶體資源有限的情境。使用以下測試命令指定模型檔案路徑啟動模型服務:
python -m sglang.launch_server --model-path <model> --tensor-parallel-size <tp>(推薦)PageCache預熱部署
適用於記憶體充足的生產環境。通過預熱機制將模型檔案積極式載入至作業系統的 PageCache 中。該方式將原本的隨機(亂序)讀取轉化為 “順序讀預先載入 + 緩衝內隨機訪問” 的混合模式,顯著減少OSS網路請求次數和延遲。
使用以下命令預熱並啟動模型服務:
# 預熱資料,該命令啟動了16個進程並發cat該模型目錄下的檔案,cat完成後資料會駐留在作業系統的pagecache中
find "<model>" -type f -print0 | xargs -0 -I {} -P "16" sh -c 'cat "{}" > /dev/null && cat "{}" > /dev/null'
# 啟動服務
python -m sglang.launch_server --model-path <model> --tensor-parallel-size <tp>PageCache由作業系統管理,如果節點的空閑記憶體不足,或在容器環境中限制了容器的記憶體,則會導致已預取的資料被提前回收釋放。請確保可用記憶體超過模型總大小,並預留一部分冗餘記憶體給模型服務進程和ossfs 2.0進程使用,這部分快取資料在資料載入完畢後會由作業系統自動管理,不會永久佔用系統資源。
請確保部署模型服務的節點上不要同時存在其他業務讀取大量檔案,否則可能因為系統記憶體壓力導致預取的資料被提前回收釋放。
載入時間對比
該結果僅記錄了部署過程中模型載入的時間(越小越好),測試結果中不包含服務初始化以及後續的模型預熱等步驟。
ossfs 1.0在載入DeepSeek-R1-0528模型時會寫滿系統硬碟導致系統卡死,需額外配置800 GiB的本地磁碟以支援寫入。
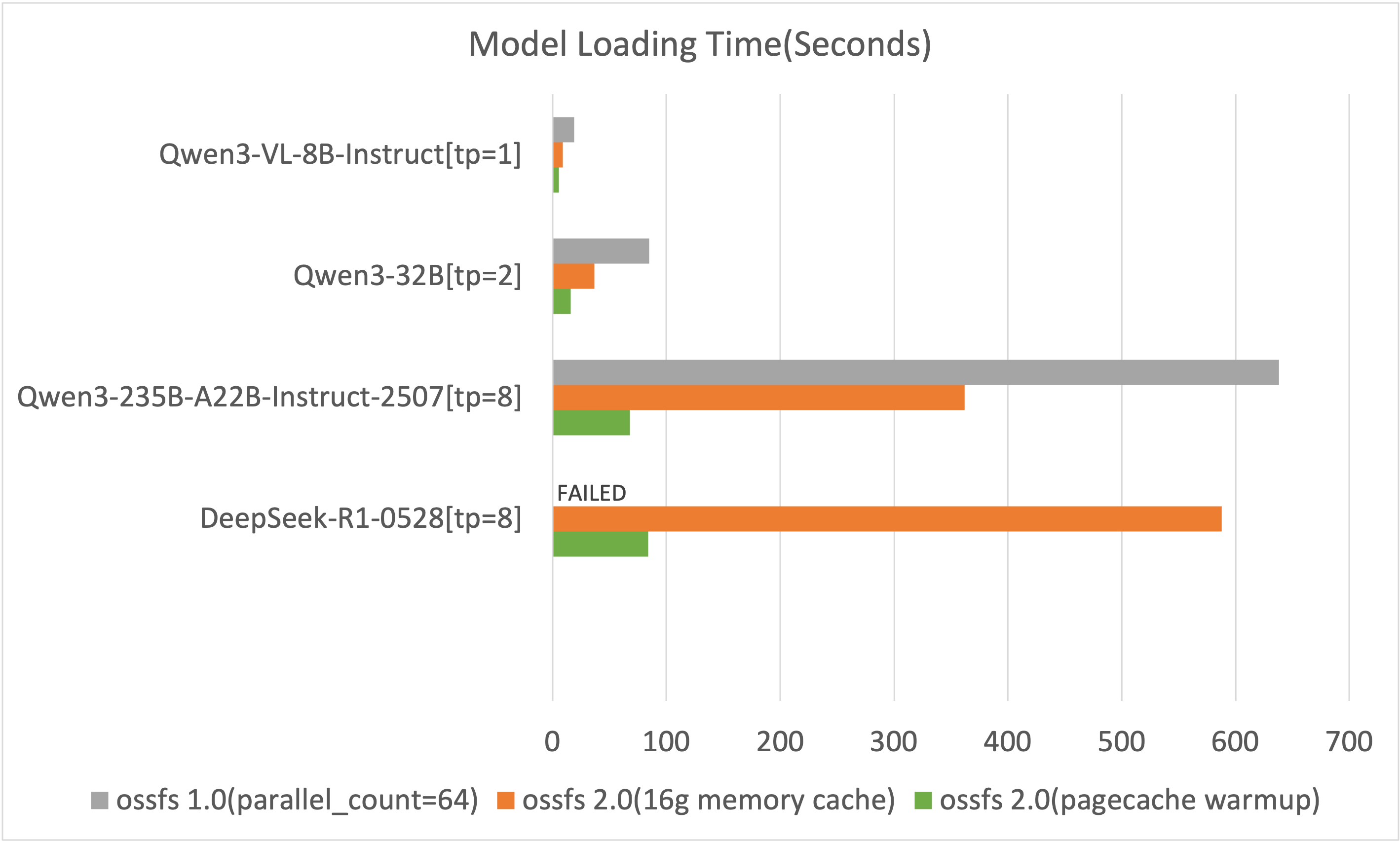
由上圖可知,ossfs 2.0相比1.0版本在模型載入時間上有顯著提升。
部署其他格式模型
GGUF模型部署注意事項
ossfs 2.0在檔案開啟後會預分配一部分記憶體進行資料預取,這部分記憶體會在檔案關閉後歸還。但由於目前llama.cpp架構在讀取資料時沒有關閉已讀取完畢的檔案控制代碼,對於檔案數量較多的模型倉庫,後續檔案沒有對應的記憶體資源進行預取,從而導致載入效率下降。
使用ossfs 2.0載入該類型模型時,有以下兩種最佳化方案:
預熱PageCache方案:具體說明請參見PageCache預熱部署。
不限制預取記憶體方案:配置
--prefetch_chunks=-1,預設配置下最多會使用約模型檔案的個數 × 1.5 GiB的額外記憶體。
如果所用的GGUF模型較大且無法使用上述兩種方案,請使用OSS Connector for AI/ML進行模型載入。
PyTorch模型部署注意事項
在多GPU情境下使用EasyRec部署PyTorch模型,每個GPU會順序全量載入一次模型檔案。配置--memory_data_cache_size=4g掛載選項可有效減少並發讀取帶來的頻寬放大,加快整體模型載入效率。