ACK Edge叢集可以納管資料中心和邊緣側的GPU節點,統一管理多地區、多環境的異構算力。您可以在ACK Edge叢集中接入阿里雲Prometheus監控,使資料中心和邊緣計算的GPU節點擁有與雲上一致的可觀測能力。
邊緣節點可觀測原理
ACK Edge叢集支援通過專線和公網兩種方式接入IaaS資源(例如IDC節點、第三方雲廠商節點、IoT裝置等)。在專線情境下,邊緣節點通過專線與雲端實現網路互連,確保Prometheus能夠直接存取邊緣節點,從而保證可觀測能力的正常運行。在公網情境下,Prometheus通過Raven組件實現對邊緣節點的可觀測能力。具體實現步驟如下:
Prometheus是通過節點名稱而非節點IP來採集指標,在網域名稱解析時,CoreDNS配置了Hosts外掛程式,將邊緣節點名稱解析至Raven Service。
Prometheus訪問Raven Service時,最終從Service後端選擇一個網關節點,與邊緣側的網路域進行通訊。
網關節點上的Raven-agent會與IDC網關節點上的Raven-agent建立加密通道,支援三層和七層網路通訊。
在IDC網路域的網關節點上,Raven-agent通過訪問目標節點的GPU採集連接埠來擷取監控資料。
監控邊緣GPU節點
步驟一:開啟阿里雲Prometheus監控
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在Prometheus 監控頁面,按照頁面提示完成相關組件的安裝和監控大盤的檢查。
控制台會自動安裝組件、檢查監控大盤。安裝完成後,您可以單擊各個頁簽查看相應監控資料。
步驟二:添加邊緣GPU節點
添加邊緣GPU節點具體操作,請參見添加GPU節點。
步驟三:在接入的GPU節點上部署應用以驗證GPU相關指標正確性
本樣本以運行TensorFlow Benchmark專案為例進行介紹,採用獨佔GPU調度能力,您還可以在邊緣GPU節點上運行共用GPU的應用,請參見通過共用GPU調度實現多卡共用。
建立Job任務,並將其儲存為tensorflow.yaml檔案。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-exclusive spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-exclusive spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: nvidia.com/gpu: 1 #申請1張GPU卡。 workingDir: /root restartPolicy: Never在叢集中部署Job任務。
kubectl apply -f tensorflow.yaml
步驟四:查看GPU監控大盤
登入Container Service管理主控台,在左側導覽列選擇叢集列表。
在叢集列表頁面,單擊目的地組群名稱,然後在左側導覽列,選擇。
在Prometheus 監控頁面,單擊GPU 監控頁簽。
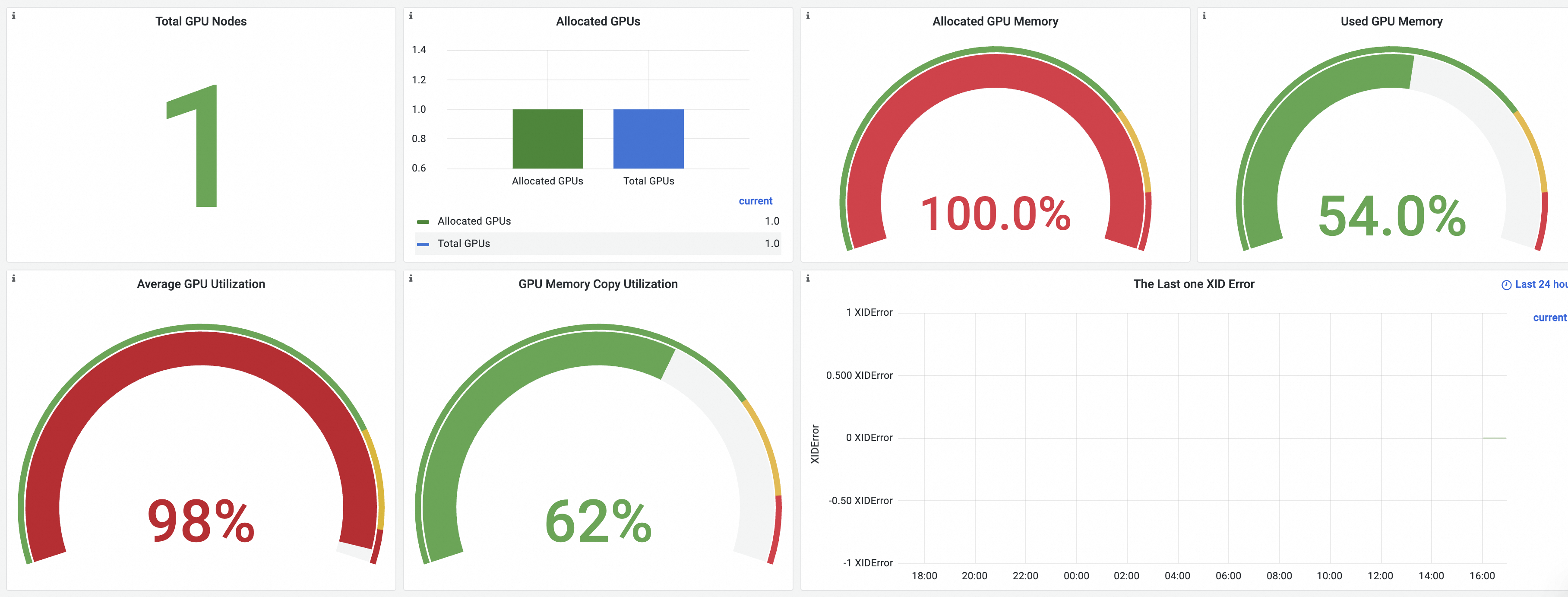
單擊叢集GPU監控-叢集維度頁簽,可查看叢集維度大盤,關於大盤詳細介紹,請參見查看叢集GPU監控-叢集維度。
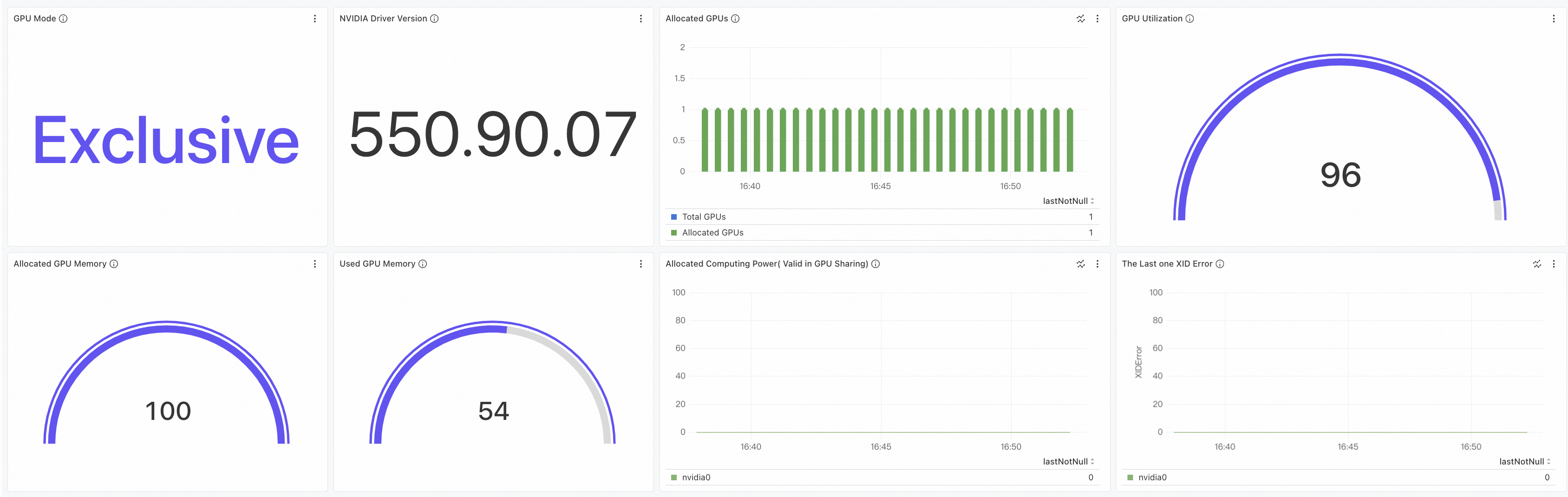
單擊叢集GPU監控-節點維度頁簽,可查看GPU節點維度大盤。關於大盤詳細介紹,請參見查看叢集GPU監控-節點維度。
步驟五:查看邊緣GPU節點監控指標
GPU監控使用的GPU Exporter在相容開源DCGM Exporter提供的監控指標的基礎上,根據某些業務情境,增加了自訂指標。關於DCGM Exporter的更多資訊,請參見DCGM Exporter。
GPU監控中所涉及的GPU監控指標包括DCGM支援的指標和自訂指標,您可以通過以下操作查看GPU相關的監控指標。
GPU監控使用自訂指標會引起額外的費用。
為避免產生額外的費用,建議在啟用此功能前,仔細閱讀阿里雲Prometheus的計費概述,瞭解自訂指標的收費策略。費用將根據您的叢集規模和應用數量等因素產生變動。您可以通過資源消耗統計功能,監控和管理您的資源使用方式。
登入ARMS控制台。
在左側導覽列選擇。
在頁面頂部下拉框選擇目標執行個體。
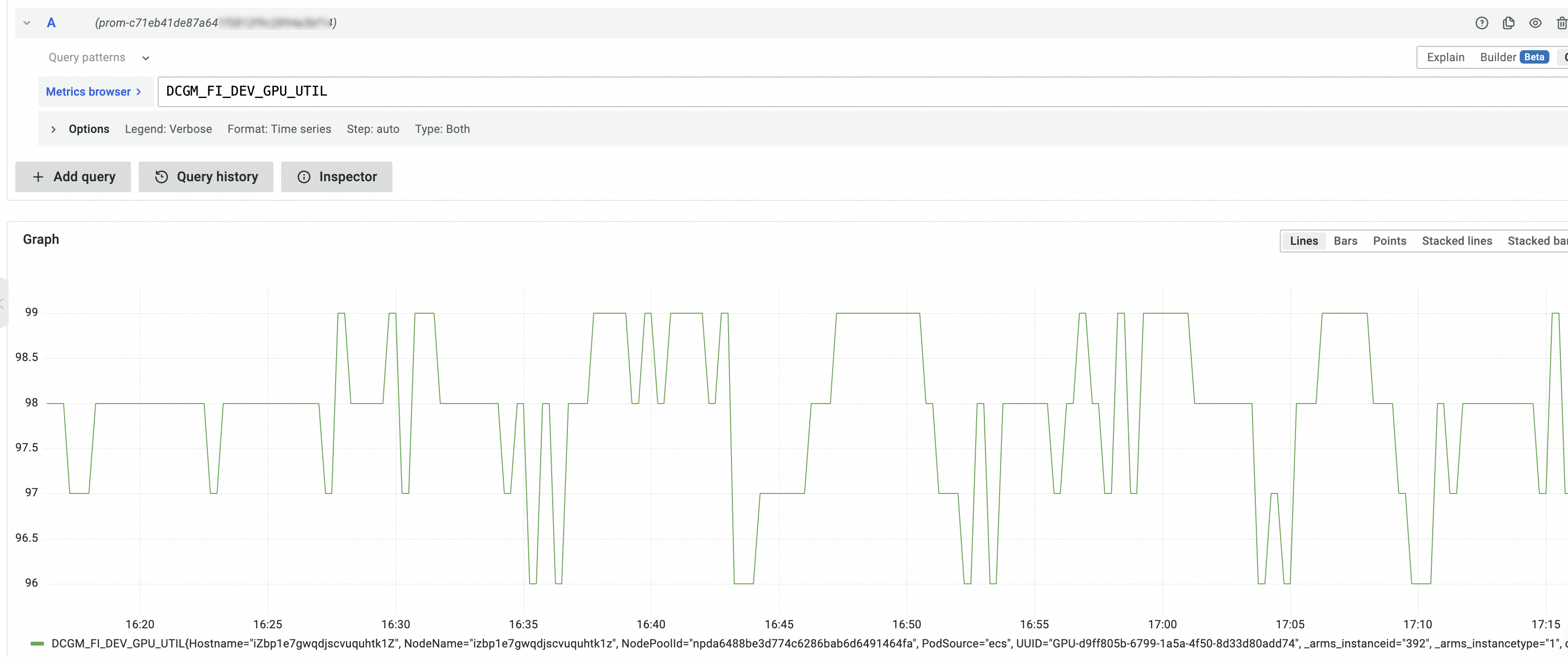
在A地區設定查詢指標,然後單擊Run query。