This tutorial shows how to build a retrieval-augmented generation (RAG) chatbot that answers questions from your own knowledge base. The chatbot uses ApsaraDB RDS for PostgreSQL with the pgvector extension to store and search vector embeddings, and OpenAI to generate answers.
Tech stack:
ApsaraDB RDS for PostgreSQL + pgvector: vector storage and similarity search
OpenAI
text-embedding-ada-002: converts text to vector embeddingsOpenAI
gpt-3.5-turbo/text-davinci-003: generates answersPython + psycopg2 + LangChain-compatible splitting: knowledge base ingestion
What you'll build:
A data pipeline that splits your knowledge base into text chunks, converts them to vector embeddings, and stores them in RDS PostgreSQL.
A Q&A function that embeds an incoming question, retrieves the most relevant chunks by cosine similarity, and passes them to an LLM for a grounded answer.
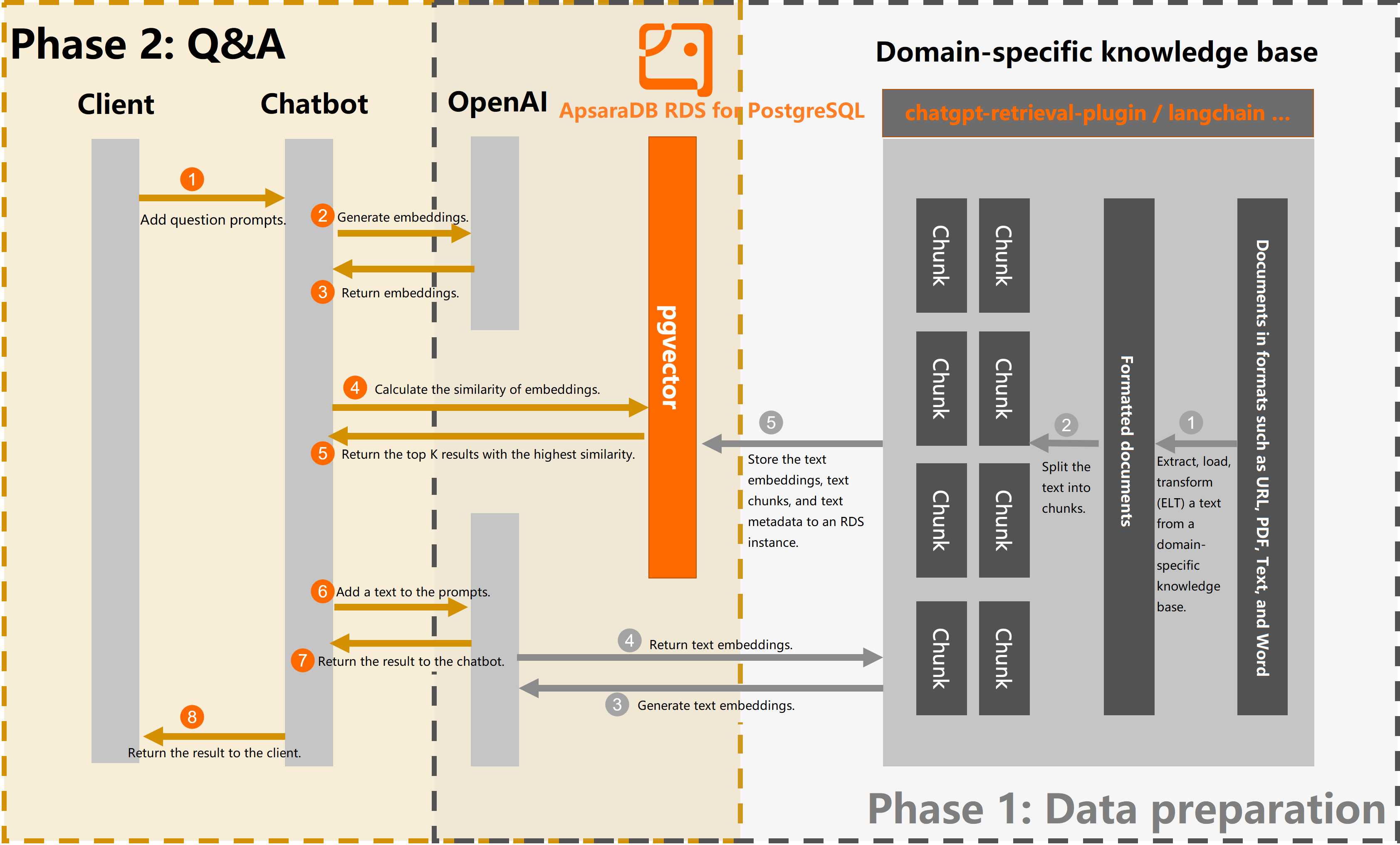
How it works
Phase 1: Data preparation
Split documents from your knowledge base into text chunks.
Call the OpenAI Embeddings API to convert each chunk into a 1536-dimension vector embedding.
Store the text chunks, their embeddings, and metadata in your RDS instance.
Phase 2: Q&A
Convert an incoming question to a vector embedding using the same OpenAI model.
Query the RDS instance to find text chunks with a cosine similarity score above the threshold.
Pass the matching chunks to an LLM to generate a grounded answer.
The following figure shows the end-to-end process.
Prerequisites
Before you begin, make sure you have:
An ApsaraDB RDS for PostgreSQL instance running PostgreSQL 14 or later, with minor engine version 20230430 or later
To upgrade the major engine version, see Upgrade the major engine version. To update the minor engine version, see Update the minor engine version.
Familiarity with the pgvector extension — see Use the pgvector extension to perform high-dimensional vector similarity searches for background
An OpenAI Secret API key with network access to the OpenAI API (the sample code in this tutorial runs on an Elastic Compute Service (ECS) instance in the Singapore region)
Python 3.11.4 and PyCharm 2023.1.2 (or a compatible Python environment)
Key concepts
Embedding
An embedding represents text as a fixed-length numeric vector, capturing semantic meaning so that similar texts produce similar vectors. In this tutorial, each text chunk and each user question is converted to a 1536-dimension vector using OpenAI's text-embedding-ada-002 model.
Why ApsaraDB RDS for PostgreSQL for RAG
ApsaraDB RDS for PostgreSQL with the pgvector extension lets you run vector similarity searches inside the same database that handles your application's transactional data — chat history, user records, session state — without maintaining a separate vector store.
Phase 1: Prepare the knowledge base
Step 1: Set up the database
Create a test database.
CREATE DATABASE rds_pgvector_test;Switch to the database and enable the pgvector extension.
CREATE EXTENSION IF NOT EXISTS vector;Create a table to store knowledge base chunks and their embeddings.
CREATE TABLE rds_pg_help_docs ( id bigserial PRIMARY KEY, title text, description text, doc_chunk text, token_size int, embedding vector(1536) );The table stores the following fields for each text chunk:
Column Data type Description idbigserial Auto-incrementing primary key titletext Source document title descriptiontext Source document description doc_chunktext Text chunk content token_sizeint Number of tokens in the chunk embeddingvector(1536) Vector embedding generated by the embedding model The dimension
1536matches the output of OpenAI'stext-embedding-ada-002model. If you use a different embedding model, update this value to match its output dimensions.Create an ivfflat index on the
embeddingcolumn to speed up similarity searches.For guidance on choosing index types and parameters for vector indexes, see Use the pgvector extension to perform high-dimensional vector similarity searches.
CREATE INDEX ON rds_pg_help_docs USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
Step 2: Install Python dependencies
In PyCharm, open the terminal and run:
pip install openai psycopg2 tiktoken requests beautifulsoup4 numpyStep 3: Split and store knowledge base content
Create a file named knowledge_chunk_storage.py with the following code. This script fetches a web page, splits the HTML content into fixed-size text chunks, generates an embedding for each chunk, and stores the results in your RDS instance.
The example below uses a fixed character count to split content. For production use, consider the splitting utilities in LangChain or the ChatGPT Retrieval Plugin, which support Markdown, PDF, Word, and other formats. Chunking quality directly affects retrieval accuracy.
Replace the following placeholders before running:
| Placeholder | Description | Example |
|---|---|---|
<Database name> | Name of the database you created | rds_pgvector_test |
<Endpoint of the RDS instance> | Public or private endpoint of the RDS instance | pgm-xxx.pg.rds.aliyuncs.com |
<Username> | Database account username | myuser |
<Password> | Database account password | — |
<Database port number> | Listening port | 5432 |
<Secret API Key> | Your OpenAI Secret API key | — |
import openai
import psycopg2
import tiktoken
import requests
from bs4 import BeautifulSoup
EMBEDDING_MODEL = "text-embedding-ada-002"
tokenizer = tiktoken.get_encoding("cl100k_base")
# Connect to the RDS instance
conn = psycopg2.connect(
database="<Database name>",
host="<Endpoint of the RDS instance>",
user="<Username>",
password="<Password>",
port="<Database port number>"
)
conn.autocommit = True
# OpenAI API key
openai.api_key = '<Secret API Key>'
# Split HTML content into fixed-size character chunks
def get_text_chunks(text, max_chunk_size):
chunks_ = []
soup_ = BeautifulSoup(text, 'html.parser')
content = ''.join(soup_.strings).strip()
length = len(content)
start = 0
while start < length:
end = min(start + max_chunk_size, length)
chunks_.append(content[start:end])
start = end
return chunks_
# Fetch the source document
url = 'https://www.alibabacloud.com/help/document_detail/148038.html'
response = requests.get(url)
if response.status_code == 200:
web_html_data = response.text
soup = BeautifulSoup(web_html_data, 'html.parser')
# Extract title and description
title = soup.find('h1').text.strip()
description = soup.find('p', class_='shortdesc').text.strip()
# Split content into 500-character chunks and store with embeddings
chunks = get_text_chunks(web_html_data, 500)
for chunk in chunks:
doc_item = {
'title': title,
'description': description,
'doc_chunk': chunk,
'token_size': len(tokenizer.encode(chunk))
}
# Generate embedding for the chunk
query_embedding_response = openai.Embedding.create(
model=EMBEDDING_MODEL,
input=chunk,
)
doc_item['embedding'] = query_embedding_response['data'][0]['embedding']
# Insert into RDS
cur = conn.cursor()
insert_query = '''
INSERT INTO rds_pg_help_docs
(title, description, doc_chunk, token_size, embedding)
VALUES (%s, %s, %s, %s, %s);
'''
cur.execute(insert_query, (
doc_item['title'],
doc_item['description'],
doc_item['doc_chunk'],
doc_item['token_size'],
doc_item['embedding']
))
conn.commit()
else:
print('Failed to fetch web page')Step 4: Run and verify
Run the
knowledge_chunk_storage.pyscript.Log in to the database and verify that data was stored correctly.
SELECT * FROM rds_pg_help_docs;The output lists rows with populated
doc_chunk,token_size, andembeddingcolumns.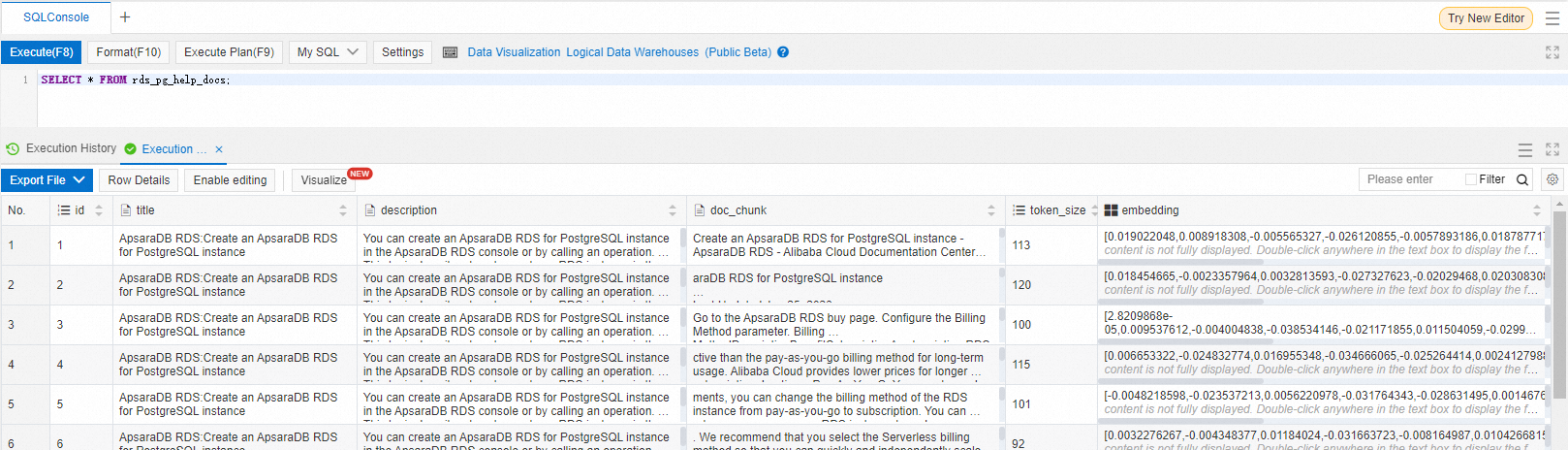
Phase 2: Build the Q&A function
Create a file named chatbot.py. The key parameters are listed at the top of the script.
| Parameter | Value | Description |
|---|---|---|
GPT_MODEL | gpt-3.5-turbo | Chat model |
EMBEDDING_MODEL | text-embedding-ada-002 | Embedding model (must match phase 1) |
GPT_COMPLETIONS_MODEL | text-davinci-003 | Completions model for answer generation |
MAX_TOKENS | 1024 | Maximum tokens in a single LLM response |
similarity_threshold | 0.78 | Minimum cosine similarity score for a chunk to be retrieved |
max_matched_doc_counts | 8 | Maximum number of matching chunks to retrieve |
The Q&A flow works as follows: embed the question using the same model as phase 1, retrieve chunks with cosine similarity above similarity_threshold, batch them into groups of up to 1,000 tokens, and call the LLM once per batch.
import openai
import psycopg2
from psycopg2.extras import DictCursor
GPT_MODEL = "gpt-3.5-turbo"
EMBEDDING_MODEL = "text-embedding-ada-002"
GPT_COMPLETIONS_MODEL = "text-davinci-003"
MAX_TOKENS = 1024
# OpenAI API key
openai.api_key = '<Secret API Key>'
# The question to answer
prompt = 'Create an RDS instance.'
# Embed the question
prompt_response = openai.Embedding.create(
model=EMBEDDING_MODEL,
input=prompt,
)
prompt_embedding = prompt_response['data'][0]['embedding']
# Connect to the RDS instance
conn = psycopg2.connect(
database="<Database name>",
host="<Endpoint of the RDS instance>",
user="<Username>",
password="<Password>",
port="<Database port number>"
)
conn.autocommit = True
def answer(prompt_doc, prompt):
"""Send matching chunks and the question to the LLM and print the answer."""
improved_prompt = f"""
Answer the following questions based on the following file and steps:
a. Check whether the content in the file is related to the question.
b. Reference the content in the file to answer the question and provide the detailed answer as a Markdown file.
c. Use "I don't know because the question is beyond my scope" to answer the questions that are irrelevant to ApsaraDB RDS for PostgreSQL.
File:
\"\"\"
{prompt_doc}
\"\"\"
Question: {prompt}
"""
response = openai.Completion.create(
model=GPT_COMPLETIONS_MODEL,
prompt=improved_prompt,
temperature=0.2,
max_tokens=MAX_TOKENS
)
print(f"{response['choices'][0]['text']}\n")
# Retrieve text chunks with cosine similarity above the threshold
similarity_threshold = 0.78
max_matched_doc_counts = 8
similarity_search_sql = f'''
SELECT doc_chunk, token_size, 1 - (embedding <=> '{prompt_embedding}') AS similarity
FROM rds_pg_help_docs
WHERE 1 - (embedding <=> '{prompt_embedding}') > {similarity_threshold}
ORDER BY id
LIMIT {max_matched_doc_counts};
'''
cur = conn.cursor(cursor_factory=DictCursor)
cur.execute(similarity_search_sql)
matched_docs = cur.fetchall()
# Batch chunks into groups of up to 1,000 tokens and call the LLM per batch
total_tokens = 0
prompt_doc = ''
print('Answer: \n')
for matched_doc in matched_docs:
if total_tokens + matched_doc['token_size'] <= 1000:
prompt_doc += f"\n---\n{matched_doc['doc_chunk']}"
total_tokens += matched_doc['token_size']
continue
answer(prompt_doc, prompt)
total_tokens = 0
prompt_doc = ''
answer(prompt_doc, prompt)Run the script. The chatbot prints an answer grounded in your knowledge base.
To improve answer accuracy, refine the text chunking strategy and adjust the prompt template in the answer() function.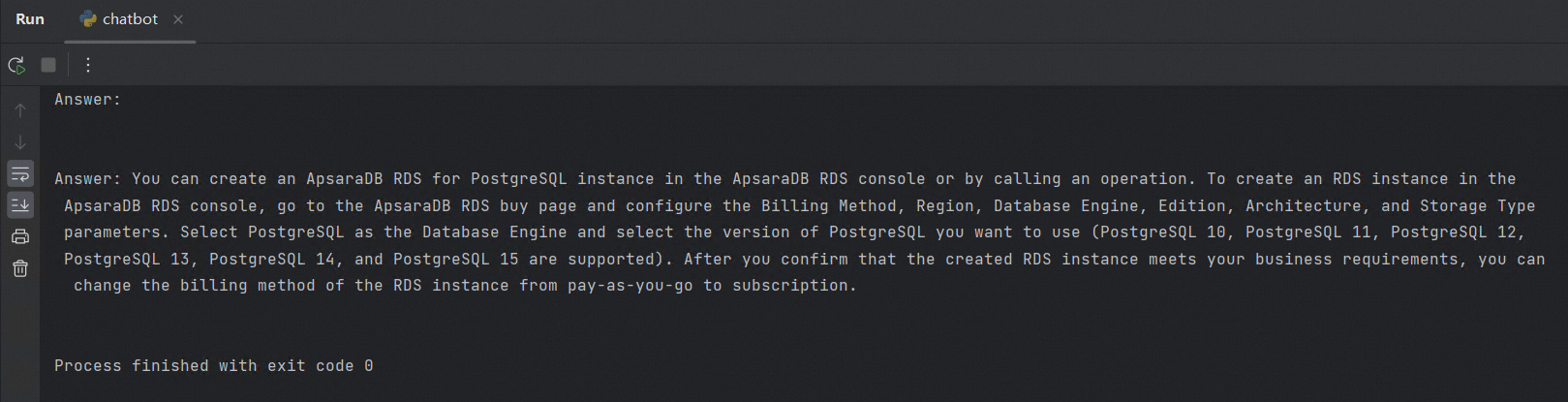
Results
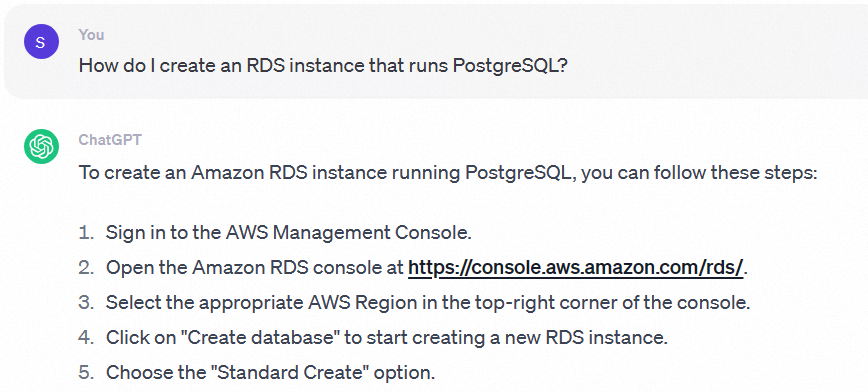
Without a connected knowledge base, OpenAI has no context about Alibaba Cloud products. The answer to "How do I create an ApsaraDB RDS for PostgreSQL instance?" is generic and unrelated to ApsaraDB RDS.
After connecting the knowledge base stored in your RDS instance, the same question returns an answer specific to ApsaraDB RDS for PostgreSQL, drawn directly from your ingested documentation.
What's next
Improve retrieval accuracy by using LangChain or the ChatGPT Retrieval Plugin for more sophisticated document chunking and ingestion.
Learn more about vector indexing options and similarity operators in Use the pgvector extension to perform high-dimensional vector similarity searches.