このトピックでは、集計操作を実行してデータを分析する方法について説明します。集計操作を実行して、行の最小値、最大値、合計、平均値、カウント、個別カウント、パーセンタイル統計を取得できます。また、集計操作を実行して、フィールド値、範囲、地理的位置、フィルター、ヒストグラム、または日付ヒストグラム別に結果をグループ化し、ネストされたクエリを実行し、各グループの集計操作の結果から取得された行をクエリすることもできます。複雑なクエリに対して複数の集計操作を実行できます。
手順
次の図は、完全な集計手順を示しています。
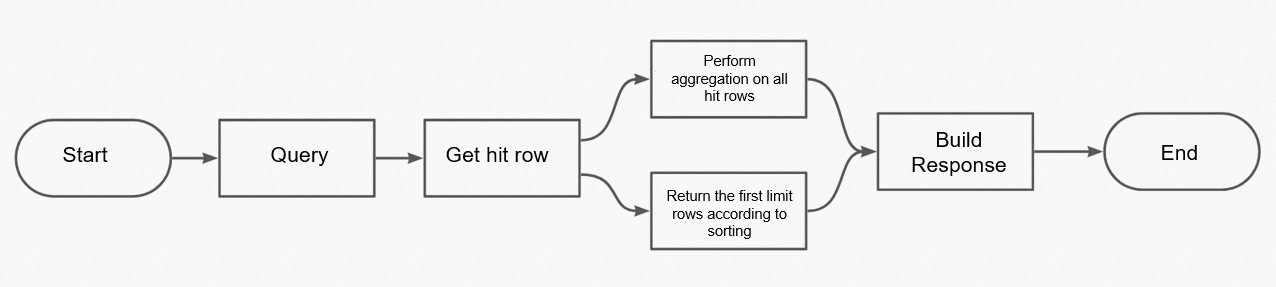
サーバーは、クエリ条件を満たすデータをクエリし、リクエストに基づいてデータの集計を実行します。したがって、集計を必要とするリクエストは、集計を必要としないリクエストよりも処理が複雑になります。
背景情報
次の表に、集計方法を示します。
メソッド | 説明 |
最小値 | フィールドの最小値を返すために使用できる集計方法。このメソッドは、SQL の MIN 演算子と同様の方法で使用できます。 |
最大値 | フィールドの最大値を返すために使用できる集計方法。このメソッドは、SQL の MAX 演算子と同様の方法で使用できます。 |
そして | 数値フィールドのすべての値の合計を返すために使用できる集計方法。このメソッドは、SQL の SUM 演算子と同様の方法で使用できます。 |
平均値 | 数値フィールドのすべての値の平均を返すために使用できる集計方法。このメソッドは、SQL の AVG 演算子と同様の方法で使用できます。 |
カウント | フィールドの値の総数または検索インデックス内の行の総数を返すために使用できる集計方法。このメソッドは、SQL の COUNT 演算子と同様の方法で使用できます。 |
個別カウント | フィールドの個別値の数を返すために使用できる集計方法。このメソッドは、SQL の COUNT(DISTINCT) 演算子と同様の方法で使用できます。 |
パーセンタイル統計 | パーセンタイル値は、データセット内の値の相対位置を示します。たとえば、システムの日常的な O&M 中に各リクエストの応答時間の統計を収集する場合、p25、p50、p90、p99 などのパーセンタイルを使用して応答時間分布を分析する必要があります。 |
フィールド値によるグループ化 | フィールド値に基づいてクエリ結果をグループ化するために使用できる集計方法。同じ値は一緒にグループ化されます。各グループの値と各グループのメンバー数が返されます。 説明 フィールド値によるグループ化は並列計算を使用し、正確な計算ではありません。わずかな誤差がある可能性があります。 |
複数フィールドによるグループ化 | 複数のフィールドに基づいてクエリ結果をグループ化するために使用できる集計方法。トークンを使用してページングを実行できます。 |
ネストされたグループ化 | GroupBy はネストをサポートしています。 GroupBy を使用してサブ集計操作を実行できます。 |
範囲によるグループ化 | フィールドの値の範囲に基づいてクエリ結果をグループ化するために使用できる集計方法。特定の範囲内にあるフィールド値は一緒にグループ化されます。各範囲の値の数が返されます。 |
地理的位置によるグループ化 | 地理的位置から中心点までの距離に基づいてクエリ結果をグループ化するために使用できる集計方法。特定の範囲内にある距離のクエリ結果は一緒にグループ化されます。各範囲の値の数が返されます。 |
フィルターによるグループ化 | クエリ結果をフィルタリングし、各フィルターに基づいてグループ化して、一致する結果の数を取得するために使用できる集計方法。結果は、フィルターが指定された順序で返されます。 |
ヒストグラムによるクエリ | この集計方法を使用して、特定のデータ間隔に基づいてクエリ結果をグループ化できます。同じ範囲内にあるフィールド値は一緒にグループ化されます。各グループの値の範囲と各グループの値の数が返されます。 |
日付ヒストグラムによるクエリ | 特定の日付間隔に基づいてクエリ結果をグループ化するために使用できる集計方法。同じ範囲内にあるフィールド値は一緒にグループ化されます。各グループの値の範囲と各グループの値の数が返されます。 |
各グループの集計操作の結果から取得された行のクエリ | クエリ結果をグループ化した後、各グループの行をクエリできます。このメソッドは、MySQL の ANY_VALUE(field) と同様の方法で使用できます。 |
複数集計 | 複数の集計操作を実行できます。 説明 複数の複雑な集計操作を同時に実行すると、長時間がかかる場合があります。 |
前提条件
OTSClient インスタンスが初期化されています。詳細については、「Tablestore クライアントの初期化」をご参照ください。
データテーブルが作成され、データがデータテーブルに書き込まれています。詳細については、「データテーブルの作成」および「データの書き込み」をご参照ください。
データテーブルの検索インデックスが作成されます。詳細については、「検索インデックスを作成する」をご参照ください。
重要集約機能でサポートされているフィールドタイプは、検索インデックスでサポートされているフィールドタイプです。 検索インデックスでサポートされているフィールドタイプ、および検索インデックスでサポートされているフィールドタイプとデータテーブルでサポートされているフィールドタイプ間のマッピングについては、「データ型」をご参照ください。
最小値
フィールドの最小値を返すために使用できる集計方法。このメソッドは、SQL の MIN 演算子と同様の方法で使用できます。
パラメーター
パラメーター
説明
aggregationName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果を照会できます。
fieldName
集計操作を実行するために使用されるフィールドの名前。Long、Double、および Date タイプのみがサポートされています。
missing
集計操作が実行されるフィールドのデフォルト値。フィールド値が空の行に適用されます。
missing パラメーターの値を指定しない場合、行は無視されます。
missing パラメーターの値を指定した場合、このパラメーターの値が行のフィールド値として使用されます。
例
/** * 各製品の価格は product テーブルにリストされています。浙江省で生産された製品の最低価格を照会します。 * SQL 文: SELECT min(column_price) FROM product where place_of_production="Zhejiang". */ public void min(SyncClient client) { // builder を使用してクエリステートメントを作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) // 特定のデータではなく集計結果のみを取得する場合、 limit を 0 に設定してクエリのパフォーマンスを向上させることができます。 .addAggregation(AggregationBuilders.min("min_agg_1", "column_price").missing(100)) .build()) .build(); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsMinAggregationResult("min_agg_1").getValue()); } // builder を使用せずにクエリステートメントを作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); // 次のコメントでは、 builder を使用してクエリステートメントを作成しています。 builder を使用してクエリステートメントを作成する方法は、 TermQuery を使用してクエリステートメントを作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); MinAggregation aggregation = new MinAggregation(); aggregation.setAggName("min_agg_1"); aggregation.setFieldName("column_price"); aggregation.setMissing(ColumnValue.fromLong(100)); // 次のコメントでは、 builder を使用してクエリステートメントを作成しています。 builder を使用してクエリステートメントを作成する方法は、 aggregation を使用してクエリステートメントを作成する方法と同じ効果があります。 // MinAggregation aggregation2 = AggregationBuilders.min("min_agg_1", "column_price").missing(100).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsMinAggregationResult("min_agg_1").getValue()); } }
最大値
フィールドの最大値を返すために使用できる集計方法。このメソッドは、SQL の MAX 演算子と同様の方法で使用できます。
パラメーター
パラメーター
説明
aggregationName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果を照会できます。
fieldName
集計操作を実行するために使用されるフィールドの名前。Long、Double、および Date タイプのみがサポートされています。
missing
集計操作が実行されるフィールドのデフォルト値。フィールド値が空の行に適用されます。
missing パラメーターの値を指定しない場合、行は無視されます。
missing パラメーターの値を指定した場合、このパラメーターの値が行のフィールド値として使用されます。
例
/** * 各製品の価格は product テーブルに記載されています。浙江省で生産された製品の最高価格を照会します。 * SQL 文: SELECT max(column_price) FROM product where place_of_production="Zhejiang". */ public void max(SyncClient client) { // ビルダーを使用してクエリステートメントを作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) // 特定のデータではなく集計結果のみを取得する場合、クエリのパフォーマンスを向上させるために limit を 0 に設定できます。 .addAggregation(AggregationBuilders.max("max_agg_1", "column_price").missing(0)) .build()) .build(); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsMaxAggregationResult("max_agg_1").getValue()); } // ビルダーを使用せずにクエリステートメントを作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); // 次のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成する方法は、TermQuery を使用してクエリステートメントを作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); MaxAggregation aggregation = new MaxAggregation(); aggregation.setAggName("max_agg_1"); aggregation.setFieldName("column_price"); aggregation.setMissing(ColumnValue.fromLong(100)); // 次のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成する方法は、aggregation を使用してクエリステートメントを作成する方法と同じ効果があります。 // MaxAggregation aggregation2 = AggregationBuilders.max("max_agg_1", "column_price").missing(100).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsMaxAggregationResult("max_agg_1").getValue()); } }
および
数値フィールドのすべての値の合計を返すために使用できる集計方法。このメソッドは、SQL の SUM 演算子と同様の方法で使用できます。
パラメーター
パラメーター
説明
aggregationName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果を照会できます。
fieldName
集計操作を実行するために使用されるフィールドの名前。Long 型と Double 型のみがサポートされています。
missing
集計操作が実行されるフィールドのデフォルト値。フィールド値が空の行に適用されます。
missing パラメーターの値を指定しない場合、行は無視されます。
missing パラメーターの値を指定した場合、このパラメーターの値が行のフィールド値として使用されます。
例
/** * 各製品の価格は product テーブルに記載されています。浙江省で生産された製品の最高価格を照会します。 * SQL 文: SELECT sum(column_price) FROM product where place_of_production="Zhejiang". */ public void sum(SyncClient client) { // ビルダーを使用してクエリステートメントを作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) // 特定のデータではなく集計結果のみを取得する場合、 limit を 0 に設定してクエリのパフォーマンスを向上させることができます。 .addAggregation(AggregationBuilders.sum("sum_agg_1", "column_number").missing(10)) .build()) .build(); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsSumAggregationResult("sum_agg_1").getValue()); } // ビルダーを使用せずにクエリステートメントを作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); // 次のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成する方法は、 TermQuery を使用してクエリステートメントを作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); SumAggregation aggregation = new SumAggregation(); aggregation.setAggName("sum_agg_1"); aggregation.setFieldName("column_number"); aggregation.setMissing(ColumnValue.fromLong(100)); // 次のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成する方法は、 aggregation を使用してクエリステートメントを作成する方法と同じ効果があります。 // SumAggregation aggregation2 = AggregationBuilders.sum("sum_agg_1", "column_number").missing(10).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsSumAggregationResult("sum_agg_1").getValue()); } }
平均値
数値フィールドのすべての値の平均を返すために使用できる集計方法。このメソッドは、SQL の AVG 演算子と同様の方法で使用できます。
パラメーター
パラメーター
説明
aggregationName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果を照会できます。
fieldName
集計操作を実行するために使用されるフィールドの名前。Long、Double、および Date タイプのみがサポートされています。
missing
集計操作が実行されるフィールドのデフォルト値。フィールド値が空の行に適用されます。
missing パラメーターの値を指定しない場合、行は無視されます。
missing パラメーターの値を指定した場合、このパラメーターの値が行のフィールド値として使用されます。
例
/** * 各製品の売上高は product テーブルに一覧表示されています。浙江省で生産された製品の平均価格を照会します。 * SQL 文: SELECT avg(column_price) FROM product where place_of_production="Zhejiang". */ public void avg(SyncClient client) { // ビルダーを使用してクエリステートメントを作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) // 特定のデータではなく集計結果のみを取得する場合、 limit を 0 に設定してクエリのパフォーマンスを向上させることができます。 .addAggregation(AggregationBuilders.avg("avg_agg_1", "column_price")) .build()) .build(); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsAvgAggregationResult("avg_agg_1").getValue()); } // ビルダーを使用せずにクエリステートメントを作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); // 次のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成するメソッドは、 TermQuery を使用してクエリステートメントを作成するメソッドと同じ効果があります。 // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); AvgAggregation aggregation = new AvgAggregation(); aggregation.setAggName("avg_agg_1"); aggregation.setFieldName("column_price"); // 次のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成するメソッドは、 aggregation を使用してクエリステートメントを作成するメソッドと同じ効果があります。 // AvgAggregation aggregation2 = AggregationBuilders.avg("avg_agg_1", "column_price").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsAvgAggregationResult("avg_agg_1").getValue()); } }
カウント
フィールドの値の総数、または検索インデックスの行の総数を返すために使用できる集計メソッド。このメソッドは、SQL の COUNT オペレーターと同様の方法で使用できます。
次のメソッドを使用して、検索インデックスの行の総数、またはクエリ条件を満たす行の総数をクエリできます。
集計の count 機能を使用します。リクエストで count パラメーターを * に設定します。
クエリ機能を使用して、クエリ条件を満たす行の数を取得します。クエリで setGetTotalCount パラメーターを true に設定します。 MatchAllQuery を使用して、検索インデックスの行の総数を取得します。
列の名前を count 式の値として使用して、検索インデックス内の列を含む行の数をクエリできます。このメソッドは、スパース列を含むシナリオに適しています。
パラメーター
パラメーター
説明
aggregationName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果をクエリできます。
fieldName
集計操作を実行するために使用されるフィールドの名前。サポートされているタイプは、Long、Double、Boolean、Keyword、Geo_point、および Date のみです。
例
/** * 加盟店のペナルティ記録は加盟店テーブルに記録されます。浙江省に所在し、ペナルティ記録が存在する加盟店の数をクエリできます。加盟店のペナルティ記録が存在しない場合、ペナルティ記録に対応するフィールドも加盟店には存在しません。 * SQL 文: SELECT count(column_history) FROM product where place_of_production="Zhejiang". */ public void count(SyncClient client) { // ビルダーを使用してクエリステートメントを作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) // 特定のデータではなく集計結果のみを取得する場合、limit を 0 に設定してクエリのパフォーマンスを向上させることができます。 .addAggregation(AggregationBuilders.count("count_agg_1", "column_history")) .build()) .build(); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsCountAggregationResult("count_agg_1").getValue()); } // ビルダーを使用せずにクエリステートメントを作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); // 次のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成するメソッドは、TermQuery を使用してクエリステートメントを作成するメソッドと同じ効果があります。 // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); CountAggregation aggregation = new CountAggregation(); aggregation.setAggName("count_agg_1"); aggregation.setFieldName("column_history"); // 次のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成するメソッドは、aggregation を使用してクエリステートメントを作成するメソッドと同じ効果があります。 // CountAggregation aggregation2 = AggregationBuilders.count("count_agg_1", "column_history").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsCountAggregationResult("count_agg_1").getValue()); } }
個別カウント
フィールドの個別値の数を返すために使用できる集計メソッド。このメソッドは、SQL の COUNT(DISTINCT) オペレーターと同様の方法で使用できます。
個別値の数は概算です。
個別カウント機能を使用する前の行の総数が 10,000 未満の場合、計算結果は正確な値に近くなります。
個別カウント機能を使用する前の行の総数が 1 億以上の場合、エラー率は約 2% です。
パラメーター
パラメーター
説明
aggregationName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果を照会できます。
fieldName
集計操作を実行するために使用されるフィールドの名前。サポートされているタイプは、Long、Double、Boolean、Keyword、Geo_point、および Date のみです。
missing
集計操作が実行されるフィールドのデフォルト値。フィールド値が空の行に適用されます。
missing パラメーターの値を指定しない場合、行は無視されます。
missing パラメーターの値を指定した場合、このパラメーターの値が行のフィールド値として使用されます。
例
/** * 製品が生産された異なる都道府県の数を照会します。 * SQL 文: SELECT count(distinct column_place) FROM product. */ public void distinctCount(SyncClient client) { // ビルダーを使用してクエリステートメントを作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) // 特定のデータではなく集計結果のみを取得する場合、クエリのパフォーマンスを向上させるために limit を 0 に設定できます。 .addAggregation(AggregationBuilders.distinctCount("dis_count_agg_1", "column_place")) .build()) .build(); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("dis_count_agg_1").getValue()); } // ビルダーを使用せずにクエリステートメントを作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); // 次のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成するメソッドは、TermQuery を使用してクエリステートメントを作成するメソッドと同じ効果があります。 // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); DistinctCountAggregation aggregation = new DistinctCountAggregation(); aggregation.setAggName("dis_count_agg_1"); aggregation.setFieldName("column_place"); // 次のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成するメソッドは、aggregation を使用してクエリステートメントを作成するメソッドと同じ効果があります。 // DistinctCountAggregation aggregation2 = AggregationBuilders.distinctCount("dis_count_agg_1", "column_place").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // 集計結果を取得します。 System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("dis_count_agg_1").getValue()); } }
パーセンタイル統計
パーセンタイル値は、データセット内の値の相対的な位置を示します。たとえば、システムの日常的な運用保守中に各リクエストの応答時間の統計を収集する場合、p25、p50、p90、p99 などのパーセンタイルを使用して応答時間の分布を分析する必要があります。
結果の精度を向上させるために、p1 や p99 などの極端なパーセンタイル値を指定することをお勧めします。 p50 などの他の値の代わりに極端なパーセンタイル値を使用すると、返される結果がより正確になります。
パラメーター
パラメーター
説明
aggregationName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果を照会できます。
fieldName
集計操作を実行するために使用されるフィールドの名前。 Long、Double、および Date タイプのみがサポートされています。
percentiles
p50、p90、p99 などのパーセンタイル。 1 つ以上のパーセンタイルを指定できます。
missing
集計操作が実行されるフィールドのデフォルト値。フィールド値が空の行に適用されます。
missing パラメーターの値を指定しない場合、行は無視されます。
missing パラメーターの値を指定した場合、このパラメーターの値が行のフィールド値として使用されます。
例
/** * システムに送信される各リクエストの応答時間の分布をパーセンタイルを使用して分析します。 */ public void percentilesAgg(SyncClient client) { //ビルダーを使用してクエリステートメントを作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("indexName") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) //特定のデータではなく集計結果のみを取得する場合は、limit を 0 に設定してクエリのパフォーマンスを向上させることができます。 .addAggregation(AggregationBuilders.percentiles("percentilesAgg", "latency") .percentiles(Arrays.asList(25.0d, 50.0d, 99.0d)) .missing(1.0)) .build()) .build(); //クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); //結果を取得します。 PercentilesAggregationResult percentilesAggregationResult = resp.getAggregationResults().getAsPercentilesAggregationResult("percentilesAgg"); for (PercentilesAggregationItem item : percentilesAggregationResult.getPercentilesAggregationItems()) { System.out.println("key:" + item.getKey() + " value:" + item.getValue().asDouble()); } } //ビルダーを使用せずにクエリステートメントを作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); //以下のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成する方法は、TermQuery を使用してクエリステートメントを作成する方法と同じ効果があります。 // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); PercentilesAggregation aggregation = new PercentilesAggregation(); aggregation.setAggName("percentilesAgg"); aggregation.setFieldName("latency"); aggregation.setPercentiles(Arrays.asList(25.0d, 50.0d, 99.0d)); //以下のコメントでは、ビルダーを使用してクエリステートメントを作成しています。ビルダーを使用してクエリステートメントを作成する方法は、aggregation を使用してクエリステートメントを作成する方法と同じ効果があります。 // AggregationBuilders.percentiles("percentilesAgg", "latency").percentiles(Arrays.asList(25.0d, 50.0d, 99.0d)).missing(1.0).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); //結果を取得します。 PercentilesAggregationResult percentilesAggregationResult = resp.getAggregationResults().getAsPercentilesAggregationResult("percentilesAgg"); for (PercentilesAggregationItem item : percentilesAggregationResult.getPercentilesAggregationItems()) { System.out.println("key:" + item.getKey() + " value:" + item.getValue().asDouble()); } } }
フィールド値でグループ化
フィールド値に基づいてクエリ結果をグループ化するために使用できる集計メソッド。同じ値はグループ化されます。各グループの値と各グループのメンバー数が返されます。
フィールド値によるグループ化は並列計算を使用しており、正確な計算ではありません。わずかな誤差が生じる可能性があります。
クエリ結果を複数のフィールドでグループ化する場合は、ネストグループ化または複数フィールドグループ化を使用できます。 これらの 2 つのメソッドの違いについては、「付録: 複数フィールドグループ化のさまざまなメソッド」をご参照ください。
パラメータ
パラメータ
説明
groupByName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果を照会できます。
fieldName
集計操作を実行するために使用されるフィールドの名前。 Long、Double、Boolean、Keyword、および Date タイプのみがサポートされています。
groupBySorter
グループのソート規則。 デフォルトでは、グループはグループ内の項目数に基づいて降順にソートされます。 複数のソート規則を設定すると、グループは規則が設定された順序でソートされます。 次のソート規則がサポートされています。
groupKeySortInAsc: 値でアルファベット順にソートします。
groupKeySortInDesc: 値でアルファベットの逆順にソートします。
rowCountSortInAsc: 行数で昇順にソートします。
rowCountSortInDesc (デフォルト): 行数で降順にソートします。
subAggSortInAsc: サブ集計結果から取得された値で昇順にソートします。
subAggSortInDesc: サブ集計結果から取得された値で降順にソートします。
size
返されるグループの数。 デフォルト値: 10。 最大値: 2000。
subAggregations
各グループのデータに対して実行できるサブ集計操作 (最大値、合計、または平均値の計算など)。
subGroupBys
各親グループのデータをさらにグループ化するために、各親グループのデータに対して実行できるサブグループ化操作。
例
単一フィールドによるグループ化
/** * 各カテゴリの製品数、製品の最高価格、最低価格を照会します。 * 返される結果の例: 果物: 5。 最高価格は 15 人民元、最低価格は 3 人民元です。 洗面用品: 10。 最高価格は 98 人民元、最低価格は 1 人民元です。 電子機器: 3。 最高価格は 8,699 人民元、最低価格は 2,300 人民元です。 その他の製品: 15。 最高価格は 1,000 人民元、最低価格は 80 人民元です。 */ public void groupByField(SyncClient client) { //ビルダーを使用してクエリステートメントを作成します。 { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) //特定のデータではなく集計結果のみを取得する場合は、limit を 0 に設定してクエリのパフォーマンスを向上させることができます。 .addGroupBy(GroupByBuilders .groupByField("name1", "column_type") .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) .addSubAggregation(AggregationBuilders.max("subName2", "column_price")) ) .build()) .build(); //クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); //集計結果を取得します。 for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name1").getGroupByFieldResultItems()) { //値を表示します。 System.out.println(item.getKey()); //行数を表示します。 System.out.println(item.getRowCount()); //最低価格を表示します。 System.out.println(item.getSubAggregationResults().getAsMinAggregationResult("subName1").getValue()); //最高価格を表示します。 System.out.println(item.getSubAggregationResults().getAsMaxAggregationResult("subName2").getValue()); } } //ビルダーを使用せずにクエリステートメントを作成します。 { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); //以下のコメントでは、ビルダーを使用してクエリステートメントを作成しています。 ビルダーを使用してクエリステートメントを作成するメソッドは、TermQuery を使用してクエリステートメントを作成するメソッドと同じ効果があります。 // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); GroupByField groupByField = new GroupByField(); groupByField.setGroupByName("name1"); groupByField.setFieldName("column_type"); //サブ集計操作を設定します。 MinAggregation minAggregation = AggregationBuilders.min("subName1", "column_price").build(); MaxAggregation maxAggregation = AggregationBuilders.max("subName2", "column_price").build(); groupByField.setSubAggregations(Arrays.asList(minAggregation, maxAggregation)); //以下のコメントでは、ビルダーを使用してクエリステートメントを作成しています。 ビルダーを使用してクエリステートメントを作成するメソッドは、集計を使用してクエリステートメントを作成するメソッドと同じ効果があります。 // GroupByBuilders.groupByField("name1", "column_type") // .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) // .addSubAggregation(AggregationBuilders.max("subName2", "column_price").build()); List<GroupBy> groupByList = new ArrayList<GroupBy>(); groupByList.add(groupByField); searchQuery.setGroupByList(groupByList); searchRequest.setSearchQuery(searchQuery); //クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); //集計結果を取得します。 for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name1").getGroupByFieldResultItems()) { //値を表示します。 System.out.println(item.getKey()); //行数を表示します。 System.out.println(item.getRowCount()); //最低価格を表示します。 System.out.println(item.getSubAggregationResults().getAsMinAggregationResult("subName1").getValue()); //最高価格を表示します。 System.out.println(item.getSubAggregationResults().getAsMaxAggregationResult("subName2").getValue()); } } }ネストモードで複数のフィールドをグループ化
/** * ネストモードで複数のフィールドによってクエリ結果をグループ化する例。 * 検索インデックスでは、ネストモードで 2 つの groupBy フィールドを使用して、SQL ステートメントで複数の groupBy フィールドを使用するのと同じ効果を得ることができます。 * SQL ステートメント: select a,d, sum(b),sum(c) from user group by a,d. */ public void GroupByMultiField(SyncClient client) { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .returnAllColumns(true) //returnAllColumns を false に設定し、addColumesToGet に値を指定すると、クエリのパフォーマンスが向上します。 //.addColumnsToGet("col_1","col_2") .searchQuery(SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) //クエリ条件を指定します。 クエリ条件は、SQL の WHERE 句と同じように使用できます。 QueryBuilders.bool() を使用してネストクエリを実行できます。 .addGroupBy( GroupByBuilders .groupByField("unique name_1", "field_a") .size(20) .addSubGroupBy( GroupByBuilders .groupByField("unique name_2", "field_d") .size(20) .addSubAggregation(AggregationBuilders.sum("unique name_3", "field_b")) .addSubAggregation(AggregationBuilders.sum("unique name_4", "field_c")) ) ) .build()) .build(); SearchResponse response = client.search(searchRequest); //指定された条件を満たす行を照会します。 List<Row> rows = response.getRows(); //集計結果を取得します。 GroupByFieldResult groupByFieldResult1 = response.getGroupByResults().getAsGroupByFieldResult("unique name_1"); for (GroupByFieldResultItem resultItem : groupByFieldResult1.getGroupByFieldResultItems()) { System.out.println("field_a key:" + resultItem.getKey() + " Count:" + resultItem.getRowCount()); //サブ集計結果を取得します。 GroupByFieldResult subGroupByResult = resultItem.getSubGroupByResults().getAsGroupByFieldResult("unique name_2"); for (GroupByFieldResultItem item : subGroupByResult.getGroupByFieldResultItems()) { System.out.println("field_a " + resultItem.getKey() + " field_d key:" + item.getKey() + " Count: " + item.getRowCount()); double sumOf_field_b = item.getSubAggregationResults().getAsSumAggregationResult("unique name_3").getValue(); double sumOf_field_c = item.getSubAggregationResults().getAsSumAggregationResult("unique name_4").getValue(); System.out.println("sumOf_field_b:" + sumOf_field_b); System.out.println("sumOf_field_c:" + sumOf_field_c); } } }集計のグループをソート
/** * 集計のソート規則を設定する例。 * 方法: GroupBySorter を指定してソート規則を設定します。 複数のソート規則を設定すると、グループは規則が設定された順序でソートされます。 GroupBySorter は、昇順または降順でのソートをサポートしています。 * デフォルトでは、グループは行数で降順にソートされます (GroupBySorter.rowCountSortInDesc())。 */ public void groupByFieldWithSort(SyncClient client) { //クエリステートメントを作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByField("name1", "column_type") //.addGroupBySorter(GroupBySorter.subAggSortInAsc("subName1")) //サブ集計結果から取得された値に基づいてグループを昇順にソートします。 .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) //集計結果から取得された値に基づいてグループを昇順にソートします。 //.addGroupBySorter(GroupBySorter.rowCountSortInDesc()) //各グループの集計結果から取得された行数に基づいてグループを降順にソートします。 .size(20) .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) .addSubAggregation(AggregationBuilders.max("subName2", "column_price")) ) .build()) .build(); //クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); }
ネストされたグループ化
GroupBy はネスト操作をサポートしており、親レベルのグループ化結果に基づいてサブレベルの集計を追加できます。
複雑な GroupBy 操作の高パフォーマンスを確保するために、ネストのレベル数を少なく指定できます。詳細については、「検索インデックスの制限」をご参照ください。
一般的なシナリオ
複数レベルのグループ化(GroupBy + SubGroupBy)
最初のレベルでデータをグループ化した後、2 番目のレベルのグループ化を実行できます。たとえば、最初に県でデータをグループ化し、次に市でグループ化して、各県の各市のデータを取得できます。
グループ化後の集計(GroupBy + SubAggregation)
最初のレベルでデータをグループ化した後、各グループのデータに対して集計操作(最大値や平均値の計算など)を実行できます。たとえば、県別にデータをグループ化した後、各県のグループの特定の指標の最大値を取得できます。
例
次の例は、県と市でネストされたグループ化を実行し、各県の注文の総数と、各市の注文の総数と注文の最大金額を計算する方法を示しています。
public static void subGroupBy(SyncClient client) { //クエリ文を作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .returnAllColumns(true) .searchQuery(SearchQuery.newBuilder() .query(QueryBuilders.matchAll()).limit(20) //第 1 レベルのグループ化: 県別にグループ化し、各県の注文 ID の数(注文の総数)をカウントします。 //第 2 レベルのグループ化: 市別にグループ化し、各市の注文 ID の数(注文の総数)をカウントし、各市の注文の最大金額を計算します。 .addGroupBy(GroupByBuilders.groupByField("provinceName", "province") .addSubAggregation(AggregationBuilders.count("provinceOrderCounts", "order_id")) .addGroupBySorter(GroupBySorter.rowCountSortInDesc()) .addSubGroupBy(GroupByBuilders.groupByField("cityName", "city") .addSubAggregation(AggregationBuilders.count("cityOrderCounts", "order_id")) .addSubAggregation(AggregationBuilders.max("cityMaxAmount", "order_amount")) .addGroupBySorter(GroupBySorter.subAggSortInDesc("cityMaxAmount")))) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //第 1 レベルのグループ化結果(各県の注文の総数)を取得します。 GroupByFieldResult results = resp.getGroupByResults().getAsGroupByFieldResult("provinceName"); for (GroupByFieldResultItem item : results.getGroupByFieldResultItems()) { System.out.println("Province:" + item.getKey() + "\tTotal Orders:" + item.getSubAggregationResults().getAsCountAggregationResult("provinceOrderCounts").getValue()); //第 2 レベルのグループ化結果(各市の注文の総数と注文の最大金額)を取得します。 GroupByFieldResult subResults = item.getSubGroupByResults().getAsGroupByFieldResult("cityName"); for (GroupByFieldResultItem subItem : subResults.getGroupByFieldResultItems()) { System.out.println("\t(City)" + subItem.getKey() + "\tTotal Orders:" + subItem.getSubAggregationResults().getAsCountAggregationResult("cityOrderCounts").getValue() + "\tMaximum Order Amount:" + subItem.getSubAggregationResults().getAsMaxAggregationResult("cityMaxAmount").getValue()); } } }
複数のフィールドでグループ化する
複数のフィールドに基づいてクエリ結果をグループ化するために使用できる集約方法です。トークンを使用してページングを実行できます。
パラメーター
パラメーター
説明
groupByName
集約操作の一意の名前です。この名前を使用して、特定の集約操作の結果を照会できます。
sources
クエリ結果をグループ化するフィールドです。最大 32 のフィールドでクエリ結果をグループ化し、結果のグループに対して集約操作を実行できます。次のグループタイプがサポートされています。
GroupByField: フィールド値でグループ化します。 groupByName、fieldName、および groupBySorter パラメーターを設定できます。
GroupByHistogram: ヒストグラムでクエリします。 groupByName、fieldName、interval、および groupBySorter パラメーターを設定できます。
GroupByDateHistogram: 日付ヒストグラムでクエリします。 groupByName、fieldName、interval、timeZone、および groupBySorter パラメーターを設定できます。
重要sources のグループ項目では、辞書順でのグループ値 (groupKeySort) によるソートのみがサポートされています。デフォルトでは、グループは降順でソートされます。
特定の列にフィールド値が存在しない場合、返される結果の値は NULL になります。
nextToken
次のページのデータを取得するために使用されるページネーショントークンです。デフォルトでは、このパラメーターは空です。
最初のリクエストでは、nextToken を空に設定します。クエリ条件を満たすすべてのデータが 1 回のリクエストで返されない場合、レスポンスの nextToken パラメーターは空ではありません。この nextToken をページングクエリに使用できます。
説明nextToken を永続化したり、フロントエンドページに送信したりする必要がある場合は、保存または送信する前に、Base64 エンコーディングを使用して nextToken を文字列としてエンコードすることをお勧めします。 nextToken 自体は文字列ではありません。エンコードに new String(nextToken) を直接使用すると、トークン情報が失われます。
size
1 ページあたりのグループ数です。デフォルト値: 10。最大値: 2000。
重要返すグループの数を制限する場合は、ほとんどの場合、size パラメーターを設定することをお勧めします。
size パラメーターと suggestedSize パラメーターを同時に設定することはできません。
suggestedSize
返すグループの数です。サーバー側で許可されている最大グループ数より大きい値、または -1 を指定できます。サーバー側は、その容量に基づいてグループの数を返します。
このパラメーターをサーバー側で許可されている最大グループ数より大きい値に設定すると、システムは値をサーバー側で許可されている最大グループ数に調整します。実際に返されるグループの数は、min(suggestedSize、サーバー側で許可されている最大グループ数、グループの総数) となります。
重要このパラメーターは、Tablestore を Apache Spark や PrestoSQL などの高スループットコンピューティングエンジンと相互接続するシナリオに適しています。
subAggregations
各グループのデータに対して実行できるサブ集約操作 (最大値、合計、または平均値の計算など) です。
subGroupBys
各親グループのデータをさらにグループ化するために、親グループのデータに対して実行できるサブグループ化操作です。
重要GroupByComposite パラメーターは subGroupBy ではサポートされていません。
例
/** * グループ化と集計のクエリ結果: SourceGroupBy パラメーターに渡された groupbyField、groupByHistogram、groupByDataHistogram などのパラメーターに基づいて、クエリ結果をグループ化し、結果のグループに対して集約操作を実行します。 * 複数のフィールドの集計結果をフラットな構造で返します。 */ public static void groupByComposite(SyncClient client) { GroupByComposite.Builder compositeBuilder = GroupByBuilders .groupByComposite("groupByComposite") .size(2000) .addSources(GroupByBuilders.groupByField("groupByField", "Col_Keyword") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()).build()) .addSources(GroupByBuilders.groupByHistogram("groupByHistogram", "Col_Long") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) .interval(5) .build()) .addSources(GroupByBuilders.groupByDateHistogram("groupByDateHistogram", "Col_Date") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) .interval(5, DateTimeUnit.DAY) .timeZone("+05:30").build()); SearchRequest searchRequest = SearchRequest.newBuilder() .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .returnAllColumnsFromIndex(true) .searchQuery(SearchQuery.newBuilder() .addGroupBy(compositeBuilder.build()) .build()) .build(); SearchResponse resp = client.search(searchRequest); while (true) { if (resp.getGroupByResults() == null || resp.getGroupByResults().getResultAsMap().size() == 0) { System.out.println("groupByComposite Result is null or empty"); return; } GroupByCompositeResult result = resp.getGroupByResults().getAsGroupByCompositeResult("groupByComposite"); if(!result.getSourceNames().isEmpty()) { for (String sourceGroupByNames: result.getSourceNames()) { System.out.printf("%s\t", sourceGroupByNames); } System.out.print("rowCount\t\n"); } for (GroupByCompositeResultItem item : result.getGroupByCompositeResultItems()) { for (String value : item.getKeys()) { String val = value == null ? "NULL" : value; System.out.printf("%s\t", val); } System.out.printf("%d\t\n", item.getRowCount()); } // トークンを使用してグループをページングします。 if (result.getNextToken() != null) { searchRequest.setSearchQuery( SearchQuery.newBuilder() .addGroupBy(compositeBuilder.nextToken(result.getNextToken()).build()) .build() ); resp = client.search(searchRequest); } else { break; } } }
範囲でグループ化
フィールドの値の範囲に基づいてクエリ結果をグループ化するために使用できる集計方法。特定の範囲内のフィールド値はグループ化されます。各範囲の値の数が返されます。
パラメータ
パラメータ
説明
groupByName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果をクエリできます。
fieldName
集計操作を実行するために使用されるフィールドの名前。Long 型と Double 型のみがサポートされています。
range[double_from, double_to)
グループ化の値の範囲。
double_from を Double.MIN_VALUE に設定して最小値を指定し、double_to を Double.MAX_VALUE に設定して最大値を指定できます。
subAggregation and subGroupBy
サブ集計操作。グループ化結果に基づいてサブ集計操作を実行できます。
たとえば、売上高と州別にクエリ結果をグループ化した後、指定した範囲内で売上高の割合が最も大きい州を取得できます。このクエリを実行するには、GroupByRange で GroupByField を指定する必要があります。
例
/** * 範囲 [0, 1000)、[1000, 5000)、および [5000, Double.MAX_VALUE) に基づいて売上高をグループ化し、各範囲の売上高を取得します。 */ public void groupByRange(SyncClient client) { //クエリ文を作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByRange("name1", "column_number") .addRange(0, 1000) .addRange(1000, 5000) .addRange(5000, Double.MAX_VALUE) ) .build()) .build(); //クエリ文を実行します。 SearchResponse resp = client.search(searchRequest); //集計結果を取得します。 for (GroupByRangeResultItem item : resp.getGroupByResults().getAsGroupByRangeResult("name1").getGroupByRangeResultItems()) { //行数を表示します。 System.out.println(item.getRowCount()); } }
地理的な場所別にグループ化する
地理的な位置から中心点までの距離に基づいてクエリ結果をグループ化するために使用できる集計方法です。特定の範囲内の距離にあるクエリ結果はグループ化されます。各範囲の値の数が返されます。
パラメータ
パラメータ
説明
groupByName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果を照会できます。
fieldName
集計操作を実行するために使用されるフィールドの名前。 Geo_point タイプのみがサポートされています。
origin(double lat, double lon)
中心点の経度と緯度。
double lat は中心点の緯度を指定します。 double lon は中心点の経度を指定します。
range[double_from, double_to)
グループ化に使用される距離範囲。単位:メートル。
double_from を Double.MIN_VALUE に設定して最小値を指定し、double_to を Double.MAX_VALUE に設定して最大値を指定できます。
subAggregation and subGroupBy
サブ集計操作。グループ化結果に基づいてサブ集計操作を実行できます。
例
/** * 地理的な場所に基づいてユーザーを Wanda Plaza にグループ化し、各距離範囲内のユーザー数を取得します。距離範囲は [0, 1000)、[1000, 5000)、および [5000, Double.MAX_VALUE) です。単位:メートル。 */ public void groupByGeoDistance(SyncClient client) { //クエリステートメントを作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByGeoDistance("name1", "column_geo_point") .origin(3.1, 6.5) .addRange(0, 1000) .addRange(1000, 5000) .addRange(5000, Double.MAX_VALUE) ) .build()) .build(); //クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); //集計結果を取得します。 for (GroupByGeoDistanceResultItem item : resp.getGroupByResults().getAsGroupByGeoDistanceResult("name1").getGroupByGeoDistanceResultItems()) { //行数を表示します。 System.out.println(item.getRowCount()); } }
フィルターによるグループ化
クエリ結果をフィルタリングし、各フィルターに基づいてグループ化して、一致する結果の数を得ることができる集計方法。結果は、フィルターが指定された順序で返されます。
パラメータ
パラメータ
説明
groupByName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果をクエリできます。
filter
クエリに使用できるフィルター。結果は、フィルターが指定された順序で返されます。
subAggregation and subGroupBy
サブ集計操作。グループ化結果に基づいてサブ集計操作を実行できます。
例
/** * 次のフィルターを指定して、各フィルターに一致する項目の数を取得します。売上高が 100 を超えている、原産地が浙江省である、説明に杭州が含まれている。 */ public void groupByFilter(SyncClient client) { // クエリステートメントを作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByFilter("name1") .addFilter(QueryBuilders.range("number").greaterThanOrEqual(100)) .addFilter(QueryBuilders.term("place","Zhejiang")) .addFilter(QueryBuilders.match("text","Hangzhou")) ) .build()) .build(); // クエリステートメントを実行します。 SearchResponse resp = client.search(searchRequest); // フィルターの順序に基づいて集計結果を取得します。 for (GroupByFilterResultItem item : resp.getGroupByResults().getAsGroupByFilterResult("name1").getGroupByFilterResultItems()) { // 行数を表示します。 System.out.println(item.getRowCount()); } }
ヒストグラム統計
集計メソッドを使用すると、特定のデータ間隔に基づいてクエリ結果をグループ化できます。同じ範囲内のフィールド値はグループ化されます。各グループの値の範囲と各グループの値の数が返されます。
パラメーター
パラメーター
説明
groupByName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果を照会できます。
fieldName
集計操作の実行に使用されるフィールドの名前。Long 型と Double 型のみがサポートされています。
interval
集計結果を取得するために使用されるデータ間隔。
fieldRange[min,max]
interval パラメーターと共に使用され、グループ数を制限する範囲。
(fieldRange.max-fieldRange.min)/interval数式を使用して決定されるグループ数は 2,000 を超えることはできません。minDocCount
行の最小数。グループ内の行数が最小行数より少ない場合、グループの集計結果は返されません。
missing
集計操作が実行されるフィールドのデフォルト値。フィールド値が空の行に適用されます。
missing パラメーターの値を指定しない場合、行は無視されます。
missing パラメーターの値を指定した場合、このパラメーターの値が行のフィールド値として使用されます。
例
/** * 年齢層ごとのユーザー分布の統計情報を収集します。 */ public static void groupByHistogram(SyncClient client) { //クエリステートメントを作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .addGroupBy(GroupByBuilders .groupByHistogram("groupByHistogram", "age") .interval(10) .minDocCount(0L) .addFieldRange(0, 99)) .build()) .build(); //クエリステートメントを実行します。 SearchResponse resp = ots.search(searchRequest); //集計操作の実行時に返される結果を取得します。 GroupByHistogramResult results = resp.getGroupByResults().getAsGroupByHistogramResult("groupByHistogram"); for (GroupByHistogramItem item : results.getGroupByHistogramItems()) { System.out.println("key:" + item.getKey().asLong() + " value:" + item.getValue()); } }
日付ヒストグラムによるクエリ
特定の日付間隔に基づいてクエリ結果をグループ化するために使用できる集計方法です。 同じ範囲内のフィールド値はグループ化されます。 各グループの値の範囲と各グループの値の数が返されます。
この機能は、Tablestore SDK for Java V5.16.1 以降でサポートされています。 Tablestore SDK for Java のバージョン履歴については、「Tablestore SDK for Java のバージョン履歴」をご参照ください。
パラメーター
パラメーター
説明
groupByName
集計操作の一意の名前。 この名前を使用して、特定の集計操作の結果をクエリできます。
fieldName
集計操作を実行するために使用されるフィールドの名前。 Date 型のみがサポートされています。
重要検索インデックスの Date 型は、Tablestore SDK for Java V5.13.9 以降でサポートされています。
interval
統計間隔。
fieldRange[min,max]
interval パラメーターと共に使用して、グループの数を制限する範囲。
(fieldRange.max-fieldRange.min)/interval数式を使用して決定されるグループの数は 2,000 を超えることはできません。minDocCount
行の最小数。 グループ内の行数が最小行数より少ない場合、グループの集計結果は返されません。
missing
集計操作が実行されるフィールドのデフォルト値。 フィールド値が空の行に適用されます。
missing パラメーターの値を指定しない場合、行は無視されます。
missing パラメーターの値を指定した場合、このパラメーターの値が行のフィールド値として使用されます。
timeZone
+hh:mmまたは-hh:mm形式(+08:00または-09:00など)のタイムゾーン。 このパラメーターは、フィールドが Date 型の場合にのみ必要です。Date 型のフィールドにこのパラメーターが指定されていない場合、集計結果に N 時間のオフセットが発生する可能性があります。 この問題を防ぐために、timeZone パラメーターを指定できます。
例
/** * 2017年5月1日 10:00:00 から 2017年5月21日 13:00:00 までの col_date フィールドのデータの日次分布に関する統計情報を収集します。 */ public static void groupByDateHistogram(SyncClient client) { //クエリステートメントを作成します。 SearchRequest searchRequest = SearchRequest.newBuilder() .returnAllColumns(false) .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .getTotalCount(false) .addGroupBy(GroupByBuilders .groupByDateHistogram("groupByDateHistogram", "col_date") .interval(1, DateTimeUnit.DAY) .minDocCount(1) .missing("2017-05-01 13:01:00") .fieldRange("2017-05-01 10:00", "2017-05-21 13:00:00")) .build()) .build(); //クエリステートメントを実行します。 SearchResponse resp = ots.search(searchRequest); //集計操作が実行されたときに返される結果を取得します。 List<GroupByDateHistogramItem> items = resp.getGroupByResults().getAsGroupByDateHistogramResult("groupByDateHistogram").getGroupByDateHistogramItems(); for (GroupByDateHistogramItem item : items) { System.out.printf("millisecondTimestamp:%d, count:%d \n", item.getTimestamp(), item.getRowCount()); } }
各グループの集計操作の結果から取得された行をクエリする
クエリ結果をグループ化した後、各グループの行をクエリできます。このメソッドは、MySQL の ANY_VALUE(field) と同様の方法で使用できます。
各グループの集計操作の結果から取得した行をクエリする場合、検索インデックスに NESTED、GEOPOINT、または ARRAY フィールドが含まれていると、返される結果にはプライマリキー情報のみが含まれます。必要なフィールドを取得するには、データテーブルをクエリする必要があります。
パラメーター
パラメーター
説明
aggregationName
集計操作の一意の名前。この名前を使用して、特定の集計操作の結果を照会できます。
limit
各グループに返される最大行数。デフォルトでは、1 行のデータのみが返されます。
sort
グループ内のデータをソートするために使用されるソート方法。
columnsToGet
返されるフィールド。 検索インデックス内のフィールドのみがサポートされています。 配列、日付、地理座標、およびネストされたフィールドはサポートされていません。
このパラメーターの値は、SearchRequest の columnsToGet パラメーターの値と同じです。 SearchRequest の columnsToGet パラメーターの値のみを指定する必要があります。
例
/** * 学校の活動申請フォームには、生徒、クラス、担任、学級委員長などの情報を指定できるフィールドが含まれています。クラスごとに生徒をグループ化して、申請統計と各クラスのプロパティ情報を表示できます。 * SQL 文: select className, teacher, monitor, COUNT(*) as number from table GROUP BY className. */ public void testTopRows(SyncClient client) { SearchRequest searchRequest = SearchRequest.newBuilder() .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders.groupByField("groupName", "className") .size(5) // 返すグループの数を指定します。返されるグループ数の最大値については、「検索インデックスの制限」 Topic の GroupByField で返されるグループ数の説明を参照してください。 .addSubAggregation(AggregationBuilders.topRows("topRowsName") .limit(1) .sort(new Sort(Arrays.asList(new FieldSort("teacher", SortOrder.DESC)))) // teacher で降順にソートします。 ) ) .build()) .addColumnsToGet(Arrays.asList("teacher", "monitor")) .build(); SearchResponse resp = client.search(searchRequest); List<GroupByFieldResultItem> items = resp.getGroupByResults().getAsGroupByFieldResult("groupName").getGroupByFieldResultItems(); for (GroupByFieldResultItem item : items) { String className = item.getKey(); long number = item.getRowCount(); List<Row> topRows = item.getSubAggregationResults().getAsTopRowsAggregationResult("topRowsName").getRows(); Row row = topRows.get(0); String teacher = row.getLatestColumn("teacher").getValue().asString(); String monitor = row.getLatestColumn("monitor").getValue().asString(); } }
複数の集計
複数の集計操作を実行できます。
複数の複雑な集計操作を同時に実行すると、長時間を要する場合があります。
複数の集計の組み合わせ
public void multipleAggregation(SyncClient client) {
// クエリ文を作成します。
SearchRequest searchRequest = SearchRequest.newBuilder()
.tableName("<TABLE_NAME>")
.indexName("<SEARCH_INDEX_NAME>")
.searchQuery(
SearchQuery.newBuilder()
.query(QueryBuilders.matchAll())
.limit(0)
.addAggregation(AggregationBuilders.min("name1", "long"))
.addAggregation(AggregationBuilders.sum("name2", "long"))
.addAggregation(AggregationBuilders.distinctCount("name3", "long"))
.build())
.build();
// クエリ文を実行します。
SearchResponse resp = client.search(searchRequest);
// 集計操作の結果から最小値を取得します。
System.out.println(resp.getAggregationResults().getAsMinAggregationResult("name1").getValue());
// 集計操作の結果から合計値を取得します。
System.out.println(resp.getAggregationResults().getAsSumAggregationResult("name2").getValue());
// 集計操作の結果から個別値の数を取得します。
System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("name3").getValue());
}集計と GroupBy の組み合わせ
public void multipleGroupBy(SyncClient client) {
// クエリ文を作成します。
SearchRequest searchRequest = SearchRequest.newBuilder()
.tableName("<TABLE_NAME>")
.indexName("<SEARCH_INDEX_NAME>")
.searchQuery(
SearchQuery.newBuilder()
.query(QueryBuilders.matchAll())
.limit(0)
.addAggregation(AggregationBuilders.min("name1", "long"))
.addAggregation(AggregationBuilders.sum("name2", "long"))
.addAggregation(AggregationBuilders.distinctCount("name3", "long"))
.addGroupBy(GroupByBuilders.groupByField("name4", "type"))
.addGroupBy(GroupByBuilders.groupByRange("name5", "long").addRange(1, 15))
.build())
.build();
// クエリ文を実行します。
SearchResponse resp = client.search(searchRequest);
// 集計操作の結果から最小値を取得します。
System.out.println(resp.getAggregationResults().getAsMinAggregationResult("name1").getValue());
// 集計操作の結果から合計値を取得します。
System.out.println(resp.getAggregationResults().getAsSumAggregationResult("name2").getValue());
// 集計操作の結果から個別値の数を取得します。
System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("name3").getValue());
// 集計操作の結果から GroupByField の値を取得します。
for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name4").getGroupByFieldResultItems()) {
// キーを表示します。
System.out.println(item.getKey());
// 行数を表示します。
System.out.println(item.getRowCount());
}
// 集計操作の結果から GroupByRange の値を取得します。
for (GroupByRangeResultItem item : resp.getGroupByResults().getAsGroupByRangeResult("name5").getGroupByRangeResultItems()) {
// 行数を表示します。
System.out.println(item.getRowCount());
}
}付録: 複数フィールドのグループ化のさまざまな方法
複数のフィールドでクエリ結果をグループ化する場合は、ネストモードで groupBy パラメーターを使用するか、GroupByComposite パラメーターを使用できます。次の表は、ネストモードの groupBy パラメーターと GroupByComposite パラメーターの違いについて説明しています。
機能 | groupBy (ネスト) | 複数フィールドのグループ化 |
サイズ | 2000 | 2000 |
フィールドの制限 | 最大 3 レベルまでサポートされています。 | 最大 32 レベルまでサポートされています。 |
ページネーション | サポートされていません | nextToken パラメーターを使用してサポートされています |
グループ内の行のソート規則 |
| アルファベット順またはアルファベットの逆順 |
集計のサポート | はい | はい |
互換性 | Date 型のフィールドの場合、クエリ結果は指定された形式で返されます。 | DATE 型のフィールドの場合、クエリ結果はタイムスタンプ文字列として返されます。 |
参照資料
データテーブルのデータのクエリと分析については、次のトピックも参照できます。
Tablestore の SQL クエリ機能を使用します。詳細については、「SQL クエリ」をご参照ください。
DataWorks などのビッグデータプラットフォームに Tablestore を接続して、SQL クエリを実行し、データを分析します。詳細については、「ビッグデータプラットフォームへの Tablestore の接続」をご参照ください。
MaxCompute、Spark、Hive、HadoopMR、Function Compute、Flink、PrestoDB などのコンピューティングエンジンに Tablestore を接続して、SQL クエリを実行し、データを分析します。詳細については、「概要」をご参照ください。