診断レポートは、パフォーマンスメトリクス、リクエスト分散、スロークエリデータを分析することで、ApsaraDB for Redis インスタンスの健全性を評価します。このレポートを利用することで、ビジネスに影響が及ぶ前に異常を特定し、対処することができます。
前提条件
開始する前に、以下を確認してください。
-
インスタンスで診断を実行済みであること。手順については、「インスタンスで診断を実行」をご参照ください。
レポートのセクション
診断レポートには 4 つのセクションがあります。
-
インスタンスの基本情報:インスタンス ID、インスタンスタイプ、エンジンバージョン、およびインスタンスがデプロイされているゾーン
-
概要:インスタンスのヘルススコアと減点の内訳
-
パフォーマンスレベル:主要なパフォーマンスメトリクスの現在の状態
-
スロークエリが最も多い上位 10 ノード:スロークエリ数に基づく上位 10 のデータノードと、それらのクエリに関する詳細
インスタンスの基本情報
このセクションには、インスタンス ID、インスタンスタイプ、エンジンバージョン、およびインスタンスがデプロイされているゾーンが表示されます。
診断期間は 2021 年 3 月 1 日 11:10:23 から 2021 年 3 月 1 日 14:10:23 までです。インスタンスの基本情報には、次のフィールドが含まれます。
-
インスタンス ID:インスタンス ID とインスタンス名 (例:サフィックス「-Diagnostic Report Test」)
-
仕様:2 GB Cluster Edition (2 ノード)
-
エンジンバージョン:Redis 5.0
-
ゾーン:China (Hangzhou)
概要
このセクションでは、インスタンスの全体的なヘルススコアが表示されます。最大スコアは 100 です。スコアが 100 未満の場合、減点の原因となった診断項目とその理由が一覧表示されます。
ヘルススコアは 100 点満点中 70 点です。次の項目が減点の原因となりました。
-
高い CPU 使用率:CPU 使用率が 85.9% に達し、安全しきい値を超えました。10 ポイント減点。
-
高いメモリ使用率:メモリ使用率が 100.0% に達し、安全しきい値を超えました。10 ポイント減点。
-
スローログアクセス:サーバーに記録された上位のスローログエントリが 12 件ありました。10 ポイント減点。
パフォーマンスレベル
このセクションには、主要なパフォーマンスメトリクスの現在の状態が表示されます。危険 状態にあるメトリクスには特に注意してください。しきい値を超える値が持続すると、スループットが低下し、レイテンシーが増加する可能性があります。
クラスターアーキテクチャまたは読み書き分離アーキテクチャで実行されているインスタンスの場合、メトリクスがデータノード間で不均等に分散されているかどうかを確認してください。各メトリクスの[上位 5 ノード] の曲線グラフを確認し、どのノードが最も高い負荷にさらされているかを特定してください。アーキテクチャの詳細については、「クラスターマスター/レプリカインスタンス」および「読み書き分離インスタンス」をご参照ください。
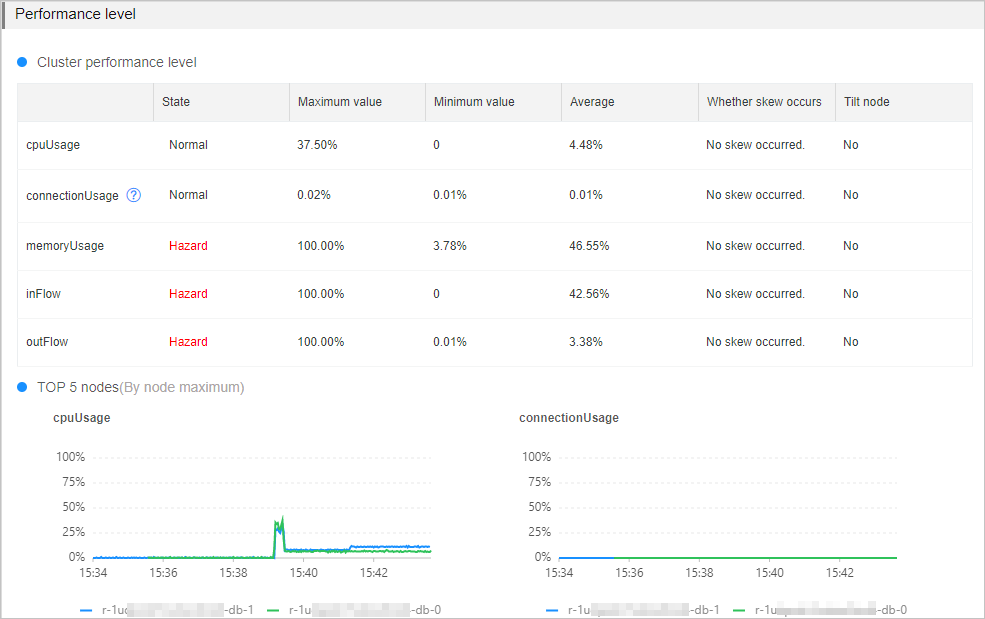
次の表では、各パフォーマンスメトリクス、そのしきい値、しきい値を超えた場合のビジネスへの影響、およびトラブルシューティング方法について説明します。
| メトリクス | しきい値 | 適用対象 | 影響 | 考えられる原因と次のステップ |
|---|---|---|---|---|
| CPU 使用率 | 60% | すべてのアーキテクチャ | 高い CPU 使用率は、スループットを低下させ、応答時間が増加します。クライアントが応答しなくなる可能性があります。 | 原因:複雑度の高いコマンド、ホットキー、または頻繁な接続作成。詳細については、「インスタンスの CPU 使用率が高い場合のトラブルシューティング」をご参照ください。 |
| [メモリ使用率] | 80% | すべてのアーキテクチャ | 高いメモリ使用率が持続すると、応答時間が増加し、1 秒あたりのクエリ数 (QPS) が不安定になり、頻繁なキーの削除がトリガーされます。 | 原因:メモリの枯渇または多数の大きなキー。詳細については、「インスタンスのメモリ使用率が高い場合のトラブルシューティング」をご参照ください。 |
| [データノードの接続数使用率] | 80% | 直接接続モードのクラスターインスタンスのみ。クライアントがプロキシノード経由で接続する場合、代わりにプロキシノードレベルで接続をモニタリングします。詳細については、「直接接続モードの有効化」および「パフォーマンスモニタリングデータの表示」をご参照ください。 | 接続数が上限に達すると、新しい接続リクエストはタイムアウトするか、失敗します。 | 原因:トラフィックの急増や、解放されていないアイドル接続。詳細については、「インスタンスセッション」をご参照ください。 |
| インバウンドトラフィック | 80% | すべてのアーキテクチャ | トラフィックがインスタンスタイプの帯域幅を超えると、クライアントのパフォーマンスが低下します。 | 原因:ワークロードの急増や、大きなキーの頻繁な読み書き。詳細については、「インスタンスのトラフィック使用量が高い場合のトラブルシューティング」をご参照ください。 |
| [アウトバウンドトラフィック] | 80% | すべてのアーキテクチャ |
リクエストの偏り
クラスターアーキテクチャまたは読み書き分離アーキテクチャで実行されているインスタンスの場合、レポートはリクエストがデータノード間で均等に分散されているかも確認します。メトリクスでリクエストの偏りが検出された場合は、どのノードが不均等な負荷を受け取っているかを特定します。
レポートは、次の両方の条件が満たされた場合にリクエストの偏りをフラグ付けします。
-
すべてのデータノードのピーク値が、以下の最小しきい値を超えていること。
-
CPU 使用率:10%
-
メモリ使用率:20%
-
インバウンドおよびアウトバウンドトラフィック:5 Mbit/s
-
接続数使用率:5%
-
-
バランススコアが 1.3 を超えていること。バランススコアは、
max{すべてのデータノードの平均パフォーマンス値} / すべてのデータノードの平均パフォーマンス値の中央値として計算されます。たとえば、インスタンスに 4 つのデータノードがあり、平均 CPU 使用率が 10%、30%、50%、60% であるとします。中央値は 40% で、バランススコアは 60% / 40% = 1.5 です。1.5 > 1.3 であるため、レポートは CPU 使用率に偏りがあると見なします。
| 考えられる原因 | トラブルシューティング方法 |
|---|---|
| データノードに過剰な大きなキーが存在する。 | オフラインキー分析機能 または 上位キー統計機能 を使用してそれらを特定し、再分散してください。 |
| データノードにホットキーが存在する。 | 上位キー統計機能を使用してホットキーを特定してください。 |
| ハッシュタグが不適切に設定されている。同じハッシュタグを持つキーは常に同じデータノードに配置されます。多くのキーが同じハッシュタグを共有すると、そのノードは過負荷になります。 | ハッシュタグの設定を見直し、キーがノード間に分散されるように調整してください。 |
スロークエリが最も多い上位 10 ノード
このセクションでは、スロークエリ数に基づいて上位 10 のデータノードを一覧表示し、それらのクエリに関する詳細を提供します。レポートは、以下の 2 つのスローログデータソースから情報を取得します。
-
システム監査ログ:4 日間保持されるスローログ
-
データノードログ:各データノードに直接保存される最新の 1,024 ログエントリ。redis-cli を使用してインスタンスに接続し、
SLOWLOG GETコマンドを実行して取得します。
r-bp***-db-0 と r-bp***-db-1 の 2 つのノードには、それぞれ 6 つのスロークエリがあります。主なスロークエリコマンドとその実行時間は次のとおりです。
-
keys *:最大実行時間は約 86 ms、平均は約 86 ms -
keys key:0000001*:最大実行時間は約 62 ms、平均は約 59 ms -
複数の
delコマンド:実行時間は約 12~18 ms
スロークエリデータを使用して、パフォーマンスの問題を引き起こしているコマンドを特定してください。
| 原因 | 解決策 |
|---|---|
O(N) の時間計算量または高い CPU コストのコマンド (例:KEYS *) |
FLUSHALL、KEYS、HGETALL などの高リスクコマンドを評価し、無効化してください。詳細については、「高リスクコマンドの無効化」をご参照ください。 |
| 大きなキーがデータノードから頻繁に読み書きされている | オフラインキー分析機能 を使用して大きなキーを分析し、ビジネス要件に基づいて分割してください。 |