Redis インスタンスに負荷がかかっている場合、問題を引き起こす前にメモリを大量に消費するキーを特定することは困難です。オフラインキー分析は、ご利用の Tair (Redis OSS-compatible) インスタンスのバックアップファイルをスキャンして large キーを検出し、メモリ使用量、キー分布、有効期限を表示します。この機能はインスタンスのパフォーマンスに影響を与えません。分析結果を使用してインスタンスを最適化し、キーの偏りによるメモリ枯渇やパフォーマンスの低下を防ぐことができます。
この機能は、[CloudDBA] の キャッシュ解析 機能に基づいて構築されています。
制限事項
ディスクベースのインスタンスはサポートされていません。
インスタンスタイプを変更した場合、変更前に作成されたバックアップファイルは分析できません。
Redis オープンソース版のデータ構造と、Tair 独自のデータ構造である TairString、TairHash、TairGIS、TairBloom、TairDoc、TairCpc、TairZset のみがサポートされています。バックアップファイルに他の Tair 独自のデータ構造が含まれている場合、分析タスクは失敗します。
分析メソッドの選択
3 つの分析メソッドが利用可能です。必要なデータの鮮度に基づいて選択してください。
| メソッド | データの鮮度 | 使用シーン |
|---|---|---|
| 最近のバックアップファイルを使用 | 最終スケジュールバックアップ | 日次または定期的な点検 |
| 履歴バックアップファイルを選択 | 過去の特定の時点 | 既知の状態との比較 |
| 分析用に新しいバックアップを作成 | 現在のインスタンスの状態 | アクティブな問題の調査 |
既存のバックアップファイルを分析する場合は、その作成時刻が調査したい時点と一致していることを確認してください。
オフラインキー分析の実行
前提条件
開始する前に、以下が準備できていることを確認してください:
Tair (Redis OSS-compatible) インスタンス (ディスクベースではないもの)
必要な権限。Resource Access Management (RAM) ユーザーを使用している場合は、「」をご参照ください。
分析タスクの開始
コンソールにログインし、[インスタンス] ページに移動します。インスタンスが存在するリージョンを選択し、インスタンス ID をクリックします。
左側のナビゲーションウィンドウで、CloudDBA > [オフラインキー分析] を選択します。デフォルトでは、前日の分析結果が表示されます。必要に応じて時間範囲を調整してください。
[分析] をクリックします。
ダイアログボックスで、次のパラメーターを設定します。
パラメーター 説明 ノード 分析対象のノード。インスタンス全体または特定のノードを選択します。 分析方法 使用するバックアップファイル。詳細については、「分析メソッドの選択」をご参照ください。 区切り文字 キープレフィックスを識別するために使用される文字。デフォルトのデリミタは `:;,_-+@=|#` です。空白のままにすると、デフォルト値が使用されます。 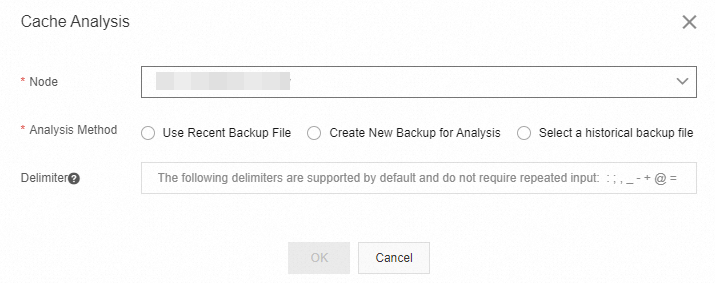
[OK] をクリックします。システムが分析タスクを送信し、そのステータスが表示されます。[更新] をクリックしてステータスを更新します。
結果の表示
タスクのステータスが「完了」と表示されたら、[操作] 列の [詳細] をクリックします。
詳細ページには、次のセクションが含まれています:
基本情報 — インスタンスの属性と使用された分析メソッド。

関連ノード — 各ノードのメモリ使用量とキーの統計。
このセクションは、[ノード] としてインスタンス全体が選択されたクラスターインスタンスまたは読み書き分離インスタンスの場合にのみ表示されます。

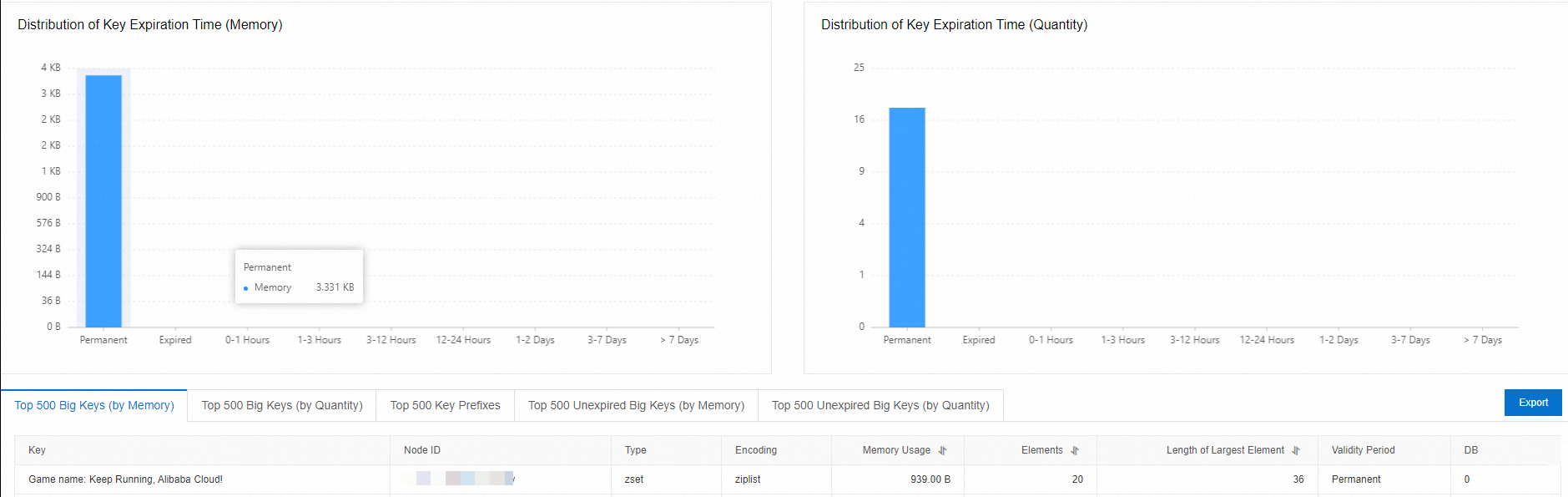
詳細 — 以下を含む内訳:
キータイプ別のメモリ使用量と分布
キー内の要素数とサイズ分布
キーの有効期限の分布
メモリによる上位 large キーのランキング
よくある質問
期限切れのキーが多数存在するのはなぜですか?
生存時間 (TTL) が設定されたキーは、多数が同時に有効期限切れになると蓄積されることがあります。インスタンスはこれらを自動的にクリアしますが、すぐにメモリを解放するには、[データをクリア] 機能を使用してください。詳細については、「期限切れキーのクリア」をご参照ください。
RAM ユーザーの使用時に「permission denied」エラーが報告された場合はどうすればよいですか?
RAM ユーザーに必要な権限を付与し、操作を再試行してください。詳細については、「カスタム権限ポリシーの適用シナリオと例」をご参照ください。
同じインスタンスでタスクごとに分析速度が異なるのはなぜですか?
分析タスクは CloudDBA で非同期に実行されます。他のタスクがキューの前方にある場合、ご利用のタスクの待機時間が長くなります。合計時間はインスタンスのサイズだけでなく、キューの深さにも依存します。
decode rdbfile error: rdb: unknown object type 116 for key を修正するにはどうすればよいですか?
バックアップに非標準の Bloom 構造が含まれていますが、これらは分析でサポートされていません。
decode rdbfile error: rdb: invalid file format を修正するにはどうすればよいですか?
一般的な原因は 2 つあります:
バックアップ作成後にインスタンス構成が変更された。現在の構成に一致するバックアップを選択してください。
TDE (透過的データ暗号化) が有効になっています。この機能は、暗号化されたバックアップファイルを分析できません。
decode rdbfile error: rdb: unknown module type を修正するにはどうすればよいですか?
バックアップに、サポートされているリスト (TairString、TairHash、TairGIS、TairBloom、TairDoc、TairCpc、TairZset) にない Tair 独自のデータ構造が含まれています。サポートされていない構造を含むバックアップでは、分析を進めることはできません。
分析用に新しいバックアップを作成する際に XXX backup failed エラーを修正するにはどうすればよいですか?
インスタンスで BGSAVE または BGREWRITEAOF コマンドが実行されており、新しいバックアップがブロックされています。オフピーク時間に分析を実行するか、代わりに 最近のバックアップファイルを使用 または 履歴バックアップファイルを選択 に切り替えてください。
[詳細] ページのメモリ使用量が実際の使用量よりも少なく表示されるのはなぜですか?
この分析では、Redis データベース (RDB) バックアップファイル内のシリアル化されたキーと値のデータに基づいてメモリを計算します。これは、実際のメモリフットプリントの一部にすぎません。残りの部分には以下が含まれます:
構造体データ、ポインター、およびバイトアライメントのオーバーヘッド。2 億 5000 万個のキーを持つインスタンスの場合、これにより約 2~3 GB (jemalloc を介して割り当て) が追加される可能性があります。
クライアント側のバッファー:出力バッファー、クエリバッファー、および AOF (Append-Only File) 書き換えバッファー。
プライマリ/レプリカレプリケーションからのレプリケーションバックログ。
Stream キーのメモリ使用量が予想よりも数倍高いのはなぜですか?
Stream は、内部で基数木 (radix tree) と listpack を使用する複雑なデータ構造です。この分析では、これらのネストされた構造のメモリを正確に測定できないため、結果は概算値となります。この不一致は統計的なものであり、インスタンスの機能には影響しません。
String キーの要素数と要素の長さが同じなのはなぜですか?
Tair (Redis OSS-compatible) インスタンスの場合、String キーの要素数は値の長さとして定義されます。これは仕様によるものです。
API リファレンス
| API | 説明 |
|---|---|
| CreateCacheAnalysisJob | キャッシュ解析タスクを作成します |
| DescribeCacheAnalysisJob | キャッシュ解析タスクの詳細を照会します |
| DescribeCacheAnalysisJobs | キャッシュ解析タスクを一覧表示します |
次のステップ
上位キー統計 — バックアップファイルなしで large キーをリアルタイムに監視します