アナライザは、テキストフィールドを解析および形態素解析(トークン化)し、TairSearch がインデックスを構築して全文検索クエリに応答できるようにします。各アナライザは、文字フィルター、トークナイザー、トークンフィルターの 3 つのステージを順次実行します。TairSearch には、9 種類の組み込みアナライザが同梱されています。特殊な要件がある場合は、個別のコンポーネントからカスタムアナライザを構築できます。
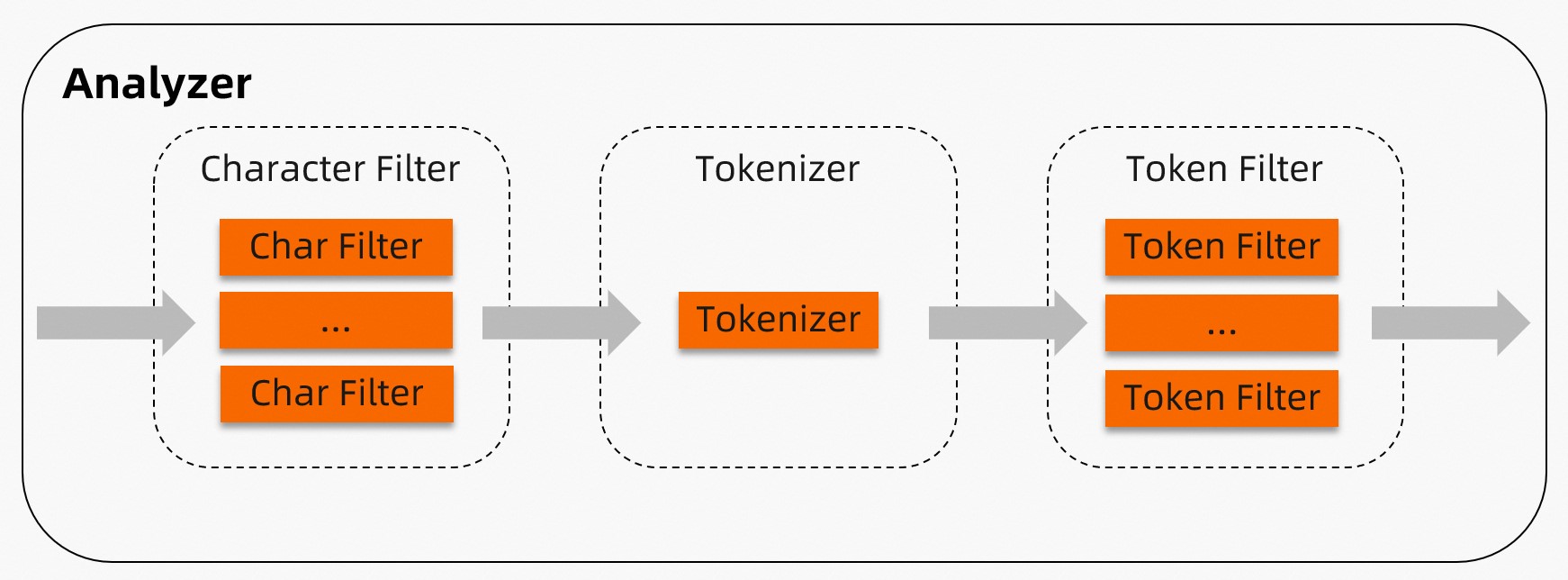
| ステージ | 目的 | アナライザあたりの数 |
|---|---|---|
| 文字フィルター | トークン化前の生のテキストを前処理します(例: :) を _happy_ に置き換え) | 0 個以上(順序通りに実行) |
| トークナイザー | 前処理済みのテキストをトークンに分割します | 1 個のみ |
| トークンフィルター | 各トークンを後処理します(例:小文字化、ストップワード除去、語幹抽出) | 0 個以上(順序通りに実行) |
アナライザの選択
| アナライザ | 推奨用途 | トークン化方法 | 小文字化 | ストップワード除去 |
|---|---|---|---|---|
| 標準 | ほとんどの言語 | Unicode の単語境界 | はい | はい |
| Stop | ほとんどの言語(ストップワードに重点) | 非英字文字 | はい | はい |
| Jieba | 中国語テキスト | 学習済み辞書 | 英語トークンのみ | はい |
| IK | 中国語テキスト(Elasticsearch 互換) | 学習済み辞書(2 モード対応) | 実施(デフォルト) | 任意設定可能 |
| Pattern | カスタム区切り文字ロジック | 正規表現パターン | 任意設定可能 | 任意設定可能 |
| Whitespace | 事前にトークン化済みまたは構造化されたテキスト | 空白文字 | 実施しない | 実施しない |
| Simple | 西洋言語テキスト(大文字・小文字を区別しない) | 非英字文字 | はい | いいえ |
| Keyword | 完全一致検索対象のフィールド | 分割なし(フィールド全体 = 1 トークン) | 実施しない | いいえ |
| Language | 特定の自然言語 | 言語固有のルール | はい | はい |
仕組み
アナライザは、ドキュメントを 3 つの順次実行されるステージで処理します。
ステージ 1 — 文字フィルター:0 個以上の文字フィルターが、生のドキュメントテキストを前処理します。フィルターは、指定された順序で実行されます。たとえば、マッピング文字フィルターは、トークン化開始前に "(:" を "happy" に置き換えます。
ステージ 2 — トークナイザー:1 個のトークナイザーが、(必要に応じて前処理済みの)テキストをトークンに分割します。たとえば、Whitespace トークナイザーは "I am very happy" を ["I", "am", "very", "happy"] に分割します。
ステージ 3 — トークンフィルター:0 個以上のトークンフィルターが、トークナイザーから出力されたトークンを後処理します。フィルターは、指定された順序で実行されます。たとえば、Stop トークンフィルターは "the" や "is" などの一般的なストップワードを除去します。
組み込みアナライザ
標準
標準アナライザは、ほとんどの言語でデフォルトとして推奨されるアナライザです。Unicode の単語境界(Unicode Standard Annex #29 に基づく)でテキストを分割し、すべてのトークンを小文字化し、一般的なストップワードを除去します。
構成要素: 標準トークナイザー → 小文字化トークンフィルター → ストップトークンフィルター
文字フィルターは含まれません。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
stopwords | 除去対象のストップワードの配列。デフォルトリストを完全に上書きします。 | 以下を参照 |
max_token_length | トークンあたりの最大文字数。この長さを超えるトークンは、指定された長さで分割されます。 | 255 |
デフォルトのストップワード:
["a", "an", "and", "are", "as", "at", "be", "but", "by", "for", "if", "in",
"into", "is", "it", "no", "not", "of", "on", "or", "such", "that", "the",
"their", "then", "there", "these", "they", "this", "to", "was", "will", "with"]構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "standard"
}
}
}
}// カスタムストップワードおよびトークン長
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "standard",
"max_token_length": 10,
"stopwords": ["memory", "disk", "is", "a"]
}
}
}
}
}Stop
Stop アナライザは、非英字文字でテキストを分割し、すべてのトークンを小文字化し、ストップワードを除去します。
構成要素: 小文字化トークナイザー → ストップトークンフィルター
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
stopwords | 除去対象のストップワードの配列。デフォルトリストを完全に上書きします。 | 標準アナライザと同じ |
構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "stop"
}
}
}
}// カスタムストップワード
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "stop",
"stopwords": ["memory", "disk", "is", "a"]
}
}
}
}
}Jieba
Jieba アナライザは、中国語テキストに推奨されます。Jieba の辞書ベースの分割を使用してテキストを分割し、英語トークンを小文字化し、ストップワードを除去します。
構成要素: Jieba トークナイザー → 小文字化トークンフィルター → ストップトークンフィルター
Jieba アナライザは、20 MB の組み込み辞書をメモリに読み込みます。辞書はグローバルに 1 つだけ読み込まれます。Jieba の初回使用時には、辞書読み込み中に一時的にレイテンシーが増加する場合があります。
カスタム辞書内の単語には、スペースおよび以下の文字を含めることはできません:
\t、\n、,、。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
userwords | デフォルト辞書に追加される文字列の配列。 Jieba デフォルト辞書Jieba デフォルト辞書 をご参照ください。 | 空 |
use_hmm | 隠れマルコフモデル(HMM)を使用して、辞書に登録されていない語彙(OOV)を処理します。 | true |
stopwords | 除去対象のストップワードの配列。デフォルトリストを完全に上書きします。 Jieba デフォルトストップワードJieba デフォルトストップワード をご参照ください。 | 組み込みリスト |
構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "jieba"
}
}
}
}// カスタム辞書、ストップワード、および HMM の使用
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "jieba",
"stopwords": ["memory", "disk", "is", "a"],
"userwords": ["Redis", "open-source", "flexible"],
"use_hmm": true
}
}
}
}
}IK
IK アナライザは、中国語テキストの分割に対応しており、Alibaba Cloud Elasticsearch の IK アナライザプラグインと互換性があります。2 つのモードをサポートしています。
`ik_max_word`:可能なすべてのトークンを識別します。
`ik_smart`:
ik_max_wordモードの結果をフィルター処理して、最も可能性の高いトークンを特定します。
構成要素: IK トークナイザー(デフォルトではトークンフィルターなし)
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
stopwords | 除去対象のストップワードの配列。デフォルトリストを完全に上書きします。 | 標準と同じ |
userwords | デフォルト IK 辞書に追加される文字列の配列。 デフォルト IK 辞書 をご参照ください。 | 空 |
quantifiers | デフォルトの数量詞辞書に追加される数量詞の配列。 デフォルトの数量詞辞書 をご参照ください。 | 空 |
enable_lowercase | トークン化前に大文字を小文字に変換します。 | true |
カスタム辞書に大文字が含まれる場合は、enable_lowercase を false に設定してください。小文字化は分割の前に実行されるため、辞書内の大文字のエントリは一致しません。
構成例:
// デフォルト構成:両方の IK モード
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "ik_smart"
},
"f1": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}// カスタムストップワード、辞書、および数量詞
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_ik_smart_analyzer"
},
"f1": {
"type": "text",
"analyzer": "my_ik_max_word_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_ik_smart_analyzer": {
"type": "ik_smart",
"stopwords": ["memory", "disk", "is", "a"],
"userwords": ["Redis", "open-source", "flexible"],
"quantifiers": ["ns"],
"enable_lowercase": false
},
"my_ik_max_word_analyzer": {
"type": "ik_max_word",
"stopwords": ["memory", "disk", "is", "a"],
"userwords": ["Redis", "open-source", "flexible"],
"quantifiers": ["ns"],
"enable_lowercase": false
}
}
}
}
}Pattern
Pattern アナライザは、正規表現を使用してテキストを分割します。デフォルトでは、マッチしたテキストが区切り文字(デリミタ)として扱われ、マッチした部分の間にあるテキストがトークンになります。また、トークンを小文字化し、ストップワードを除去します。
構成要素: Pattern トークナイザー → 小文字化トークンフィルター → ストップトークンフィルター
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
pattern | 正規表現。マッチしたテキストが区切り文字として使用されます。 RE2 構文 をご参照ください。 | \W+ |
stopwords | ストップワードの配列。デフォルトリストを完全に上書きします。 | 標準版と同じ |
lowercase | トークンを小文字化します。 | true |
flags | 正規表現を大文字・小文字を区別しないものにするには、CASE_INSENSITIVE を指定します。 | 空(大文字・小文字を区別) |
構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "pattern"
}
}
}
}// 大文字・小文字を区別しないマッチングを伴うカスタムパターン
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "pattern",
"pattern": "\\'([^\\']+)\\'",
"stopwords": ["aaa", "@"],
"lowercase": false,
"flags": "CASE_INSENSITIVE"
}
}
}
}
}Whitespace
Whitespace アナライザは、空白文字でテキストを分割します。トークンの小文字化やストップワードの除去は行いません。
構成要素: Whitespace トークナイザー
任意パラメーター: なし
構成:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "whitespace"
}
}
}
}Simple
Simple アナライザは、非英字文字でテキストを分割し、すべてのトークンを小文字化します。ストップワードの除去は行いません。
構成要素: 小文字化トークナイザー
任意パラメーター: なし
構成:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "simple"
}
}
}
}Keyword
Keyword アナライザは、フィールド値全体を分割せずに 1 つのトークンとして扱います。ID、状態コード、タグなど、完全一致検索が必要なフィールドに使用します。
構成要素: Keyword トークナイザー
任意パラメーター: なし
構成:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "keyword"
}
}
}
}Language
Language アナライザは、固定された言語セットに対する言語固有のトークン化およびストップワード除去をサポートします。arabic、cjk、chinese、brazilian、czech、german、greek、persian、french、dutch、russian が対応しています。
任意パラメーター:
| パラメーター | 説明 | デフォルト | 対応言語 |
|---|---|---|---|
stopwords | ストップワードの配列です。デフォルトのリストを置き換えます。デフォルトのリストについては、付録 4 をご参照ください。 | 言語固有 | chinese |
stem_exclusion | 語幹が抽出されないようにする単語の配列です。たとえば、"apples" を追加すると、"apple" に変換されなくなります。 | 空 | brazilian、 german、 french、 dutch |
chinese アナライザのストップワードは変更できません。構成例:
// デフォルト構成(アラビア語)
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "arabic"
}
}
}
}// カスタムストップワードおよび語幹除外(ドイツ語)
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "german",
"stopwords": ["ein"],
"stem_exclusion": ["speicher"]
}
}
}
}
}カスタムアナライザ
組み込みアナライザが要件を満たさない場合、カスタムアナライザを構築します。settings でアナライザを定義し、mappings 内でその名前を参照します。
パラメーター:
| パラメーター | 必須 | 説明 | 有効な値 |
|---|---|---|---|
type | はい | カスタムアナライザであることを識別します。 | custom |
tokenizer | はい | 使用するトークナイザー。1 つだけ許可されます。 | whitespace、lowercase、standard、classic、letter、keyword、jieba、pattern、ik_max_word、ik_smart |
char_filter | いいえ | トークン化前に適用する文字フィルターの配列。 | mapping(「付録 1」を参照) |
filter | いいえ | トークン化後に適用するトークンフィルターの配列。 | classic、elision、lowercase、snowball、stop、asciifolding、length、arabic_normalization、persian_normalization(「付録 3」を参照) |
例:絵文字の置換およびストップワード除去を伴うカスタムアナライザ
// 文字フィルターは、トークン化前に絵文字を置換し、「&」を展開します。
// Whitespace トークナイザーは、空白で分割します。
// トークンフィルターは、小文字化およびストップワード除去を行います。
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lowercase", "stop"],
"char_filter": ["emoticons", "conjunctions"]
}
},
"char_filter": {
"emoticons": {
"type": "mapping",
"mappings": [":) => _happy_", ":( => _sad_"]
},
"conjunctions": {
"type": "mapping",
"mappings": ["&=>and"]
}
}
}
}
}付録 1:対応する文字フィルター
マッピング文字フィルター
キーと値のペアを使用して指定された文字列を置き換えます。入力にキーが含まれている場合、対応する値に置き換えられます。1 つのアナライザで複数のマッピング文字フィルターを使用できます。
パラメーター:
| パラメーター | 必須 | 説明 |
|---|---|---|
mappings | はい | 置換ルールの配列。各ルールは "key => value" の形式で指定する必要があります。例:"& => and"。 |
構成例:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"char_filter": ["emoticons"]
}
},
"char_filter": {
"emoticons": {
"type": "mapping",
"mappings": [":) => _happy_", ":( => _sad_"]
}
}
}
}
}付録 2:対応するトークナイザー
whitespace
空白文字でテキストを分割します。max_token_length を超えるトークンは、指定された長さで分割されます。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
max_token_length | トークンあたりの最大文字数。この長さを超えるトークンは、指定された長さで分割されます。 | 255 |
構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace"
}
}
}
}
}// カスタムトークン最大長
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "token1"
}
},
"tokenizer": {
"token1": {
"type": "whitespace",
"max_token_length": 2
}
}
}
}
}standard
Unicode のテキスト分割アルゴリズム(Unicode Standard Annex #29)を使用してテキストを分割します。ほとんどの言語に適しています。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
max_token_length | トークンあたりの最大文字数。この長さを超えるトークンは、指定された長さで分割されます。 | 255 |
構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard"
}
}
}
}
}// カスタムトークン最大長
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "token1"
}
},
"tokenizer": {
"token1": {
"type": "standard",
"max_token_length": 2
}
}
}
}
}classic
英語の文法ルールを使用してテキストを分割し、特定のパターンを特別に処理します。
句読点で分割し、句読点を削除します。ただし、非空白文字に囲まれたピリオド(
.)は保持されます。たとえば、red.appleは分割されませんが、red. appleはredとappleに分割されます。ハイフンで分割しますが、トークンに数字が含まれる場合は(製品番号と解釈され、そのまま保持されます)、分割されません。
メールアドレスおよびホスト名を単一のトークンとして認識します。
max_token_length を超えるトークンは、分割されずスキップされます。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
max_token_length | トークンあたりの最大文字数。この長さを超えるトークンはスキップされます。 | 255 |
構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "classic"
}
}
}
}
}// カスタムトークン最大長
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "token1"
}
},
"tokenizer": {
"token1": {
"type": "classic",
"max_token_length": 2
}
}
}
}
}letter
非英字文字でテキストを分割します。ヨーロッパ言語に適しています。
構成:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "letter"
}
}
}
}
}lowercase
非英字文字でテキストを分割し、すべてのトークンを小文字化します。Letter トークナイザーと小文字化トークンフィルターを組み合わせたものと同等ですが、ドキュメントを 1 回だけ走査するため、より高速です。
構成:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "lowercase"
}
}
}
}
}keyword
入力全体を分割せずに単一のトークンとして扱います。通常、lowercase などのトークンフィルターと併用されます。
構成:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "keyword"
}
}
}
}
}jieba
学習済み辞書を使用して中国語テキストを分割します。中国語のフィールドに推奨されます。
カスタム辞書内の単語には、スペースおよび以下の文字を含めることはできません:\t、\n、,、。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
userwords | デフォルト辞書に追加される文字列の配列。 デフォルト Jieba 辞書 をご参照ください。 | 空 |
use_hmm | 隠れマルコフモデル(HMM)を使用して、辞書に登録されていない語彙(OOV)を処理します。 | true |
構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "jieba"
}
}
}
}
}// カスタム辞書
{
"mappings": {
"properties": {
"f1": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "token1"
}
},
"tokenizer": {
"token1": {
"type": "jieba",
"userwords": ["Redis", "open-source", "flexible"],
"use_hmm": true
}
}
}
}
}pattern
正規表現を使用してテキストを分割します。デフォルトでは、マッチしたテキストが区切り文字(デリミタ)として扱われます。group パラメーターを使用すると、マッチしたテキストをトークンとして扱うこともできます。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
pattern | 正規表現。 RE2 構文 をご参照ください。 | \W+ |
group | 正規表現の結果の使用方法を制御します。-1 の場合、マッチしたテキストが区切り文字として使用されます。0 の場合、完全なマッチがトークンとして使用されます。1 以上の場合、対応するキャプチャグループがトークンとして使用されます。 | -1 |
flags | 正規表現を大文字・小文字を区別しないものにするには、CASE_INSENSITIVE を指定します。 | 空(大文字・小文字を区別) |
`group` の動作例:
正規表現:"a(b+)c"、入力:"abbbcdefabc"
group: 0→ トークン:[ abbbc, abc ](完全なマッチ)group: 1→ トークン:[ bbb, b ](最初のキャプチャグループ)
構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "pattern"
}
}
}
}
}// キャプチャグループを伴うカスタムパターン
{
"mappings": {
"properties": {
"f1": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "pattern_tokenizer"
}
},
"tokenizer": {
"pattern_tokenizer": {
"type": "pattern",
"pattern": "AB(A(\\w+)C)",
"flags": "CASE_INSENSITIVE",
"group": 2
}
}
}
}
}IK
中国語テキストを分割します。2 つのモードをサポートしています。
`ik_max_word`:可能なすべてのトークンを識別します(最大粒度)。
`ik_smart`:最も可能性の高いトークンを識別します(粗い粒度)。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
stopwords | ストップワードの配列。デフォルトリストを完全に上書きします。 | 標準と同じ |
userwords | デフォルト IK 辞書に追加される文字列の配列。 デフォルト IK 辞書 をご参照ください。 | 空 |
quantifiers | デフォルトの数量詞辞書に追加される数量詞の配列。 デフォルトの数量詞辞書 をご参照ください。 | 空 |
enable_lowercase | トークン化前に大文字を小文字に変換します。 | true |
カスタム辞書に大文字が含まれる場合は、enable_lowercase を false に設定してください。小文字化は分割の前に実行されます。
構成例:
// デフォルト構成:両方の IK モード
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_ik_smart_analyzer"
},
"f1": {
"type": "text",
"analyzer": "my_custom_ik_max_word_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_ik_smart_analyzer": {
"type": "custom",
"tokenizer": "ik_smart"
},
"my_custom_ik_max_word_analyzer": {
"type": "custom",
"tokenizer": "ik_max_word"
}
}
}
}
}// カスタム辞書、ストップワード、および数量詞
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_ik_smart_analyzer"
},
"f1": {
"type": "text",
"analyzer": "my_custom_ik_max_word_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_ik_smart_analyzer": {
"type": "custom",
"tokenizer": "my_ik_smart_tokenizer"
},
"my_custom_ik_max_word_analyzer": {
"type": "custom",
"tokenizer": "my_ik_max_word_tokenizer"
}
},
"tokenizer": {
"my_ik_smart_tokenizer": {
"type": "ik_smart",
"userwords": ["The tokenizer for the Chinese language", "The custom stop words"],
"stopwords": ["about", "test"],
"quantifiers": ["ns"],
"enable_lowercase": false
},
"my_ik_max_word_tokenizer": {
"type": "ik_max_word",
"userwords": ["The tokenizer for the Chinese language", "The custom stop words"],
"stopwords": ["about", "test"],
"quantifiers": ["ns"],
"enable_lowercase": false
}
}
}
}
}付録 3:対応するトークンフィルター
classic
トークンの末尾にある所有格 's を削除し、頭字語のピリオドを除去します。たとえば、Fig. は Fig になります。
構成:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "classic",
"filter": ["classic"]
}
}
}
}
}elision
トークンの先頭から指定された省略形を除去します。主にフランス語テキストで使用されます(例:l'avion → avion)。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
articles | 除去対象の省略形の配列。デフォルトリストを完全に上書きします。 | ["l", "m", "t", "qu", "n", "s", "j"] |
articles_case | 省略形のマッチングを大文字・小文字を区別するかどうか。 | false |
構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["elision"]
}
}
}
}
}// 大文字・小文字を区別するカスタム省略形
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["elision_filter"]
}
},
"filter": {
"elision_filter": {
"type": "elision",
"articles": ["l", "m", "t", "qu", "n", "s", "j"],
"articles_case": true
}
}
}
}
}lowercase
すべてのトークンを小文字化します。
任意パラメーター:
| パラメーター | 説明 | 有効な値 |
|---|---|---|
language | 言語固有の小文字化ルールを適用します。未指定の場合は、標準の英語ルールが適用されます。 | greek、russian |
構成例:
// デフォルト構成(英語)
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["lowercase"]
}
}
}
}
}// 言語固有の小文字化(ギリシャ語およびロシア語)
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_greek_analyzer"
},
"f1": {
"type": "text",
"analyzer": "my_custom_russian_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_greek_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["greek_lowercase"]
},
"my_custom_russian_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["russian_lowercase"]
}
},
"filter": {
"greek_lowercase": {
"type": "lowercase",
"language": "greek"
},
"russian_lowercase": {
"type": "lowercase",
"language": "russian"
}
}
}
}
}snowball
各トークンから語幹を抽出します。たとえば、cats は cat に、running は run になります。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 | 有効な値 |
|---|---|---|---|
language | 語幹抽出に使用する言語のルール。 | english | english、german、french、dutch |
構成例:
// デフォルト構成(英語)
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["snowball"]
}
}
}
}
}// 標準トークナイザーを伴う英語語幹抽出
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["my_filter"]
}
},
"filter": {
"my_filter": {
"type": "snowball",
"language": "english"
}
}
}
}
}stop
トークンストリームからストップワードを除去します。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
stopwords | ストップワードの配列。デフォルトリストを完全に上書きします。 | 標準と同じ |
ignoreCase | ストップワードのマッチングを大文字・小文字を区別しないかどうか。 | false |
構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["stop"]
}
}
}
}
}// 大文字・小文字を区別しないカスタムストップワード
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["stop_filter"]
}
},
"filter": {
"stop_filter": {
"type": "stop",
"stopwords": ["the"],
"ignore_case": true
}
}
}
}
}asciifolding
基本ラテン Unicode ブロック外のアルファベット、数字、記号を、それらの ASCII 等価文字に変換します。たとえば、é は e に、ü は u になります。このフィルターは、ヨーロッパ言語のアクセント付き文字を正規化するために使用します。
構成:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["asciifolding"]
}
}
}
}
}length
指定された文字数より短いまたは長いトークンを除去します。
任意パラメーター:
| パラメーター | 説明 | デフォルト値 |
|---|---|---|
min | トークンが保持されるために必要な最小文字数。 | 0 |
max | トークンが保持されるために許容される最大文字数。 | 2147483647(2^31 - 1) |
構成例:
// デフォルト構成
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["length"]
}
}
}
}
}// 2 文字以上 5 文字以下のトークンのみを保持
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": ["length_filter"]
}
},
"filter": {
"length_filter": {
"type": "length",
"max": 5,
"min": 2
}
}
}
}
}Normalization
言語固有の文字を正規化します。arabic_normalization をアラビア語テキストに、persian_normalization をペルシャ語テキストに使用します。最適な結果を得るには、このフィルターを標準トークナイザーと併用してください。
構成:
{
"mappings": {
"properties": {
"f0": {
"type": "text",
"analyzer": "my_arabic_analyzer"
},
"f1": {
"type": "text",
"analyzer": "my_persian_analyzer"
}
}
},
"settings": {
"analysis": {
"analyzer": {
"my_arabic_analyzer": {
"type": "custom",
"tokenizer": "arabic",
"filter": ["arabic_normalization"]
},
"my_persian_analyzer": {
"type": "custom",
"tokenizer": "arabic",
"filter": ["persian_normalization"]
}
}
}
}
}付録 4:言語アナライザのデフォルトストップワード
arabic
["","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","",""]cjk
["with","will","to","this","there","then","the","t","that","such","s","on","not","no","it","www","was","is","","into","their","or","in","if","for","by","but","they","be","these","at","are","as","and","of","a"]brazilian
["uns","umas","uma","teu","tambem","tal","suas","sobre","sob","seu","sendo","seja","sem","se","quem","tua","que","qualquer","porque","por","perante","pelos","pelo","outros","outro","outras","outra","os","o","nesse","nas","na","mesmos","mesmas","mesma","um","neste","menos","quais","mediante","proprio","logo","isto","isso","ha","estes","este","propios","estas","esta","todas","esses","essas","toda","entre","nos","entao","em","eles","qual","elas","tuas","ela","tudo","do","mesmo","diversas","todos","diversa","seus","dispoem","ou","dispoe","teus","deste","quer","desta","diversos","desde","quanto","depois","demais","quando","essa","deles","todo","pois","dele","dela","dos","de","da","nem","cujos","das","cujo","durante","cujas","portanto","cuja","contudo","ele","contra","como","com","pelas","assim","as","aqueles","mais","esse","aquele","mas","apos","aos","aonde","sua","e","ao","antes","nao","ambos","ambas","alem","ainda","a"]czech
["a","s","k","o","i","u","v","z","dnes","cz","tímto","budeš","budem","byli","jseš","muj","svým","ta","tomto","tohle","tuto","tyto","jej","zda","proc","máte","tato","kam","tohoto","kdo","kterí","mi","nám","tom","tomuto","mít","nic","proto","kterou","byla","toho","protože","asi","ho","naši","napište","re","což","tím","takže","svých","její","svými","jste","aj","tu","tedy","teto","bylo","kde","ke","pravé","ji","nad","nejsou","ci","pod","téma","mezi","pres","ty","pak","vám","ani","když","však","neg","jsem","tento","clánku","clánky","aby","jsme","pred","pta","jejich","byl","ješte","až","bez","také","pouze","první","vaše","která","nás","nový","tipy","pokud","muže","strana","jeho","své","jiné","zprávy","nové","není","vás","jen","podle","zde","už","být","více","bude","již","než","který","by","které","co","nebo","ten","tak","má","pri","od","po","jsou","jak","další","ale","si","se","ve","to","jako","za","zpet","ze","do","pro","je","na","atd","atp","jakmile","pricemž","já","on","ona","ono","oni","ony","my","vy","jí","ji","me","mne","jemu","tomu","tem","temu","nemu","nemuž","jehož","jíž","jelikož","jež","jakož","nacež"]german
["wegen","mir","mich","dich","dir","ihre","wird","sein","auf","durch","ihres","ist","aus","von","im","war","mit","ohne","oder","kein","wie","was","es","sie","mein","er","du","daß","dass","die","als","ihr","wir","der","für","das","einen","wer","einem","am","und","eines","eine","in","einer"]greek
["ο","η","το","οι","τα","του","τησ","των","τον","την","και","κι","κ","ειμαι","εισαι","ειναι","ειμαστε","ειστε","στο","στον","στη","στην","μα","αλλα","απο","για","προσ","με","σε","ωσ","παρα","αντι","κατα","μετα","θα","να","δε","δεν","μη","μην","επι","ενω","εαν","αν","τοτε","που","πωσ","ποιοσ","ποια","ποιο","ποιοι","ποιεσ","ποιων","ποιουσ","αυτοσ","αυτη","αυτο","αυτοι","αυτων","αυτουσ","αυτεσ","αυτα","εκεινοσ","εκεινη","εκεινο","εκεινοι","εκεινεσ","εκεινα","εκεινων","εκεινουσ","οπωσ","ομωσ","ισωσ","οσο","οτι"]persian
["","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","",""]french
["ô","être","vu","vous","votre","un","tu","toute","tout","tous","toi","tiens","tes","suivant","soit","soi","sinon","siennes","si","se","sauf","s","quoi","vers","qui","quels","ton","quelle","quoique","quand","près","pourquoi","plus","à","pendant","partant","outre","on","nous","notre","nos","tienne","ses","non","qu","ni","ne","mêmes","même","moyennant","mon","moins","va","sur","moi","miens","proche","miennes","mienne","tien","mien","n","malgré","quelles","plein","mais","là","revoilà","lui","leurs","","toutes","le","où","la","l","jusque","jusqu","ils","hélas","ou","hormis","laquelle","il","eu","nôtre","etc","est","environ","une","entre","en","son","elles","elle","dès","durant","duquel","été","du","voici","par","dont","donc","voilà","hors","doit","plusieurs","diverses","diverse","divers","devra","devers","tiennes","dessus","etre","dessous","desquels","desquelles","ès","et","désormais","des","te","pas","derrière","depuis","delà","hui","dehors","sans","dedans","debout","vôtre","de","dans","nôtres","mes","d","y","vos","je","concernant","comme","comment","combien","lorsque","ci","ta","nບnmoins","lequel","chez","contre","ceux","cette","j","cet","seront","que","ces","leur","certains","certaines","puisque","certaine","certain","passé","cependant","celui","lesquelles","celles","quel","celle","devant","cela","revoici","eux","ceci","sienne","merci","ce","c","siens","les","avoir","sous","avec","pour","parmi","avant","car","avait","sont","me","auxquels","sien","sa","excepté","auxquelles","aux","ma","autres","autre","aussi","auquel","aujourd","au","attendu","selon","après","ont","ainsi","ai","afin","vôtres","lesquels","a"]dutch
["andere","uw","niets","wil","na","tegen","ons","wordt","werd","hier","eens","onder","alles","zelf","hun","dus","kan","ben","meer","iets","me","veel","omdat","zal","nog","altijd","ja","want","u","zonder","deze","hebben","wie","zij","heeft","hoe","nu","heb","naar","worden","haar","daar","der","je","doch","moet","tot","uit","bij","geweest","kon","ge","zich","wezen","ze","al","zo","dit","waren","men","mijn","kunnen","wat","zou","dan","hem","om","maar","ook","er","had","voor","of","als","reeds","door","met","over","aan","mij","was","is","geen","zijn","niet","iemand","het","hij","een","toen","in","toch","die","dat","te","doen","ik","van","op","en","de"]russian
["","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","","",""]