インスタンスの I/O スループットが高くなると、クエリパフォーマンスが低下する可能性があります。このトピックでは、I/O スループットの表示方法と、I/O 負荷が高い場合の問題のトラブルシューティング方法について説明します。
背景情報
I/O パフォーマンスは、主に IOPS と I/O スループットによって測定されます。IOPS がパフォーマンスのボトルネックになることはほとんどありません。しかし、I/O スループットは上限に達するとボトルネックになる可能性があります。
I/O スループットの上限
-
プレミアムローカル SSD を使用するインスタンス
プレミアムローカル SSD を使用するインスタンスは、同じ物理ホストのローカル SSD を共有します。単一インスタンスの最大 IOPS のみが制限され、I/O スループットは制限されません。その結果、単一インスタンスの I/O スループットは 1 GB/s を超えることがあります。ただし、この共有アーキテクチャは I/O リソースの競合につながる可能性があります。専用の I/O リソースが必要な場合は、 専用ホストインスタンスタイプ を選択してください。
-
クラウドディスクを使用するインスタンス
クラウドディスクを使用するインスタンスは、各インスタンスに独自のクラウドディスクがアタッチされているため、専用で分離された I/O リソースを使用します。単一インスタンスの I/O スループットの上限は、次の 2 つの要因によって決まります。
-
インスタンス仕様:クラウドディスクを使用する ApsaraDB RDS for SQL Server インスタンスのコンピューティング仕様は、主に Elastic Compute Service (ECS) の g6 世代インスタンスファミリーに基づいており、その I/O スループットは 対応する仕様の上限 によって制限されます。
-
ストレージタイプと容量:クラウドディスクを使用する ApsaraDB RDS for SQL Server インスタンスは、標準 SSD、 ESSDなどのストレージタイプをサポートします。その I/O スループットは、 対応するストレージタイプと容量 によって制限されます。
-
I/O スループットの表示
この機能は、クラウドディスクを使用する ApsaraDB RDS for SQL Server 2008 R2 インスタンスでは利用できません。
- RDSインスタンスにアクセスし、上部のリージョンを選択し、対象のRDSインスタンスのIDをクリックします。
-
左側メニューで、 自律型サービス > 性能を最適化する を選択し、 パフォーマンスインサイト タブをクリックします。
-
右上隅にある カスタムメトリクス をクリックし、 IO スループット に関連するパフォーマンスメトリクスを選択して、 決定 をクリックします。
説明IO スループット カテゴリには、次のパフォーマンスメトリクスが含まれます:
-
IO_Throughput_Read_Kb:ディスクの読み取り I/O スループット (KB/s)。
-
IO_Throughput_Write_kb:ディスクの書き込み I/O スループット (KB/s)。
-
IO_Throughput_Total_Kb:ディスクの読み取りと書き込みの I/O スループットの合計 (KB/s)。
-
I/O スループットの分析と最適化
ApsaraDB RDS for SQL Server インスタンスの I/O 負荷は、主にデータファイルの読み取りリクエストと、トランザクションログファイルの読み取り/書き込みリクエストで構成されます。データファイルの読み取りリクエストは、主にクエリ中のデータページの読み取りとデータベースのバックアップから発生します。トランザクションログファイルは、バックアップ中に高い読み取り I/O 負荷が発生し、それ以外の状況では主に書き込み I/O 負荷が発生します。
インスタンスで高い I/O スループットが確認された場合は、 カスタムメトリクス パネルで次のパフォーマンスメトリクスを追加して、どのタイプの負荷が増加の原因となっているかを分析できます。
|
メトリック |
タイプ |
説明 |
|
Page_Reads |
読み取り |
キャッシュミスにより、データファイルから 1 秒あたりに読み取られるデータページの数。 |
|
Page_Write |
書き込み |
データファイルに 1 秒あたりに書き込まれるデータページの数。 |
|
Log_Bytes_Flushed/sec |
書き込み |
ログファイルに 1 秒あたりに書き込まれるバイト数。 |
|
Backup_Restore_Throughput/sec |
読み取り |
バックアップまたは復元操作中に、データファイルおよびログファイルに対して1秒あたりに読み書きされるバイト数。 |
各データページのサイズは 8 KB です。
ケーススタディ
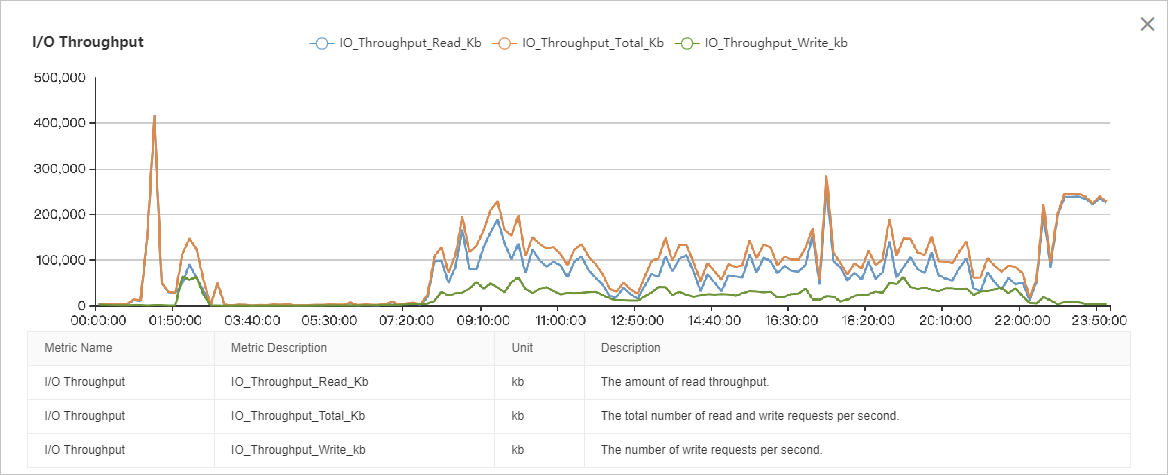
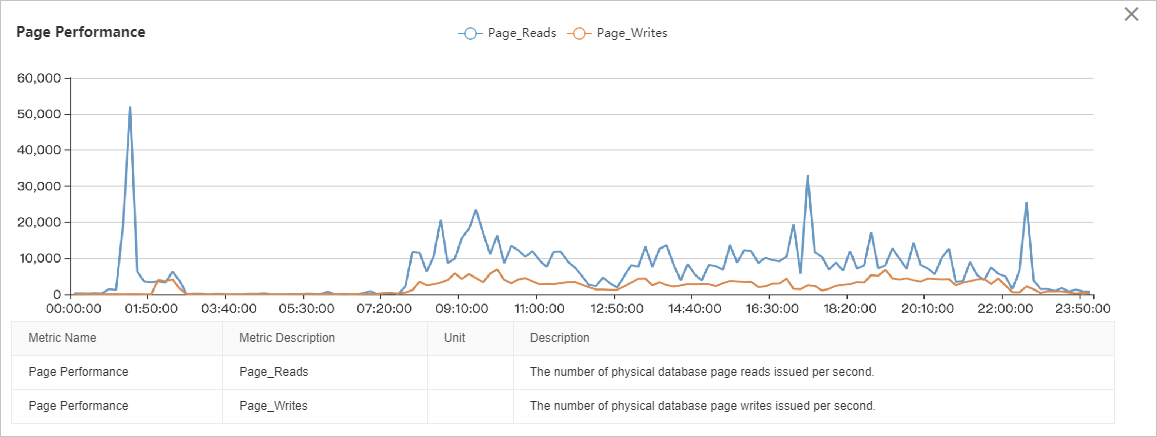
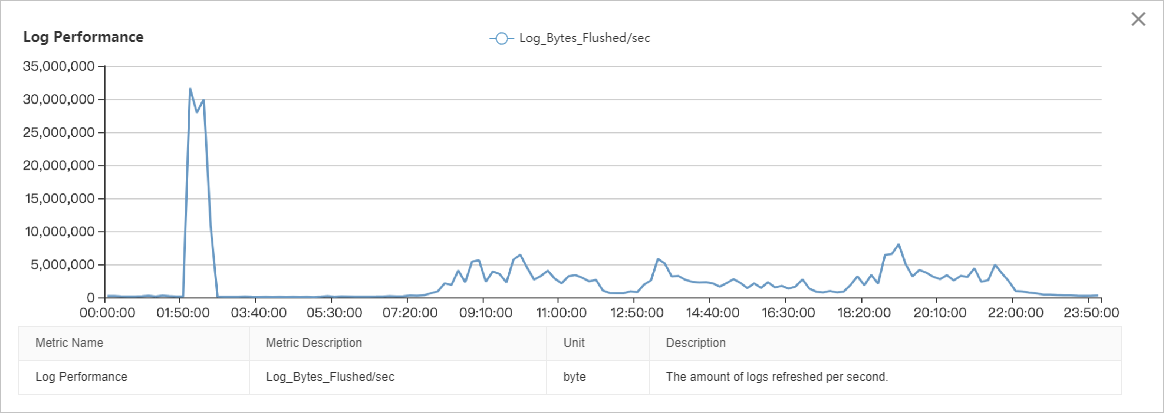
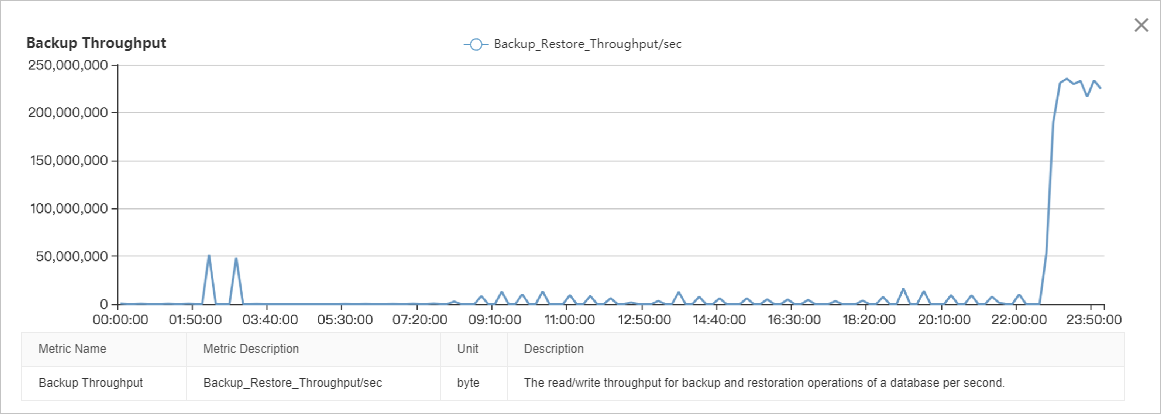
I/O スループットのグラフは、読み取り I/O が書き込み I/O よりも大幅に高いことを示しています。I/O 負荷は 08:00 から 22:00 までは比較的安定しており、01:00 から 03:00 までと 22:00 から 00:00 までの 2 つの明確なピークがあります。詳細な分析には、このデータを他のパフォーマンスメトリクスと関連付ける必要があります。
-
ページのパフォーマンスメトリクスによると、01:00 頃の I/O スループットの急上昇はデータページの読み取りによるもので、1 秒あたり約 50,000 ページでピークに達し、これは 400 MB/s に相当します。
-
ページ、ログ、およびバックアップのスループットメトリクスによると、02:00 から 03:00 までの I/O ピークは、データページの読み取り (ピーク時約 40 MB/s)、データページの書き込み (ピーク時約 40 MB/s)、ログファイルの書き込み (ピーク時約 30 MB/s)、およびログバックアップ (ピーク時約 50 MB/s) の組み合わせによるものです。累積 I/O スループットは、約 160 MB/s でピークに達します。
-
ページとログのパフォーマンスメトリクスによると、08:00 から 22:00 までの I/O スループットは、主にデータページの読み取り (約 80〜100 MB/s) で構成され、次にデータページの書き込み (約 30 MB/s)、ログファイルの書き込み (約 5 MB/s) が続きます。
-
バックアップスループットのメトリックによると、22:00 から 00:00 までの I/O ピークはすべてバックアップによるものであり、一貫して 220 MB/s を超えています。
データページの読み取りによる高い I/O スループット
データページの読み取り (Page Reads) による高い I/O スループットは、ApsaraDB RDS for SQL Server インスタンスで高い I/O が発生する最も一般的な原因の 1 つです。これは主に、バッファープール用のメモリが不足していることが原因です。クエリが必要なデータをキャッシュで見つけられない場合 (キャッシュミス)、システムはディスクから大量のデータページを読み取る必要があります。
キャッシュのパフォーマンスを診断するための主要なメトリックは、ページの予測寿命 (PLE) です。これは、データページがバッファープールにとどまる平均時間を秒単位で表します。PLE 値が低いほど、インスタンスのメモリ負荷が大きいことを示します。
一般的な経験則として、PLE 値を少なくとも 300 秒に維持することが推奨されます。メモリ容量の多いインスタンスでは、より高いしきい値を推奨します。次の式を使用できます。
推奨しきい値 = (バッファープールのサイズ (GB) / 4) × 300
たとえば、16 GB のメモリを搭載したインスタンスの場合、バッファープールで使用可能なメモリは 12 GB を超えません。推奨しきい値は次のとおりです:(12 / 4) * 300 = 900 (秒)
詳細については、「SQL Server のページの予測寿命 (PLE)」をご参照ください。
データページの読み取りによって高い I/O スループットが発生している場合は、ディスクのパフォーマンスレベル (PL) をアップグレードするのではなく、インスタンスの メモリ仕様をアップグレードすることを 推奨します。
データベースレベルでは、データページの総数を減らすことで、データページの読み取り負荷を軽減することもできます。たとえば、履歴データのアーカイブやクリーンアップ、テーブルデータ圧縮の有効化、価値の低いインデックスの削除、インデックスの断片化解消などです。
データページとログファイルの書き込みによる高い I/O スループット
データページとログファイルの書き込みによる高い I/O スループットが発生した場合は、Autonomy Services を使用して、スループットが高い期間に頻繁なデータ操作言語 (DML) 操作 (INSERT、 DELETE、 UPDATE、 MERGE など) またはデータ定義言語 (DDL) 操作 (CREATE INDEX、 ALTER INDEX など) がないか確認してください。次の解決策を検討してください。
-
DML 書き込み操作
まず、これらが通常のビジネスオペレーションであるかどうかを判断してください。そうでない場合、たとえば一時的なデータ処理やアーカイブのためである場合は、オフピーク時にこれらの操作を実行してください。これらが定常的なものである場合は、ディスクの パフォーマンスレベル (PL) をアップグレードする (例:ESSD PL1 から PL2 へ) ことを 推奨します。
インデックス構造を最適化し、不要な非クラスター化インデックスを削除することも推奨します。
-
DDL 書き込み操作
これらは通常、メンテナンスまたは一時的な操作です。オフピーク時にこれらの操作を実行してください。
さらに、インデックスを作成または再構築する際には、SQL ステートメントで MAXDOP オプションを使用して、並列処理の次数を制限してください。これにより、操作中のピーク I/O スループットは減少しますが、DDL 操作の総実行時間は増加します。
バックアップによる高い I/O スループット
現在、ApsaraDB RDS for SQL Server はプライマリインスタンスでのみデータバックアップをサポートしています。これにより、プライマリインスタンスのディスク I/O スループットが増加します。完全バックアップの影響が最も大きく、ログバックアップの影響は比較的小さくなります。
バックアップはデータのセキュリティと信頼性に不可欠であるため、ビジネスへの影響を最小限に抑えるために、 適切なバックアップスケジュールを設定することを推奨します。
インスタンスの 復元 ページでデータバックアップの期間を確認できます。この情報を使用して、ビジネスのピーク時間を避けるための適切なバックアップ時間を選択してください。
[Data Backup] タブをクリックし、テーブルの [Backup Start Time] 列と [Backup End Time] 列を使用してバックアップ期間を計算してください。
-
完全バックアップに約 6 時間かかり、ビジネスのピーク時間が 09:00 から 21:00、 バックグラウンドのデータ処理タスクが 22:00 から 01:00 に実行される場合、 バックアップ開始時間を 01:00 から 02:00 の間に設定できます。これにより、完全バックアップは 08:00 までに完了します。バックアップサイクルを毎日に設定することもでき、これにより復元操作の効率が向上します。
-
完全バックアップに約 15 時間かかり、 平日のいつでも実行するとビジネスに影響が出る場合は、バックアップサイクルを週末 (土曜日と日曜日) に設定することを検討してください。ただし、このアプローチでは、ポイントインタイムリカバリに必要な時間が増加する可能性があります。
バックアップ時間の調整で完全バックアップとビジネスオペレーションの競合を防げない場合は、ディスクのパフォーマンスレベル (PL) のアップグレードや、複数のインスタンスにデータを分割して単一インスタンスのデータ量を削減することを検討してください。これにより、完全バックアップに必要な時間が短縮されます。