パフォーマンスメトリックの表示は、データベースのメンテナンスとトラブルシューティングに不可欠です。 RDS for MySQL の標準モニタリング機能は、幅広いパフォーマンスメトリックと強力な診断機能を提供し、異常を検出してソリューションを提供します。
特徴
アップグレードされた RDS for MySQL の標準モニタリング 機能は、パフォーマンストレンドを統合し、より多くの機能を提供します。
カスタムビュー: 標準モニタリング機能は、幅広いパフォーマンスメトリックを提供し、カスタムビューをサポートします。 監視するメトリックを選択できます。
説明各メトリックのパフォーマンスパラメーターの詳細については、「パフォーマンスパラメーター表」をご参照ください。
一般的な問題の診断ビュー: サービスは、問題を迅速に特定するために使用できるいくつかの診断ビューを提供します。 これらのビューには、[メモリ OOM 診断]、[読み取り専用インスタンスの遅延診断]、[フルストレージ診断]、[CPU ジッター診断]、[ラージトランザクション認識診断] が含まれます。
自動診断: 標準モニタリング機能は、データベースインスタンスのイベントを検出し、自動診断を実行し、根本原因分析と提案を提供できます。
手動診断: 時間範囲を選択して手動診断を実行できます。
標準モニタリングデータの表示
ApsaraDB RDS コンソールにログインし、[インスタンス] ページに移動します。 上部のナビゲーションバーで、RDS インスタンスが存在するリージョンを選択します。 次に、RDS インスタンスを見つけて、インスタンス ID をクリックします。
左側のナビゲーションウィンドウで、モニターとアラーム をクリックします。
標準モニタリング ページで、[標準ビュー] または [カスタムビュー] を選択します。
標準ビュー
[標準ビュー] タブで、時間範囲を選択して、選択した期間の [パフォーマンスイベント] と [パフォーマンスメトリック] を表示できます。
説明時間範囲を選択する場合、開始時刻と終了時刻の間隔は 7 日を超えることはできません。 過去 30 日間のデータを表示できます。
パフォーマンスイベントを表示する
イベント統計エリアでは、選択した時間範囲内のさまざまなタイプのイベントの統計情報を表示できます。 [詳細の表示] をクリックして、パフォーマンスイベントの表示 ページを開きます。ここでは、スケジュール済み、進行中、または完了済みのイベントを含む、異常なインスタンスアクティビティと最適化イベントに関する詳細情報を表示できます。
パフォーマンスメトリックを表示する
メトリックを表示する
デフォルトの [クラシックビュー] では、選択した時間範囲のモニタリングメトリックを表示できます。
[その他のメトリック] をクリックして、メトリックを選択し、そのパフォーマンストレンドを表示します。
各メトリックの後の
 をクリックして、含まれているメトリックを表示できます。
をクリックして、含まれているメトリックを表示できます。
メトリックトレンドグラフの [詳細] をクリックして、ズームインし、時間範囲を調整します。
[トレンド比較を追加] をクリックして、異なる期間にわたる同じメトリックのパフォーマンストレンドを比較します。

イベント分析を表示する
デフォルトの [クラシックビュー] で、イベントレベルを選択すると、[MySQL CPU/メモリ使用率] および [セッション接続] トレンドチャートに対応するイベントが表示されます。
トレンドチャートのイベントをクリックして、イベントの詳細の診断結果を表示できます。
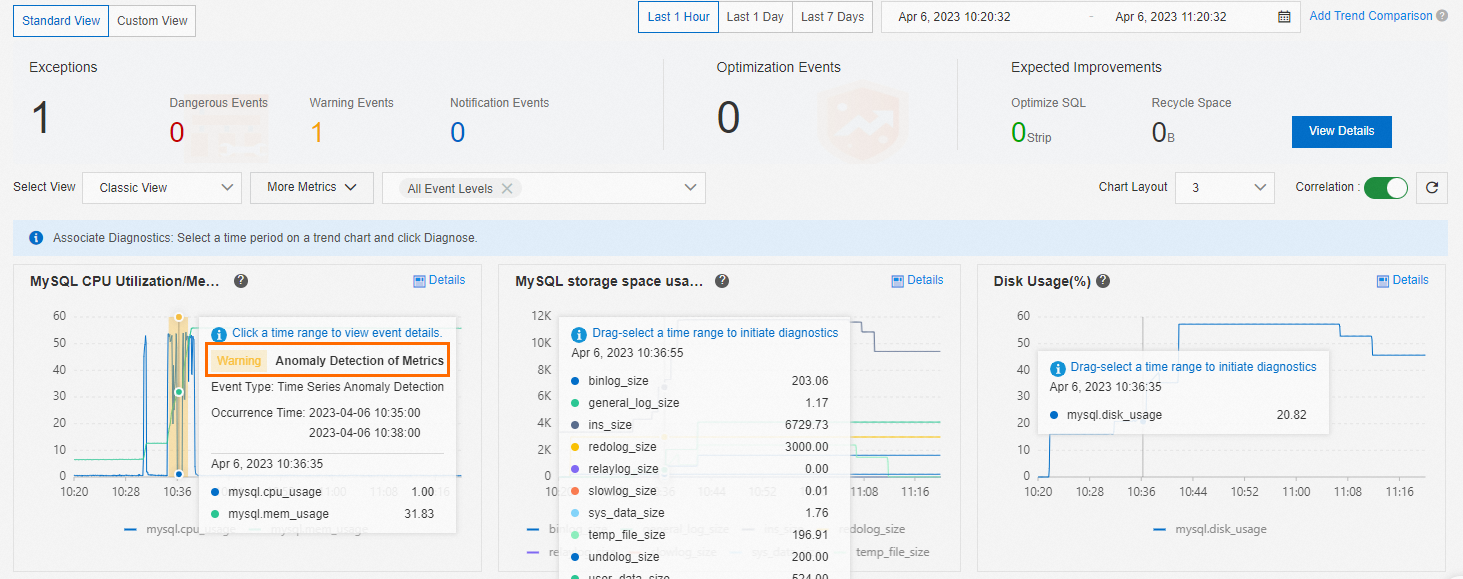
メトリックの診断と分析
任意のメトリックトレンドチャートで、マウスをドラッグして時間範囲を選択し、[診断] できます。
一般的な問題の診断ビューを表示する
次の診断ビューを使用して、問題の根本原因を迅速に特定できます: [メモリ OOM 診断]、[読み取り専用インスタンスの遅延診断]、[フルディスク容量診断]、[CPU ジッター診断]、[ラージトランザクション認識診断]。 詳細については、「診断ビューの使用」をご参照ください。
カスタムビュー
[カスタムビュー] タブで、[モニタリングダッシュボードを追加] をクリックして、監視するメトリックのトレンドを表示します。 各メトリックのパフォーマンスパラメーターの詳細については、「パフォーマンスパラメーター表」をご参照ください。
[ノードとメトリックのモニタリングを追加] をクリックして、ダッシュボードに追加するノードとメトリックを選択します。
メトリックの表示方法を選択できます: [マージ表示] または [個別表示]。
[マージビュー]: 複数のメトリックを 1 つのトレンドチャートに表示します。
[個別表示]: 各メトリックを個別のトレンドグラフに表示します。
[チャートレイアウト] を使用して、1 行に表示するメトリックトレンドチャートの数を設定できます。
メトリックトレンドグラフの [詳細] をクリックして、ズームインし、時間範囲を調整します。
標準モニタリング ページで、右上隅にある 旧バージョンに戻る ボタンをクリックして、以前のモニタリングバージョンに戻します。
診断ビューの使用
メモリ OOM 診断
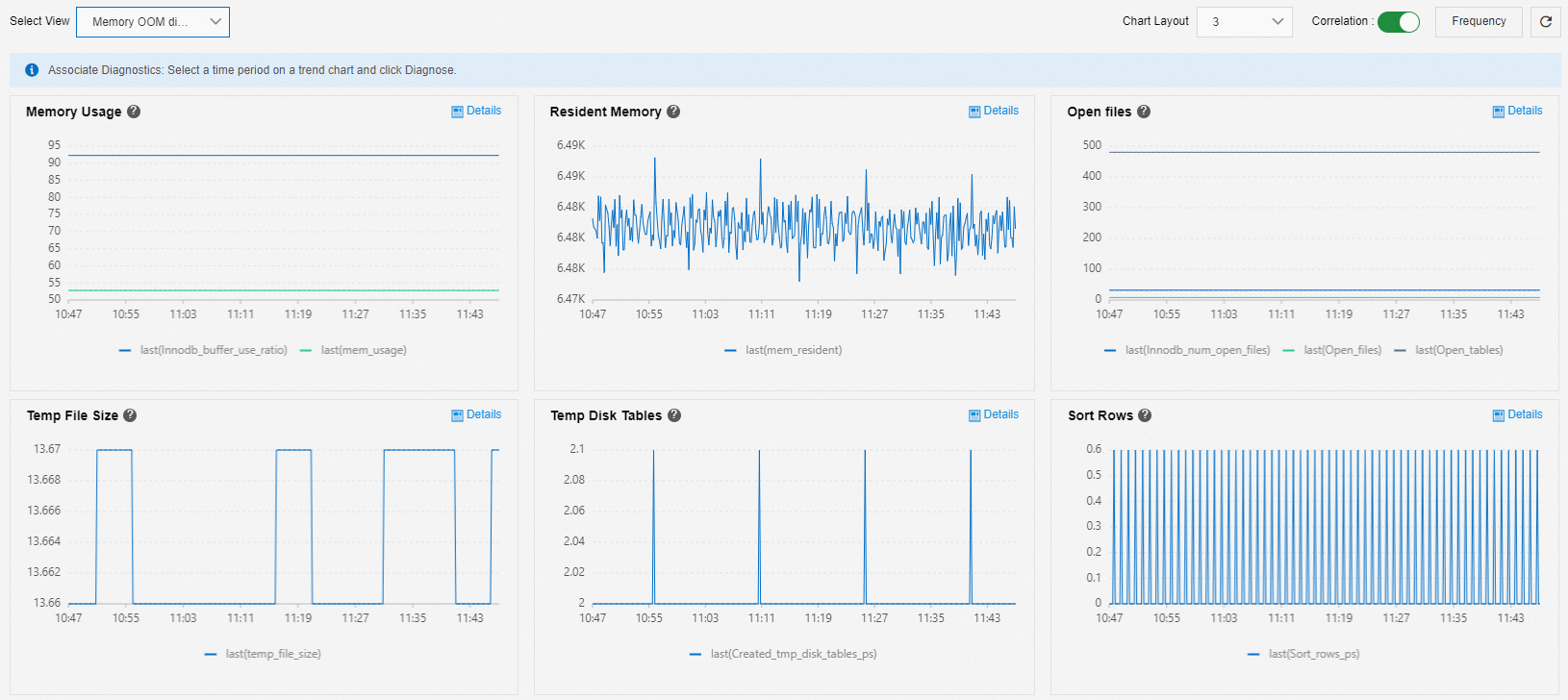
[メモリ OOM 診断] ビューを使用して、メモリ不足 (OOM) の問題を分析できます。
[メモリ使用量]:
InnoDB バッファプールの使用量が変わらず、メモリ使用量が 7 日以上など長期間にわたってゆっくりと継続的に増加する場合、メモリリークが発生している可能性があります。
InnoDB バッファプールの使用量が変わらず、メモリ使用量が急激に増加する場合、トラフィックの急増が原因である可能性があります。
メモリと InnoDB バッファプールの使用量が両方とも増加する場合、InnoDB バッファプールが徐々にいっぱいになっていることを示しており、これは正常です。
[常駐メモリ]: 使用されている物理メモリの量。
[開いているファイル]、[一時ファイルサイズ]、[一時ディスクテーブル]、[ソート行] は、メモリ消費量を示す一般的なメトリックです。
メモリの増加は、ビジネスメトリックに関連しています。 メモリの急増を引き起こす SQL 文は、OOM のため、多くの場合追跡できません。 したがって、次のことをお勧めします。
ビジネスログをチェックして、メモリが急激に増加した原因を特定します。
メモリスペックをアップグレードし、SQL Explorer と監査を有効にします。 メモリが急激に増加した場合、SQL クエリの実行時間をチェックして原因を特定できます。
読み取り専用インスタンスのレイテンシ診断
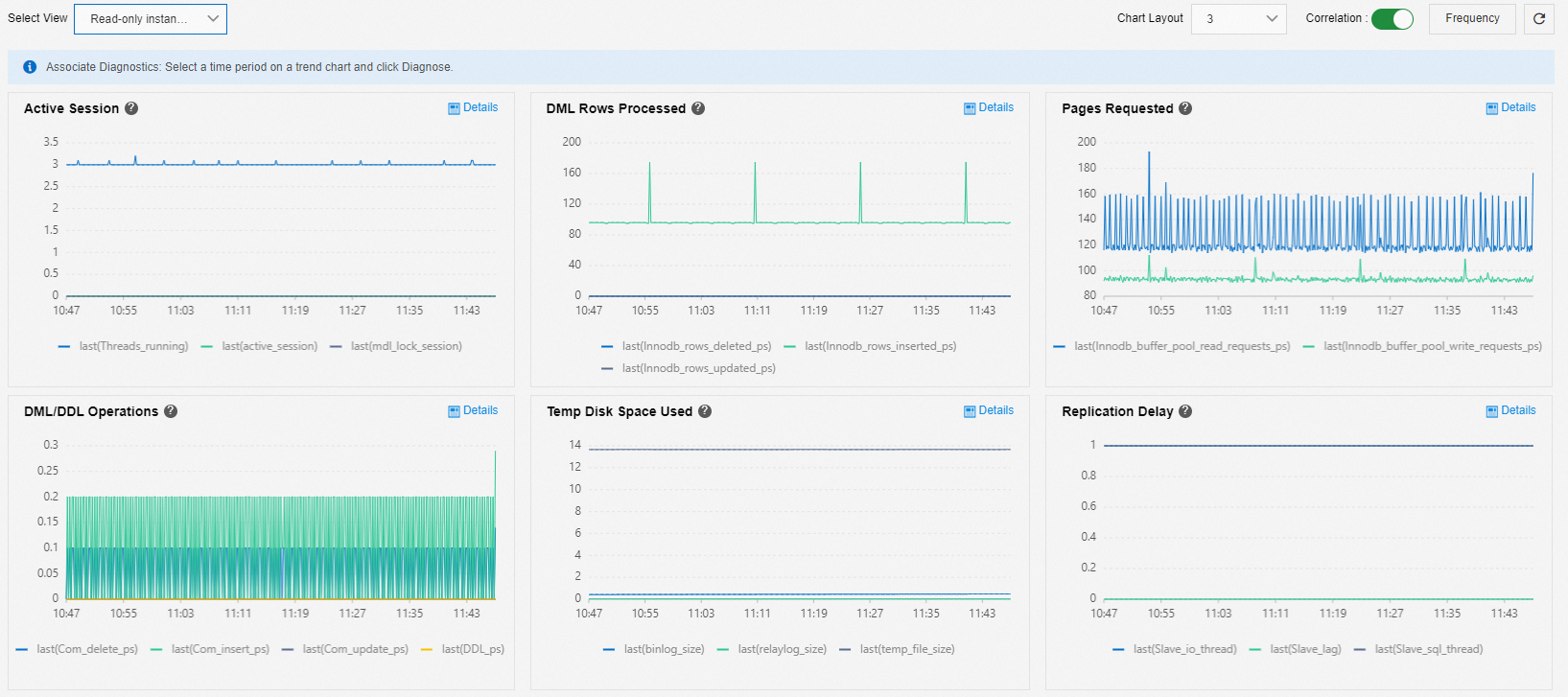
[読み取り専用インスタンスの遅延診断] ビューを使用して、読み取り専用インスタンスの遅延を診断できます。
[アクティブセッション]: メタデータロックからのブロッキングを確認します。
通常、大量のデータに対するクエリは、DDL 文がメタデータロックを取得するのを妨げます。 この場合、DDL 文は他のセッションをブロックし、接続が蓄積されます。
[処理された DML 行]、[リクエストされたページ]、[DML/DDL 操作]、[使用済み一時ディスク容量]: 一般的なビジネスメトリックを表示します。
[レプリケーションの遅延]: レイテンシメトリック。
フルストレージ容量診断
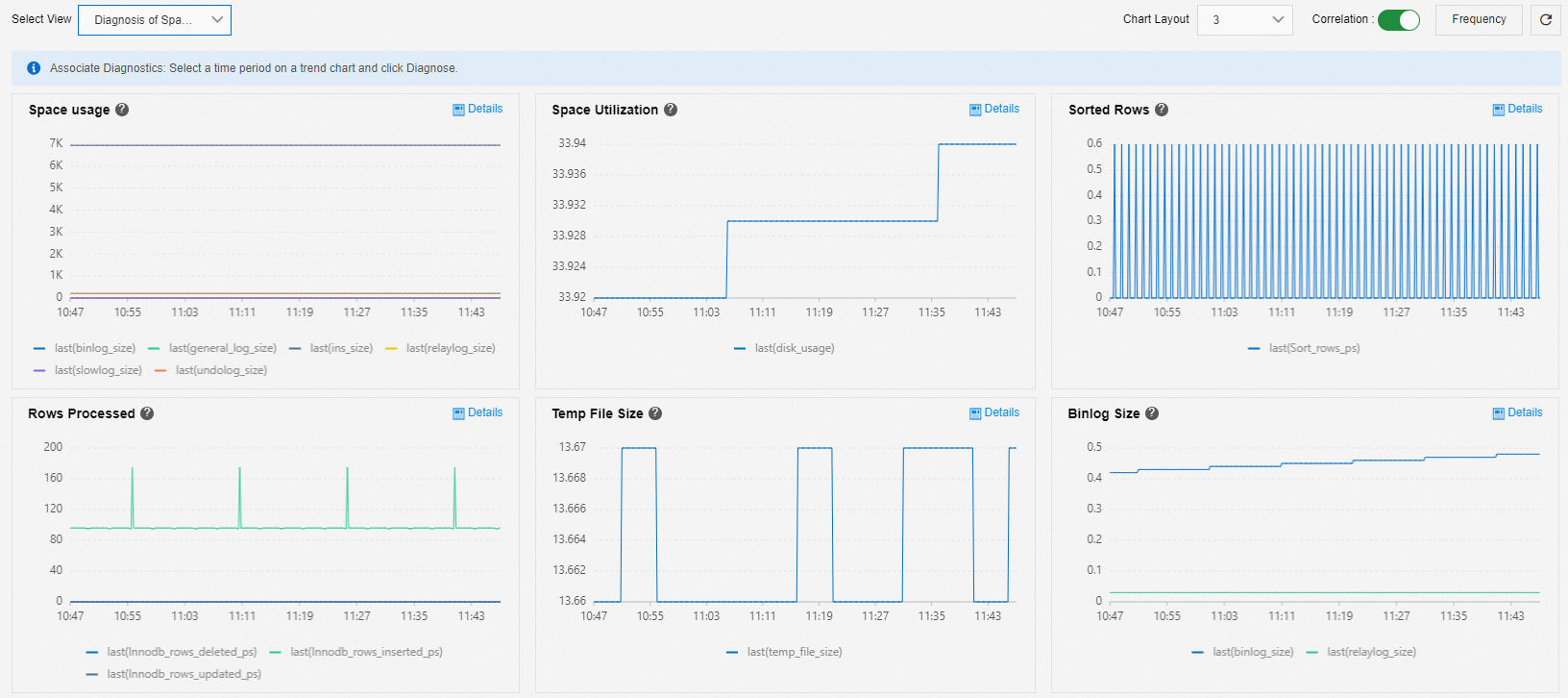
[容量不足問題の診断] ビューを使用して、容量不足の問題を分析できます。
インスタンスのストレージ容量を占有しているファイルの種類とその変化の傾向を表示できます。 次のメトリックは、一般的にストレージの使用量に関連付けられています。
データファイル (user_data_size): 容量分析を使用して、各データベースとテーブルの容量使用量を表示し、スケールアウトまたは不要なデータを削除できます。 詳細については、「データファイルが原因でインスタンスがいっぱいになった場合のソリューション」をご参照ください。
一時ファイル (temp_file_size): データをソートおよびグループ化したり、テーブルを関連付けたりするために SQL 文を実行すると、一時テーブルが生成される場合があります。 バイナリログキャッシュファイルは、ラージトランザクションがコミットされる前に生成されます。 これらのテーブルとファイルはストレージ容量を占有します。 詳細については、「一時ファイルが原因でインスタンスストレージがいっぱいになった場合の解決」をご参照ください。
バイナリログ (binlog_size): ラージトランザクションは、バイナリログを迅速に生成する可能性があります。 これらのログはストレージ容量を占有します。 バイナリログの管理方法の詳細については、「MySQL バイナリログファイルが原因でインスタンスストレージがいっぱいになった場合の解決」をご参照ください。
説明サービスがデータベースのバイナリログをサブスクライブしている場合、ログがすぐにクリアされない可能性があり、容量を占有する可能性があります。
UNDO ログ (undo_log_size): ほとんどの場合、長時間実行されるクエリは、UNDO ログがクリアされるのを妨げます。 完了していない長時間実行されるクエリを確認できます。
説明MySQL 5.6 以前では、UNDO ログには個別の表領域がありません。
スローログ (slowlog_size): スローログの容量が大きすぎる場合は、
truncateコマンドを使用して、オフピーク時にクリアできます。説明truncateコマンドのサポートは、MySQL 5.7 のバージョン 20210630 と MySQL 8.0 のバージョン 20210930 で追加されました。一般ログ (general_log_size): インスタンスのエラー、パフォーマンスエージェント、およびリカバリログの合計サイズ。通常は安定しており、1 GB 未満です。 サイズがこの値を大幅に超える場合は、 チケットを送信 して、プロダクトチームに連絡してください。 このメトリックは、MySQL カーネルによって定期的に生成されるデータを表し、MySQL の general_log ファイルのサイズではありません。
CPU ジッター診断
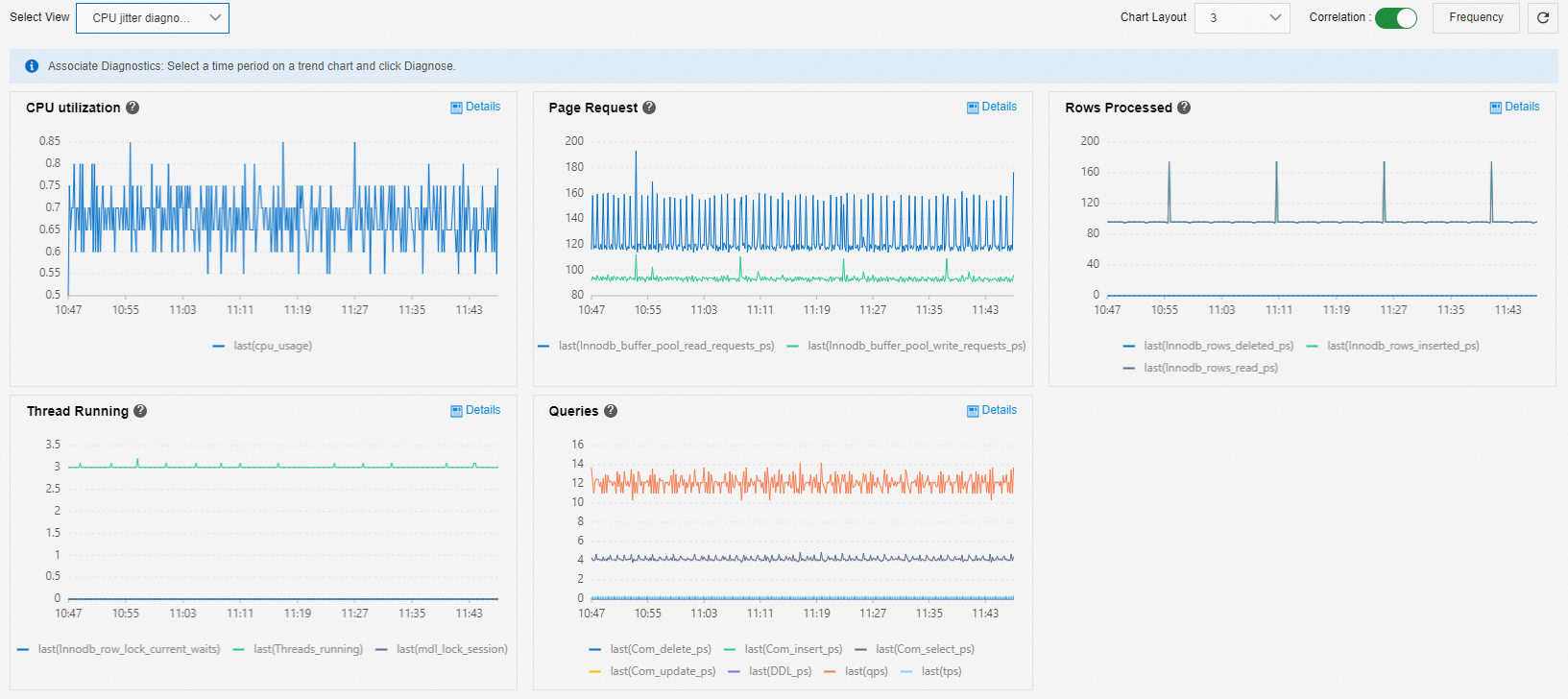
[CPU ジッター診断] ビューを使用して、CPU ジッターの問題を分析できます。 関連するメトリックは次のとおりです。
ビジネスメトリック:
[ページリクエスト]: 通常、バッファプールリクエストは CPU 使用率と同期して変動します。
[処理された行]: CPU 使用率と処理された行数の関係を調べて、行数の急増が CPU 使用率の変化に対応しているかどうかを判断します。
[クエリ]: CPU 使用率が変化したときに実行される SQL 文の主なタイプを表示します。
接続:
[スレッド実行中]: 高い同時実行性は、高い CPU 使用率を引き起こす可能性があります。 MDL スタッキングまたは行ロックも接続の蓄積を引き起こし、CPU 使用率を増加させる可能性があります。
CPU ジッターの一般的な原因:
[ページリクエスト] や [処理された行] などのビジネスメトリックの変化は、CPU 使用率に影響を与える可能性があります。 この場合、CPU 使用率の変化の時間範囲を選択し、[診断] を実行して、根本原因の詳細な分析を取得できます。
アクティブな接続の増加は CPU 消費を引き起こします。 この場合、ビジネス側から問題を調査する必要があります。
ラージトランザクション診断
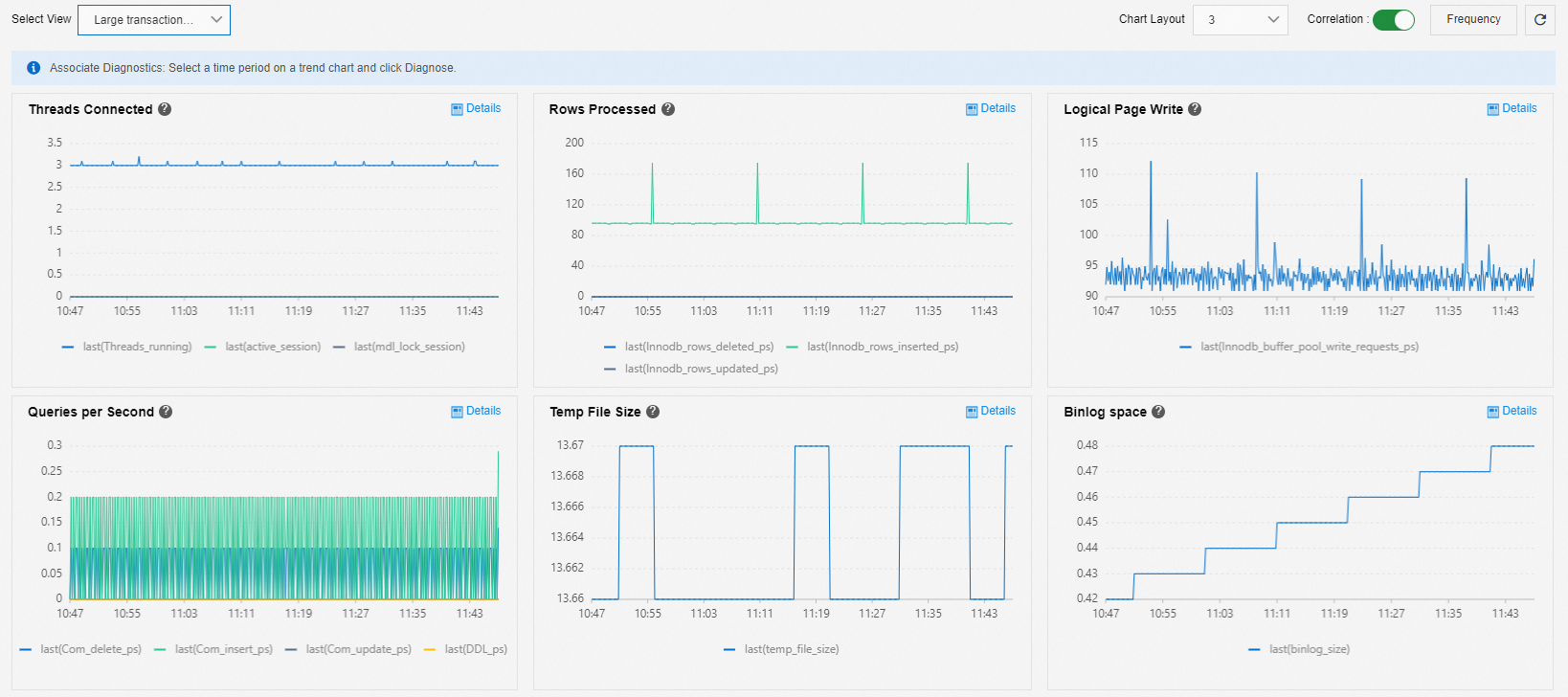
[ラージトランザクション認識診断] ビューを使用して、ラージトランザクションの問題を分析できます。
[接続されたスレッド]、[一時ファイルサイズ]、[Binlog 容量]: これらは、ラージトランザクションを示す 3 つの主要なメトリックです。 次のイベントのいずれかが発生した場合、データベースにラージトランザクションが存在します。
アクティブなセッションが蓄積される。
一時容量が最初に増加し、次に減少する。
一時容量が減少した後、Binlog 容量が増加する。
[処理された行]、[論理ページ書き込み]、[1 秒あたりのクエリ数]: これらのメトリックは、ラージトランザクションのタイプを判断するために使用されます。
たとえば、クエリは少ないが、多くの行が削除されている場合、データを削除するラージトランザクションを示します。
ラージトランザクションは、バイナリログの書き込みをブロックする可能性があります。
インスタンスにラージトランザクションがある場合、一時表領域 (binlog キャッシュ) は最初に徐々に増加し、次に安定します。
一時表領域が安定すると、Binlog 容量が増加します。 バイナリログの書き込みはグローバルにシリアルであるため、他のトランザクションがブロックされ、接続が蓄積されます。
インスタンスが RDS High-availability Edition を実行している場合、プライマリインスタンスとセカンダリインスタンスの高可用性 (HA) コンポーネントからのプローブステートメントもブロックされ、プライマリ/セカンダリのフェールオーバーが発生します。
ラージトランザクションを小さなトランザクションに分割して、個別に実行することをお勧めします。 たとえば、delete 文では、where 句を追加して、各操作で削除されるデータの量を制限し、1 つの削除操作を複数の小さな削除操作に分割します。
関連情報
一般的なパフォーマンスの問題:
自律型サービスを使用して、データベースのパフォーマンスの最適化と診断を実行できます。 詳細については、「パフォーマンスの最適化と診断」をご参照ください。
関連 API
API | 説明 |
RDS インスタンスのパフォーマンスデータをクエリします。 |
付録: レガシーモニタリング
レガシーモニタリングのメトリックの概要
レガシーモニタリングデータの表示
ApsaraDB RDS コンソールにログインし、[インスタンス] ページに移動します。 上部のナビゲーションバーで、RDS インスタンスが存在するリージョンを選択します。 次に、RDS インスタンスを見つけて、インスタンス ID をクリックします。
左側のナビゲーションウィンドウで、モニターとアラーム をクリックします。
標準モニタリング タブで、旧バージョンに戻る をクリックします。

レガシーモニタリングページで、[リソース監視]、[エンジンモニタリング]、または [デプロイメントモニタリング] と時間範囲を選択して、モニタリングデータを表示します。 Cluster Edition インスタンスの場合、インスタンスまたはノード ID を選択することもできます。 過去 30 日間のみのモニタリングデータをクエリできます。