このトピックでは、ApsaraDB RDSのX-EngineがDingTalkのコストを削減し、オンラインコラボレーションを実装する方法について説明します。
背景情報
DingTalkは、中国の主要なエンタープライズグレードのインスタントメッセージング (IM) ツールとして、中国全土の何億ものユーザーにサービスを提供しています。 DingTalkの基本機能には、プロジェクト固有のチャットグループ、ビデオ会議、日報などがあります。 DingTalk Open Platformは、同僚間のコミュニケーションを容易にするためのさまざまなオフィスオートメーション (OA) アプリケーションも提供します。
2020では、COVID-19は深刻な問題です。 集中オフィスでの仕事によって引き起こされる感染のリスクを減らすために、多くの従業員が自宅で仕事をすることを選択しました。 コラボレーションツールの需要が急増しています。 このような状況では、DingTalkはすぐにApp Storeのダウンロードリストの一番上に上がり、トラフィックが急激に増加します。 DingTalkは、Alibaba Cloudの柔軟なインフラストラクチャに基づいて開発されています。 これにより、すべてのトラフィックスパイクがスムーズに処理されます。
多数のユーザーにサービスを提供するために、DingTalkはメッセージの送受信の正確さと適時性を保証し、読み取りレシートなどの特定の機能を提供する必要があります。 WeChatなどの個人向けのIMツールとは異なり、エンタープライズグレードのIMツールは、チャット履歴の永続的な保存をサポートし、複数端末のローミング機能を提供する必要があります。 この機能により、複数の端末からメッセージを受信できます。 ユーザーの数が急激に増加するにつれて、DingTalkは、チャット履歴の永続的な保存によって発生するコストの課題と、チャット履歴に対する読み取りおよび書き込み操作のパフォーマンスを保証するための課題に直面しています。
これらの課題に対処するために、DingTalkはメッセージのストレージエンジンとしてX-Engineを使用しています。 これにより、コストとパフォーマンスのバランスが取れます。 X-Engineには次の利点があります。
- X-Engineが必要とするストレージは、InnoDBストレージエンジンが必要とするストレージよりも約62% 少ない。
- トランザクションやセカンダリインデックスなどの一部のデータベース機能がサポートされています。
- X-Engineを搭載したApsaraDB RDSインスタンスに変更なしでコードを移行できます。
- X-Engineは、ホットデータとコールドデータを分離して、現在のメッセージの処理を高速化します。 X-Engineは、履歴メッセージに対して最も効率的な圧縮アルゴリズムも実装しています。
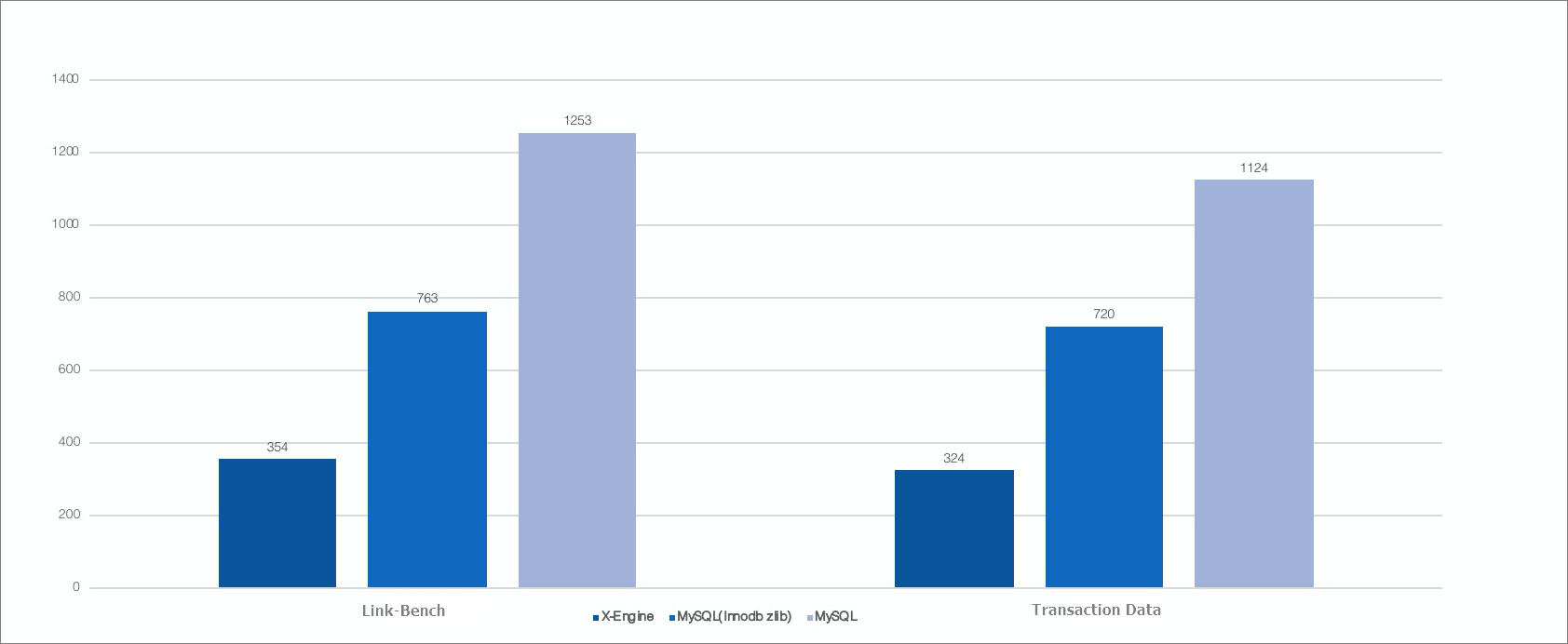
X-Engineストレージ効率は、Link-BenchとAlibaba内部トランザクションビジネスの2つのデータセットでテストされます。 テストでは、X-Engineは、圧縮が有効なInnoDBストレージエンジンよりも2倍少ないストレージを必要とし、圧縮が無効なInnoDBストレージエンジンよりも3〜5倍少ないストレージを必要とします。
Xエンジンによって達成される低コスト
Xエンジンは低コストを保障するために次の技術を採用します:
- コンパクトページ
X-Engineは、コピーオンライト技術を使用して、元のページを更新せずに新しいページに新しいデータを書き込みます。 新しいページは読み取り専用であり、更新できません。 これらのページはコンパクトに格納され、データはプレフィックス符号化などのアルゴリズムを使用して圧縮されます。 これにより、ストレージ効率が向上する。 コンパクション操作を使用して、無効なレコードを消去できます。 これにより、有効なレコードのコンパクトな配置が保証される。 X-Engineは、InnoDBなどの従来のストレージエンジンと比較して、10% から50% のストレージしか必要としません。
- 無効なレコードのデータ圧縮とクリーニング
エンコード後のページは、zlib、zstd、snappyなどの一般的な圧縮アルゴリズムを使用して圧縮できます。 ログ構造化マージツリー (LSMツリー) の低レベルのデータは、デフォルトで圧縮されます。
データ圧縮はストレージのコンピューティングリソースを犠牲にします。 圧縮率が低く、圧縮と解凍の速度が高い圧縮アルゴリズムを選択することをお勧めします。 多数の比較テストの後、X-Engineはzstdをデフォルトの圧縮アルゴリズムとして選択し、他の圧縮アルゴリズムをさらにサポートします。
さらに、無効なレコードを削除するためにコンパクション操作が導入されます。 このようにして、有効なレコードのみが保持される。 コンパクション操作が頻繁に実行されるほど、無効なレコードの割合が低くなり、ストレージ効率が高くなります。 したがって、適切な頻度でコンパクション操作を実行する必要があります。
X-Engineチームは、フィールドプログラマブルゲートアレイ (FPGA) コンパクション技術も開発して、コンパクション操作のコンピューティングリソース消費を削減します。 このテクノロジーは、異種コンピューティングハードウェアを使用して、圧縮プロセスを加速します。 FPGAテクノロジーは、FPGAハードウェアを使用してコンパクションおよび圧縮操作を合理化します。 FPGAハードウェアのないホストでは、X-Engineは適切なスケジューリングアルゴリズムを使用して、ストレージを低パフォーマンスコストで節約できます。
- ホットデータとコールドデータのインテリジェントな分離
ストレージシステムへの通常のアクセスでは、ほとんどのアクセス要求はデータの小さな部分に向けられる。 これがキャッシュが機能する理由です。 LSMツリー構造では、頻繁にアクセスされるデータは、不揮発性メモリ (NVM) およびダイナミックランダムアクセスメモリ (DRAM) などの高速記憶装置にハイレベルで記憶される。 頻繁にアクセスされないデータは、低速の記憶装置に低レベルで記憶される。 これは、X-Engineのホットデータとコールドデータの分離です。
分離アルゴリズムは、次のタスクを完了します。
- コンパクション操作では、アクセスされる可能性が最も低いページおよびレコードが選択され、LSMツリーの最下部に移動される。
- 現在のホットデータが選択され、コンパクションまたはダンププロセスでBlockCacheやRowCacheなどのメモリにバックフィルされます。 これにより、キャッシュヒット率のジッターによるパフォーマンスの低下を防ぎます。
- AIアルゴリズムは、将来アクセスされる可能性のあるデータを認識し、それをメモリに事前に読み込みます。 これは、最初にキャッシュにアクセスするためのヒット率を増加させる。
無効な圧縮または解凍によるコンピューティングリソースの浪費を回避するために、ホットデータおよびコールドデータが正確に識別される。 これにより、システムスループットが向上する。
詳細については、「X-Engineの概要」をご参照ください。