ApsaraDB RDS for MySQL の DuckDB 分析読み取り専用インスタンスは、列のストアとベクトル化を使用して、複雑な分析クエリのパフォーマンスを最大 100 倍向上させます。これらのインスタンスは、大規模なデータシナリオに対してリアルタイム分析を提供し、データ駆動型の意思決定を迅速に行うのに役立ちます。
製品紹介
DuckDB 分析読み取り専用インスタンスには、次の特徴を持つ DuckDB エンジンが組み込まれています。
高性能分析: 列のストア、ジャストインタイム (JIT) コンパイル、ベクトル化、効率的なメモリ管理、並列処理などの特徴をサポートします。
MySQL との高い互換性: MySQL の構文とデータ形式との高い互換性があります。元のクエリ文を変更することなく、効率的に結果を取得できます。
データ同期メカニズム:
既存データ同期: DuckDB 分析読み取り専用インスタンスを作成すると、システムはプライマリインスタンスから既存データを同期し、自動的に DuckDB エンジン形式に変換します。
増分データ同期: DuckDB 分析読み取り専用インスタンスが作成された後、プライマリインスタンスからの増分データは、ネイティブの MySQL バイナリログ (binlog) レプリケーションメカニズムを使用して、リアルタイムで分析読み取り専用インスタンスに同期されます。データは常に RDS 内で転送され、外部のデータ同期ツールは必要ありません。この技術の詳細については、「DuckDB 分析インスタンスの技術原理」をご参照ください。
シナリオ
集約分析: ログデータ分析などの集約分析のために、DuckDB 分析読み取り専用インスタンスは効率的な集約クエリを提供します。
複数テーブル結合クエリ: 複数テーブルの
JOINを含むワークロードに対して、MySQL の分析パフォーマンスを大幅に向上させます。
DuckDB 分析読み取り専用インスタンス、読み取り専用インスタンス、OLAP データベースの比較
複雑なクエリにプライマリインスタンス、読み取り専用インスタンス、または OLAP データベースを使用する場合と比較して、DuckDB 分析読み取り専用インスタンスには次の利点があります。
高性能: InnoDB エンジンと比較して、複雑なクエリに対して 2 桁優れたパフォーマンスを提供します。
高い互換性: MySQL プロトコルとデータの型と 100% 互換性があり、SQL 構文とデータ定義言語 (DDL) とも高い互換性があります。
効率的で安定したデータ同期: ネイティブの binlog レプリケーションチャネルを使用し、より安定した効率的な同期リンクを実現します。追加のデータ同期料金は発生しません。
リソースの隔離: DuckDB 分析読み取り専用インスタンスは複雑な分析クエリを処理し、プライマリインスタンスと通常の読み取り専用インスタンスはトランザクション処理を処理します。これにより、各ワークロードのリソースが隔離され、互いに影響し合うのを防ぎます。
項目 | DuckDB 分析読み取り専用インスタンス | 読み取り専用インスタンス | OLAP データベース | |
適したサービス | 複雑な分析クエリ | トランザクション処理 | 複雑な分析クエリ | |
分析クエリパフォーマンス | 強力 | 低 | 強力 | |
データ同期方法 | ネイティブ binlog レプリケーション | ネイティブ binlog レプリケーション | DTS データ同期リンク | |
MySQL 互換性 | データの型 | 完全互換 | 完全互換 | 非互換 (フィールドマッピングが必要) |
SQL 構文 | 高い互換性 (99.9% 以上) | 完全互換 | 非互換 (SQL の再書き込みが必要) | |
DDL | 高い互換性 | 完全互換 | 部分的に互換 | |
O&M コスト | 低 (統合インスタンス) | 低 (統合インスタンス) | 高 (データベースと同期リンクの追加メンテナンスが必要) | |
シナリオ
DuckDB 分析読み取り専用インスタンスを作成するには、アタッチされている ApsaraDB RDS for MySQL プライマリインスタンスが次の要件を満たしている必要があります。
メジャーバージョン: MySQL 8.0
シリーズ: 高可用性シリーズ
ストレージタイプ: プレミアム ESSD またはエンタープライズ SSD (ESSD)
ストレージ容量: 10 GB から 16,000 GB
データアーカイブ機能が無効になっていること。
課金
DuckDB 分析読み取り専用インスタンスの課金は、通常の読み取り専用インスタンスと同じです。コストは、製品シリーズ、インスタンスタイプ、ストレージタイプ、ストレージ容量などの要因に影響されます。実際のコストは購入ページに表示されます。
注意事項
インスタンス作成時間: DuckDB 分析読み取り専用インスタンスを作成する際、インスタンス内のすべてのテーブルのエンジンが自動的に DuckDB エンジンに変換されます。そのため、分析読み取り専用インスタンスの作成には、通常の読み取り専用インスタンスよりも時間がかかります。作成時間はプライマリインスタンスのデータ量に依存します。
外部キーの削除: DuckDB 分析読み取り専用インスタンスの作成中に外部キーは自動的に削除されます。DuckDB 分析読み取り専用インスタンスには外部キー制約はありません。
テーブルスキーマの制限: DuckDB 分析読み取り専用インスタンスは、
UTF8またはUTF8MB4文字セットを使用するテーブルのみをサポートします。パーティション分割テーブルや、ビジネスプライマリキーのないテーブルはサポートされていません。ビジネスプライマリキーとは、定義されたプライマリキー、または非 null フィールドに対する UNIQUE 制約のことです。説明サポートされていないテーブルの場合、DuckDB 分析読み取り専用インスタンス内ではエンジンは InnoDB エンジンのままです。次の SQL 文を実行して、互換性のないテーブルのリストをクエリできます。
SELECT table_schema, table_name, engine FROM information_schema.tables WHERE table_schema NOT IN ('mysql', 'sys') AND engine = 'InnoDB';Binlog サブスクリプションの制限: DuckDB 分析読み取り専用インスタンスは、バイナリログ機能の有効化をサポートしていません。そのため、その binlog をサブスクライブすることはできません。binlog をサブスクライブするには、プライマリインスタンスを選択してください。
互換性の制限: 詳細については、「DuckDB 分析インスタンスの互換性」をご参照ください。
DuckDB 分析読み取り専用インスタンスの作成
ApsaraDB RDS コンソールにログインします。上部のナビゲーションバーでリージョンを選択します。次に、ターゲットインスタンスの ID をクリックします。
[基本情報] ページで、[インスタンス分布] セクションに移動します。[DuckDB 分析インスタンス] の右側にある [追加] をクリックします。
DuckDB 分析読み取り専用インスタンスを構成します。次の表に、主要なパラメーターを示します。
パラメーター
説明
[課金方法]
サブスクリプションと従量課金がサポートされています。サーバーレスはサポートされていません。
シリーズ
高可用性シリーズのみがサポートされています。
プロダクトタイプ
Standard Edition のみがサポートされています。
プライマリゾーン
プライマリインスタンスと同じリージョン内のゾーンのみを選択できます。
デプロイメント方法
単一ゾーンデプロイメント: 分析読み取り専用インスタンスのプライマリノードとセカンダリノードは同じゾーンにあります。
複数ゾーンデプロイメント: 分析読み取り専用インスタンスのプライマリノードとセカンダリノードは、同じリージョン内の異なるゾーンにあります。これにより、追加料金なしでクロスゾーンのディザスタリカバリが提供されます。このオプションを選択した場合は、セカンダリノードのゾーンも構成する必要があります。
[インスタンスタイプ]
専用インスタンスタイプがサポートされています。インスタンスタイプの詳細については、「DuckDB 分析読み取り専用インスタンスタイプ」をご参照ください。
データベースプロキシ
汎用データベースプロキシ (無料) を有効にすると、システムはハイブリッドトランザクション/分析処理 (HTAP) リクエストを自動的に分散できます。オンライン分析処理 (OLAP) クエリリクエストは DuckDB 分析読み取り専用インスタンスにルーティングされ、オンライン取引処理 (OLTP) リクエストはプライマリインスタンスまたは通常の読み取り専用インスタンスにルーティングされます。
ストレージ容量
分析読み取り専用インスタンスのストレージ容量は、プライマリインスタンスのストレージ容量の少なくとも半分である必要があります。
[次へ: インスタンス構成] をクリックします。インスタンスのネットワークとリソースグループを構成します。次の表に、主要なパラメーターを示します。
パラメーター
説明
[VPC]
VPC はデフォルトでプライマリインスタンスと同じであり、変更できません。
プライマリノードの VSwitch
デフォルトのプライマリ vSwitch を使用するか、必要に応じて選択します。
[リソースグループ]
リソースグループはデフォルトでプライマリインスタンスと同じであり、変更できません。
[次へ: 注文の確認] をクリックします。
[パラメーター設定] を確認し、[数量] を選択し、[注文の確認] をクリックして支払いを完了します。
サブスクリプション課金方法を選択した場合は、[サブスクリプション期間] も選択する必要があります。支払い遅延によるサービス中断を防ぐために、[自動更新] を選択することをお勧めします。
しばらくしてから、[インスタンス] ページでプライマリインスタンスを見つけます。インスタンス ID の左側にある矢印をクリックして、プライマリインスタンスにアタッチされている DuckDB 分析読み取り専用インスタンスを表示します。
DuckDB 分析読み取り専用インスタンスへの接続
(推奨) データベースプロキシ経由で接続
ビジネスに高同時実行性のオンライン取引処理 (OLTP) と複雑なオンライン分析処理 (OLAP) の両方が含まれる場合、データベースプロキシを使用して HTAP の自動リクエスト分散を有効にできます。データベースプロキシノードは SQL 文の実行コストを推定します。OLAP クエリリクエストを DuckDB 分析読み取り専用インスタンスに、OLTP クエリリクエストをプライマリインスタンスまたは通常の読み取り専用インスタンスに自動的にルーティングします。クライアント側でデータベースリクエストを手動で分類する必要はありません。
ApsaraDB RDS for MySQL プライマリインスタンスに DuckDB 分析読み取り専用インスタンスを追加します。
プライマリインスタンスの汎用データベースプロキシを有効にします。
プライマリインスタンスのHTAP の自動リクエスト分散を有効にします。
DuckDB 分析読み取り専用インスタンスに読み取りの重みを割り当てます。
データベースプロキシエンドポイントを使用してデータベースに接続します。データベースプロキシは、SQL クエリの推定実行コストに基づいて、リクエストを最適なインスタンスタイプに自動的に分散します。
直接接続
DuckDB 分析読み取り専用インスタンスには独立したエンドポイントがあります。OLAP クエリリクエストのみを処理する必要がある場合は、このエンドポイントを使用してインスタンスに直接接続できます。
ApsaraDB RDS コンソールにログインします。左側のナビゲーションウィンドウで、[インスタンス] をクリックします。上部のナビゲーションバーでリージョンを選択します。
[インスタンス] ページで、プライマリインスタンスを見つけます。インスタンス ID の左側にある矢印をクリックして、プライマリインスタンスにアタッチされている DuckDB 分析読み取り専用インスタンスを表示します。
DuckDB 分析読み取り専用インスタンスの ID をクリックして詳細ページに移動します。 セクションで、[エンドポイントの詳細を表示] をクリックしてエンドポイントを取得します。
デフォルトでは、ApsaraDB RDS インスタンスは内部エンドポイントを提供します。インターネット経由でインスタンスにアクセスするには、まずパブリックエンドポイントを申請し、次にDuckDB 分析読み取り専用インスタンスに接続します。
リファレンスと API 操作
関連 API 操作
CreateReadOnlyDBInstance 操作を呼び出して、DuckDB 分析読み取り専用インスタンスを作成します。
DescribeDBInstanceAttribute 操作を呼び出して、特定の DuckDB 分析読み取り専用インスタンスの詳細をクエリします。
DescribeDBInstances 操作を呼び出して、アカウントに属するすべての ApsaraDB RDS インスタンス (DuckDB 分析読み取り専用インスタンスを含む) の基本情報をクエリします。
付録: DuckDB 分析読み取り専用インスタンスのパフォーマンステスト
次のセクションでは、複雑なデータベースクエリのパフォーマンスを評価するために使用される標準の TPC-H ベンチマークテストを使用して、DuckDB 分析読み取り専用インスタンスの分析クエリパフォーマンスを示します。
テスト環境
データセット: TPC-H sf-100 データセットが使用されます。データ量は 100 GB です。データは DuckDB の公式ウェブサイトからのものです。
実行環境: 各データベースは、同じ仕様の ECS インスタンス (32 コア CPU、128 GB メモリ、ESSD) で実行されます。これにより、一貫したテスト環境が保証されます。
比較対象: 通常の ApsaraDB RDS for MySQL インスタンス (バージョン 8.0.36、InnoDB エンジン) と ClickHouse Community Edition (バージョン 25.3)。
テスト方法: クエリ結果の一貫性を確保するため、各データベースはまず 3 回のウォームアップラウンドを実行し、その結果は記録されません。その後、3 回の公式テストラウンドが実行されます。3 回の公式テストラウンドの平均値が最終的なパフォーマンス結果として使用されます。
テスト結果
次の表は、TPC-H sf-100 シナリオにおける、DuckDB 分析読み取り専用インスタンス、RDS MySQL インスタンス (InnoDB エンジン)、および ClickHouse での各クエリの実行時間を比較したものです。
クエリ ID | 実行時間 (秒) | ||
DuckDB 分析読み取り専用インスタンス | RDS MySQL 標準インスタンス (InnoDB エンジン) | ClickHouse | |
q1 | 0.92 | 1134.25 | 3.47 |
q2 | 0.15 | 1800 | 1.52 |
q3 | 0.53 | 802.94 | 3.65 |
q4 | 0.46 | 1000.45 | 2.77 |
q5 | 0.5 | 1800 | 5.38 |
q6 | 0.22 | 566.73 | 0.73 |
q7 | 0.59 | 1800 | 6.06 |
q8 | 0.68 | 1800 | 6.99 |
q9 | 1.44 | 1800 | 13.29 |
q10 | 0.91 | 894.35 | 3.22 |
q11 | 0.11 | 79.63 | 1.1 |
q12 | 0.44 | 734.35 | 1.69 |
q13 | 1.59 | 454.15 | 5.85 |
q14 | 0.38 | 574.07 | 0.83 |
q15 | 0.31 | 568.43 | 1.53 |
q16 | 0.32 | 63.56 | 0.52 |
q17 | 0.89 | 1800 | 7.96 |
q18 | 1.59 | 1800 | 3.11 |
q19 | 0.8 | 1800 | 2.96 |
q20 | 0.51 | 1800 | 3.38 |
q21 | 1.64 | 1800 | メモリ不足 |
q22 | 0.33 | 361.4 | 4 |
合計 | 15.31 | 25234.31 | 80.01 |
テストの結論
DuckDB 分析読み取り専用インスタンスと通常の ApsaraDB RDS for MySQL インスタンス (InnoDB エンジン) の比較
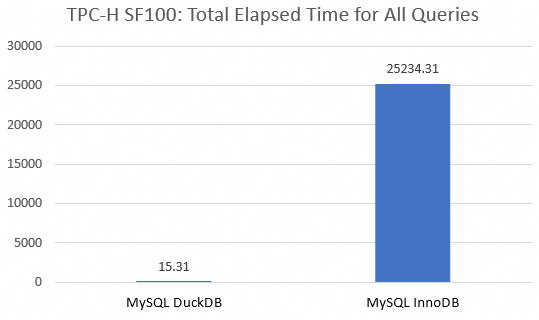
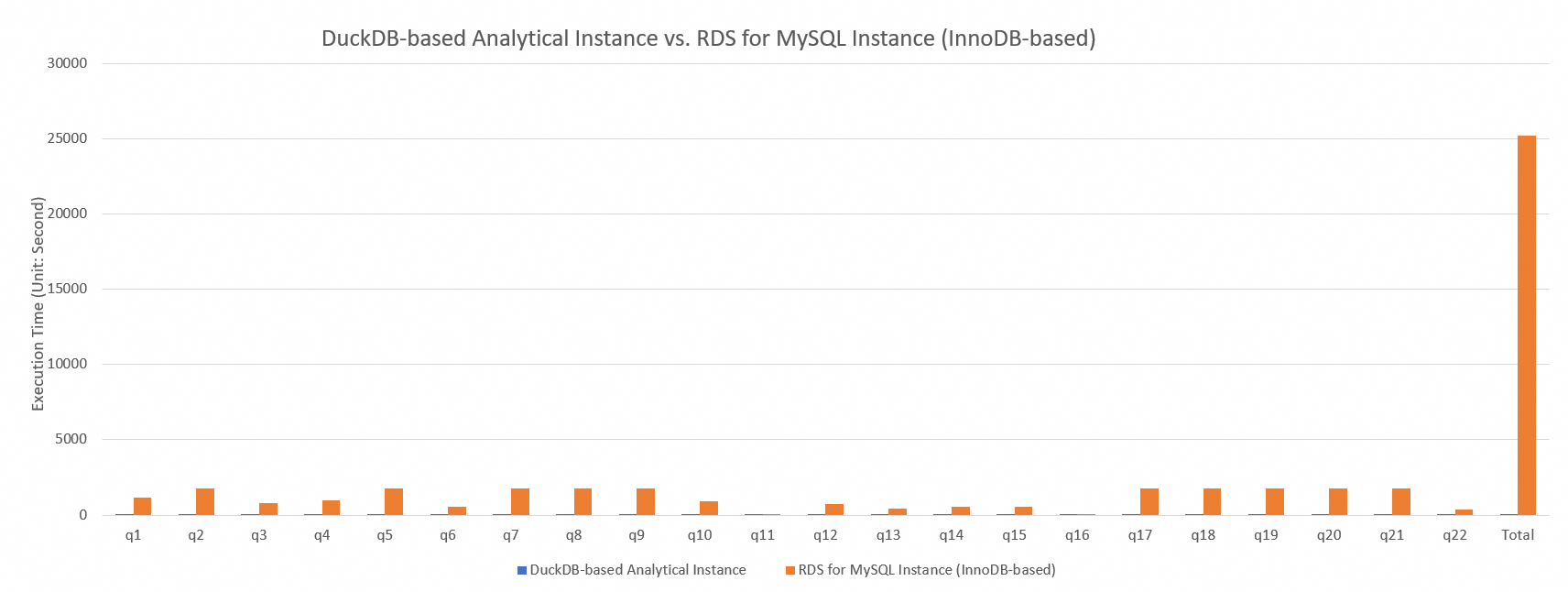
TPC-H テストでは、ApsaraDB RDS for MySQL インスタンス (InnoDB エンジン) の合計実行時間は 25,234.31 秒でしたが、DuckDB 分析読み取り専用インスタンスの合計実行時間はわずか 15.31 秒でした。パフォーマンスの差は 3 桁以上です。ApsaraDB RDS for MySQL インスタンス (InnoDB エンジン) は、複雑なクエリの処理において重大な欠陥を示しました。クエリ q5、q7、q8、q9、q17、q18、q19、q20、および q21 は、タイムアウトのために完了できませんでした。タイムアウト期間は一律に 1,800 秒としてカウントされます。これは、ApsaraDB RDS for MySQL DuckDB 分析読み取り専用インスタンスが、大規模なデータ分析クエリタスクに対して優れたパフォーマンスを発揮し、複雑なクエリの効率を大幅に向上させることを示しています。
DuckDB 分析読み取り専用インスタンスと ClickHouse インスタンスの比較
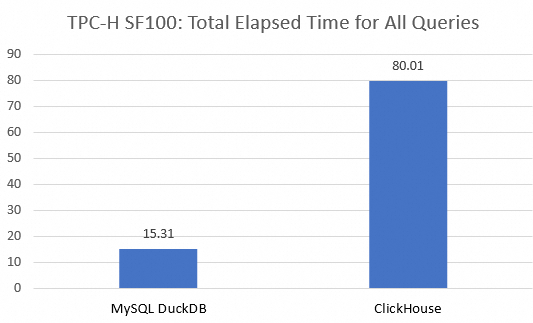
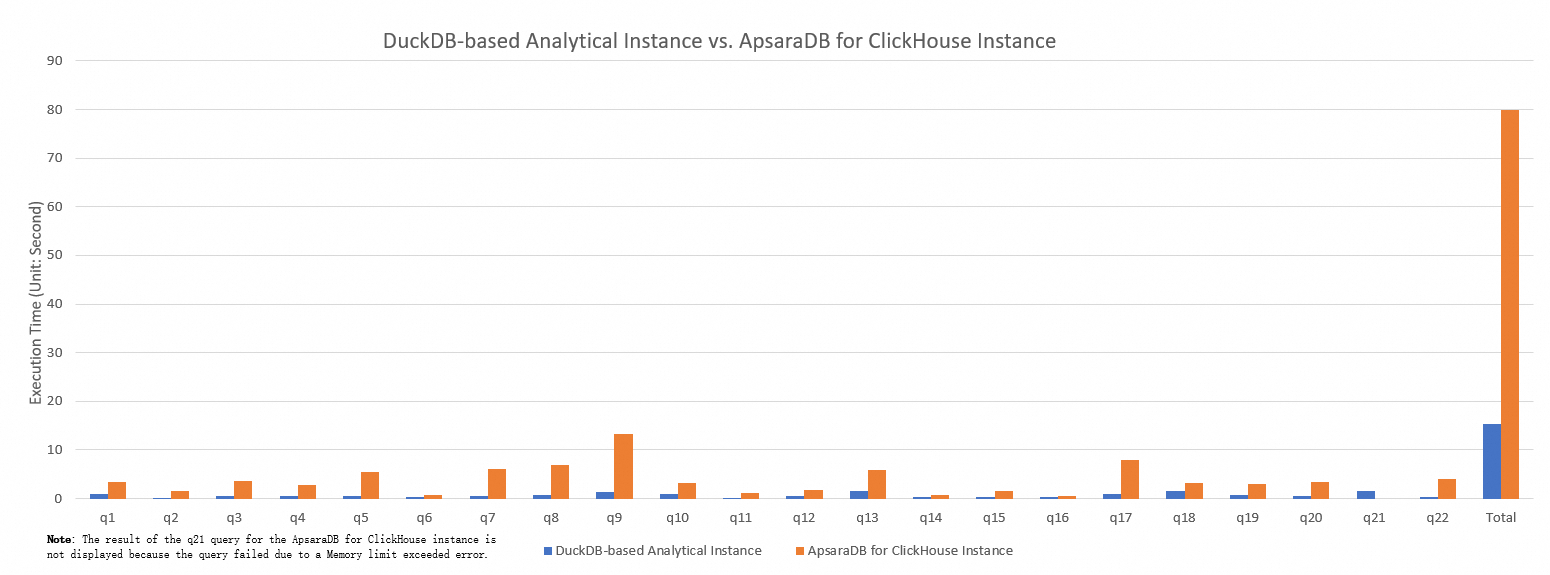
ClickHouse インスタンスの合計実行時間は 80.01 秒でした。比較すると、DuckDB 分析読み取り専用インスタンスの合計実行時間はわずか 15.31 秒であり、全体的なパフォーマンスで大きなリードを示しています。ClickHouse インスタンスは、クエリ q21 の実行時に
Memory limit exceededエラーを報告し、クエリを完了できませんでした。他のクエリでは、DuckDB 分析読み取り専用インスタンスは ClickHouse インスタンスよりも大幅に優れたパフォーマンスを発揮しました。これは、複雑な分析シナリオにおける優れたクエリパフォーマンスと安定性を示しています。