ARMS Prometheus Helm 1.1.17 / Agent v4.0.0 は、収集の安定性を向上させ、既知のバグを修正し、リソース消費を最適化します。
お使いのクラスターで ARMS Prometheus Agent v3.x.x が実行されている場合は、直ちに最新バージョンにアップグレードしてください。古いバージョンには最適化されていないコンポーネントが含まれており、データが途切れるリスクがあります。
v4.0.0 の機能
|
変更タイプ |
リリース内容 |
|
新機能 |
クラスターイベント収集ジョブ。Kubernetes Deployment ダッシュボードをサポートします。 |
|
新機能 |
SLA ベースの自己監視メトリックのインストルメンテーション。SLA 安定性ダッシュボードのデータを提供します。 |
|
新機能 |
ServiceMonitor が BasicAuth 認証をサポートします。Secret は ServiceMonitor と同じ名前空間に存在する必要があります。 |
|
新機能 |
メトリックメタデータにメトリックの定義が表示されるようになりました。 |
|
新機能 |
Agent Chart のバージョンをサーバーに渡し、それに応じてダッシュボードを初期化またはアップグレードします。 |
|
新機能 |
RemoteWrite の自己監視メトリック。バッチごとのデータ送信の所要時間を記録します。 |
|
追加 |
基本メトリック収集のエラーと収集遅延に関する自己監視メトリック。 |
|
新機能 |
ビジネスメトリック収集のエラーと遅延に関する自己監視メトリック。 |
|
最適化 |
RemoteWrite の |
|
最適化 |
PV 収集のための CSI 収集ジョブのサービスディスカバリー。 |
|
最適化 |
|
|
最適化 |
ログを効率化し、詳細なスクレイプリンクのタイミングを追加します。 |
|
最適化 |
基本メトリック収集ジョブは、グローバル設定の代わりに専用の収集サイクルとタイムアウト設定を使用します。 |
|
最適化 |
Master-Worker のマルチレプリカ分離。Master と Worker、および Worker 同士が互いに影響しなくなりました。 |
|
最適化 |
Master のターゲット割り当てを最適化。CPU オーバーヘッドを約 30%、メモリオーバーヘッドを約 40% 削減します。 |
|
最適化 |
メトリックのリラベルを最適化。CPU 使用率が 70% 削減されました。 |
|
最適化 |
マルチテナントシナリオにおける Informer リスナーロジック。CPU オーバーヘッドを約 20% 削減します。 |
|
最適化 |
CoreDNS の解決に失敗した場合、キャッシュされた IP にフォールバックします。データ送信の安定性が向上します。 |
|
最適化 |
収集設定のための |
|
最適化 |
Master の事前スクレイプポリシーを最適化。リソースオーバーヘッドを削減し、サービスディスカバリーとターゲットのスケジューリングを改善します。 |
|
最適化 |
1 MB を超えるデータバッチに対する適応的な処理。バックエンドの制限によるパケット損失を削減します。 |
|
バグ修正 |
|
|
バグ修正 |
マルチテナントシナリオ:Pod ラベルのキャッシュが迅速に更新されず、1 つのタイムラインが 2 つになる問題。 |
|
バグ修正 |
Master:OOM またはレプリカの再起動後にターゲットの割り当てが異常になり、一部の収集ターゲットが失われる問題。 |
|
バグ修正 |
RemoteWrite:Secret タイプの解析とヘッダーの送信に関する問題。 |
|
バグ修正 |
|
|
バグ修正 |
グローバルデフォルトパラメーターと |
アップグレードのリスク
-
Helm 1.1.17/Agent v4.0.0 へのアップグレードは中断を伴います。クラスター内のターゲットとシリーズの量に応じて、監視データが 0~5 分間途切れる可能性があります。
-
アップグレードする前に、「1. アップグレード前のチェック (必須)」を完了して、データの中断を最小限に抑えてください。
-
アップグレード後、「3. アップグレード後のチェック (任意)」でデータに異常がないか確認してください。トラブルシューティングについては、「アップグレード後の FAQ」をご参照ください。問題が解決しない場合は、DingTalk (ID: aliprometheus) で Prometheus の技術専門家にお問い合わせください。
アップグレード方法
1. アップグレード前のチェック (必須)
1.1.16 より前の Helm バージョンから 1.1.17 にアップグレードする場合、以前に変更したパラメーターは保持されません。アップグレード後に手動で復元できるように、アップグレードする前にカスタムパラメーターを記録しておいてください。
Helm 1.1.16 以降からのアップグレードはパラメーターの継承をサポートしているため、手動での復元は不要です。アップグレード前にパラメーターを確認するには、次の手順を実行します。
-
対象のクラスター名をクリックします。左側メニューで、[Workloads] > [Stateless] を選択します。名前空間を
arms-promに切り替えます。arms-prometheus-ack-arms-prometheusの [Actions] 列で、[More] > [View YAML] を選択します。 -
次のパラメーターを確認します。
-
spec.replicas:アップグレード後はデフォルトで 1 になります。値が 1 の場合は対応不要です。 -
spec.containersargs(エージェントの起動パラメーター)。マルチテナンシーが無効な場合は存在しません。アップグレード後にカスタム値を手動で復元してください。-
tenant_userid -
tenant_clusterid -
tenant_token
-
-
spec.containers.resources:デフォルトのリミットは 3 コア / 4 GB、デフォルトのリクエストは 1 コア / 1 GB です。デフォルト以外の値がある場合は記録し、アップグレード後に復元してください。

変更したパラメーターを保持するには、その値を記録します。アップグレード後、再度 YAML を開き、[Update] をクリックして復元します。

-
2. アップグレード手順
ACK コンソールで ARMS Prometheus Helm コンポーネントをアップグレードするには、次の手順を実行します。
-
ACK コンソールにログインします。
-
対象のクラスター名をクリックします。左側メニューで、[Operations Management] > [Component Management] を選択します。[Logs and Monitoring] タブをクリックします。
ack-arms-prometheusカードで [Upgrade] をクリックします。 -
アップグレード後、左側メニューで、[Operations Management] > [Prometheus Monitoring] を選択します。右上隅の [Go to Prometheus Service] をクリックして、エージェントの実行ステータスとメトリックの収集詳細を表示します。
左側メニューで [Settings] をクリックします。[Settings] タブで、Helm のバージョンが更新されていることを確認します。

3. アップグレード後のチェック (任意)
にログインします。 Prometheusコンソールのマネージドサービス。
左側のナビゲーションウィンドウで、[インスタンス] をクリックします。
-
対象の Prometheus インスタンス名をクリックします。左側メニューで [Service Discovery] をクリックします。[Targets] タブで、収集ジョブのステータスを確認します。
-
左側メニューで [Settings] をクリックします。[Self-Monitoring] タブで、右上隅の [Go to Grafana to view dashboards] をクリックします。レプリカ数、データ送信レート、リソース消費が正常であることを確認します。
-
[Self-Monitoring] ページで、[Agent Self-Monitoring] タブを選択して、Prometheus エージェントの自己監視ダッシュボードを表示します。
4 つの基本メトリック収集ジョブ (
_arms/kubelet/cadvisor、_arms/kubelet/metric、_kube-state-metrics、node-exporter) を監視します。アップグレードの前後を含む期間を選択し、異常がないか確認します。
アップグレード後の FAQ
実行中のレプリカ数が期待値と一致しない
ARMS Prometheus では、すべてのレプリカが実行中 (Running) である必要があります。Container Service コンソールで保留中 (Pending) のエージェントを確認します。対象のクラスターに移動し、arms-prom 名前空間で [Workloads] > [Stateless] を選択します。
エージェントが過剰なメモリまたは CPU を消費する
データ送信の異常により、エージェントのメモリにデータが蓄積されることがあります。Container Service コンソールで、[Operations Management] > [Prometheus Monitoring] に移動し、[Others] タブをクリックします。[Prometheus Agent] で、メモリと CPU の消費量を確認します。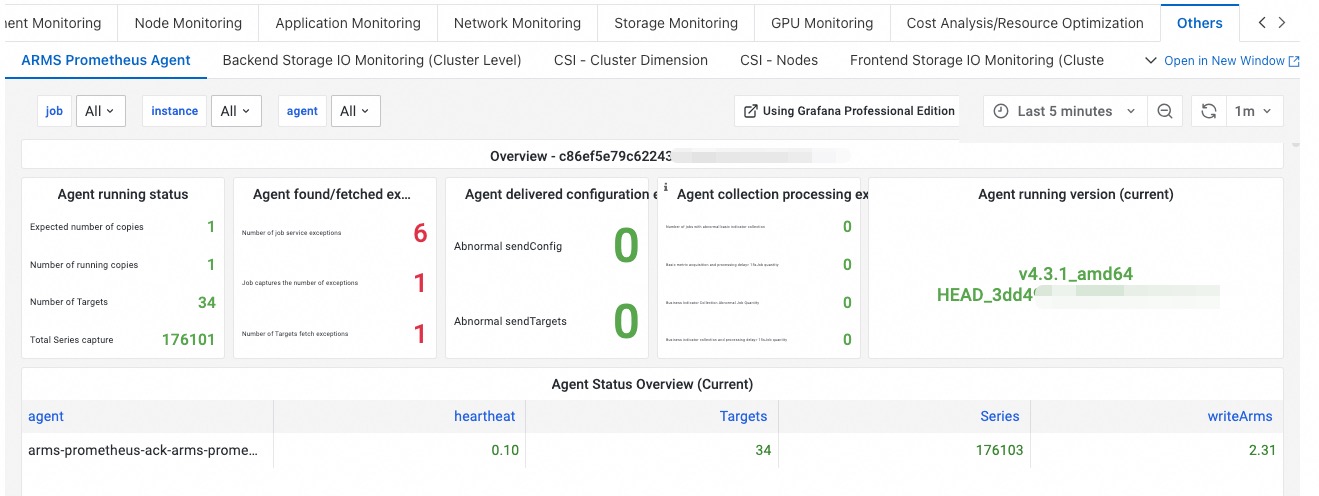
基本メトリックに途切れや不連続が見られる
node_*** (①)、container_*** (②)、kubelet_*** (③)、kube_*** (④) などのメトリックに異常がある場合は、Prometheus コンソールの [Service Discovery] > [Targets] ページで基本メトリック収集ジョブを確認してください。エラーが解決しない場合は、DingTalk (ID: aliprometheus) で Prometheus の技術専門家にお問い合わせください。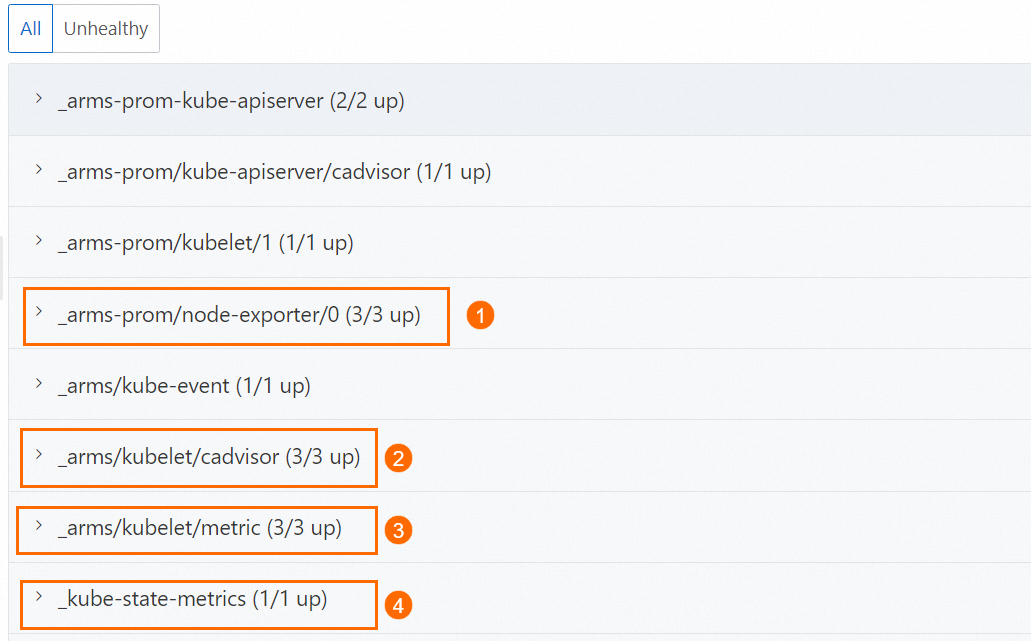
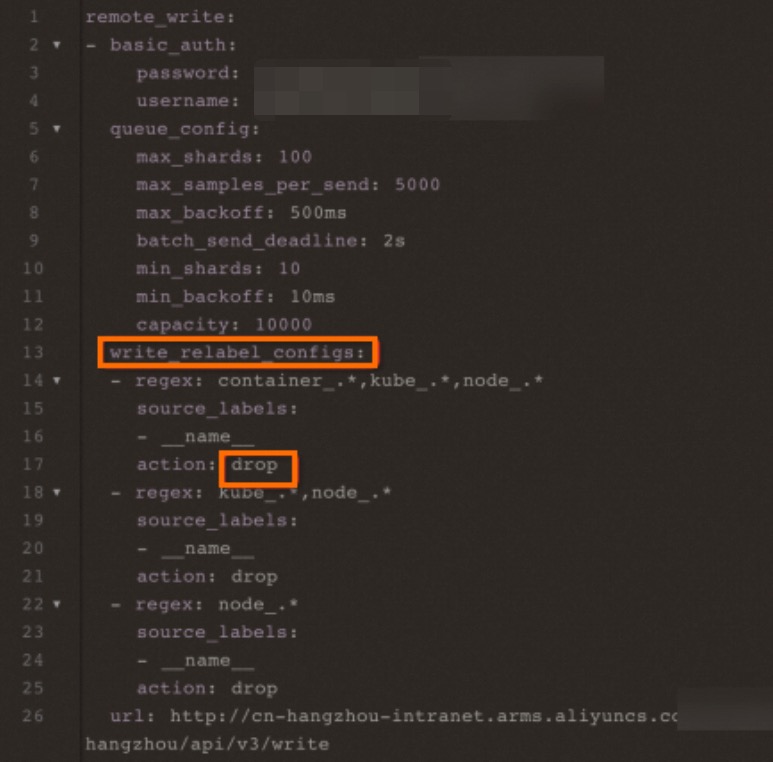
RemoteWrite のトラフィックが低下またはデータが欠落する
-
RemoteWrite を設定していない場合は、この問題を無視できます。
-
v4.0.0 では、
write_relabel_configsが自動的に有効になります。dropまたはkeepアクションを設定している場合、トラフィックが失われる可能性があります。このフィールドを変更するには、[Settings] > [Settings] に移動し、[Edit Prometheus.yaml] をクリックします。