このトピックでは、PolarDB-X のオプティマイザーとエグゼキュータが JOIN 操作とサブクエリをどのように処理するかについて説明します。JOIN 操作とは、複数のテーブルの行を、それらのテーブル間にある 1 つ以上の共通の列に基づいて結合する操作です。サブクエリとは、クエリの WHERE 句または HAVING 句の中にネストされた SELECT 文です。
概念
JOIN 操作は SQL クエリでよく使用されます。JOIN のセマンティクスは、2 つのテーブルのデカルト積を計算し、フィルター条件を満たすデータを保持することと同じです。ほとんどの場合、等結合が使用されます。等結合は、指定された列の値に基づいて 2 つのテーブルを結合するために使用されます。
サブクエリとは、別の SQL クエリの中にネストされたクエリです。サブクエリ の結果は外部クエリに渡され、外部クエリの処理に使用されます。サブクエリは、SQL 文のさまざまなコンポーネントで使用できます。たとえば、サブクエリは、SELECT 句の出力データ、FROM 句の入力ビュー、または WHERE 句のフィルター条件として使用できます。
このトピックで説明する JOIN 操作は、コンピューティング レイヤーで実行されます。ストレージ レイヤーの MySQL エンジンは、LogicalView にプッシュダウンされた JOIN 操作の実行方法を決定します。
JOIN 操作の種類
PolarDB-X 1.0 は、内部結合、左外部結合、右外部結合など、一般的な JOIN 操作の種類をサポートしています。

次の例は、さまざまな種類の JOIN 操作を示しています。
/* 内部結合 */
SELECT * FROM A, B WHERE A.key = B.key;
/* 左外部結合 */
SELECT * FROM A LEFT JOIN B ON A.key = B.key;
/* 右外部結合 */
SELECT * FROM A RIGHT OUTER JOIN B ON A.key = B.key;PolarDB-X 1.0 は、セミ結合とアンチ結合もサポートしています。セミ結合とアンチ結合は SQL で記述できません。これらは、EXISTS 条件または IN 条件の中にネストされたサブクエリを使用して実装されます。
次のコードは、セミ結合とアンチ結合の例を示しています。
/* セミ結合 - 1 */
SELECT * FROM Emp WHERE Emp.DeptName IN (
SELECT DeptName FROM Dept
)
/* セミ結合 - 2 */
SELECT * FROM Emp WHERE EXISTS (
SELECT * FROM Dept WHERE Emp.DeptName = Dept.DeptName
)
/* アンチ結合 - 1 */
SELECT * FROM Emp WHERE Emp.DeptName NOT IN (
SELECT DeptName FROM Dept
)
/* アンチ結合 - 2 */
SELECT * FROM Emp WHERE NOT EXISTS (
SELECT * FROM Dept WHERE Emp.DeptName = Dept.DeptName
)JOIN アルゴリズム
PolarDB-X 1.0 は、ネステッドループ結合、ハッシュ結合、ソートマージ結合、ルックアップ結合など、複数の分散結合アルゴリズムをサポートしています。ルックアップ結合は、BKA 結合とも呼ばれます。
ネステッドループ結合 (NLJoin)
ネステッドループ結合は、非等結合によく使用されます。ネステッドループ結合は、次の方法で動作します。
内部テーブルからすべての行を選択し、それらの行をメモリにキャッシュします。内部テーブルとは、ほとんどの場合、データ量の少ない右側のテーブルを指します。
外部テーブル全体をスキャンし、外部テーブルの各行を内部テーブルと比較して、結果セットを作成します。
結果セットが結合条件を満たしているかどうかを確認し、条件が満たされている場合は結果セットを返します。
次のコードは、ネステッドループ結合の例を示しています。
> EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey < s_suppkey;
NlJoin(condition="ps_suppkey < s_suppkey", type="inner")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp`")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier`")ほとんどの場合、ネステッドループ結合は最も効率の悪い結合アルゴリズムです。ネステッドループ結合は、前の例のように結合が非等結合である場合、または内部テーブルのデータ量が小さい場合にのみ使用できます。
次のヒントを使用すると、PolarDB-X 1.0 にネステッドループ結合を使用させ、結合順序を指定できます。
/*+TDDL:NL_JOIN(outer_table, inner_table)*/ SELECT ...次の例のように、複数のテーブルを結合した結果を inner_table または outer_table として使用することもできます。
/*+TDDL:NL_JOIN((outer_table_a, outer_table_b), (inner_table_c, inner_table_d))*/ SELECT ...他の例のヒントも同様に機能します。
ハッシュ結合
ハッシュ結合は、等結合で最もよく使用される結合アルゴリズムの 1 つです。ハッシュ結合は、次の方法で動作します。
内部テーブルからすべての行を選択し、メモリに格納されたハッシュテーブルに行を書き込みます。内部テーブルとは、ほとんどの場合、データ量の少ない右側のテーブルを指します。
外部テーブル全体をスキャンします。外部テーブルの各行について、次の操作を行います。
等価条件の結合キーに対してハッシュテーブルをスキャンし、同じ結合キーを持つ 0 ~ N 個の行を選択します。
結果セットを作成し、結果セットが結合条件を満たしているかどうかを確認し、条件が満たされている場合は結果セットを返します。
次のコードは、ハッシュ結合の例を示しています。
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey;
HashJoin(condition="ps_suppkey = s_suppkey", type="inner")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp`")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier`")ハッシュ結合は、大量のデータを結合する複雑なクエリでよく使用されますが、インデックスルックアップでは最適化できません。この場合、ハッシュ結合が最適なアルゴリズムです。前の例では、システムは partsupp テーブルと supplier テーブルで全表スキャンを実行する必要があります。これには大量のデータが関係します。したがって、ハッシュ結合はこのシナリオに適しています。
ハッシュ結合の内部テーブルは、メモリに格納されたハッシュテーブルを作成するために使用されます。内部テーブルのデータ量が外部テーブルよりも少ないことを確認してください。ほとんどの場合、オプティマイザーは最適な結合順序を自動的に選択できます。手動制御が必要な場合は、次のヒントを使用すると、PolarDB-X 1.0 にハッシュ結合を使用させ、結合順序を指定できます。
/*+TDDL:HASH_JOIN(table_outer, table_inner)*/ SELECT ...ルックアップ結合 (BKAJoin)
ルックアップ結合は、等結合のもう 1 つの結合アルゴリズムであり、少量のデータが関係するシナリオでよく使用されます。ルックアップ結合は、次の方法で動作します。
外部テーブル全体をスキャンします。外部テーブルとは、ほとんどの場合、データ量の少ない左側のテーブルを指します。外部テーブルの各バッチ (たとえば、1,000 行ごと) について、次の操作を行います。
バッチ内の行の結合キーを使用した
IN (...)条件を作成し、その条件を内部テーブルクエリに追加します。内部テーブルクエリを実行して、結合条件を満たす行を選択します。
ハッシュテーブルに基づいて外部テーブルの各行を内部テーブルの行にマッピングし、内部テーブルと外部テーブルの行をマージして、結果を返します。
次のコードは、ルックアップ結合 (BKA 結合) の例を示しています。
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey AND ps_partkey = 123;
BKAJoin(condition="ps_suppkey = s_suppkey", type="inner")
LogicalView(tables="partsupp_3", sql="SELECT * FROM `partsupp` AS `partsupp` WHERE (`ps_partkey` = ?)")
Gather(concurrent=true)
LogicalView(tables="supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier` WHERE (`s_suppkey` IN ('?'))")ルックアップ結合は、外部テーブルのデータ量が小さいシナリオに適しています。前の例では、フィルター条件 ps_partkey = 123 により、左側のテーブル partsupp から選択される行はごくわずかです。また、s_suppkey IN (...) 条件は、右側のテーブルの主キーインデックスと一致します。これにより、ルックアップ結合のコストが削減されます。
次のヒントを使用すると、PolarDB-X 1.0 にルックアップ結合を使用させ、結合順序を指定できます。
/*+TDDL:BKA_JOIN(table_outer, table_inner)*/ SELECT ...ルックアップ結合の内部テーブルは単一のテーブルでなければならず、複数のテーブルを結合した結果は使用できません。
ソートマージ結合
ソートマージ結合は、等結合のもう 1 つの結合アルゴリズムです。ソートマージ結合は、左右のテーブルの入力行の順序に依存します。入力行は、結合キーに基づいてソートする必要があります。ソートマージ結合は、次の方法で動作します。
MergeSort または MemSort を使用して入力行をソートします。
次の方法を使用して、左右のテーブルの入力行を比較します。
現在の左側の行の結合キーが現在の右側の行の結合キーよりも小さい場合は、現在の右側の行を次の左側の行と照合します。
現在の右側の行の結合キーが現在の左側の行の結合キーよりも小さい場合は、現在の左側の行を次の右側の行と照合します。
2 つの行の結合キーが同じで、結合条件が満たされている場合は、左右の行をマージして結果を返します。
次のコードは、ソートマージ結合の例を示しています。
EXPLAIN SELECT * FROM partsupp, supplier WHERE ps_suppkey = s_suppkey ORDER BY s_suppkey;
SortMergeJoin(condition="ps_suppkey = s_suppkey", type="inner")
MergeSort(sort="ps_suppkey ASC")
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.partsupp_[0-7]", shardCount=8, sql="SELECT * FROM `partsupp` AS `partsupp` ORDER BY `ps_suppkey`")
MergeSort(sort="s_suppkey ASC")
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.supplier_[0-7]", shardCount=8, sql="SELECT * FROM `supplier` AS `supplier` ORDER BY `s_suppkey`")前述の実行プランの MergeSort 演算子とプッシュダウンされた ORDER BY 演算子により、ソートマージ結合の左右のテーブルの入力行が結合キー s_suppkey (ps_suppkey) に基づいてソートされます。
ソートマージ結合は、最初に入力行をソートする必要があるため、最適な結合アルゴリズムではありません。ただし、前の例のように、ユーザーは結合キーに基づいてクエリ結果をソートしたい場合があります。この場合、ソートマージ結合が最適な選択肢です。
次のヒントを使用すると、PolarDB-X 1.0 にソートマージ結合を使用させることができます。
/*+TDDL:SORT_MERGE_JOIN(table_a, table_b)*/ SELECT ...JOIN 操作の順序
複数のテーブルを結合するシナリオでは、オプティマイザーはテーブルを結合する順序を決定する必要があります。これは、結合順序が中間結果セットのサイズと実行プランのコストに影響を与えるためです。
たとえば、4 つのテーブルで JOIN 操作が実行され、プッシュダウンされないとします。この場合、次の結合ツリーが適用可能です。また、4 つのテーブルは最大 24 (4! の結果) 通りにソートできます。その結果、最大 72 種類の結合順序が使用可能です。
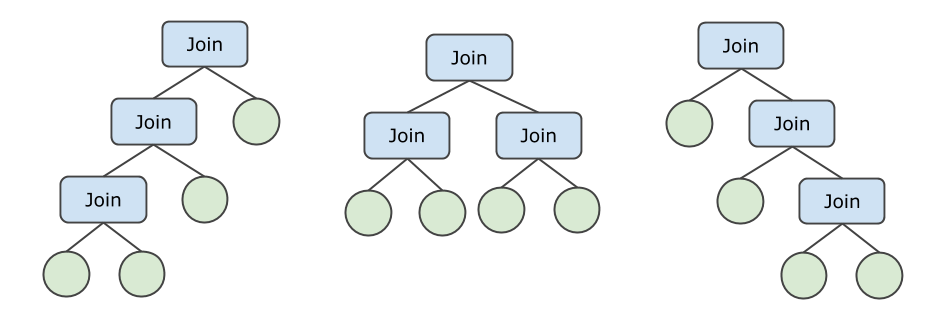
PolarDB-X 1.0 は、適応戦略を使用して、N 個のテーブルで実行される特定の JOIN 操作に最適な実行プランを作成します。
JOIN 操作がプッシュダウンされず、N の値が小さい場合は、ブッシーツリーを使用して最適な実行プランを作成します。
JOIN 操作がプッシュダウンされず、N の値が大きい場合は、ジグザグツリーまたは左優先ツリーを使用して最適な実行プランを作成します。これにより、列挙回数とコストが削減されます。
PolarDB-X 1.0 は、コストベースのオプティマイザーを使用して、コストが最も低い結合順序を選択します。詳細については、「クエリ オプティマイザーの概要」をご参照ください。
また、結合アルゴリズムによって、左右のテーブルに対するプリファレンスが異なります。たとえば、ハッシュ結合の右側のテーブルは内部テーブルであり、ハッシュテーブルを作成するために使用されます。したがって、データ量の少ないテーブルを右側のテーブルとして指定します。コストベースのオプティマイザーにも同様のプリファレンスがあります。
サブクエリ
サブクエリは、外部クエリの値を使用するかどうかによって、相関のないサブクエリまたは相関サブクエリに分類されます。相関のないサブクエリは、外部クエリの変数とは無関係に実行されます。ほとんどの場合、相関のないサブクエリは 1 回だけ実行されます。相関サブクエリは、外部クエリの変数を使用します。相関サブクエリは、外部クエリの変数の値を使用する必要があるため、各入力行で実行されます。
/* 相関のないサブクエリの例。 */
SELECT * FROM lineitem WHERE l_partkey IN (SELECT p_partkey FROM part);
/* 相関サブクエリの例。l_suppkey は外部クエリから参照される列です。 */
SELECT * FROM lineitem WHERE l_partkey IN (SELECT ps_partkey FROM partsupp WHERE ps_suppkey = l_suppkey);PolarDB-X 1.0 は、ほとんどの SQL サブクエリをサポートしています。詳細については、「SQL の制限」をご参照ください。
PolarDB-X 1.0 は、一般的なサブクエリを SEMIJOIN 文または JOIN 文に変換して、実行効率を向上させることができます。これにより、大量のデータが関係する場合でも、システムはネストされたパラメーターのグループを反復処理する必要がなくなります。これにより、実行コストが大幅に削減されます。このサブクエリの変換方法は、非ネスト化と呼ばれます。
次の例は、PolarDB-X が実行プランで JOIN 文に置き換えることによってサブクエリを非ネスト化する方法を示しています。
EXPLAIN SELECT p_partkey, (
SELECT COUNT(ps_partkey) FROM partsupp WHERE ps_suppkey = p_partkey
) supplier_count FROM part;
Project(p_partkey="p_partkey", supplier_count="CASE(IS NULL($10), 0, $9)", cor=[$cor0])
HashJoin(condition="p_partkey = ps_suppkey", type="left")
Gather(concurrent=true)
LogicalView(tables="part_[0-7]", shardCount=8, sql="SELECT * FROM `part` AS `part`")
Project(count(ps_partkey)="count(ps_partkey)", ps_suppkey="ps_suppkey", count(ps_partkey)2="count(ps_partkey)")
HashAgg(group="ps_suppkey", count(ps_partkey)="SUM(count(ps_partkey))")
Gather(concurrent=true)
LogicalView(tables="partsupp_[0-7]", shardCount=8, sql="SELECT `ps_suppkey`, COUNT(`ps_partkey`) AS `count(ps_partkey)` FROM `partsupp` AS `partsupp` GROUP BY `ps_suppkey`")ただし、PolarDB-X 1.0 は、一部のシナリオではサブクエリを非ネスト化できません。これらのシナリオでは、サブクエリが実行された後にのみクエリを実行できます。外部クエリに大量のデータが関係する場合、反復処理に時間がかかることがあります。
次の例では、特定の行で l_partkey の値が 50 未満であるため、サブクエリを非ネスト化できません。したがって、PolarDB-X はネストされた反復処理を実行します。
EXPLAIN SELECT * FROM lineitem WHERE l_partkey IN (SELECT ps_partkey FROM partsupp WHERE ps_suppkey = l_suppkey) OR l_partkey IS NOT
Filter(condition="IS(in,[$1])[29612489] OR l_partkey < ?0")
Gather(concurrent=true)
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.lineitem_[0-7]", shardCount=8, sql="SELECT * FROM `lineitem` AS `lineitem`")
>> individual correlate subquery : 29612489
Gather(concurrent=true)
LogicalView(tables="QIMU_0000_GROUP,QIMU_0001_GROUP.partsupp_[0-7]", shardCount=8, sql="SELECT * FROM (SELECT `ps_partkey` FROM `partsupp` AS `partsupp` WHERE (`ps_suppkey` = `l_suppkey`)) AS `t0` WHERE (((`l_partkey` = `ps_partkey`) OR (`l_partkey` IS NULL)) OR (`ps_partkey` IS NULL))")実行効率を向上させるには、OR 条件を削除して SQL 文を書き直すことをお勧めします。