クエリオプティマイザーは、論理プランを物理プランに変換します。このプロセスは、主に SQL 書き換えとプラン列挙の 2 つのフェーズで構成されます。

PolarDB-X が SQL ステートメントを受信すると、次の処理が行われます。
構文パーサーが SQL テキストを解析し、抽象構文木 (AST) を生成します。
AST は、関係代数ベースの論理プランに変換されます。
オプティマイザーが論理プランを書き換えて最適化し、物理プランを生成します。
エグゼキュータが物理プランを実行し、クエリ結果をクライアントに返します。
このトピックでは、オプティマイザーを構成する 3 つの要素について説明します。
関係代数演算子
SQL 書き換え (ルールベースオプティマイザー (RBO) フェーズ)
クエリプランの列挙 (コストベースオプティマイザー (CBO) フェーズ)
関係代数演算子
PolarDB-X は、SQL クエリを関係代数演算子のツリーとして表現します。各演算子は、1 つ以上の物理的な実装にマッピングされます。
| 論理演算子 | 内容 | 物理演算子 |
|---|---|---|
| Project | SELECT 列リスト (関数計算を含む) | — |
| Filter | WHERE 条件 | — |
| JOIN | JOIN 句 | HashJoin、BKAJoin、Nested-Loop Join、SortMergeJoin |
| Agg | GROUP BY および集計関数 | HashAgg、SortAgg |
| Sort | ORDER BY および LIMIT | TopN、MemSort |
| LogicalView | MySQL ストレージレイヤーに送信される SQL。1 つ以上の論理演算子をラップすることがあります。 | — |
| Gather | 複数のデータストリームから結果を収集します。通常、LogicalView ノードの上に表示されます。並列実行が有効な場合、オプティマイザーは並列最適化ステップで Gather をプルアップします。 | — |
例:EXPLAIN 出力の読み取り
次のクエリは、TPC-H クエリ 3 を基にしています。
SELECT l_orderkey, sum(l_extendedprice *(1 - l_discount)) AS revenue
FROM CUSTOMER, ORDERS, LINEITEM
WHERE c_mktsegment = 'AUTOMOBILE'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < '1995-03-13'
and l_shipdate > '1995-03-13'
GROUP BY l_orderkey;EXPLAIN を実行して実行計画を表示します。
HashAgg(group="l_orderkey", revenue="SUM(*)")
HashJoin(condition="o_custkey = c_custkey", type="inner")
Gather(concurrent=true)
LogicalView(tables="ORDERS_[0-7],LINEITEM_[0-7]", shardCount=8, sql="SELECT `ORDERS`.`o_custkey`, `LINEITEM`.`l_orderkey`, (`LINEITEM`.`l_extendedprice` * (? - `LINEITEM`.`l_discount`)) AS `x` FROM `ORDERS` AS `ORDERS` INNER JOIN `LINEITEM` AS `LINEITEM` ON (((`ORDERS`.`o_orderkey` = `LINEITEM`.`l_orderkey`) AND (`ORDERS`.`o_orderdate` < ?)) AND (`LINEITEM`.`l_shipdate` > ?))")
Gather(concurrent=true)
LogicalView(tables="CUSTOMER_[0-7]", shardCount=8, sql="SELECT `c_custkey` FROM `CUSTOMER` AS `CUSTOMER` WHERE (`c_mktsegment` = ?)")プランツリーは次のようになります。
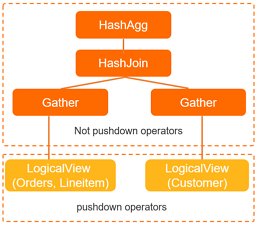
左側の LogicalView ノードは、ORDERS と LINEITEM の JOIN をラップしています。EXPLAIN 出力の sql 属性は、その JOIN を含め、PolarDB-X がストレージレイヤーにプッシュダウンするフル SQL を示しています。EXPLAIN 出力フィールド
| フィールド | 意味 | 例 |
|---|---|---|
group= | Agg 演算子のグルーピング列 | group="l_orderkey" |
condition= | Join またはフィルター条件 | condition="o_custkey = c_custkey" |
tables= | LogicalView がアクセスするシャードテーブル名 | tables="ORDERS_[0-7]" |
shardCount= | アクセスされるシャード数 | shardCount=8 |
sql= | MySQL ストレージレイヤーに送信される SQL | フル SQL 文字列 |
concurrent= | Gather がストリームを並列に収集するかどうか | concurrent=true |
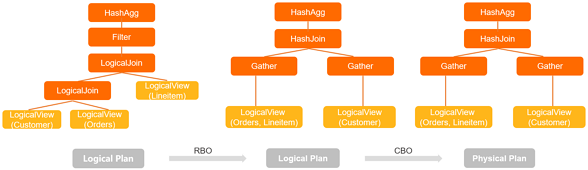
SQL 書き換え (RBO)
ルールベースオプティマイザー (RBO) は、論理プランを入力として受け取り、書き換えられた論理プランを生成します。RBO は、固定された一連のヒューリスティックなルールを適用します。ルールは決定論的であるため、このフェーズは RBO フェーズとも呼ばれます。
サブクエリのネスト解除
サブクエリのネスト解除は、相関サブクエリを SemiJoin または同等の演算子に変換します。これにより、サブクエリを MySQL ストレージレイヤーにプッシュダウンしたり、PolarDB-X レイヤーで効率的な実行アルゴリズムを選択したりすることが可能になります。
次の例では、IN サブクエリが SemiHashJoin として書き換えられています。
> explain select id from t1 where id in (select id from t2 where t2.name = 'hello');
SemiHashJoin(condition="id = id", type="semi")
Gather(concurrent=true)
LogicalView(tables="t1", shardCount=2, sql="SELECT `id` FROM `t1` AS `t1`")
Gather(concurrent=true)
LogicalView(tables="t2_[0-3]", shardCount=4, sql="SELECT `id` FROM `t2` AS `t2` WHERE (`name` = ?)")演算子のプッシュダウン
演算子のプッシュダウンは、処理を可能な限りデータに近い場所へ移動させます。演算子を MySQL ストレージレイヤーにプッシュダウンすることで、早期にデータのフィルタリングと集計が行われ、ネットワーク経由で転送されるデータ量を削減します。
PolarDB-X は、次のプッシュダウンルールを適用します。
| ルール | 内容 |
|---|---|
| 述語プッシュダウンと列のプルーニング | Filter および Project 演算子を MySQL ストレージレイヤーにプッシュダウンし、不要な行と列をフィルタリングします。 |
| JOIN クラスタリング | シャードキーの等価条件に基づいて JOIN 操作を再ソートおよびグループ化し、後続の JOIN プッシュダウンを可能にします。 |
| JOIN プッシュダウン | シャードキーの条件を満たす JOIN 操作を MySQL ストレージレイヤーにプッシュダウンします。 |
| Agg プッシュダウン | Agg を LocalAgg (各シャードで実行) と FinalAgg (PolarDB-X レイヤーで実行) に分割し、LocalAgg を MySQL にプッシュダウンします。 |
| Sort プッシュダウン | Sort を LocalSort (各シャードで実行) と MergeSort (PolarDB-X レイヤーで実行) に分割し、LocalSort を MySQL にプッシュダウンします。 |
プッシュダウンの動作に関する詳細なウォークスルーについては、「SQL 書き換えとプッシュダウン」をご参照ください。
クエリプランの列挙 (CBO)
CBO は、RBO フェーズで書き換えられた論理プランを受け取り、多くの代替案の中から最もコストの低い物理実行計画を選択します。事前定義されたコストモデルを使用して、複数の実行可能なクエリプランの中から最小コストのクエリプランを選択します。RBO とは異なり、CBO はルールを無条件に適用しません。ルールの適用順序が異なると、プランの良し悪しが変わるため、CBO はコストを比較して最適なオプションを選択します。そのため、プラン列挙子 (Plan Enumerator) は CBO とも呼ばれます。
CBO の仕組み
CBO (プラン列挙子とも呼ばれます) は、次の 3 つのステップで実行されます。
検索空間の構築: 検索エンジンが論理プランに変換ルールを適用し、候補となる物理プランのセットを生成します。
コストの推定: コストモデルが検索空間内の各候補プランを評価し、推定コストが最も低いものを選択します。
カーディナリティの推定: コスト推定はカーディナリティ推定に依存します。オプティマイザーは、各演算子について、テーブルと列の統計情報に基づいて入力行数と選択性を見積もります。これらの推定値はコストモデルに入力されます。
CBO のコンポーネント
| コンポーネント | 役割 |
|---|---|
| 統計情報 | PolarDB-X によって収集されたテーブルごとおよび列ごとのデータ分布 |
| カーディナリティ推定 | 統計情報に基づいて、各演算子の行数と選択性を見積もります。 |
| 変換ルール | 論理プランを代替の物理プラン形状に書き換えるルール (例:JOIN の順序変更) |
| コストモデル | 推定行数と演算子の特性に基づいて、各候補プランにコストを割り当てます。 |
| プラン空間検索エンジン | 変換ルールを使用して候補プランを列挙し、最小コストのプランを選択します。 |
次のステップ
SQL 書き換えとプッシュダウン:PolarDB-X がシャーディング情報をどのように使用して演算子を MySQL にプッシュダウンし、データフローを最適化するかを詳しく説明します。