分散データベースでは、コーディネーターレイヤーで計算を実行すると、処理前にネットワーク経由で生データをフェッチする必要があり、これは低速です。PolarDB-X 1.0 は、演算子実行をデータのできるだけ近くに移動するためにプッシュダウンを使用します。これにより、フィルター、集約、ソート、結合、サブクエリが各 MySQL シャード内で実行され、削減された事前処理済みの結果のみがネットワークを介して転送されます。
オプティマイザーが特定のクエリをどのようにクエリリライトするかを確認するには、以下を実行します。
EXPLAIN OPTIMIZER <your_sql>;以下の演算子タイプがプッシュダウンをサポートしています。
| 演算子タイプ | 例 |
|---|---|
| フィルター | WHERE、HAVING 条件 |
| プロジェクト | 列選択 |
| ソート | ORDER BY |
| リミット | LIMIT |
| 集約 | COUNT、GROUP BY |
| 結合 | 内部結合、外部結合 |
| サブクエリ | IN、EXISTS サブクエリ |
| 関数 | NOW() および類似の関数 |
| 重複排除 | DISTINCT |
以下の各セクションでは、オプティマイザーがその演算子を LogicalView (実行計画における MySQL ストレージレイヤーを表す演算子) にどのようにプッシュダウンするか、およびプッシュダウンが適用されない場合について説明します。
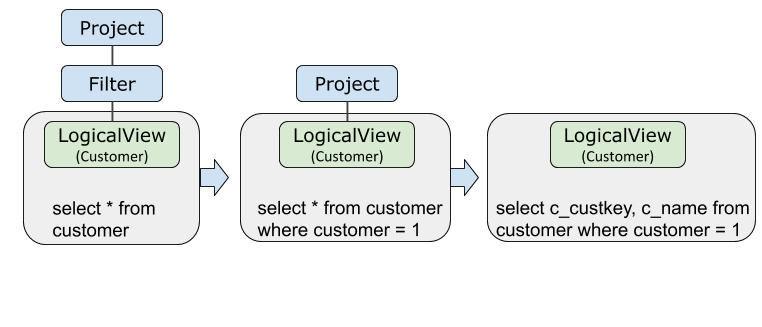
プロジェクションとフィルターのプッシュダウン
クエリにシャードキーに対するフィルターが含まれている場合、オプティマイザーはフィルター演算子とプロジェクション演算子の両方を LogicalView にプッシュダウンします。ストレージレイヤーは、データをコーディネーターに送信する前に、行を破棄し、未使用の列を削除するため、ネットワーク転送が削減されます。
EXPLAIN OPTIMIZER SELECT c_custkey, c_name FROM customer WHERE c_custkey = 1;c_custkey は customer のシャードキーです。フィルターがシャードキー上にあるため、オプティマイザーは条件をストレージレイヤーで完全に評価します。
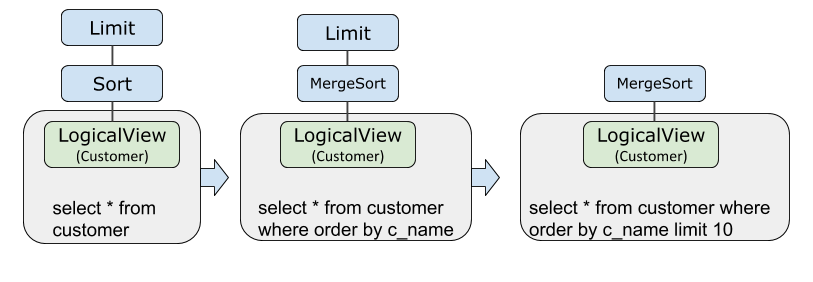
リミットとソートのプッシュダウン
オプティマイザーはソートとリミットを一緒に LogicalView にプッシュダウンします。各シャードは自身の行をローカルでソートおよびリミットするため、コーディネーターは生データではなく、事前にソートおよびフィルターされた行を受け取ります。
EXPLAIN OPTIMIZER SELECT * FROM customer ORDER BY c_custkey LIMIT 10;これにより、ネットワーク転送が削減され、シャード間での並列ソートが可能になり、コーディネーターレイヤーでのメモリ使用量が低減されます。
集約のプッシュダウン
オプティマイザーは集約演算子を LogicalView にプッシュダウンし、各シャードがローカルで部分集約を計算するようにします。その後、コーディネーターは生データではなく部分的な結果をマージするため、ネットワーク転送とコーディネーターのメモリ使用量の両方が削減されます。
EXPLAIN OPTIMIZER SELECT COUNT(*) FROM customer GROUP BY c_nationkey;実行計画は、c_nationkey がシャードキーであるかどうかに応じて異なります。
c_nationkey がシャードキーの場合:

c_nationkey がシャードキーではない場合:

結合のプッシュダウン
結合のプッシュダウンは、結合計算をストレージレイヤーに移動させ、シャード間での並列実行を可能にします。以下の両方の条件を満たす必要があります。
テーブル t1 と t2 が同じシャーディングメソッドを使用していること。つまり、データベースシャーディングキー、テーブルシャーディングキー、シャーディング関数、および Shard Count が同一であること。
結合条件に、t1 と t2 のシャードキー間の等価述語が含まれていること。
両方の条件が満たされる場合、オプティマイザーは結合演算子を LogicalView にプッシュダウンします。
EXPLAIN OPTIMIZER SELECT * FROM t1, t2 WHERE t1.id = t2.id;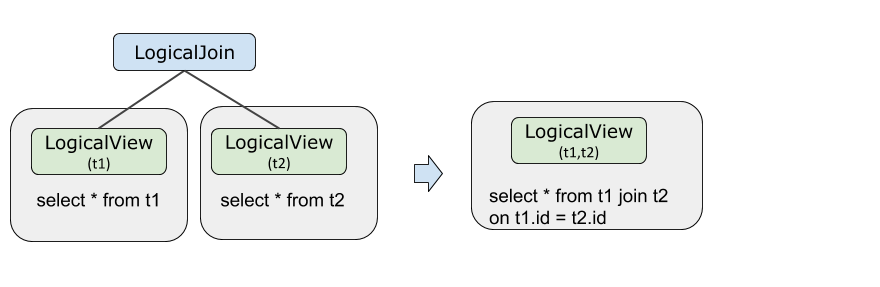
任意のテーブルとブロードキャストテーブル間の結合は、シャーディングメソッドに関係なく常にプッシュダウンされます。これは、ブロードキャストテーブルがそのデータをすべてのシャードにレプリケートするためです。
JoinClustering
クエリが3つ以上のテーブルを結合する場合、すべてのペアがプッシュダウン条件を満たすとは限りません。JoinClustering は結合シーケンスを並べ替え、プッシュダウン可能なペアを隣接する位置に配置することで、ストレージレイヤーで実行される結合の数を最大化します。
EXPLAIN SELECT t2.id FROM t2 JOIN t1 ON t2.id = t1.id JOIN l2 ON t1.id = l2.id;元の結合順序は t2 → t1 → l2 です。JoinClustering 後、t2 と l2 は同じシャーディングメソッドを共有するため隣接して配置され、その結合は LogicalView に一緒にプッシュダウンされます。
Project(id="id")
HashJoin(condition="id = id AND id = id0", type="inner")
Gather(concurrent=true)
LogicalView(tables="t2_[0-3],l2_[0-3]", shardCount=4, sql="SELECT `t2`.`id`, `l2`.`id` AS `id0` FROM `t2` AS `t2` INNER JOIN `l2` AS `l2` ON (`t2`.`id` = `l2`.`id`) WHERE (`t2`.`id` = `l2`.`id`)")
Gather(concurrent=true)
LogicalView(tables="t1", shardCount=2, sql="SELECT `id` FROM `t1` AS `t1`")t2–l2 結合は各シャード内で並列に実行されます。残りの t1 との HashJoin は、t1 が異なるシャーディングメソッドを使用しているため、コーディネーターレイヤーで実行されます。
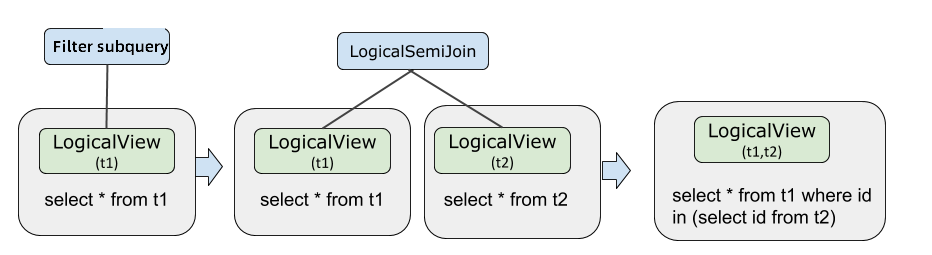
サブクエリのプッシュダウン
サブクエリのプッシュダウンは、サブクエリ実行をストレージレイヤーに移動させ、外部クエリと並行して並列評価を可能にします。
オプティマイザーは3段階のプロセスを使用します。
サブクエリを
Semi JoinまたはAnti Joinに変換します。結合のプッシュダウン条件を適用します。両方の条件が満たされる場合、
Semi JoinまたはAnti JoinをLogicalViewにプッシュダウンします。プッシュダウンされた演算子を最終的な実行計画でサブクエリ形式に戻します。
EXPLAIN OPTIMIZER SELECT * FROM t1 WHERE id IN (SELECT id FROM t2);