このトピックでは、PolarDB for PostgreSQL および のオフピーク時間におけるガベージコレクション機能の使用方法について説明し、使用例を示します。
適用対象
この機能は、PolarDB for PostgreSQL の以下のバージョンでサポートされています。
PostgreSQL 17 (マイナーエンジンバージョン 2.0.17.2.2.1 以降)
PostgreSQL 16 (マイナーエンジンバージョン 2.0.16.8.3.0 以降)
PostgreSQL 15 (マイナーエンジンバージョン 2.0.15.12.4.0 以降)
PostgreSQL 14 (マイナーエンジンバージョン 2.0.14.12.24.0 以降)
PostgreSQL 11 (マイナーエンジンバージョン 2.0.11.15.42.0 以降)
コンソールで、または SHOW polardb_version; 文を実行して、マイナーエンジンバージョンを表示できます。マイナーエンジンバージョンが要件を満たしていない場合は、マイナーエンジンバージョンをアップグレードする必要があります。
背景情報
ネイティブの PostgreSQL と同様に、PolarDB for PostgreSQL および は、バックグラウンドで autovacuum プロセスを開始してガベージコレクションを実行します。これにより、以下のような利点が得られます。
古いデータバージョンを回収してディスク領域の使用量を削減します。
統計情報を更新して、クエリオプティマイザーが最適な実行計画を選択できるようにします。
トランザクション ID の周回を防ぎ、クラスターが利用できなくなるリスクを効果的に低減します。
これらのガベージコレクション操作は、多くのハードウェアリソースを消費します。autovacuum が頻繁に実行されるのを避けるため、ネイティブの PostgreSQL では特定のトリガー条件が設定されています。詳細については、「Autovacuum パラメーター設定」をご参照ください。クリーンアッププロセスは、これらの条件が満たされた場合にのみ開始されます。トリガー条件は変更された行数とデータベース Age に関連しているため、データの変更が頻繁に行われ、トランザクション ID がより速く消費されるビジネスのピーク時間には、autovacuum がより頻繁にトリガーされます。これにより、以下の問題が発生します。
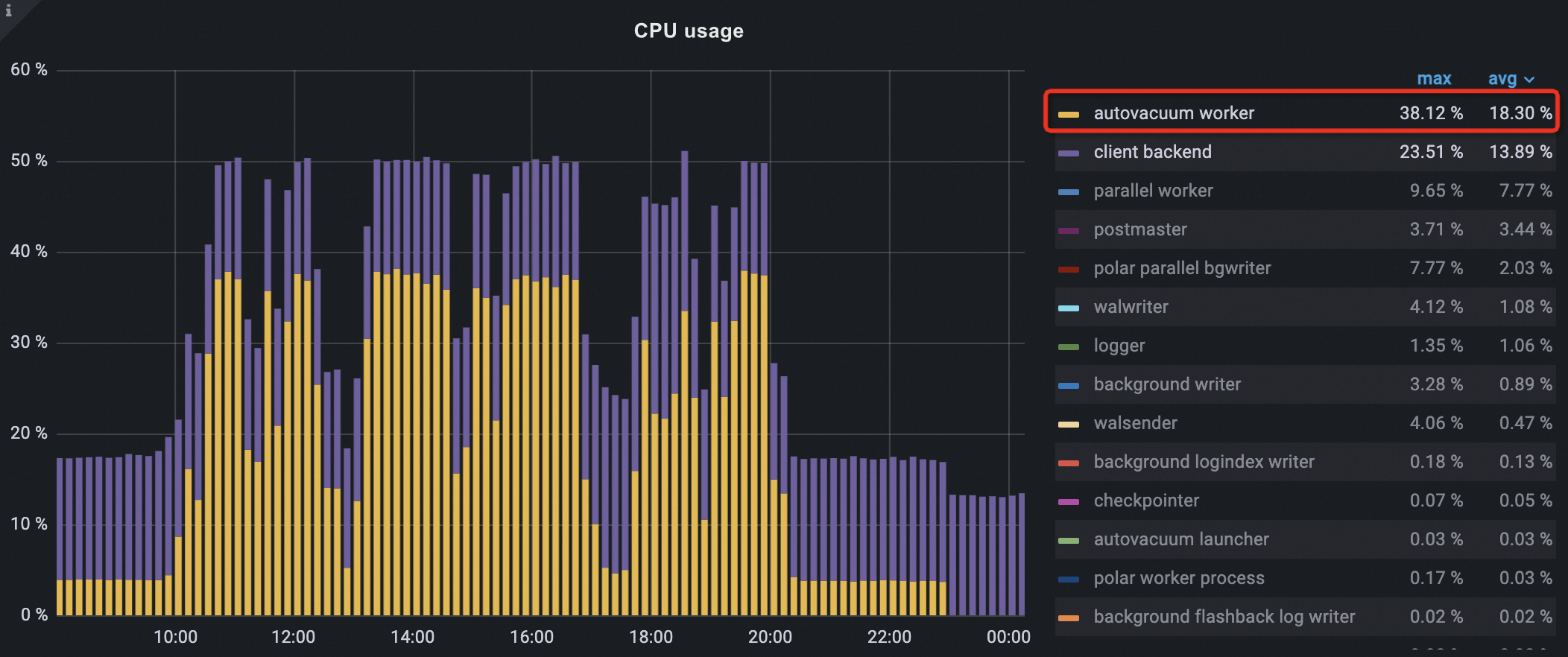
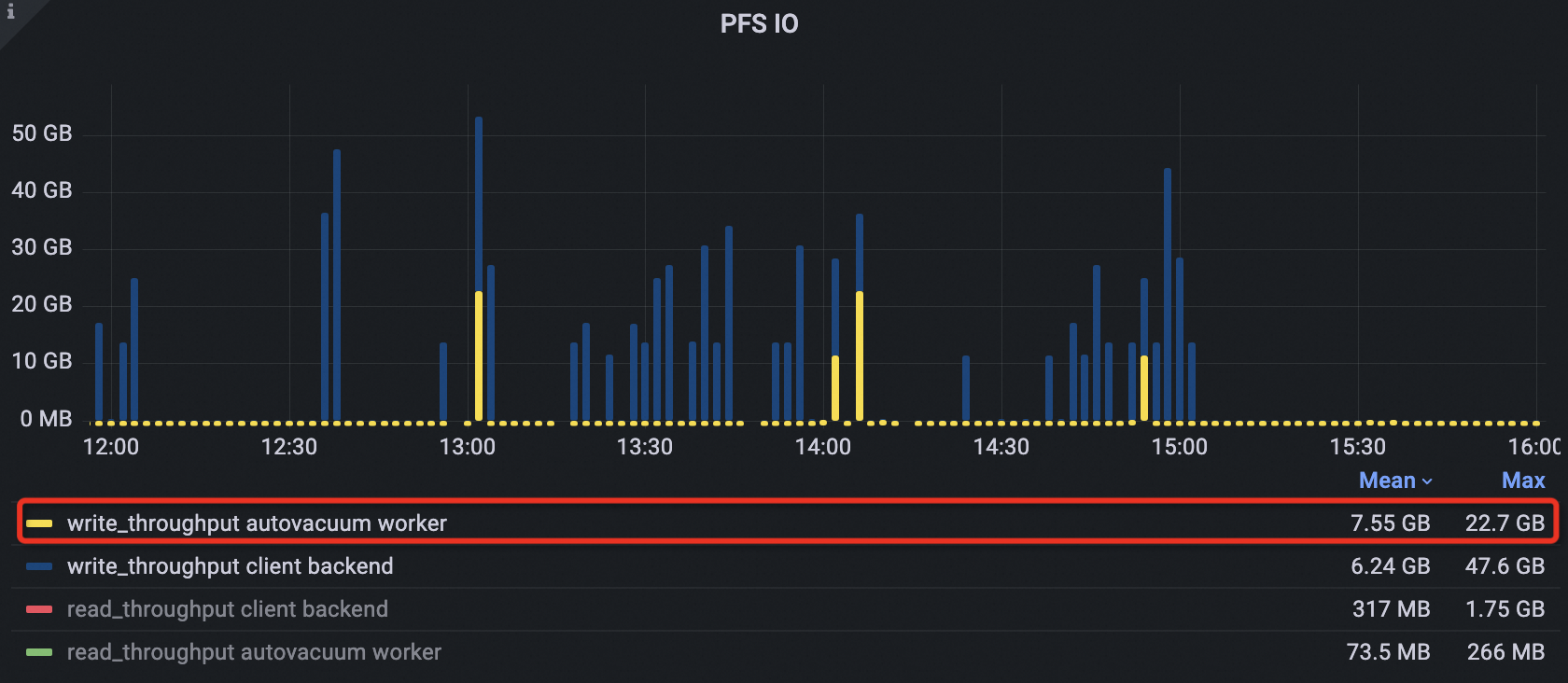
高いリソース使用量:ピーク時間中、autovacuum プロセスは頻繁にガベージコレクションを実行します。これにより、大量の CPU と I/O が消費され、ビジネスの読み取り/書き込みリクエストとハードウェアリソースを競合します。これは、データベースの読み取り/書き込みパフォーマンスに影響します。次の例では、日中のピーク時間において、autovacuum プロセスの CPU 使用率と I/O スループットがすべてのプロセスの中で最も高くなっています。
テーブルロックによる読み取り/書き込みリクエストのブロック:autovacuum プロセスは、空のページを回収する際に排他ロックを短時間保持する必要があります。これにより、単一テーブルに対するビジネスリクエストがブロックされます。ブロック時間は通常短いですが、ビジネスのピーク時間にはわずかな中断でも許容できません。
プランキャッシュの無効化:autovacuum プロセスは統計情報を収集するため、既存のプランキャッシュが無効になる可能性があります。新しいクエリは、実行計画を再生成する必要があります。ピーク時間中、複数の接続が並行して実行計画を生成する可能性があります。これは、複数の接続からのビジネスリクエストの応答時間に影響します。
説明PolarDB for PostgreSQL のグローバルプランキャッシュ (GPC) 機能は、この問題の影響を軽減できます。詳細については、「グローバルプランキャッシュ (GPC)」をご参照ください。
これらの問題の核心は、ネイティブの PostgreSQL にはオフピーク時間という概念がないことですが、実際のビジネスシナリオでは通常、ピーク時間とオフピーク時間が明確に分かれています。PolarDB for PostgreSQL および では、オフピーク時間のタイムウィンドウを設定できます。この機能は、オフピーク時間のアイドル状態のハードウェアリソースを使用して、積極的かつ徹底的なガベージコレクションを実行します。その結果、ピーク時間中の autovacuum の頻度が減少し、ビジネスの読み取り/書き込みリクエストにより多くのハードウェアリソースが割り当てられ、読み取り/書き込みパフォーマンスが最適化されます。
期待される効果
オフピーク時間におけるガベージコレクションは、前述の問題を緩和できます。さらに、オフピーク時間中のクリーンアップ戦略は、ネイティブの PostgreSQL の autovacuum よりも積極的であるため、追加の利点が得られる場合があります。全体的な利点は次のとおりです。
リソース使用率の最適化:ガベージはオフピーク時間中に収集されます。これにより、ピーク時間中に autovacuum がトリガーされる可能性が大幅に減少し、リソース使用量が削減されます。
データベース Age の最適化:オフピーク時間中により多くのトランザクション ID が回収されます。これにより、トランザクション ID の周回によるデータベースの利用不能を防ぎます。
統計情報と低速 SQL 文の最適化:より多くのテーブル統計情報が収集されます。これにより、オプティマイザーがより正確なクエリプランを選択し、古い統計情報による低速 SQL 文の数を減らすのに役立ちます。
テーブルロック問題の軽減:ピーク時間中に autovacuum 操作がテーブルをロックし、ビジネスの読み取り/書き込みリクエストをブロックする可能性が低減されます。
プランキャッシュ無効化の軽減:ピーク時間中に autovacuum 操作がプランキャッシュの無効化を引き起こす可能性が低減されます。
使用方法
「適用対象」セクションに記載されているサポート対象バージョンを実行している場合にのみ、以下の方法を使用して PolarDB for PostgreSQL クラスターのオフピーク期間を設定できます。クラスターが以前のマイナーエンジンバージョンを実行している場合は、まずコンソールで最新のマイナーエンジンバージョンにアップグレードする必要があります。詳細については、「バージョン管理」をご参照ください。
クラスターのマイナーエンジンバージョンをアップグレードせずにオフピーク期間を設定するには、バックエンド構成についてお問い合わせください。オフピーク期間の開始時刻、終了時刻、およびタイムゾーンを提供する必要があります。この方法には制限があります。プライマリ/スタンバイのスイッチオーバー、設定変更、ゾーン切り替えなどの操作により、構成が無効になる場合があります。したがって、これは一時的なソリューションにすぎません。恒久的な設定を行うには、最新のマイナーエンジンバージョンにアップグレードする必要があります。
オフピーク時間情報の設定
プラグインの作成
postgres データベースおよびガベージコレクションを実行する必要があるすべてのデータベースで
polar_advisor拡張機能を作成する必要があります。CREATE EXTENSION IF NOT EXISTS polar_advisor;polar_advisor拡張機能が既にインストールされている PolarDB クラスターの場合は、次のコマンドを実行して更新します。ALTER EXTENSION polar_advisor UPDATE;タイムウィンドウの設定
次のコマンドを実行して、オフピーク期間を設定します。
-- postgres データベースで実行します。 SELECT polar_advisor.set_advisor_window(start_time, end_time);start_time:ウィンドウの開始時刻。
end_time:ウィンドウの終了時刻。
デフォルトでは、ウィンドウは同日に有効になります。その後、ガベージコレクションはこのタイムウィンドウ内で毎日自動的に実行されます。
説明postgres データベースで設定されたタイムウィンドウのみが有効になります。他のデータベースでタイムウィンドウを設定しても効果はありません。
ウィンドウの時刻のタイムゾーンオフセットは、PolarDB クラスターのタイムゾーン設定と一致している必要があります。そうでない場合、タイムウィンドウは有効になりません。
次の例では、UTC+08 タイムゾーンで毎日 23:00 から 02:00 までをオフピーク期間として設定します。クラスターは毎日この期間中にガベージコレクションを実行します。
SELECT polar_advisor.set_advisor_window(start_time => '23:00:00+08', end_time => '02:00:00+08');タイムウィンドウの表示
次のコマンドを実行して、設定されたオフピーク期間に関する情報を表示します。
-- postgres データベースで実行します。 -- オフピーク期間の詳細を表示します。 SELECT * FROM polar_advisor.get_advisor_window(); -- オフピーク期間の長さを秒単位で表示します。 SELECT polar_advisor.get_advisor_window_length(); -- 現在の時刻がオフピーク期間内にあるかどうかを確認します。 SELECT now(), * FROM polar_advisor.is_in_advisor_window(); -- 次のオフピーク期間が開始するまでの残り時間を秒単位で表示します。 SELECT * FROM polar_advisor.get_secs_to_advisor_window_start(); -- 現在のオフピーク期間が終了するまでの残り時間を秒単位で表示します。 SELECT * FROM polar_advisor.get_secs_to_advisor_window_end();以下に例を示します。
-- オフピーク期間の詳細を表示します。 postgres=# SELECT * FROM polar_advisor.get_advisor_window(); start_time | end_time | enabled | last_error_time | last_error_detail | others -------------+-------------+---------+-----------------+-------------------+-------- 23:00:00+08 | 02:00:00+08 | t | | | (1 row) -- オフピーク期間の長さを表示します。 postgres=# SELECT polar_advisor.get_advisor_window_length() / 3600.0 AS "window_duration_hours"; window_duration_hours -------------------- 3.0000000000000000 (1 row) -- 現在の時刻がオフピーク期間内にあるかどうかを確認します。 postgres=# SELECT now(), * FROM polar_advisor.is_in_advisor_window(); now | is_in_advisor_window -------------------------------+---------------------- 2024-04-01 07:40:37.733911+00 | f (1 row) -- 次のオフピーク期間が開始するまでの残り時間を表示します。 postgres=# SELECT * FROM polar_advisor.get_secs_to_advisor_window_start(); secs_to_window_start | time_now | window_start | window_end ----------------------+--------------------+--------------+------------- 26362.265179 | 07:40:37.734821+00 | 15:00:00+00 | 18:00:00+00 (1 row) -- 現在のオフピーク期間が終了するまでの残り時間を表示します。 postgres=# SELECT * FROM polar_advisor.get_secs_to_advisor_window_end(); secs_to_window_end | time_now | window_start | window_end --------------------+--------------------+--------------+------------- 36561.870337 | 07:40:38.129663+00 | 15:00:00+00 | 18:00:00+00 (1 row)ウィンドウの無効化または有効化
ウィンドウを設定すると、デフォルトで有効になり、ガベージコレクションはこのウィンドウ内で毎日実行されます。特定の日にクラスターがオフピーク期間中にガベージコレクションを実行しないようにしたい場合、たとえば、競合を懸念する他の手動操作を実行する場合など、次のコマンドを実行してオフピーク期間を無効にできます。作業が完了したら、コマンドを再度実行してウィンドウを再度有効にできます。
-- postgres データベースで実行します。 -- オフピーク期間中のガベージコレクションを無効にします。 SELECT polar_advisor.disable_advisor_window(); -- オフピーク期間中のガベージコレクションを有効にします。 SELECT polar_advisor.enable_advisor_window(); -- ウィンドウが有効になっているかどうかを確認します。 SELECT polar_advisor.is_advisor_window_enabled();以下に例を示します。
-- ウィンドウが有効です。 postgres=# SELECT polar_advisor.is_advisor_window_enabled(); is_advisor_window_enabled --------------------------- t (1 row) -- ウィンドウを無効にします。 postgres=# SELECT polar_advisor.disable_advisor_window(); disable_advisor_window ------------------------ (1 row) -- ウィンドウが無効です。 postgres=# SELECT polar_advisor.is_advisor_window_enabled(); is_advisor_window_enabled --------------------------- f (1 row) -- ウィンドウを再度有効にします。 postgres=# SELECT polar_advisor.enable_advisor_window(); enable_advisor_window ----------------------- (1 row) -- ウィンドウが有効です。 postgres=# SELECT polar_advisor.is_advisor_window_enabled(); is_advisor_window_enabled --------------------------- t (1 row)
その他の設定
ブラックリストの設定
オフピーク期間を設定すると、データベースはウィンドウ中にどのテーブルでガベージコレクションを実行するかを自動的に決定します。どのテーブルも選択される可能性があります。特定のテーブルが選択されないようにしたい場合は、次のコマンドを実行してブラックリストに追加できます。
-- 特定のビジネスデータベースで実行します。 -- テーブルを VACUUM & ANALYZE ブラックリストに追加します。 SELECT polar_advisor.add_relation_to_vacuum_analyze_blacklist(schema_name, relation_name); -- テーブルが VACUUM & ANALYZE ブラックリストに含まれているかどうかを確認します。 SELECT polar_advisor.is_relation_in_vacuum_analyze_blacklist(schema_name, relation_name); -- VACUUM & ANALYZE ブラックリストを取得します。 SELECT * FROM polar_advisor.get_vacuum_analyze_blacklist();以下に例を示します。
-- public.t1 テーブルをブラックリストに追加します。 postgres=# SELECT polar_advisor.add_relation_to_vacuum_analyze_blacklist('public', 't1'); add_relation_to_vacuum_analyze_blacklist --------------------------- t (1 row) -- テーブルがブラックリストに含まれているかどうかを確認します。 postgres=# SELECT polar_advisor.is_relation_in_vacuum_analyze_blacklist('public', 't1'); is_relation_in_vacuum_analyze_blacklist -------------------------- t (1 row) -- 完全なブラックリストを取得して、テーブルが含まれているかどうかを確認します。 postgres=# SELECT * FROM polar_advisor.get_vacuum_analyze_blacklist(); schema_name | relation_name | action_type -------------+---------------+---------------- public | t1 | VACUUM ANALYZE (1 row)アクティブ接続数のしきい値の設定
オフピーク時間中の GC が通常のビジネス運用に影響を与えないように、システムはアクティブな接続数を自動的にチェックします。アクティブな接続数がしきい値を超えた場合、GC 操作は自動的にキャンセルされます。ビジネス要件に合わせて、このしきい値を手動で調整できます。デフォルトのしきい値は 5 から 10 の間で、クラスター内の CPU コア数によって決まります。
-- postgres データベースで実行します。 -- オフピーク期間の許容可能な接続しきい値を取得します。 実際のアクティブな接続数がこの値より大きい場合、ガベージコレクションは実行されません。 SELECT polar_advisor.get_active_user_conn_num_limit(); -- オフピーク期間中に SQL 文を実行して、実際のアクティブな接続数を取得します。 また、PolarDB コンソールでパフォーマンスモニタリング > 高度なモニタリング > 標準ビュー > セッション接続に移動して、active_session メトリックを表示することもできます。 SELECT COUNT(*) FROM pg_catalog.pg_stat_activity sa JOIN pg_catalog.pg_user u ON sa.usename = u.usename WHERE sa.state = 'active' AND sa.backend_type = 'client backend' AND NOT u.usesuper; -- アクティブな接続のしきい値を手動で設定します。 これにより、システムのデフォルトがオーバーライドされます。 SELECT polar_advisor.set_active_user_conn_num_limit(active_user_conn_limit); -- アクティブな接続のしきい値の設定を解除して、システムのデフォルトを復元します。 SELECT polar_advisor.unset_active_user_conn_num_limit();例えば:
-- インスタンスのデフォルトのアクティブな接続のしきい値を取得します。このインスタンスのしきい値は 5 です。しきい値は、CPU コア数に基づいてインスタンスごとに異なる場合があります。 postgres=# SELECT polar_advisor.get_active_user_conn_num_limit(); NOTICE: get active user conn limit by CPU cores number get_active_user_conn_num_limit -------------------------------- 5 (1 row) -- 現在のアクティブな接続数を取得します。結果は 8 で、しきい値の 5 を超えています。システムはアクティブな接続数が高いと判断し、GC を実行しません。 postgres=# SELECT COUNT(*) FROM pg_catalog.pg_stat_activity sa JOIN pg_catalog.pg_user u ON sa.usename = u.usename postgres-# WHERE sa.state = 'active' AND sa.backend_type = 'client backend' AND NOT u.usesuper; count ------- 8 (1 row) -- アクティブな接続のしきい値を 10 に設定します。これは、実際のアクティブな接続数 (8) よりも大きいです。システムは、実際の接続数がしきい値を超えていないと判断するため、GC を実行できます。 postgres=# SELECT polar_advisor.set_active_user_conn_num_limit(10); set_active_user_conn_num_limit -------------------------------- (1 row) -- アクティブな接続のしきい値を表示します。値は 10 で、前のステップで手動で設定されたものです。 postgres=# SELECT polar_advisor.get_active_user_conn_num_limit(); NOTICE: get active user conn limit from table get_active_user_conn_num_limit -------------------------------- 10 (1 row) -- アクティブな接続のしきい値の設定を解除します。 postgres=# SELECT polar_advisor.unset_active_user_conn_num_limit(); unset_active_user_conn_num_limit ---------------------------------- (1 row) -- 設定を解除すると、アクティブな接続のしきい値はデフォルト値の 5 に復元されます。 postgres=# SELECT polar_advisor.get_active_user_conn_num_limit(); NOTICE: get active user conn limit by CPU cores number get_active_user_conn_num_limit -------------------------------- 5 (1 row)
結果の表示
オフピーク期間中に実行されたガベージコレクション操作の結果と効果は、postgres データベースのログテーブルに記録されます。ログは過去 90 日間のデータを保持します。
テーブルスキーマ
polar_advisor.db_level_advisor_log テーブルには、各ラウンドのデータベースレベルのガベージコレクションに関する情報が格納されます。
CREATE TABLE polar_advisor.db_level_advisor_log (
id BIGSERIAL PRIMARY KEY,
exec_id BIGINT,
start_time TIMESTAMP WITH TIME ZONE,
end_time TIMESTAMP WITH TIME ZONE,
db_name NAME,
event_type VARCHAR(100),
total_relation BIGINT,
acted_relation BIGINT,
age_before BIGINT,
age_after BIGINT,
others JSONB
);説明:
パラメーター名 | 説明 |
id | テーブルのプライマリキー。自動増分します。 |
exec_id | 実行ラウンド。通常、1 日に 1 ラウンド実行されます。1 ラウンドで複数のデータベースを操作できるため、同日の複数のレコードは同じ |
start_time | 操作の開始時刻。 |
end_time | 操作の終了時刻。 |
db_name | 操作対象のデータベースの名前。 |
event_type | 操作タイプ。現在、 |
total_relation | 操作可能なテーブルとインデックスの数。 |
acted_relation | 実際に操作されたテーブルとインデックスの数。 |
age_before | 操作前のデータベース Age。 |
age_after | 操作後のデータベース Age。 |
others | 拡張統計データが含まれます。
|
polar_advisor.advisor_log テーブルには、各テーブルレベルまたはインデックスレベルのガベージコレクション操作に関する詳細情報が格納されます。polar_advisor.db_level_advisor_log テーブルの 1 つのレコードは、polar_advisor.advisor_log テーブルの複数のレコードに対応します。
CREATE TABLE polar_advisor.advisor_log (
id BIGSERIAL PRIMARY KEY,
exec_id BIGINT,
start_time TIMESTAMP WITH TIME ZONE,
end_time TIMESTAMP WITH TIME ZONE,
db_name NAME,
schema_name NAME,
relation_name NAME,
event_type VARCHAR(100),
sql_cmd TEXT,
detail TEXT,
tuples_deleted BIGINT,
tuples_dead_now BIGINT,
tuples_now BIGINT,
pages_scanned BIGINT,
pages_pinned BIGINT,
pages_frozen_now BIGINT,
pages_truncated BIGINT,
pages_now BIGINT,
idx_tuples_deleted BIGINT,
idx_tuples_now BIGINT,
idx_pages_now BIGINT,
idx_pages_deleted BIGINT,
idx_pages_reusable BIGINT,
size_before BIGINT,
size_now BIGINT,
age_decreased BIGINT,
others JSONB
);説明:
パラメーター | 説明 |
id | テーブルのプライマリキー。自動増分します。 |
exec_id | 実行ラウンド。通常、1 日に 1 ラウンド実行されます。1 ラウンドで複数のデータベースを操作できるため、同日の複数のレコードは同じ |
start_time | 操作の開始時刻。 |
end_time | 操作の終了時刻。 |
db_name | 操作対象のデータベースの名前。 |
schema_name | 操作対象のデータベーススキーマの名前。 |
relation_name | 操作対象のデータベーステーブルまたはインデックスの名前。 |
event_type | 操作タイプ。現在、 |
sql_cmd | 実行された特定のコマンド。例: |
detail | 操作の詳細な結果。例: |
tuples_deleted | この操作でテーブルから回収されたデッドタプルの数。 |
tuples_dead_now | この操作後にテーブルに残っているデッドタプルの数。 |
tuples_now | この操作後のテーブル内のライブタプルの数。 |
pages_scanned | この操作中にスキャンされたページ数。 |
pages_pinned | 他のセッションによってピン留めされていたため削除できなかったページ数。 |
pages_frozen_now | この操作後に凍結されたページ数。 |
pages_truncated | この操作中に削除または切り捨てられた空のページ数。 |
pages_now | この操作後のテーブル内のページ数。 |
idx_tuples_deleted | この操作中に回収されたデッドインデックスタプルの数。 |
idx_tuples_now | この操作後のインデックス内のライブタプルの数。 |
idx_pages_now | この操作後のインデックス内のページ数。 |
idx_pages_deleted | この操作中に削除されたインデックスページ数。 |
idx_pages_reusable | この操作後の再利用可能なインデックスページ数。 |
size_before | この操作前のテーブルまたはインデックスのサイズ。 |
size_after | この操作後のテーブルまたはインデックスのサイズ。 |
age_decreased | この操作によるテーブル Age の減少量。 |
others | 拡張統計データ。 |
統計データ
最近の各ガベージコレクションラウンドの開始時刻、終了時刻、および操作されたテーブルとインデックスの数を表示します。以下に例を示します。
-- postgres データベースで実行します。 SELECT COUNT(*) AS "table_index_count", MIN(start_time) AS "start_time", MAX(end_time) AS "end_time", exec_id AS "round" FROM polar_advisor.advisor_log GROUP BY exec_id ORDER BY exec_id DESC;結果は、過去 3 回のラウンドで、約 4,390 のテーブルでガベージコレクションが実行され、操作は 01:00 から 04:00 の間に実行されたことを示しています。
table_index_count | start_time | end_time | round -------------------+--------------------------------+--------------------------------+------ 4391 | 2024-09-23 01:00:09.413901 +08 | 2024-09-23 03:25:39.029702 +08 | 139 4393 | 2024-09-22 01:03:07.365759 +08 | 2024-09-22 03:37:45.227067 +08 | 138 4393 | 2024-09-21 01:03:08.094989 +08 | 2024-09-21 03:45:20.280011 +08 | 137最近、日付別にグループ化された、毎日ガベージコレクションが行われたテーブル/インデックスの数を表示します。以下に例を示します。
-- postgres データベースで実行します。 SELECT start_time::pg_catalog.date AS "date", count(*) AS "table_index_count" FROM polar_advisor.advisor_log GROUP BY start_time::pg_catalog.date ORDER BY start_time::pg_catalog.date DESC, count(*) DESC;結果は、過去 3 日間、毎日約 4,390 のテーブルでガベージコレクションが実行されたことを示しています。
date | table_index_count ------------+------------------- 2024-09-23 | 4391 2024-09-22 | 4393 2024-09-21 | 4393最近、日付とデータベース別にグループ化された、ガベージコレクションが行われたテーブル/インデックスの数を表示します。以下に例を示します。
-- postgres データベースで実行します SELECT start_time::pg_catalog.date AS "Time", count(*) AS "Table/Index Count" FROM polar_advisor.advisor_log GROUP BY start_time::pg_catalog.date ORDER BY start_time::pg_catalog.date DESC, count(*) DESC;結果は、過去 3 日間にわたって postgres、db_123、db_12345、および db_123456789 データベースでガベージコレクションが実行されたことを示しています。データベースごとに操作されたテーブル/インデックスの数は、数十から数百の範囲でした。
date | db | table_index_count -------------+----------------+------------------- 2024-03-05 | db_123456789 | 697 2024-03-05 | db_123 | 277 2024-03-04 | db_123456789 | 695 2024-03-04 | db_123 | 267 2024-03-04 | db_12345 | 174 2024-03-03 | postgres | 65 (6 rows)
詳細データ
最近ガベージコレクションが行われたデータベースの利益情報を表示します。以下に例を示します。
-- postgres データベースで実行します。 SELECT id, start_time AS "start_time", end_time AS "end_time", db_name AS "database", event_type AS "operation_type", total_relation AS "total_relations_in_db", acted_relation AS "operated_relations", CASE WHEN others->>'cluster_age_before' IS NOT NULL AND others->>'cluster_age_after' IS NOT NULL THEN (others->>'cluster_age_before')::BIGINT - (others->>'cluster_age_after')::BIGINT ELSE NULL END AS "age_reduction", CASE WHEN others->>'db_size_before' IS NOT NULL AND others->>'db_size_after' IS NOT NULL THEN (others->>'db_size_before')::BIGINT - (others->>'db_size_after')::BIGINT ELSE NULL END AS "storage_reduction" FROM polar_advisor.db_level_advisor_log ORDER BY id DESC;結果は、最後の 3 つの操作がすべて
VACUUM操作であったことを示しています。id | start_time | end_time | database | operation_type | total_relations_in_db | operated_relations | age_reduction | storage_reduction ---------+-------------------------------+-------------------------------+----------------+----------+----------------+--------------+----------+-------------- 1184 | 2024-03-05 00:44:26.776894+08 | 2024-03-05 00:45:56.396519+08 | db_12345 | VACUUM | 174 | 164 | 694 | 0 1183 | 2024-03-05 00:43:30.243505+08 | 2024-03-05 00:44:26.695602+08 | db_123456789 | VACUUM | 100 | 90 | 396 | 0 1182 | 2024-03-05 00:41:47.70952+08 | 2024-03-05 00:43:30.172527+08 | db_12345 | VACUUM | 163 | 153 | 701 | 0 (3 rows)最近ガベージコレクションが行われたテーブルの利益情報を表示します。以下に例を示します。
-- postgres データベースで実行します。 SELECT start_time AS "start_time", end_time AS "end_time", db_name AS "database", schema_name AS "schema", relation_name AS "table_index", event_type AS "operation_type", tuples_deleted AS "reclaimed_dead_tuples", pages_scanned AS "pages_scanned",pages_truncated AS "pages_truncated", idx_tuples_deleted AS "reclaimed_index_dead_tuples", idx_pages_deleted AS "reclaimed_index_pages", age_decreased AS "table_age_reduction" FROM polar_advisor.advisor_log ORDER BY id DESC;結果は、回収されたデッドタプルの数、回収されたページ数、最後の 3 つの操作のテーブル Age 削減量などの情報を示しています。
start_time | end_time | database | schema | table_index | operation_type | reclaimed_dead_tuples | pages_scanned | pages_truncated | reclaimed_index_dead_tuples | reclaimed_index_pages | table_age_reduction -------------------------------+-------------------------------+----------+--------+--------+---------+------------+---------+---------+---------------+------------+------------ 2024-03-05 00:45:56.204254+08 | 2024-03-05 00:45:56.357263+08 | db_12345 | public | cccc | VACUUM | 0 | 33 | 0 | 0 | 0 | 1345944 2024-03-05 00:45:56.068499+08 | 2024-03-05 00:45:56.200036+08 | db_12345 | public | aaaa | VACUUM | 0 | 28 | 0 | 0 | 0 | 1345946 2024-03-05 00:45:55.945677+08 | 2024-03-05 00:45:56.065316+08 | db_12345 | public | bbbb | VACUUM | 0 | 0 | 0 | 0 | 0 | 1345947 (3 rows)データベース Age の削減量が最も大きい操作レコードを表示します。
PolarDB for PostgreSQL および は、約 21 億の利用可能なトランザクション ID を持っています。データベース Age は、消費されたトランザクション ID の数を測定します。Age が 21 億に達すると、トランザクション ID の周回イベントが発生し、データベースは利用できなくなります。したがって、データベース Age は低いほど良いです。
-- postgres データベースで実行します。 -- インスタンス Age の削減量が最も大きいデータベースと操作タイプのレコードを取得します。 SELECT id, exec_id AS "round", start_time AS "start_time", end_time AS "end_time", db_name AS "database", event_type AS "operation_type", CASE WHEN others->>'cluster_age_before' IS NOT NULL AND others->>'cluster_age_after' IS NOT NULL THEN (others->>'cluster_age_before')::BIGINT - (others->>'cluster_age_after')::BIGINT ELSE NULL END AS "age_reduction" FROM polar_advisor.db_level_advisor_log ORDER BY "age_reduction" DESC NULLS LAST; -- 前のステップのラウンド情報に基づいて、そのラウンドでデータベース Age の削減を引き起こした詳細なレコードを取得します。 SELECT id, start_time AS "start_time", end_time AS "end_time", db_name AS "database", schema_name AS "schema", relation_name AS "table_name", sql_cmd AS "command", event_type AS "operation_type", age_decreased AS "age_reduction" FROM polar_advisor.advisor_log WHERE exec_id = 91 ORDER BY "age_reduction" DESC NULLS LAST; -- 現在のデータベース Age を取得します。これはどのデータベースでも実行できます。PolarDB コンソールの [パフォーマンスモニタリング] > [高度なモニタリング] > [標準ビュー] > [Vacuum] で db_age メトリックを表示することもできます。 SELECT MAX(pg_catalog.age(datfrozenxid)) AS "instance_age" FROM pg_catalog.pg_database;結果の例を次に示します。
-- 2024-02-22 に、「aaaaaaaaaaaaa」データベースに対する vacuum 操作により、データベース Age が 9,275,406 (約 1,000 万) 減少しました。実行ラウンドは 91 でした。 postgres=# SELECT id, exec_id AS "round", start_time AS "start_time", end_time AS "end_time", db_name AS "database", event_type AS "operation_type", CASE WHEN others->>'cluster_age_before' IS NOT NULL AND others->>'cluster_age_after' IS NOT NULL THEN (others->>'cluster_age_before')::BIGINT - (others->>'cluster_age_after')::BIGINT ELSE NULL END AS "age_reduction" FROM polar_advisor.db_level_advisor_log ORDER BY "age_reduction" DESC NULLS LAST; id | round | start_time | end_time | database | operation_type | age_reduction --------+------+-------------------------------+-------------------------------+---------------+----------+---------- 259 | 91 | 2024-02-22 00:00:18.847978+08 | 2024-02-22 00:14:18.785085+08 | aaaaaaaaaaaaa | VACUUM | 9275406 256 | 90 | 2024-02-21 00:00:39.607552+08 | 2024-02-21 00:00:42.054733+08 | bbbbbbbbbbbbb | VACUUM | 7905122 262 | 92 | 2024-02-23 00:00:05.999423+08 | 2024-02-23 00:00:08.411993+08 | postgres | VACUUM | 578308 -- 実行ラウンド 91 の詳細な vacuum レコードを取得します。結果は、データベース Age の削減が主に一部の pg_catalog システムテーブルに対する vacuum 操作によるものであることを示しています。 postgres=# SELECT id, start_time AS "start_time", end_time AS "end_time", db_name AS "database", schema_name AS "schema", relation_name AS "table_name", event_type AS "operation_type", age_decreased AS "age_reduction" FROM polar_advisor.advisor_log WHERE exec_id = 91 ORDER BY "age_reduction" DESC NULLS LAST; id | start_time | end_time | database | schema | table_name | operation_type | age_reduction ----------+-------------------------------+-------------------------------+-------+------------+--------------------+---------+---------- 43933 | 2024-02-22 00:00:19.070493+08 | 2024-02-22 00:00:19.090822+08 | abc | pg_catalog | pg_subscription | VACUUM | 27787409 43935 | 2024-02-22 00:00:19.116292+08 | 2024-02-22 00:00:19.13875+08 | abc | pg_catalog | pg_database | VACUUM | 27787408 43936 | 2024-02-22 00:00:19.140992+08 | 2024-02-22 00:00:19.171938+08 | abc | pg_catalog | pg_db_role_setting | VACUUM | 27787408 -- 現在のインスタンス Age は 2,000 万を超えており、21 億のしきい値からは程遠いです。インスタンスは非常に安全です。 postgres=> SELECT MAX(pg_catalog.age(datfrozenxid)) AS "instance_age" FROM pg_catalog.pg_database; instance_age ---------- 20874380 (1 row)
最適化効果の例
このセクションでは、オフピーク期間が設定された後の一部のクラスターにおけるリソース使用量とデータベース Age の最適化効果を示します。
テーブルロックによる読み取り/書き込み操作のブロックやプランキャッシュの無効化などの問題に対する最適化効果は、チャートで示すのが容易ではないため、ここでは表示しません。
すべてのクラスターが例に示すような同じ最適化効果を達成できるわけではありません。実際の効果は、特定のビジネスシナリオに依存します。いくつかの理由で改善が顕著でない場合があります。たとえば、一部のクラスターは一日中ビジーで、明確なオフピーク期間がありません。他のクラスターでは、データ分析、データインポート、マテリアライズドビューのリフレッシュなどのタスクがオフピーク期間中にスケジュールされており、ガベージコレクションのためのアイドルリソースがほとんど残っていない場合があります。
メモリ使用量の最適化効果
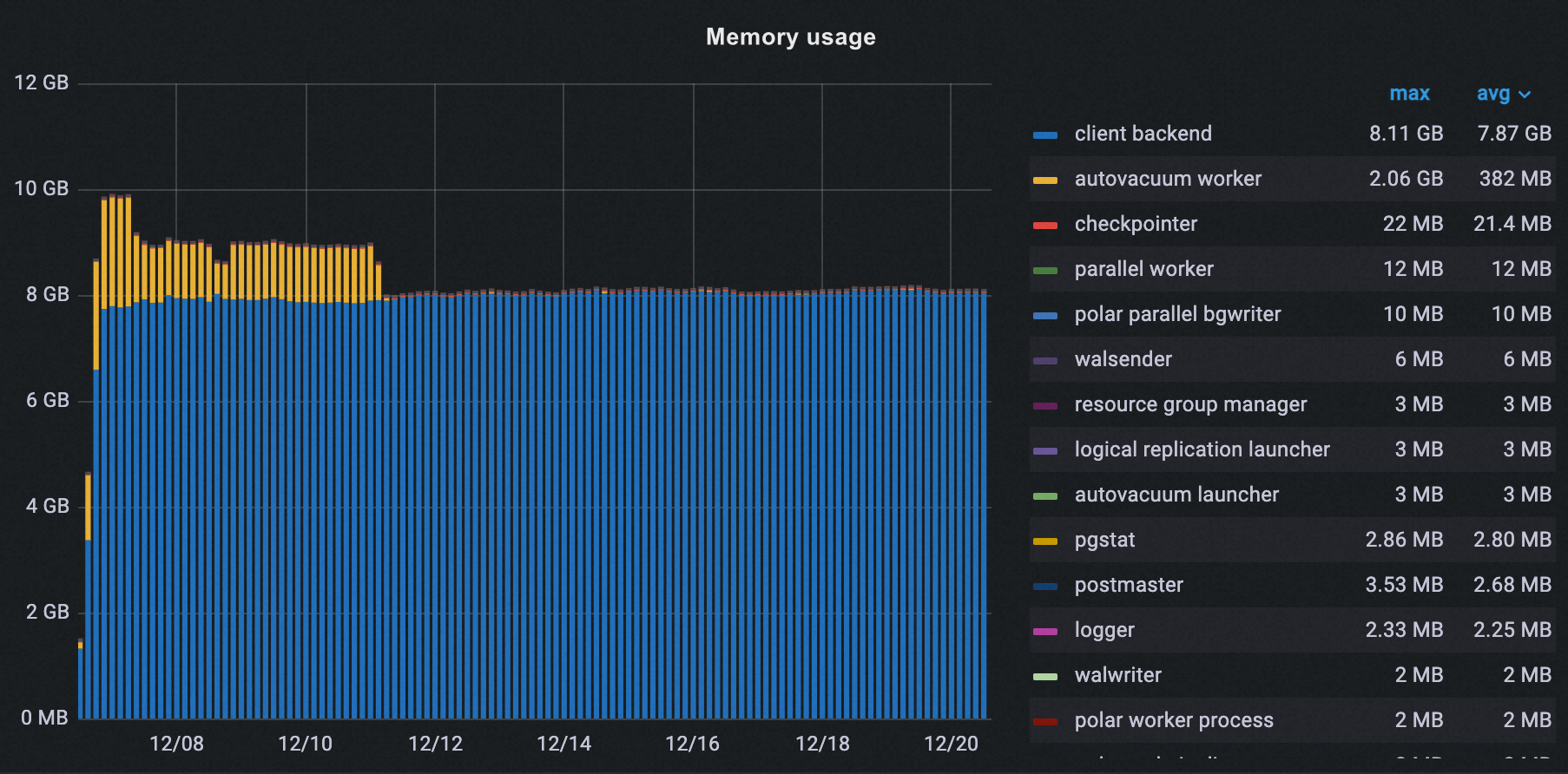
次の図に示すように、オフピーク期間のガベージコレクションを設定した後、クラスターの autovacuum プロセスのピークメモリ使用量は 2.06 GB から 37 MB に減少し、98% の削減となりました。
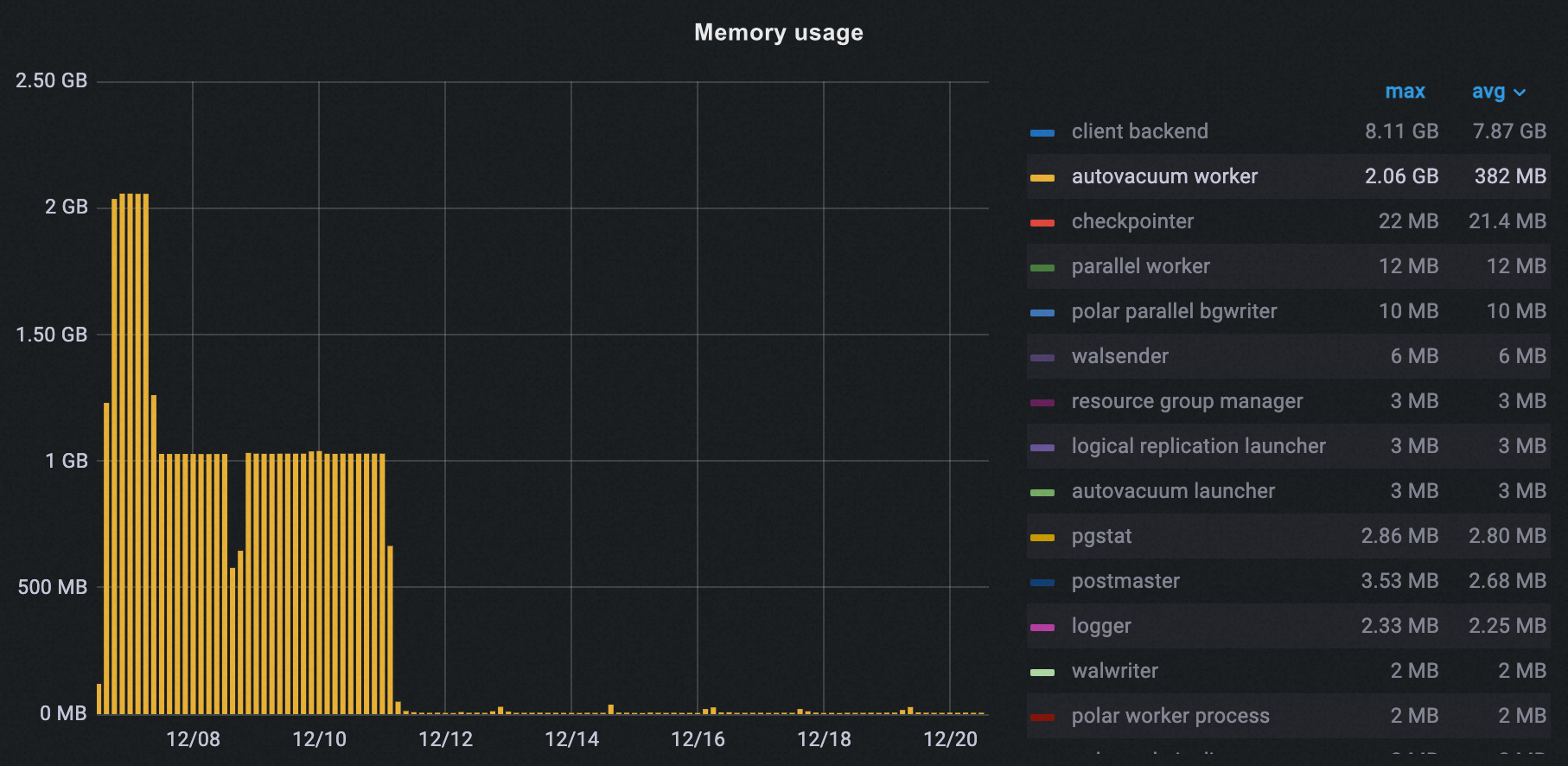
すべてのプロセスの合計ピークメモリ使用量も 10 GB から 8 GB に減少し、20% の削減となりました。
I/O 使用量の最適化効果
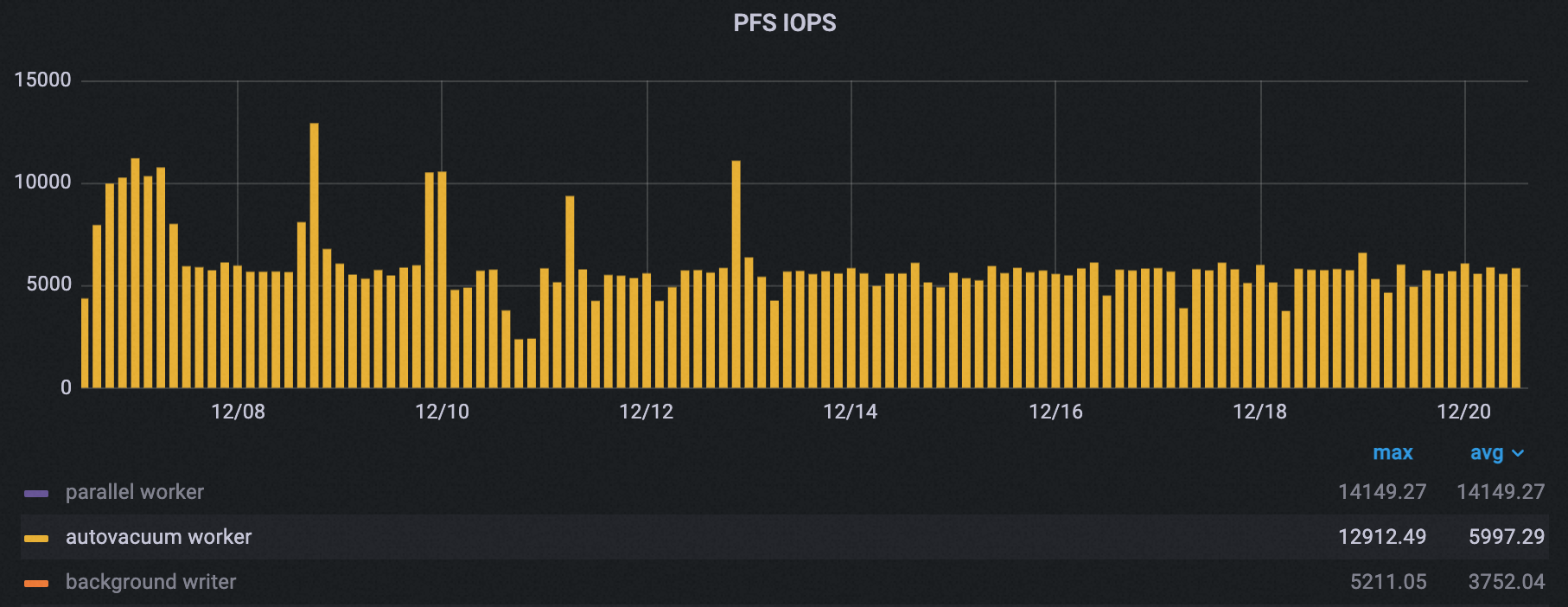
次の図に示すように、オフピーク期間が設定された後、クラスターの autovacuum プロセスのピーク PFS IOPS は約 50% 削減されました。
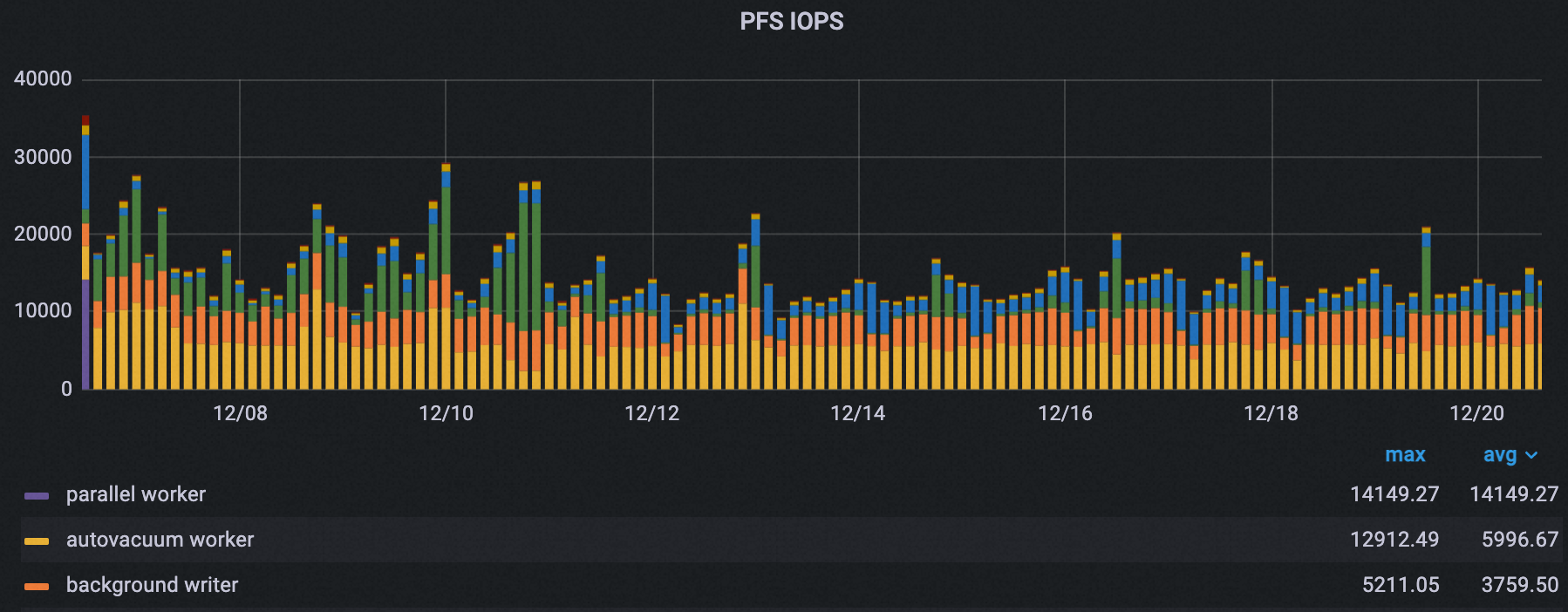
すべてのプロセスの合計ピーク PFS IOPS も 35,000 から約 21,000 に減少し、約 40% の削減となりました。
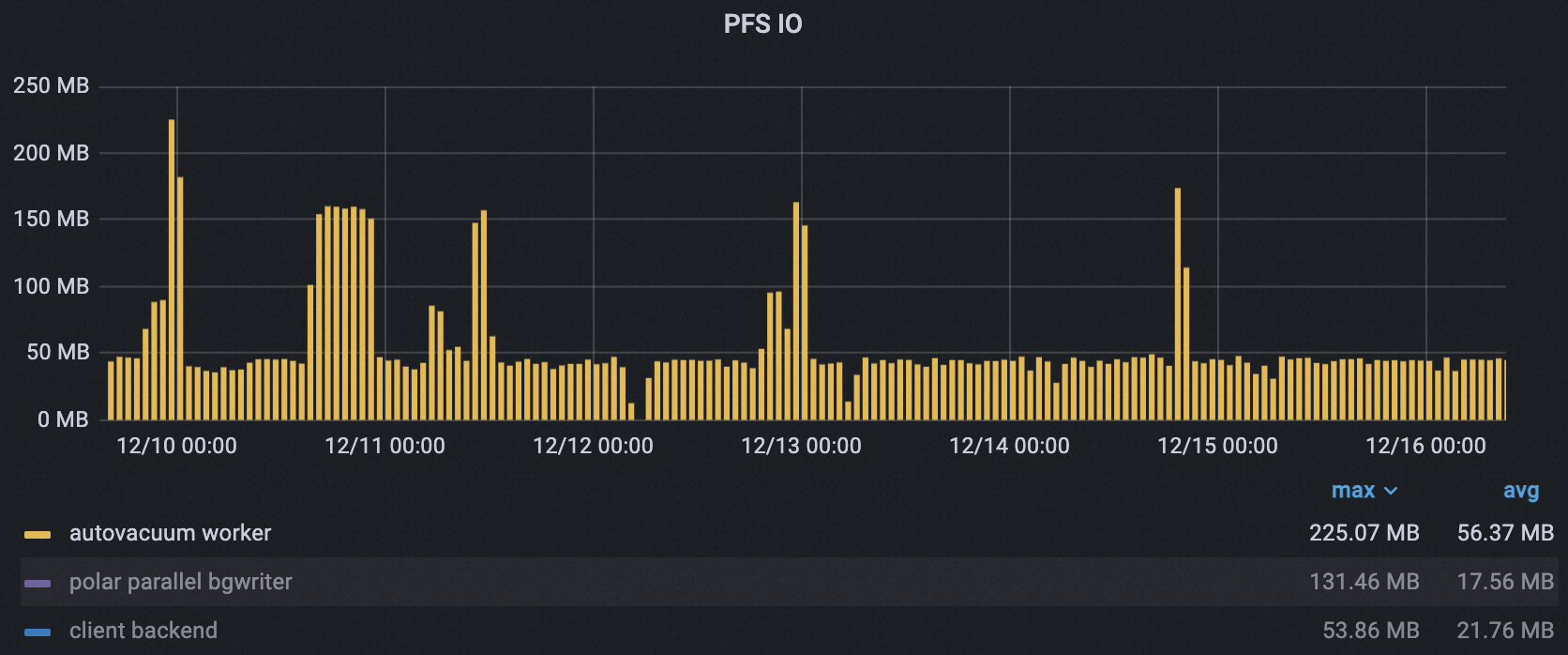
autovacuum プロセスのピーク PFS I/O スループットは 225 MB から 173 MB に減少し、23% の削減となりました。ピークの幅と数も大幅に減少しました。平均スループットは 65.5 MB から 42.5 MB に減少し、35% の削減となりました。
CPU 使用率の最適化効果
次の図に示すように、オフピーク期間が設定された後、クラスターの autovacuum プロセスの CPU 使用率は徐々に減少し、ピーク時の削減率は約 50% でした。
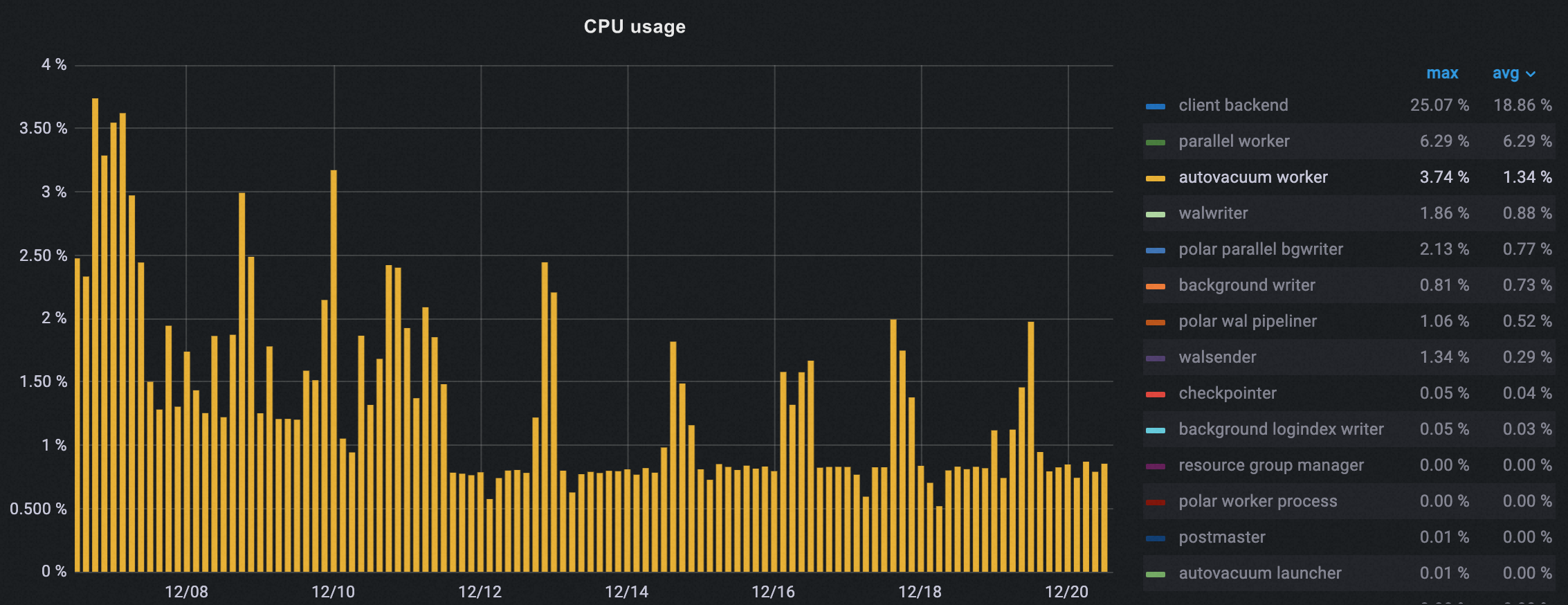
autovacuum プロセス数の最適化効果
次の図に示すように、オフピーク期間が設定された後、クラスター内の autovacuum プロセスの数は 2 から 1 に減少しました。
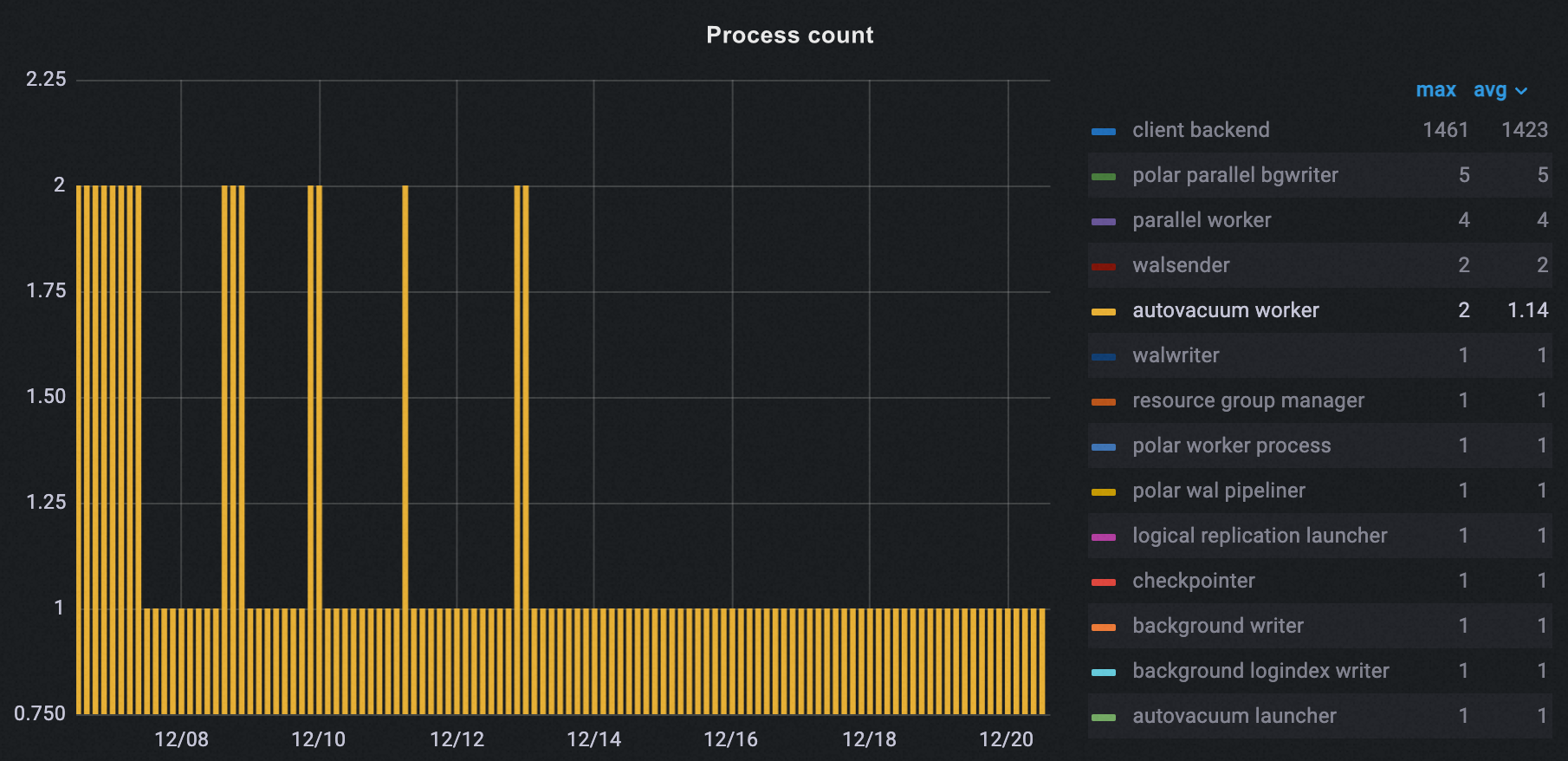
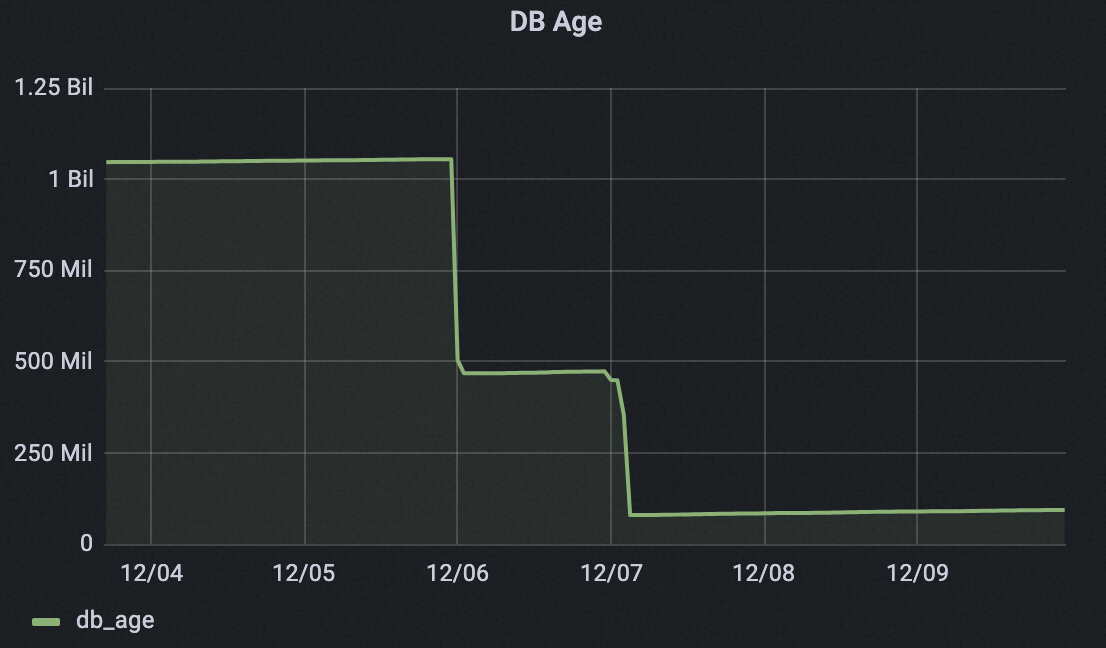
データベース Age の最適化効果
次の図に示すように、オフピーク期間を設定してから 2 日以内に、クラスターは 10 億を超えるトランザクション ID を回収しました。データベース Age は 10 億以上から 1 億未満に低下し、トランザクション ID の周回リスクが大幅に減少しました。