本ガイドでは、Amazon DynamoDB から PolarDB for PostgreSQL へのデータ移行に必要な手順とベストプラクティスを詳しく説明します。PolarDB は、フル同期と増分同期を統合した専用の移行ツール群を提供しており、ダウンタイムを最小限に抑えながらスムーズな移行を実現します。
移行の概要
移行プロセスは主に 5 段階に分けられ、以下の 3 つのコアツールが連携して実行されます:nimo-shake(データ同期:フル同期および増分同期を含む)、nimo-full-check(データ検証)、および PolarDBBackSync(逆同期)。
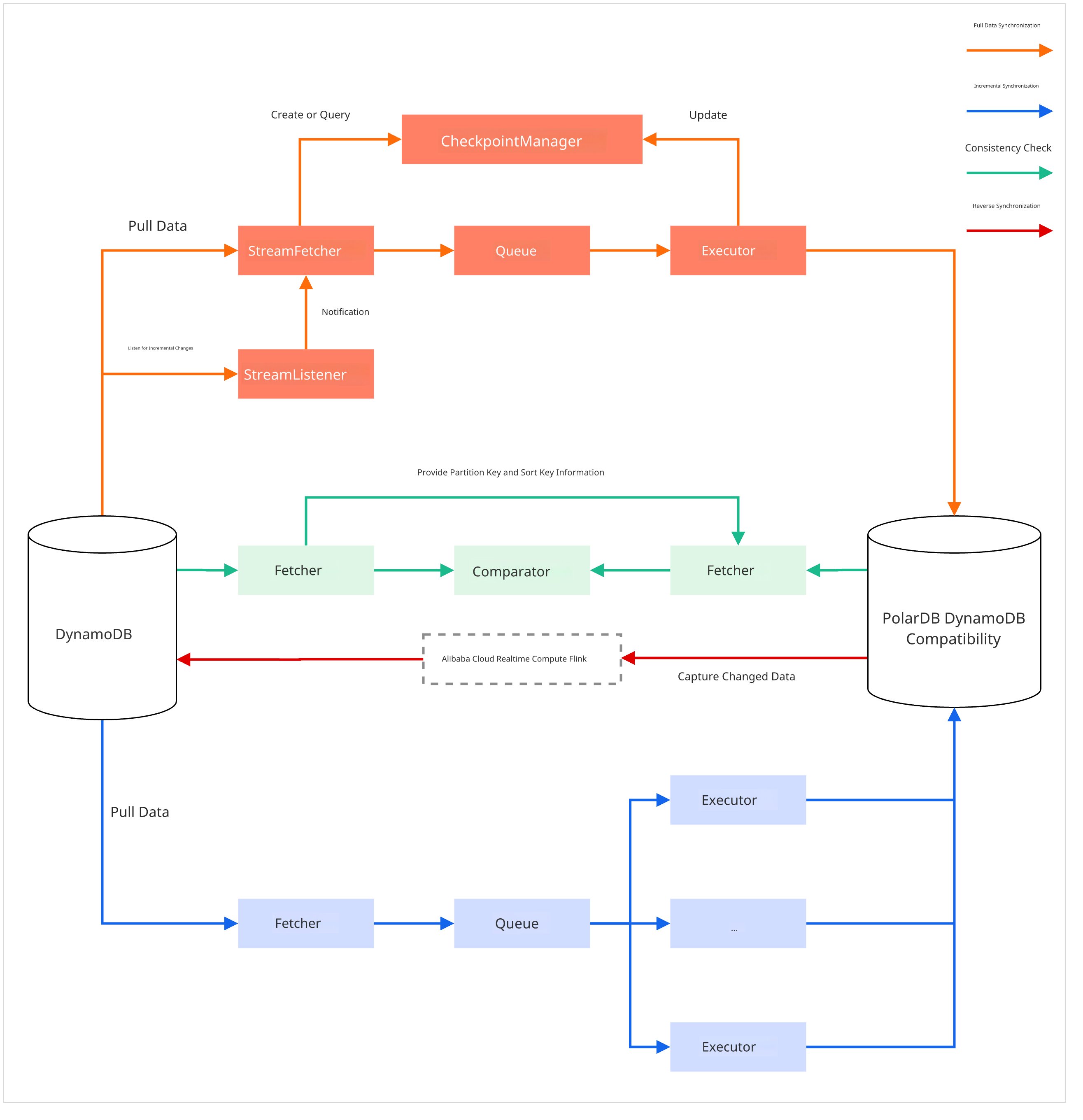
フル同期
ツール:
nimo-shake処理内容:ツールはまず、ソース側と同一のテーブル構造をターゲットの PolarDB クラスター内に自動的に作成します。その後、並列実行される
Scan操作によりソースデータベースから全データを効率よく読み込み、BatchWriteItemを使用してバッチ単位でターゲットクラスターへ書き込みます。
増分同期
ツール:
nimo-shake処理内容:フル同期完了後、ツールは AWS DynamoDB Streams を自動的に活用し、移行開始以降のソース側におけるすべてのデータ変更(挿入、削除、更新)をキャプチャします。これらの変更はターゲットクラスターへ適用され、最終的なデータ整合性を保証します。このプロセスは再開可能な転送をサポートします。
整合性チェック
ツール:
nimo-full-check処理内容:データ同期中または同期後にいつでもこのツールを実行できます。ツールはソースおよびターゲットから並列にデータを読み取り、プライマリキーに基づいて比較を行い、データ整合性を検証するための詳細な差分レポートを生成します。
(任意)逆同期
ツール:
PolarDBBackSync.jar(Realtime Compute for Apache Flink を基盤とする)処理内容:データ整合性の検証が完了した後、ロールバック時のデータ整合性を確保するために、PolarDB for PostgreSQL からソースの DynamoDB へ向けて逆同期タスクを設定できます。このツールは Flink を使用してソースの PolarDB クラスターからリアルタイムの変更をキャプチャし、変更タイプに応じて
PutItemまたはDeleteItem操作を用いて DynamoDB へ適用します。
ビジネスカットオーバー
処理内容:増分データの遅延がほぼゼロとなり、整合性チェックで差分が検出されない状態になった時点で、アプリケーションによる書き込みを一時停止します。残りのデータの同期が完了した後、アプリケーション接続先を PolarDB クラスターへ切り替えることで、移行を完了します。
注意事項
パフォーマンスへの影響:移行は非ピーク時間帯に実施し、事前にデータベースの容量を評価してください。
セキュリティ設定:ビジネスカットオーバー前に、ターゲットの PolarDB クラスターに対する書き込み権限を制御してください。誤ったデータ汚染を防ぐため、データ同期ツール専用のアカウントに対してのみ書き込み権限を付与してください。
前提条件
移行を開始する前に、以下の準備を完了していることを確認してください。
ツールパッケージの入手:
移行ツールパッケージ:NimoShake.tar.gz。このパッケージには
nimo-shakeおよびnimo-full-checkの各ツールが含まれています。(任意)逆移行ツールパッケージ:PolarDBBackSync.jar。
PolarDB クラスター:
既存または新規のクラスターにおいて、DynamoDB 互換機能を有効化、DynamoDB エンドポイントを取得、および 専用の DynamoDB アカウントを作成して、API アクセス用のアクセス認証情報(AccessKey)を取得してください。
(任意)パラメーター設定:必要に応じて 逆同期の構成を行う場合、PolarDB クラスターの
wal_levelパラメーターをlogicalに変更する必要があります。このパラメーター変更にはクラスターの再起動が必要であるため、全体の移行プロセス開始前に設定を完了することを推奨します。
AWS DynamoDB:
AWS DynamoDB 用のアクセス認証情報(AccessKey ID および Secret Access Key)を取得してください。
実行環境:移行ツールを実行するため、PolarDB クラスターおよび AWS DynamoDB の両方に接続可能な ECS インスタンスまたはその他のサーバーを準備してください。
操作手順
ステップ 1:データ同期の構成および開始
nimo-shakeツールパッケージを展開し、NimoShake/nimo-shakeディレクトリに移動して、conf/nimo-shake.conf構成ファイルを編集します。下表に、主要な構成パラメーターを示します。パラメーター
説明
例
sync_mode同期モード。
allはフル同期および増分同期を意味し、fullはフル同期のみを意味します。allsource.access_key_idソースの AWS DynamoDB 用 AccessKey ID。
AKIAIOSFODNN7...source.secret_access_keyソースの AWS DynamoDB 用 Secret Access Key。
wJalrXUtnFEMI...source.regionソースの AWS DynamoDB が配置されているリージョン。
cn-north-1source.endpoint_urlソースのエンドポイント。AWS DynamoDB の場合は、このパラメーターを空のままにしてください。
-
target.addressターゲットの PolarDB クラスター向け DynamoDB エンドポイント(
http://およびポート番号を含む)。http://pe-xxx.rwlb.rds...target.access_key_idターゲットの PolarDB クラスターの DynamoDB アカウント用 AccessKey。
your-polardb-access-keytarget.secret_access_keyターゲットの PolarDB クラスターの DynamoDB アカウント用 Secret Access Key。
your-polardb-secret-keyfilter.collection.whiteテーブルフィルターのホワイトリスト。指定されたテーブルのみを同期対象とします。複数のテーブルは
;で区切ります。説明このパラメーターはブラックリストと併用できません。両方を指定した場合、すべてのテーブルが同期対象となります。
c1;c2filter.collection.blackテーブルフィルターのブラックリスト。同期対象から除外するテーブルを指定します。複数のテーブルはセミコロン(
;)で区切ります。説明このパラメーターはホワイトリストと併用できません。両方を指定した場合、すべてのテーブルが同期対象となります。
c1;c2OS アーキテクチャーに対応するバイナリファイルを実行して、同期タスクを開始します。
説明ターミナルセッションが切断された場合でも同期タスクが中断されないように、
nohupを使用してバックグラウンドで実行することを推奨します。# nimo-shake ディレクトリに戻ります cd .. # Linux x86-64 アーキテクチャーでタスクを開始します nohup ./bin/nimo-shake.linux.amd64 -conf=./conf/nimo-shake.conf > /dev/null 2>&1 &プログラムはまずフル同期を実行し、完了後に自動的に増分同期フェーズへ移行し、継続して実行されます。
ステップ 2:データ整合性の確認
NimoShake/nimo-full-checkディレクトリに移動し、conf/nimo-full-check.conf構成ファイルを編集します。構成パラメーターはnimo-shakeと類似しています。ソースおよびターゲット双方の接続情報を指定する必要があります。検証タスクを開始します。
# nimo-full-check ディレクトリに戻ります cd .. # Linux x86-64 アーキテクチャーでタスクを開始します nohup ./bin/nimo-full-check.linux.amd64 -conf=./conf/nimo-full-check.conf > /dev/null 2>&1 &検証ツールは、進捗状況をリアルタイムでターミナルに出力し、詳細なログおよびデータ差分レポートをデフォルトのディレクトリ
logs/およびnimo-full-check-diff/に保存します。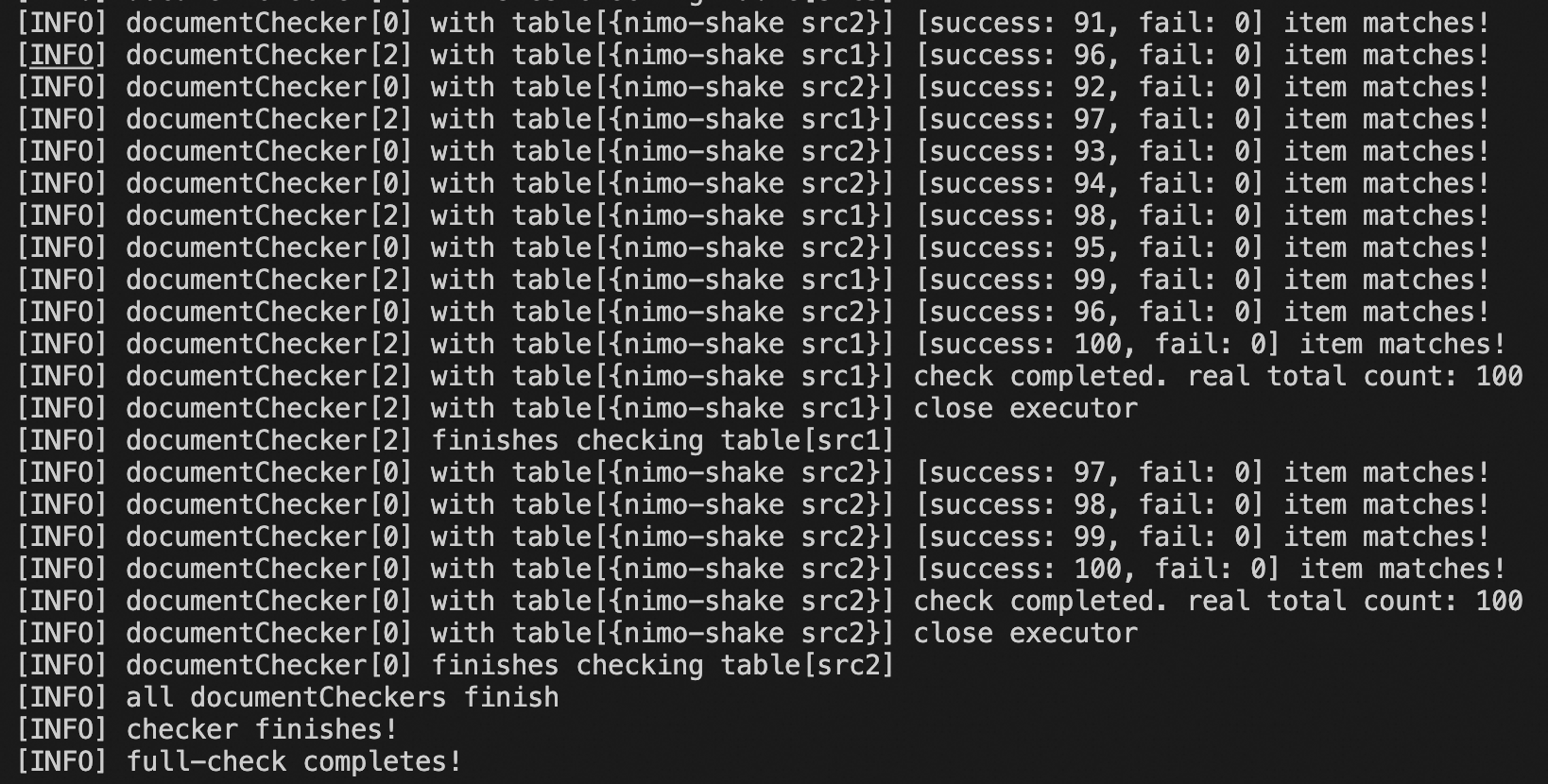
(任意)不整合データの修正:
ソースの DynamoDB とターゲットの PolarDB for PostgreSQL クラスターのデータが不整合の場合、該当するテーブル名が指定された差分ディレクトリに一覧表示されます。例:
説明差分ディレクトリはデフォルトで
nimo-full-check-diffであり、conf/nimo-full-check.conf構成ファイル内のdiff_output_fileパラメーターで変更可能です。nimo-full-check-diff/ └── testtable-0 └── testtable-1修復タスクを実行します:
nohup ./bin/nimo-repair.linux.amd64 -conf=./conf/nimo-repair.conf > /dev/null 2>&1 &
ステップ 3:(任意)逆同期の構成
ビジネスカットオーバーを実施する前に、PolarDB for PostgreSQL からソースの DynamoDB へ向けて逆同期リンクを構成できます。このリンクは、公式のビジネスカットオーバー時に PolarDB へ切り替えた直後に開始され、データをソースへ戻すことが可能となるため、ロールバック時のフォールバック手段として機能します。以下の手順に従ってリンクを構成してください。
環境の準備
PolarDB クラスターの
wal_levelパラメーターがlogicalに設定されていることを確認します。特権データベースアカウントの作成および権限の付与:
(任意)特権アカウントがまだ作成されていない場合、PolarDB コンソール にアクセスし、クラスターの セクションで特権アカウントを作成します。
論理レプリケーションスロットとパブリケーションの作成:高権限アカウントを使用して
polardb_internal_dynamodbデータベースに接続し、次の SQL コマンドを実行して、論理レプリケーションスロットを作成し、DynamoDB アカウント にレプリケーション権限を付与し、データベース内のすべてのテーブルを含むパブリケーションを作成します。作成された論理レプリケーションスロットのアクティブステータスを確認できます。-- 論理レプリケーションスロットを作成します。「flink_slot」という名前は、後続の Flink 構成で使用される名前と一致させる必要があります。 SELECT * FROM pg_create_logical_replication_slot('flink_slot', 'pgoutput'); -- 前述の専用 DynamoDB アカウントに REPLICATION 権限を付与します。 -- <your_dynamodb_user> をご自身の専用 DynamoDB アカウント名に置き換えてください。 ALTER ROLE <your_dynamodb_user> REPLICATION; -- レプリケーションスロットのステータスを確認します。この時点では「flink_slot」の `active` フィールドは `f`(false)である必要があります。 SELECT * FROM pg_replication_slots;Flink の有効化および構成:
Realtime Compute for Apache Flink を有効化 し、Flink ワークスペースを作成します。
重要Flink ワークスペースは、PolarDB クラスターと同じ VPC 内に配置する必要があります。
Flink ワークスペースのパブリックネットワークアクセスを構成 し、AWS DynamoDB への接続を可能にします。
PolarDB クラスターの IP アドレスホワイトリストの構成:
Flink コンソールでワークスペースの 詳細 ボタンをクリックし、「ワークスペースの詳細」ページで CIDR ブロック 情報を取得します。
PolarDB コンソール にアクセスし、クラスターの セクションで IP ホワイトリストの追加 をクリックし、Flink の CIDR ブロック情報を追加します。
PolarDB クラスターと Flink ワークスペース間の接続性の確認:
Flink コンソールでワークスペースに移動し、右上隅の ネットワークプローブ アイコンをクリックします。
PolarDB クラスターのプライマリノードのプライベートアドレスおよびポートを入力し、検出 をクリックします。
ポップアップメッセージ「ネットワークプローブが正常に接続されました」が表示された場合、クラスターホワイトリストの構成が正しく行われていることを示します。
Flink ジョブのデプロイ
逆同期ツールのダウンロード:PolarDBBackSync.jar。
構成ファイルの準備:
application.yamlという名前の構成ファイルを作成し、以下の内容を記述します:snapshot: mode: never source: # PolarDB プライマリノードのプライベートエンドポイント hostname: pc-xxx.pg.polardb.rds.aliyuncs.com # PolarDB プライマリノードのプライベートポート port: 5432 # 前述の論理レプリケーションスロット名 slotName: flink_slot target: # 対象の AWS DynamoDB リージョン region: cn-north-1 # (任意)テーブルフィルター構成。whiteTableSet および blackTableSet のいずれか一方のみ宣言できます。 filter: # whiteTableSet: 逆同期対象のテーブル whiteTableSet: # blackTableSet: 逆同期対象外のテーブル blackTableSet: # Flink ジョブのチェックポイント間隔(ミリ秒単位) checkpoint: interval: 3000ファイルのアップロード:Flink コンソールで対象のワークスペースに移動し、「ファイル管理」ページで
PolarDBBackSync.jarおよびapplication.yamlをアップロードします。認証情報の安全な保管:平文でのキー暴露を避けるため、Flink の 変数管理 機能を用いて機密情報を保管することを推奨します。「変数管理」ページで、以下の 4 つの変数を追加します:
変数名
変数値
polardbusernamePolarDB の DynamoDB アカウント。
polardbpasswordPolarDB の DynamoDB アカウントの元のパスワード(DynamoDB アカウントのシークレットキーではありません)。
dynamodbakAWS DynamoDB の AccessKey ID。
dynamodbskAWS DynamoDB の Secret Access Key。
configfilename(任意)添付する依存関係ファイルの名前。デフォルトは
application.yamlです。ジョブのデプロイおよび開始:
「ジョブ O&M」ページに移動し、 を選択します。
以下の主要パラメーターを入力し、その他のパラメーターは必要に応じて構成した後、デプロイ をクリックします。
パラメーター
値またはリファレンス
デプロイモード
[ストリームモード] に固定されています。
デプロイ名
ジョブデプロイの名前を入力します。例:
PolarDBBackSync。エンジンバージョン
固定値:vvr-11.3-jdk11-flink-1.20。
JAR URI
アップロード済みの
PolarDBBackSync.jarファイルを選択します。エントリポイントクラス
org.example.PolarDBCdcJobに設定します。エントリポイントのメイン引数
以下の引数を設定します:
--polardbusername ${secret_values.polardbusername}--polardbpassword ${secret_values.polardbpassword}--dynamodbak ${secret_values.dynamodbak}--dynamodbsk ${secret_values.dynamodbsk}(任意)
--configfilename ${secret_values.configfilename}追加の依存関係ファイル
アップロード済みの
application.yamlファイルを選択します。デプロイが成功した後、 をクリックします。
検証およびクリーンアップ
検証:ジョブが開始された後、高権限アカウントを使用して PolarDB クラスター内の
polardb_internal_dynamodbデータベースに接続し、SELECT * FROM pg_replication_slots;を実行します。flink_slot レプリケーションスロットのactiveフィールドがt(true)に変化した場合、Flink ジョブが正常に接続されたことを示します。この時点で、ビジネストラフィックを PolarDB クラスターへ向けることができます。クリーンアップ:逆同期が不要になった場合、以下の手順に従ってリソースを解放し、コストを削減してください。
Realtime Compute for Apache Flink:
ジョブの停止:Flink コンソールにアクセスし、対象のワークスペースで「ジョブ O&M」ページを開き、対象のジョブを見つけて 停止 をクリックします。
インスタンスの解放:Flink コンソールに戻り、対象のワークスペースを見つけ、リソースの解放 をクリックします。
PolarDB クラスター:高権限アカウントを使用して
polardb_internal_dynamodbデータベースに接続し、以下のコマンドを実行して論理レプリケーションスロットを削除します。SELECT pg_drop_replication_slot('flink_slot');
ステップ 4:ビジネスカットオーバーの実施
増分同期の遅延が低く、整合性チェックで差分が報告されない状態になった時点で、以下の手順に従ってビジネスカットオーバーを計画してください。
最終検証:予定されたダウンタイムウィンドウの開始前に、整合性チェックツールを繰り返し実行し、増分同期の遅延が最小限であること、およびデータ差分がゼロまたは許容範囲内であることを確認します。
ソースへの書き込み停止:ダウンタイムウィンドウの開始時に、ソースの AWS DynamoDB へデータを書き込むすべてのビジネアプリケーションを一時停止します。
同期完了の待機:
nimo-shakeのログを監視し、新たに同期すべき増分データがないことを確認します。最終検証:
nimo-full-checkツールを再度実行し、ソースおよびターゲットのデータが完全に一致することを確認します。同期ツールの停止:データが完全に同期されたことを確認した後、
nimo-shakeプロセスを停止します。アプリケーション接続の切り替え:ビジネアプリケーションを停止し、データベース接続設定を AWS DynamoDB エンドポイントから PolarDB クラスターの DynamoDB 互換エンドポイントへ変更します。
(任意)逆同期タスクの開始:PolarDB への公式のビジネスカットオーバー時に、逆同期タスクを開始します。このタスクは Realtime Compute for Apache Flink を使用してデータをソースへレプリケーションし、ロールバック時の保護手段を提供します。
ビジネアプリケーションの開始:ビジネアプリケーションを再起動します。これでカットオーバーは完了です。
(任意)逆同期タスクの停止:カットオーバーが完了し、サービスが一定期間安定して稼働した後、データ整合性がビジネス要件を満たしていることを確認できた場合、逆同期タスクの停止(Flink ジョブの停止および関連リソースの解放) を安全に行うことができます。
付録:リアルタイムトラフィックのシミュレーション
テスト環境で継続的なデータ書き込みを伴う現実的な移行シナリオをシミュレートしたい場合、以下の Go サンプルコードを使用できます。このコードは、ソースの DynamoDB テーブルに対して定期的にデータを書き込みおよび更新します。
この手順は、移行プロセスのテストおよび検証のみを目的としています。本番環境での移行には実施しないでください。
package main
import (
"context"
"fmt"
"log"
"math/rand"
"time"
"github.com/aws/aws-sdk-go-v2/aws"
"github.com/aws/aws-sdk-go-v2/config"
"github.com/aws/aws-sdk-go-v2/credentials"
"github.com/aws/aws-sdk-go-v2/service/dynamodb"
"github.com/aws/aws-sdk-go-v2/service/dynamodb/types"
)
// --- ソースの AWS DynamoDB 用構成 ---
var (
region = "cn-north-1" // AWS DynamoDB リージョン
accessKey = "your-aws-access-key" // AWS DynamoDB アクセスキー
secretKey = "your-aws-secret-key" // AWS DynamoDB シークレットキー
)
// --- DynamoDB クライアント作成用ヘルパー関数 ---
func createClient() (*dynamodb.Client, context.Context) {
ctx := context.Background()
sdkConfig, err := config.LoadDefaultConfig(ctx, config.WithRegion(region))
if err != nil {
log.Fatalf("AWS 構成の読み込みに失敗しました: %v", err)
}
client := dynamodb.NewFromConfig(sdkConfig, func(o *dynamodb.Options) {
o.Credentials = credentials.NewStaticCredentialsProvider(accessKey, secretKey, "")
})
return client, ctx
}
// --- テーブルの作成および初期データの投入用関数 ---
func initializeData(client *dynamodb.Client, ctx context.Context) {
tableName := "src1" // 例:テーブル名
// テーブルが存在しない場合に作成
_, err := client.CreateTable(ctx, &dynamodb.CreateTableInput{
TableName: &tableName,
AttributeDefinitions: []types.AttributeDefinition{
{AttributeName: aws.String("pk"), AttributeType: types.ScalarAttributeTypeS},
},
KeySchema: []types.KeySchemaElement{
{AttributeName: aws.String("pk"), KeyType: types.KeyTypeHash},
},
ProvisionedThroughput: &types.ProvisionedThroughput{
ReadCapacityUnits: aws.Int64(100),
WriteCapacityUnits: aws.Int64(100),
},
})
if err != nil {
// テーブルが既に存在する場合は無視し、その他のエラーの場合は失敗
if _, ok := err.(*types.ResourceInUseException); !ok {
log.Fatalf("%s に対する CreateTable が失敗しました: %v", tableName, err)
}
}
fmt.Printf("テーブル '%s' がアクティブになるまで待機中...\n", tableName)
waiter := dynamodb.NewTableExistsWaiter(client)
err = waiter.Wait(ctx, &dynamodb.DescribeTableInput{TableName: &tableName}, 5*time.Minute)
if err != nil {
log.Fatalf("テーブル %s の待機に失敗しました: %v", tableName, err)
}
// 100 件のサンプルアイテムを挿入
for i := 0; i < 100; i++ {
pk := fmt.Sprintf("%s_user_%03d", tableName, i)
item := map[string]types.AttributeValue{
"pk": &types.AttributeValueMemberS{Value: pk},
"val": &types.AttributeValueMemberN{Value: fmt.Sprintf("%d", i)},
}
client.PutItem(ctx, &dynamodb.PutItemInput{TableName: &tableName, Item: item})
}
fmt.Printf("'%s' に 100 件の初期アイテムを挿入しました。\n", tableName)
}
// --- 連続的なビジネトラフィックのシミュレーション用関数 ---
func simulateTraffic(client *dynamodb.Client, ctx context.Context) {
tableName := "src1"
fmt.Println("トラフィックのシミュレーションを開始します(Ctrl+C で停止)。")
i := 0
for {
pk := fmt.Sprintf("%s_user_%03d", tableName, i%100)
newValue := fmt.Sprintf("%d", rand.Intn(1000))
_, err := client.UpdateItem(ctx, &dynamodb.UpdateItemInput{
TableName: &tableName,
Key: map[string]types.AttributeValue{
"pk": &types.AttributeValueMemberS{Value: pk},
},
ExpressionAttributeValues: map[string]types.AttributeValue{
":newval": &types.AttributeValueMemberN{Value: newValue},
},
UpdateExpression: aws.String("SET val = :newval"),
})
if err != nil {
fmt.Printf("更新エラー: %v\n", err)
} else {
fmt.Printf("pk=%s を新しい val=%s で更新しました\n", pk, newValue)
}
i++
time.Sleep(1 * time.Second) // 1 秒ごとに 1 件のレコードを更新
}
}
func main() {
client, ctx := createClient()
initializeData(client, ctx)
simulateTraffic(client, ctx)
}