PolarDB は、並列データ定義言語 (DDL) 機能をサポートしています。データベースのハードウェアリソースがアイドル状態の場合、この機能を使用して DDL の実行を高速化できます。これにより、後続のデータ操作言語 (DML) 操作のブロッキングを回避し、DDL 操作に必要なタイムウィンドウを短縮できます。
適用範囲
セカンダリインデックスを作成するには、ご利用の PolarDB クラスターが次のいずれかのバージョン要件を満たしている必要があります:
PolarDB for MySQL 8.0.2、リビジョンバージョン 8.0.2.1.7 以降。
PolarDB for MySQL 8.0.1、リビジョンバージョン 8.0.1.1.10 以降。
PolarDB for MySQL 5.7、リビジョンバージョン 5.7.1.0.7 以降。
主キーインデックスを作成するには、ご利用の PolarDB クラスターが次のいずれかのバージョン要件を満たしている必要があります:
PolarDB for MySQL 8.0.2、リビジョンバージョン 8.0.2.2.9 以降。
PolarDB for MySQL 8.0.1、リビジョンバージョン 8.0.1.1.31 以降。
詳細については、「バージョン番号の照会」をご参照ください。
注意事項
並列 DDL 機能を有効にすると、並列スレッド数が増加します。これにより、CPU、メモリ、I/O などのハードウェアリソースの消費量が増え、同時に実行されている他の SQL 操作に影響を与える可能性があります。この機能は、オフピーク時間帯やハードウェアリソースが十分な場合に使用することを推奨します。
制限事項
現在、並列 DDL 機能は、主キーインデックスとセカンダリインデックスを作成する DDL 操作をサポートしています。フルテキストインデックス、空間インデックス、または仮想カラム上のセカンダリインデックスの作成はサポートしていません。
背景情報
従来の DDL 操作は、シングルコアプロセッサと従来のハードディスク向けに設計されていました。この設計では、大規模なテーブルに対する DDL 操作の実行時間が長くなり、レイテンシが高くなる可能性があります。例えば、セカンダリインデックスを作成するための高レイテンシな DDL 操作は、新しいインデックスに依存する後続の DML クエリをブロックする可能性があります。マルチコアプロセッサの発展により、並列 DDL がより多くのスレッドを使用するためのハードウェアサポートが提供されるようになりました。ソリッドステートディスク (SSD) の普及により、ランダムアクセスのレイテンシは順次アクセスのレイテンシに匹敵するようになりました。これにより、特に大規模なテーブルでのインデックス作成を高速化するために並列 DDL を使用することが有益になります。
使用方法
innodb_polar_parallel_ddl_threads
innodb_polar_parallel_ddl_threads パラメーターを設定することで、並列 DDL 機能を有効にできます:
パラメーター
レベル
説明
innodb_polar_parallel_ddl_threads
セッション
各 DDL 操作の並列スレッド数を制御します。有効値の範囲:1~16。デフォルト値は 1 で、シングルスレッドの DDL を実行します。
このパラメーター値が 1 でない場合、セカンダリインデックスを作成する際に並列 DDL が自動的に有効になります。
説明このパラメーターが 1 に設定されている場合、システムはデフォルトで 2 つの並列スレッドを使用します。
innodb_parallel_build_primary_index
innodb_parallel_build_primary_index パラメーターを使用して、主キーインデックスを作成する際に並列 DDL を許可するかどうかを制御できます:
説明並列主キーインデックス作成機能を使用するには、クォータセンターに移動します。 [クォータ ID] が [polardb_mysql_pddl_for_pk] のクォータを見つけ、[アクション] 列の [適用] をクリックしてトライアルを申請します。
パラメーター
レベル
説明
innodb_parallel_build_primary_index
グローバル
主キーインデックスを作成する際に並列 DDL を許可するかどうかを制御します。有効な値は次のとおりです:
ON:主キーインデックス作成のための並列 DDL を許可します。
OFF:主キーインデックス作成のための並列 DDL を許可しません (デフォルト)。
innodb_polar_use_sample_sort
並列 DDL だけではパフォーマンス要件を満たせない場合、innodb_polar_use_sample_sort パラメーターを使用して、インデックス作成中のソートプロセスをさらに最適化できます。
パラメーター
レベル
説明
innodb_polar_use_sample_sort
セッション
サンプルソート最適化機能のスイッチです。有効な値は次のとおりです:
ON:サンプルソート最適化機能を有効にします。
OFF:サンプルソート最適化機能を無効にします (デフォルト)。
innodb_polar_use_parallel_bulk_load
前述の機能でもパフォーマンス要件を満たせない場合は、innodb_polar_use_parallel_bulk_load パラメーターを使用して、インデックスツリーの作成プロセスをさらに最適化することもできます。
パラメーター
レベル
説明
innodb_polar_use_parallel_bulk_load
セッション
並列バルクロード最適化機能のスイッチです。有効な値は次のとおりです:
ON:並列バルクロード最適化機能を有効にします。
OFF:並列バルクロード最適化機能を無効にします (デフォルト)。
パフォーマンス テスト
テスト環境
16 コア、128 GB メモリの Standard Edition の PolarDB for MySQL 8.0 クラスター。
クラスターには 50 TB のストレージ容量があります。
テストテーブルのスキーマ
次の文を使用して、
t0という名前のテーブルを作成します:CREATE TABLE t0( a INT PRIMARY KEY, b INT) ENGINE=InnoDB;テストテーブルのデータ
次の文を使用してテストデータを生成します:
DELIMITER // CREATE PROCEDURE populate_t0() BEGIN DECLARE i int DEFAULT 1; WHILE (i <= $table_size) DO INSERT INTO t0 VALUES (i, 1000000 * RAND()); SET i = i + 1; END WHILE; END // DELIMITER ; CALL populate_t0() ;説明テストを実行する際、
$table_sizeをテーブル内のレコード数 (例:1000000) に置き換えてください。このテストでは、1,000,000、10,000,000、100,000,000、1,000,000,000 レコードのテーブルと、1 TB のデータを持つテーブルを使用します。
1 TB のテストテーブルは Sysbench ツールを使用して生成されます。Sysbench ツールの使用方法の詳細については、「テストツール」をご参照ください。
テスト方法
このテストでは、さまざまなサイズのテーブルで、
INTデータ型のbフィールドにセカンダリインデックスを作成する際のパフォーマンス向上を測定します。このテストでは、並列 DDL を有効にし、innodb_polar_parallel_ddl_threads パラメーターを 1、2、4、8、16、32 に設定して、並列スレッド数を変更します。テスト結果
次のグラフは、innodb_polar_parallel_ddl_threads パラメーターのみを有効にした場合の並列 DDL の高速化率を示しています。
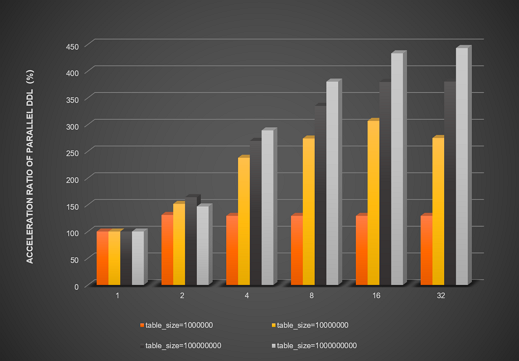
次のグラフは、innodb_polar_parallel_ddl_threads と innodb_polar_use_sample_sort パラメーターの両方を有効にした場合の並列 DDL の高速化率を示しています。
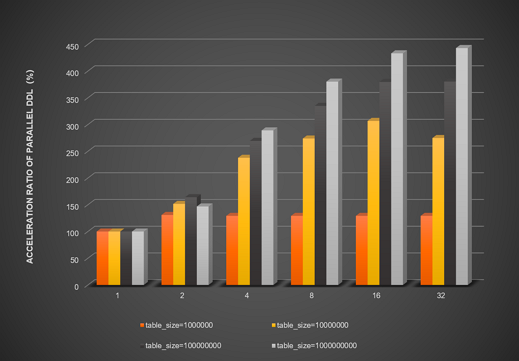
次のグラフは、innodb_polar_parallel_ddl_threads、innodb_polar_use_sample_sort、および innodb_polar_use_parallel_bulk_load パラメーターを有効にした場合の並列 DDL の高速化率を示しています。
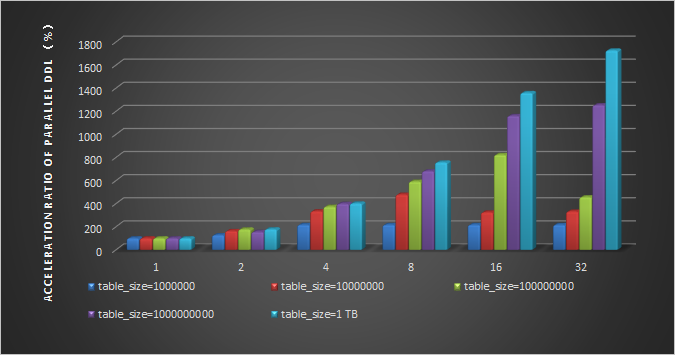
お問い合わせ
DDL 操作についてご質問がある場合は、技術サポートにお問い合わせください。