ビジネスデータ量が継続的に増加すると、ログ、トランザクションレコード、履歴注文など、アクセス頻度は低いものの分析のために保持する必要がある履歴データのストレージコストが大きな負担になる可能性があります。この機能を使用すると、PolarDB for MySQL のコールドデータを、低コストの Alibaba Cloud Object Storage Service (OSS) にアーカイブできます。さらに、Columnar Index (IMCI) と組み合わせることで、このアーカイブされたデータに対して高性能な分析クエリを実行し、コストの削減と効率の向上を実現できます。
前提条件
この機能を使用する前に、環境が次の要件を満たしていることを確認してください。
製品バージョン:エンタープライズ版(クラスター版)。
カーネルバージョン: 8.0.2.2.30 以降。
アーカイブ形式: この機能は、ORC 形式でアーカイブされたデータにのみ適用されます。
IMCI ノード: まず、クラスターに IMCI 読み取り専用ノードを追加する必要があります。
アーカイブと IMCI クエリの設定
このセクションでは、標準テーブルを使用して、IMCI の有効化、データのアーカイブ、高速化されたクエリの実行という一連のプロセスを説明します。
プロセスの概要
テーブルの IMCI を有効化し、データをアーカイブする: 対象テーブルに列指向インデックスを追加して、IMCI による高速化を有効にします。次に、テーブルデータを OSS に移行し、ORC 形式で保存します。
アーカイブ済みデータをクエリする: クラスターエンドポイントを使用した自動ルーティング、または IMCI 読み取り専用ノードへの直接接続により、分析クエリを IMCI 読み取り専用ノードに送信して実行します。
ステップ 1: IMCI を有効化してデータをアーカイブする
IMCI でクエリを高速化するには、列指向インデックスが必要です。インデックスは、データアーカイブの前、またはアーカイブ中に追加できます。
データアーカイブの前
列指向インデックスを作成する:
CREATE TABLEステートメントの末尾にcomment='columnar=1'を追加します。CREATE TABLE t1( a1 INT PRIMARY KEY, a2 INT, a3 INT, a4 INT ) ENGINE=InnoDB COMMENT='columnar=1';コールドデータをアーカイブする:
ALTER TABLE t1 ENGINE = ORC STORAGE OSS;
データアーカイブ中
テーブルを作成する:
CREATE TABLE t2( a1 INT PRIMARY KEY, a2 INT, a3 INT, a4 INT ) ENGINE=InnoDB;コールドデータをアーカイブして列指向インデックスを追加する:
ALTER TABLE t2 ENGINE = ORC STORAGE OSS comment='columnar=1';
ステップ 2: アーカイブ済みデータをクエリする
分析クエリリクエストを IMCI 読み取り専用ノードにルーティングすることで、OSS にアーカイブ済みのデータの分析を高速化します。
IMCI が有効な ORC アーカイブテーブル、および ORC アーカイブ済みパーティションを含むハイブリッドパーティションテーブルの場合、クラスターエンドポイント経由のクエリは自動的に IMCI 読み取り専用ノードに転送されます。SQL ステートメントにヒントを追加する必要はありません。
方法 1: (推奨) クラスターエンドポイントの使用
自動ルーティングを使用するには、クラスターに IMCI 読み取り専用ノードを追加する必要があります。
この自動ルーティングは、オプティマイザによるコストに基づく判断に依存しません。ショートサーキットロジックを使用します。つまり、クエリが IMCI が有効な ORC アーカイブ済みテーブルを対象とする場合、行指向ストレージと列指向ストレージのコスト比較をバイパスし、IMCI 読み取り専用ノードに直接ルーティングされます。
クラスターエンドポイントを使用してデータベースに接続し、クエリを直接実行できます。
SELECT COUNT(*) FROM t1;方法 2: IMCI ノードへの接続
コンソールで カスタムクラスターエンドポイントを追加し、IMCI 読み取り専用ノードのみを選択することもできます。この接続でのクエリは、デフォルトで列指向インデックスを使用します。
この方法は、アーカイブ済みデータに対する分析クエリを常に IMCI 読み取り専用ノードに送信したい場合に最適です。
パーティションテーブルのハイブリッドクエリの処理
パーティションテーブルの場合、一部の履歴パーティションをアーカイブして、ホットデータとコールドデータを分離できます。クエリを実行すると、インメモリー列指向インデックス (IMCI) は、アーカイブされていない InnoDB パーティションと、アーカイブ済みの OSS パーティションに対して、インテリジェントにハイブリッドクエリを実行できます。
パーティションテーブルに列指向インデックスを追加する: 列指向インデックスは、個々のパーティションではなく、テーブル全体にのみ追加できます。
CREATE TABLE t_partition( a1 INT PRIMARY KEY, a2 INT, a3 INT, a4 INT ) COMMENT='columnar=1' PARTITION BY RANGE(a1) ( PARTITION p1 VALUES LESS THAN (20), PARTITION p2 VALUES LESS THAN (40), PARTITION p3 VALUES LESS THAN (60), PARTITION p4 VALUES LESS THAN MAXVALUE );特定のパーティションをアーカイブする: 1 つ以上のパーティションをアーカイブします。
ALTER TABLE t_partition CHANGE PARTITION p1 ENGINE = ORC FORCE STORAGE OSS;ハイブリッドクエリを実行する
クエリがアーカイブ済みの OSS パーティションとアーカイブされていない InnoDB パーティションの両方にアクセスする必要がある場合は、まずセッションでハイブリッドクエリを有効にします。
-- ハイブリッドクエリのサポートを有効にする SET hybrid_partition_query_mix_engine_enabled = ON; -- クエリを実行する SELECT COUNT(*) FROM t_partition;
パーティションテーブルのルーティングルール
ORC アーカイブ済みパーティションを含むハイブリッドパーティションテーブルの場合、システムはテーブル全体の実行パスを決定します。テーブルに列指向インデックスがあり、ORC アーカイブ済みパーティションが含まれている場合、クラスターエンドポイントに送信されたクエリは自動的に IMCI 読み取り専用ノードにルーティングされます。このルールは、クエリがパーティションプルーニングを使用する場合、または PARTITION 句を使用してアーカイブされていない InnoDB パーティションのみにアクセスする場合にも適用されます。
SELECT COUNT(*) FROM t_partition;列指向インデックスを使用せずに現在のセッションでクエリを実行するには、use_imci_engine を無効にします。このパラメータを無効にすると、クエリは列指向インデックスに自動的にルーティングされません。システムは、行指向ストレージの実行パスを使用してクエリを処理します。
SET use_imci_engine = OFF;
SELECT COUNT(*) FROM t_partition;列指向インデックスを再度使用するには、パラメータを有効にします。
SET use_imci_engine = ON;パフォーマンスの参考値
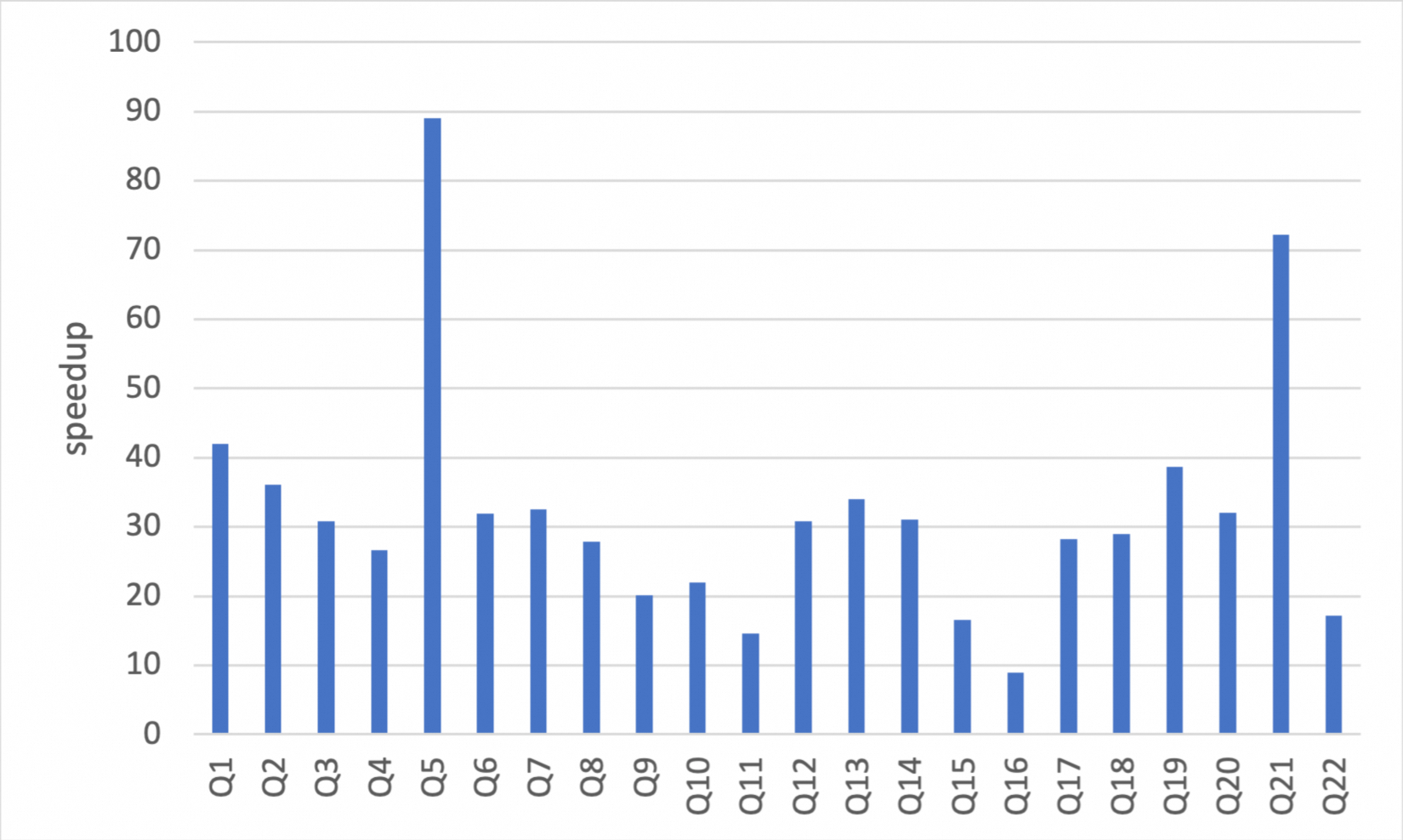
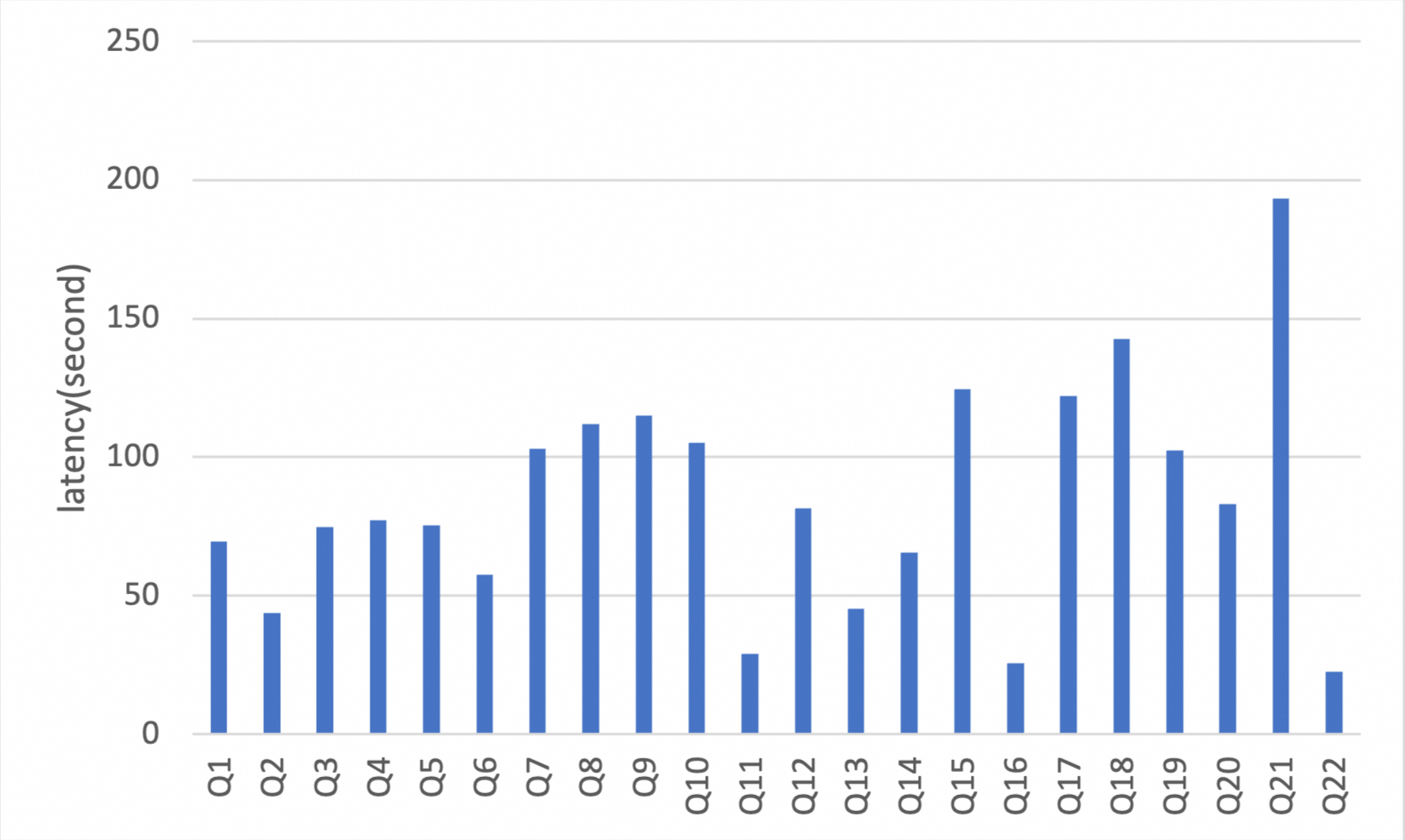
以下のデータは、32 コア、256 GB の PolarDB for MySQL クラスターで TPC-H 100 GB 標準テストセットを使用して実行されたベンチマークのものです。この結果、データを OSS にアーカイブし、IMCI を用いて分析クエリを実行した場合、InnoDB 行ストレージから直接データをクエリする場合に比べ、全体で約 35 倍の高速化が確認されました。この高速化は、テーブル全体の集計やワイドテーブルスキャンなどの一般的な分析処理 (AP) クエリで特に顕著です。
ここで説明する TPC-H の実装は、TPC-H ベンチマークに基づいています。これらの結果は、テストが TPC-H のすべての要件に完全に準拠しているわけではないため、公式発表の TPC-H ベンチマーク結果と比較できるものではありません。
列指向ストレージクエリ実行時間 (秒)
行指向ストレージと比較した列指向ストレージの高速化率