このトピックでは、DLC が提供する計算能力ヘルスチェック機能の使用方法について説明します。
機能概要
AI トレーニングのシナリオでは、次のような問題が発生することがあります。
ジョブを中断し GPU リソースを無駄にするリソース障害:ジョブがモデルのチェックポイントの読み込みやその他の初期化操作に時間を費やした後、不良リソースによりトレーニングを開始できないことがあります。その場合、問題の調査、不良リソースの特定、ジョブの再送信を行う必要があり、GPU リソースが無駄になります。
パフォーマンス問題の特定が困難で、テストツールが不足している:ジョブ実行中にモデルのトレーニングパフォーマンスが低下する原因として、遅延ノードが考えられますが、問題を迅速かつ効果的に特定する方法が不足しています。また、リソースグループ内のマシンの GPU 計算能力および通信パフォーマンスをテストするための便利で信頼性の高いベンチマークプログラムもありません。
これらの問題に対処するため、DLC では計算能力ヘルスチェック (SanityCheck) 機能を提供しています。この機能は、分散トレーニングジョブ向けの計算能力リソースの健全性とパフォーマンスをチェックします。DLC トレーニングジョブを作成する際に、この機能を有効化できます。ヘルスチェックにより、トレーニングに使用するリソースが包括的に検査され、自動的に不良ノードが隔離され、バックグラウンドで自動 O&M プロセスがトリガーされます。これにより、トレーニングジョブの開始時に問題が発生する可能性が低減され、成功率が向上します。チェック完了後には、GPU 計算能力および通信パフォーマンスに関するレポートが生成され、トレーニングパフォーマンスを低下させる要因の特定と位置づけを支援し、全体的な診断効率を向上させます。
制限事項
現在、この機能は Lingjun リソースを使用して作成された PyTorch トレーニングジョブでのみ利用可能です。ジョブの GPU 数はフルマシン構成と一致している必要があります。Lingjun リソースはホワイトリスト登録済みユーザーのみが利用できます。この機能を利用するには、アカウントマネージャーにお問い合わせください。
ヘルスチェックの有効化
コンソールを使用する
PAI コンソールで DLC トレーニングジョブを作成する 際、以下の重要なパラメーターを設定することでヘルスチェック機能を有効化できます。ジョブ作成後、システムはリソースの健全性と可用性をチェックするためにしばらく時間を要し、結果を提供します。
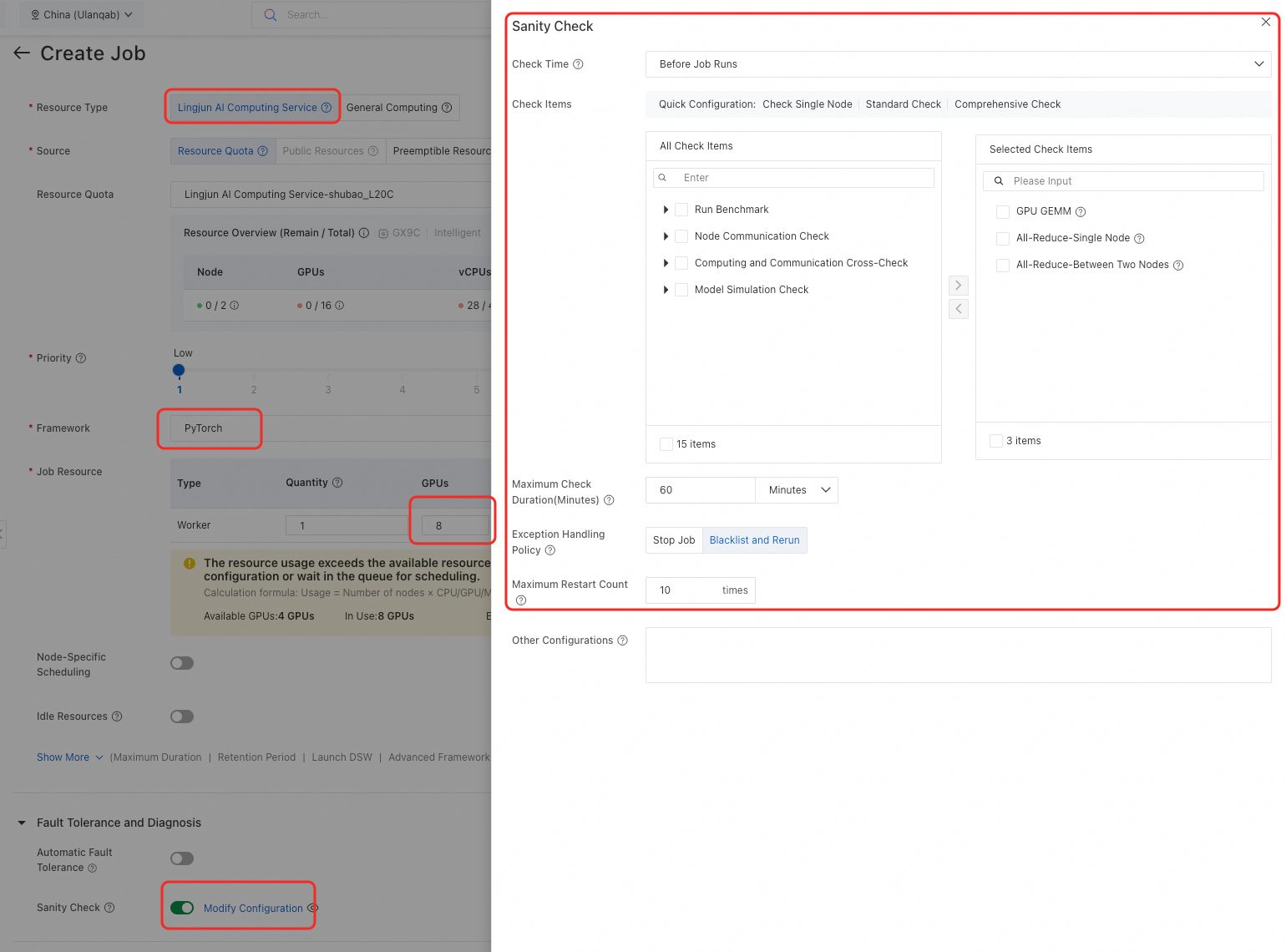
重要なパラメーターは次のとおりです。
リソース情報 の構成:
パラメーター
説明
Resource Type
Lingjun Intelligence Resources を選択します。
Source
Resource Quota を選択します。
Resource Quota
Lingjun リソース用に作成済みのリソースクォータを選択します。リソースクォータの作成方法の詳細については、「リソースクォータの作成」をご参照ください。
Framework
PyTorch を選択します。
Job Resource
GPU 数はフルマシン構成と一致している必要があります。
フォールトトレランスと診断 の構成:ヘルスチェック スイッチをオンにして、以下のパラメーターを設定します。
パラメーター
説明
Check Time
Before Job Runs (デフォルト):ジョブがリソースを取得した後、コードが実行される前にトレーニングジョブの計算能力ノードに対して事前チェックが実施されます。
After Job Restarts:ジョブが異常終了した場合、AIMaster 自動フォールトトレランスによりジョブが再起動され、その後計算能力ヘルスチェックが実行されます。
説明このオプションを選択する場合は、自動フォールトトレランス 機能を有効化する必要があります。詳細については、「AIMaster:エラスティックで自動フォールトトレランスエンジン」をご参照ください。
Check Items
チェック項目には、計算パフォーマンスチェック、ノード通信チェック、計算・通信クロスチェック、モデルシミュレーション検証の 4 つの主要カテゴリが含まれます。チェック項目と推奨シナリオの詳細については、「付録:チェック項目の説明」をご参照ください。
デフォルトでは、GPU GEMM チェック (GPU GEMM パフォーマンスをチェック) および All-Reduce チェック (ノード通信パフォーマンスをチェックし、遅延または不良な通信ノードを特定) が有効になっています。
チェック項目を検索または選択するか、クイック構成を使用してワンクリックでチェック項目テンプレートを選択することもできます。
Maximum Check Duration
ヘルスチェックの最大実行時間です。デフォルト値は 60 分です。チェックがタイムアウトした場合、例外処理ポリシーがトリガーされます。
Exception Handling Policy
ヘルスチェックが失敗した場合、選択したポリシーに基づいてシステムがジョブに対して操作を実行します。
ジョブ終了:不良または疑わしいノードが検出された場合、ジョブは終了し、「チェック失敗」としてマークされます。
ブラックリスト登録と再実行:不良または疑わしいノードが検出された場合、システムは自動的にノードをブラックリストに登録し、ジョブを再起動してチェックを再実行し、パスするまで繰り返します。
Maximum Restart Count
例外処理ポリシーが「ブラックリスト登録と再実行」に設定されている場合、最大再起動回数を設定できます。デフォルト値は 10 です。再起動回数がこの上限を超えた場合、ジョブは自動的に失敗します。
Other Configurations
デフォルトでは空です。高度なパラメーター設定がサポートされています。
チェック結果の確認
ヘルスチェックステータス
DLC ジョブのヘルスチェックステータスは次のとおりです。
チェック中:計算能力ヘルスチェックが進行中です。
チェック失敗:ヘルスチェック中に異常ノードが検出された場合、またはチェックがタイムアウトした場合、ステータスは「チェック失敗」に変化します。
チェック成功:ヘルスチェックが成功すると、ジョブは「実行中」状態になります。
ヘルスチェック結果の確認
コンソールを使用する
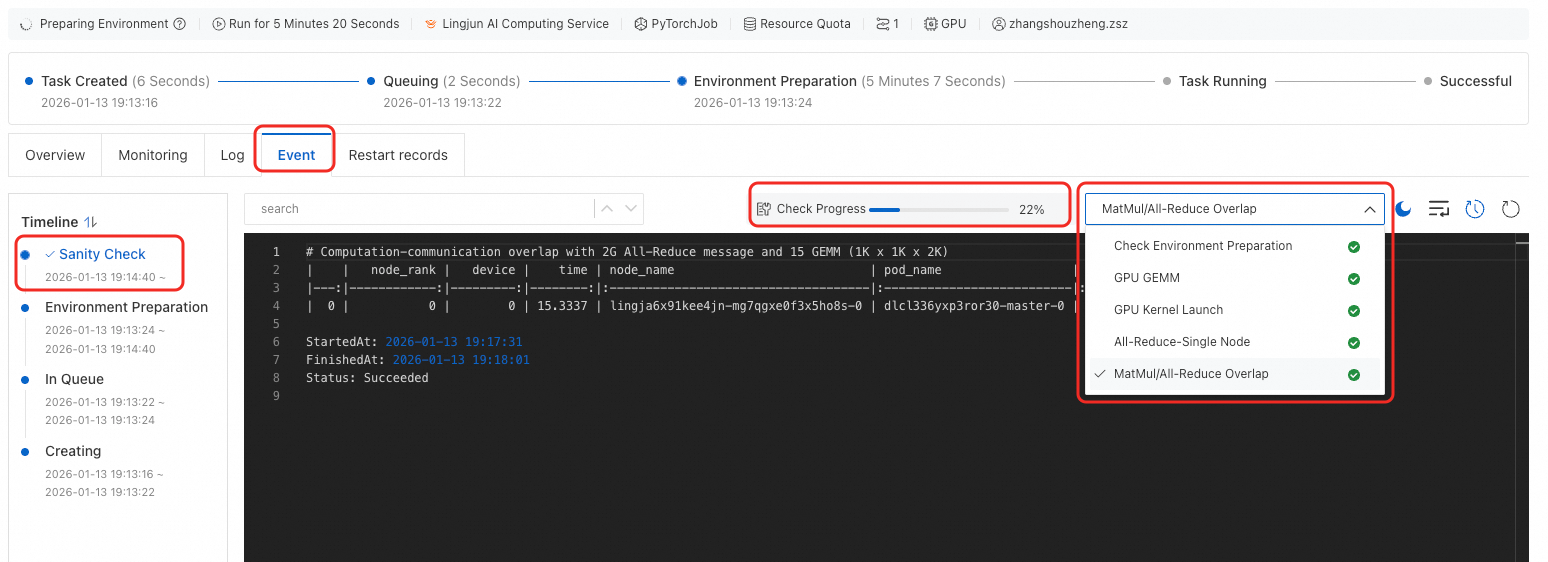
DLC ジョブの詳細ページで、Event タブをクリックし、ヘルスチェック をクリックして、チェックの進捗と結果を確認します。
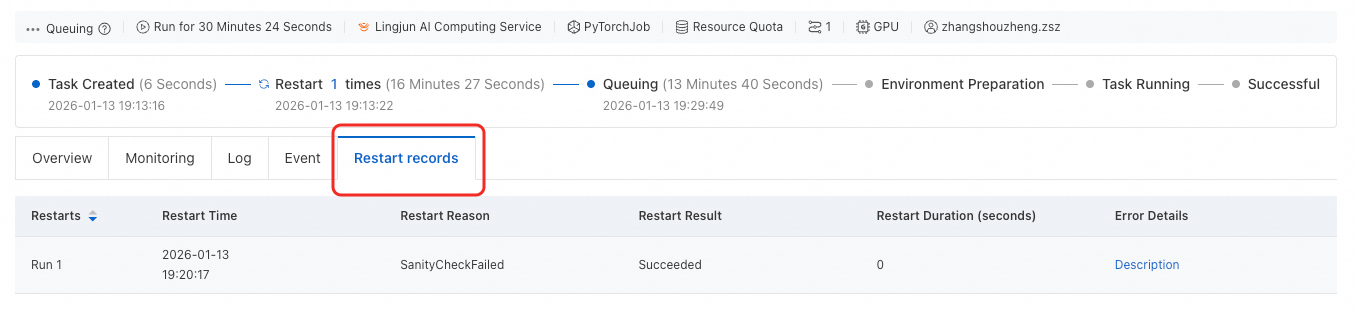
再起動記録 タブをクリックして、再起動回数、再起動理由、再起動結果などの情報を確認します。
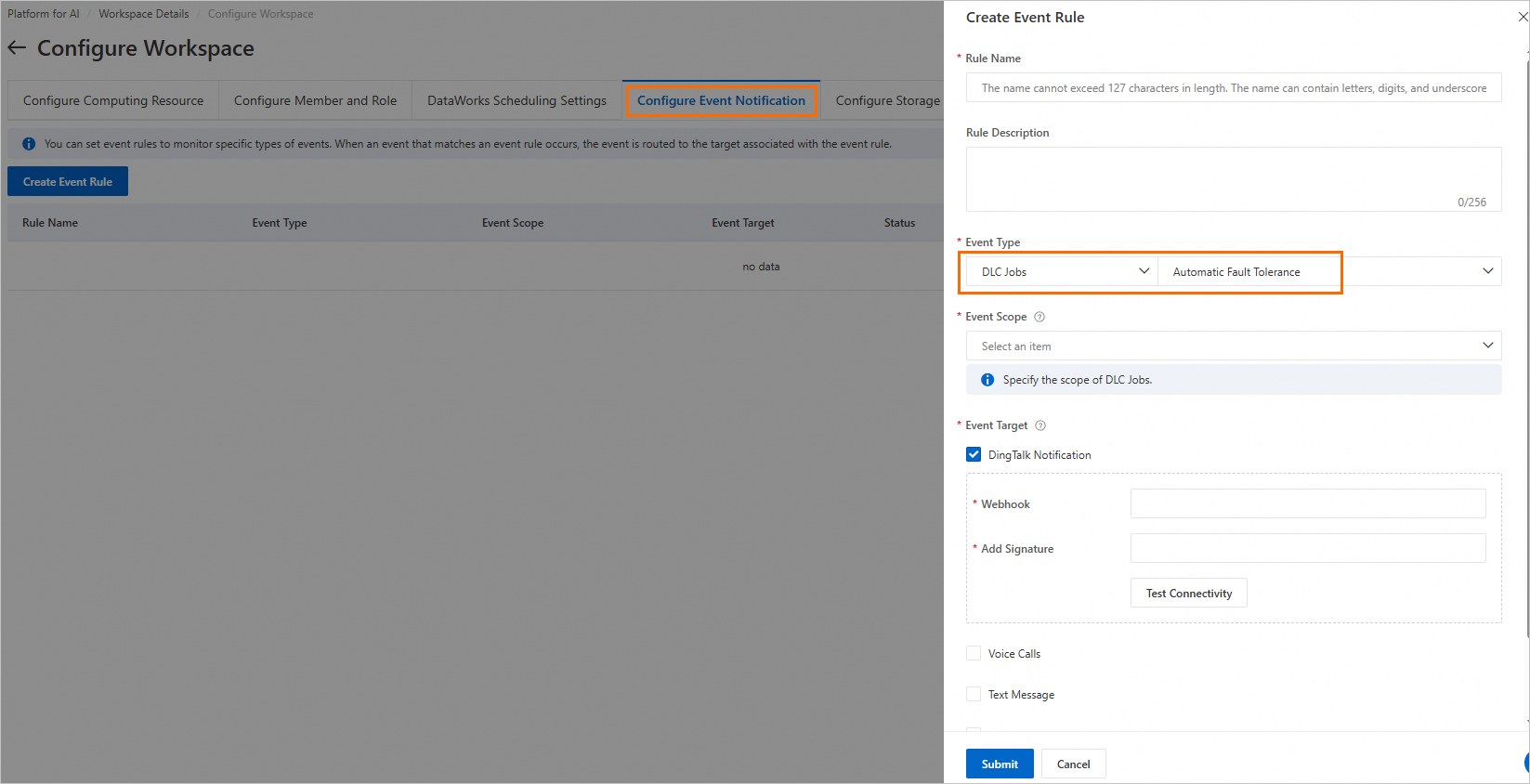
メッセージ通知の構成
PAI ワークスペースのイベント通知設定でメッセージ通知ルールを作成します。Event Type パラメーターを DLC Job > Automatic Fault Tolerance に設定します。その他のパラメーターの詳細については、「メッセージ通知」をご参照ください。この構成により、計算能力ヘルスチェックが失敗した場合に通知が送信されます。
ワークスペースでのメッセージ通知の作成方法の詳細については、「イベント通知設定」をご参照ください。
付録:チェック項目の説明
推定チェック時間は 2 台のマシンに基づいています。この値は参考情報であり、実際の時間は異なる場合があります。
チェック項目 | 説明 (推奨シナリオ) | 推定チェック時間 | |
計算パフォーマンスチェック | GPU GEMM | GPU GEMM パフォーマンスをチェックします。以下を特定できます。
| 1 分 |
GPU カーネル起動 | GPU カーネル起動レイテンシをチェックします。以下を特定できます。
| 1 分 | |
ノード通信チェック | All-Reduce | ノード通信パフォーマンスをチェックし、遅延または不良な通信ノードを特定します。異なる通信パターンにおいて、以下を特定できます。
| 単一コレクティブ通信チェック 5 分 |
All-to-All | |||
All-Gather | |||
Multi-All-Reduce | |||
ネットワーク接続 | ヘッドノードまたはテールノードのネットワーク接続性をチェックし、通信接続性が異常なノードを特定します。 | 2 分 | |
計算・通信クロスチェック | MatMul/All-Reduce オーバーラップ | 通信と計算カーネルがオーバーラップする際のシングルノードのパフォーマンスをチェックします。以下を特定できます。
| 1 分 |
モデルシミュレーション検証 | Mini GPT | モデルシミュレーションを使用して AI システムの信頼性を検証します。以下を特定できます。
| 1 分 |
Megatron GPT | 5 分 | ||
ResNet | 2 分 | ||