このトピックでは、DLC が提供する AIMaster ベースのフォールトトレランスモニタリング機能の使用方法について説明します。
背景情報
ディープラーニングは広く利用されています。モデルとデータが大規模化するにつれて、分散トレーニングが一般的な手法となっています。ジョブインスタンスの数が増えると、ソフトウェアスタックやハードウェア環境の例外によってジョブが失敗する可能性があります。
大規模な分散ディープラーニングジョブの安定した運用を保証するために、DLC は AIMaster ベースのフォールトトレランスモニタリングを提供します。AIMaster はジョブレベルのコンポーネントです。このモニタリングを有効にすると、AIMaster インスタンスがジョブの他のインスタンスと並行して実行され、ジョブのモニタリング、フォールトトレランス評価、リソース制御を提供します。
制限事項
現在、AIMaster は PyTorch、MPI、TensorFlow、ElasticBatch のフレームワークをサポートしています。
ステップ 1:フォールトトレランスモニタリングパラメーターの設定
このセクションでは、フォールトトレランスモニタリングのすべてのパラメーターについて説明します。一般的な設定例を参考にして、設定を計画できます。この機能を有効にする際、必要に応じて [その他の設定] セクションでこれらのパラメーターを設定できます。
パラメーターの説明
カテゴリ | 機能 | パラメーター | 説明 | デフォルト値 |
一般設定 | ジョブ実行タイプ | --job-execution-mode | ジョブの実行タイプを設定します。有効な値は次のとおりです:
リトライ可能なエラーに対するフォールトトレランスの動作は、ジョブタイプによって異なります:
| Sync |
ジョブの再起動設定 | --enable-job-restart | フォールトトレランス条件が満たされた場合、またはランタイム例外が検出された場合にジョブを再起動できるかどうかを指定します。有効な値は次のとおりです:
| False | |
--max-num-of-job-restart | ジョブが再起動できる最大回数。この回数を超えると、AIMaster はジョブを失敗としてマークします。 | 3 | ||
ランタイム設定 説明 これは、実行に失敗するインスタンスがないシナリオに適用されます。 | ハングタスクの異常検出 | --enable-job-hang-detection | 実行中のジョブに対してハング検出を有効にするかどうかを指定します。この機能は同期ジョブのみをサポートします。有効な値は次のとおりです:
| False |
--job-hang-interval | AIMaster がハングと見なすまでにジョブが一時停止できる時間 (秒単位)。正の整数である必要があります。 一時停止がこの値を超えた場合、AIMaster はジョブを異常としてフラグを立て、再起動します。 | 1800 | ||
--enable-c4d-hang-detection | Calibrating Collective Communication over Converged ethernet - Diagnosis (C4D) 検出を有効にして、ジョブハングの原因となる低速ノードや障害ノードを迅速に診断および特定するかどうかを指定します。 説明 このパラメーターは、--enable-job-hang-detection も有効になっている場合にのみ有効です。 | False | ||
終了中のジョブのハング検出 | --enable-job-exit-hang-detection | ジョブが終了しようとしているときにハング検出を有効にするかどうかを指定します。この機能は同期ジョブのみをサポートします。有効な値は次のとおりです:
| False | |
--job-exit-hang-interval | ジョブが終了中に一時停止できる時間 (秒単位)。正の整数である必要があります。 一時停止がこの値を超えた場合、ジョブは異常としてマークされ、再起動します。 | 600 | ||
フォールトトレランス設定 説明 これは、インスタンスの実行に失敗するシナリオに適用されます。 | フォールトトレランスポリシー | --fault-tolerant-policy | フォールトトレランスポリシー。有効な値は次のとおりです:
| ExitCodeAndErrorMsg |
同一エラーの最大発生回数 | --max-num-of-same-error | 単一のインスタンスで同じエラーが発生できる最大回数。 エラー数がこの値を超えた場合、AIMaster はジョブを失敗としてマークします。 | 10 | |
最大許容失敗率 | --max-tolerated-failure-rate | 最大許容失敗率。失敗したインスタンスの割合がこの値を超えた場合、AIMaster はジョブを失敗としてマークします。 デフォルト値の -1 はこの機能を無効にします。たとえば、値が 0.3 の場合、ワーカーの 30% 以上でエラーが発生すると、ジョブは失敗としてマークされます。 | -1 |
設定例
以下の例は、さまざまなトレーニングジョブの一般的なパラメーター設定を示しています。
同期トレーニングジョブ (PyTorch で一般的)
インスタンスが失敗し、フォールトトレランス条件を満たした場合にジョブを再起動します。
--job-execution-mode=Sync --enable-job-restart=True --max-num-of-job-restart=3 --fault-tolerant-policy=ExitCodeAndErrorMsg非同期トレーニングジョブ (TensorFlow ジョブで一般的)
リトライ可能なエラーの場合、失敗したワーカーインスタンスのみを再起動します。デフォルトでは、PS または Chief インスタンスが失敗した場合、ジョブは再起動しません。ジョブの再起動を有効にするには、--enable-job-restart を True に設定します。
--job-execution-mode=Async --fault-tolerant-policy=OnFailureオフライン推論ジョブ (ElasticBatch ジョブで一般的)
インスタンスは独立しており、非同期ジョブに似ています。インスタンスが失敗すると、AIMaster はそのインスタンスのみを再起動します。
--job-execution-mode=Async --fault-tolerant-policy=OnFailure
ステップ 2:フォールトトレランスモニタリングの有効化
DLC ジョブを送信する際に、コンソールまたは SDK を使用してフォールトトレランスモニタリングを有効にできます。
コンソールでのフォールトトレランスモニタリングの有効化
コンソールで DLC トレーニングジョブを送信する際、[フォールトトレランスと診断] セクションに移動し、[自動フォールトトレランス] をオンにして、追加のパラメーターを設定します。詳細については、「トレーニングジョブの作成」をご参照ください。その後、DLC は AIMaster ロールを開始して、ジョブをエンドツーエンドで監視し、エラーを処理します。
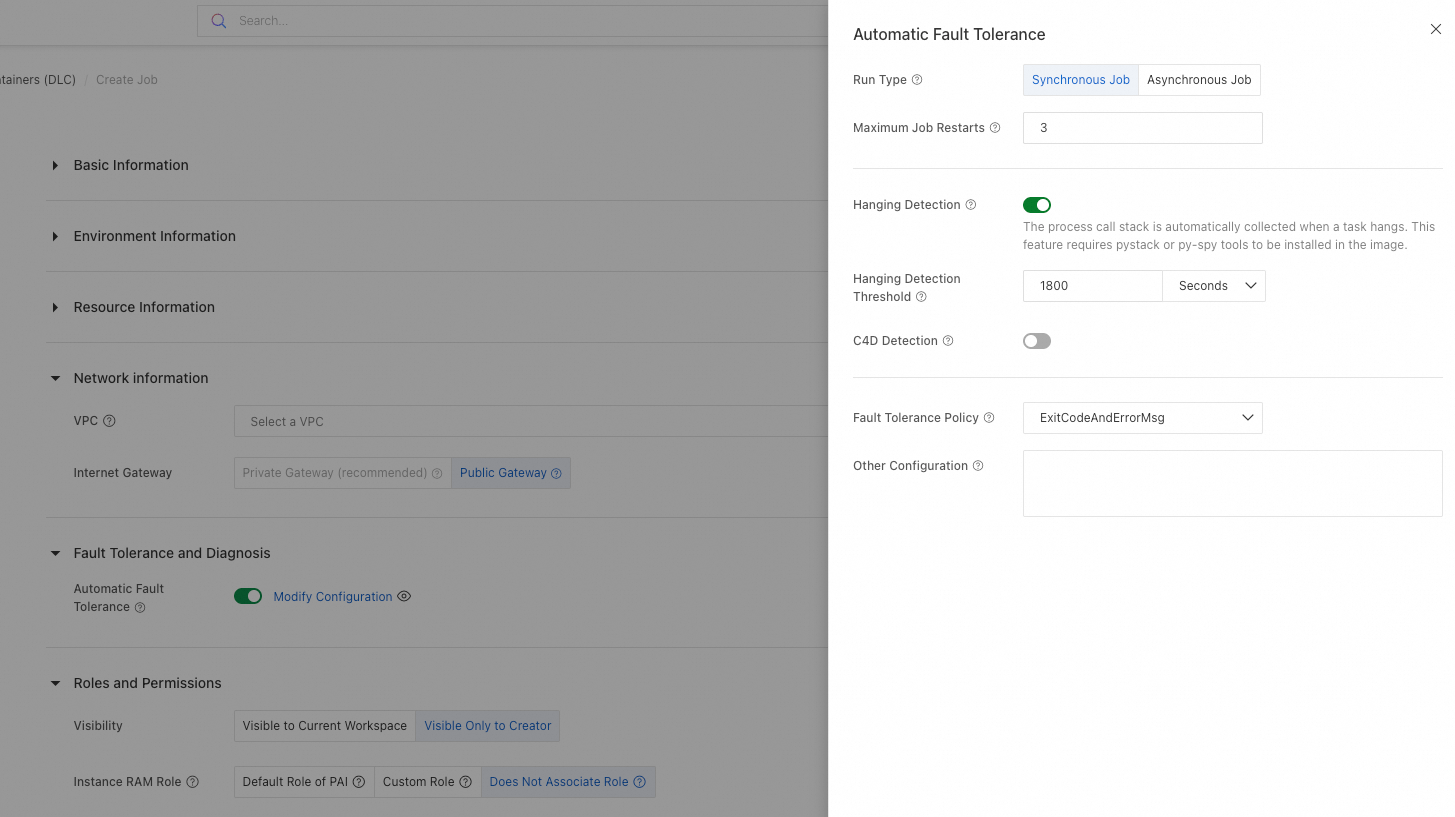
詳細は次のとおりです:
[その他の設定] テキストボックスで追加のパラメーターを設定できます。パラメーターの詳細については、「ステップ 1:フォールトトレランスモニタリングパラメーターの設定」をご参照ください。
[ハング検出] を有効にした後、[C4D 検出] 機能を有効にできます。C4D は、LLM トレーニングにおける低速ノードやハングを特定するための Alibaba Cloud の診断ツールです。 詳細については、「C4D の使用」をご参照ください。
説明C4D は ACCL (Alibaba Cloud パフォーマンス専有型集合通信ライブラリ) に依存します。ACCL がインストールされていることを確認してください。詳細については、「ACCL:Alibaba Cloud パフォーマンス専有型集合通信ライブラリ」をご参照ください。
現在、C4D 検出は、Lingjun AI コンピューティングサービスのリソースを使用する DLC ジョブでのみ利用可能です。
DLC SDK を使用したフォールトトレランスモニタリングの有効化
Go SDK の使用
Go SDK を使用してジョブを送信する際に、フォールトトレランスモニタリングを有効にします。
createJobRequest := &client.CreateJobRequest{} settings := &client.JobSettings{ EnableErrorMonitoringInAIMaster: tea.Bool(true), ErrorMonitoringArgs: tea.String("--job-execution-mode=Sync --enable-job-restart=True --enable-job-hang-detection=True --job-hang-interval=3600"), } createJobRequest.SetSettings(settings)パラメーター:
EnableErrorMonitoringInAIMaster:フォールトトレランスモニタリング機能を有効にするかどうかを指定します。
ErrorMonitoringArgs:フォールトトレランスモニタリングの追加パラメーター。
Python SDK の使用
Python SDK を使用してジョブを送信する際に、フォールトトレランスモニタリングを有効にします。
from alibabacloud_pai_dlc20201203.models import CreateJobRequest, JobSettings settings = JobSettings( enable_error_monitoring_in_aimaster = True, error_monitoring_args = "--job-execution-mode=Sync --enable-job-restart=True --enable-job-hang-detection=True --job-hang-interval=30" ) create_job_req = CreateJobRequest( ... settings = settings, )各項目の意味は次のとおりです:
enable_error_monitoring_in_aimaster:フォールトトレランスモニタリング機能を有効にするかどうかを指定します。
error_monitoring_args:フォールトトレランスモニタリングの追加パラメーター。
ステップ 3:高度なフォールトトレランスモニタリング機能の設定
これらの高度な機能を使用して、ジョブのフォールトトレランスモニタリングをカスタマイズします。
フォールトトレランス通知の設定
ジョブのフォールトトレランスモニタリングを有効にした後、フォールトトレランスイベントの通知を受け取るには、[ワークスペース詳細] ページに移動します。 を選択します。次に、[イベントルールの作成] をクリックし、イベントタイプを [DLC ジョブ] > [自動フォールトトレランス] に設定します。詳細については、「ワークスペースのイベントセンター」をご参照ください。
トレーニングジョブで NaN 損失などの例外が発生した場合、コード内で AIMaster SDK を使用してカスタム通知メッセージを送信できます:
この機能を使用するには、AIMaster wheel パッケージをインストールする必要があります。詳細については、「よくある質問」をご参照ください。
from aimaster import job_monitor as jm
job_monitor_client = jm.Monitor(config=jm.PyTorchConfig())
...
if loss == Nan and rank == 0:
st = job_monitor_client.send_custom_message(content="The training loss of the job is NaN.")
if not st.ok():
print('failed to send message, error %s' % st.to_string())カスタムフォールトトレランスキーワードの設定
フォールトトレランスモニタリングには、一般的なリトライ可能なエラーに対する組み込みの検出機能があります。カスタムキーワードを定義することもできます。失敗したインスタンスのログにこれらのキーワードのいずれかが含まれている場合、AIMaster はそのエラーをリトライ可能として扱います。モニタリングモジュールは、失敗したインスタンスのログの末尾をスキャンしてこれらのキーワードを見つけます。
フォールトトレランスポリシーを ExitCodeAndErrorMsg に設定してください。
PyTorch ジョブのカスタムフォールトトレランスキーワードの設定例
from aimaster import job_monitor as jm jm_config_params = {} jm_config = jm.PyTorchConfig(**jm_config_params) monitor = jm.Monitor(config=jm_config) monitor.set_retryable_errors(["connect timeout", "error_yyy", "error_zzz"])monitor.set_retryable_errors で設定されたパラメーターが、カスタムフォールトトレランスキーワードです。
TensorFlow ジョブのカスタムフォールトトレランスキーワードの設定例
from aimaster import job_monitor as jm jm_config_params = {} jm_config = jm.TFConfig(**jm_config_params) monitor = jm.Monitor(config=jm_config) monitor.set_retryable_errors(["connect timeout", "error_yyy", "error_zzz"])
段階的なジョブハング検出の設定
デフォルトでは、ハング検出設定はジョブ全体に適用されます。しかし、ジョブは段階的に実行されます。たとえば、初期化中にはノードが通信を確立するのに時間がかかる場合がありますが、トレーニング中にはログの更新がより頻繁になります。トレーニングプロセス中のハングをより迅速に検出するために、DLC は段階的なハング検出を提供しており、これにより異なる段階に対して異なる検出間隔を設定できます。
monitor.reset_config(jm_config_params)
# 例:
# monitor.reset_config(job_hang_interval=10)
# または
# config_params = {"job_hang_interval": 10, }
# monitor.reset_config(**config_params)以下は、PyTorch ジョブの段階的なハング検出の例です。
import torch
import torch.distributed as dist
from aimaster import job_monitor as jm
jm_config_params = {
"job_hang_interval": 1800 # グローバルな 30 分間の検出。
}
jm_config = jm.PyTorchConfig(**jm_config_params)
monitor = jm.Monitor(config=jm_config)
dist.init_process_group('nccl')
...
# aimaster sdk にこれらの 2 つの関数を実装
# ユーザーは自分の関数にアノテーションを追加するだけ
def reset_hang_detect(hang_seconds):
jm_config_params = {
"job_hang_interval": hang_seconds
}
monitor.reset_config(**jm_config_params)
def hang_detect(interval):
reset_hang_detect(interval)
...
@hang_detect(180) # ハング検出を 3 分にリセット、関数スコープのみ
def train():
...
@hang_detect(-1) # ハング検出を一時的に無効化、関数スコープのみ
def test():
...
for epoch in range(0, 100):
train(epoch)
test(epoch)
self.scheduler.step()
C4D の使用
C4D は、大規模モデルトレーニングにおける低速ノードやハングを診断するための Alibaba Cloud 独自のツールです。C4D は ACCL に依存します。ACCL がインストールされていることを確認してください。詳細については、「ACCL:Alibaba Cloud パフォーマンス専有型集合通信ライブラリ」をご参照ください。現在、DLC ジョブで Lingjun リソースを選択した場合に C4D 検出機能を使用できます。
機能概要
C4D はすべてのノードからステータス情報を集約し、ノードに通信レイヤーまたはその他の問題があるかどうかを判断します。次の図は、システムアーキテクチャーを示しています。
パラメーターの説明
C4D 検出機能を有効にすると、[その他の設定] テキストボックスで次のパラメーターを設定できます:
パラメーター | 説明 | 値の例 |
--c4d-log-level | C4D の出力ログレベルを設定します。有効な値は次のとおりです:
デフォルト値は Warning で、Warning および Error レベルのログを出力します。通常の運用ではデフォルト値の使用を推奨します。パフォーマンスの問題をトラブルシューティングするには、Info に設定できます。 |
|
--c4d-common-envs | C4D 実行用の環境変数を設定します。
|
|
Error レベルのログの場合、AIMaster は対応するノードを自動的に隔離し、ジョブを再起動します。各ログレベルの処理ロジックは次のとおりです:
エラーレベル | エラーの説明 | アクション |
Error | デフォルトでは、通信レイヤーのジョブハングが 3 分を超えるとジョブは失敗します。このデフォルトは、C4D_HANG_TIMEOUT および C4D_HANG_TIMES パラメーターを設定することで変更できます。 | AIMaster はログで報告されたノードを直接隔離します。 |
Warn | デフォルトでは、通信レイヤーのジョブハングが 10 秒を超えるとパフォーマンスに影響しますが、ジョブは失敗しません。このデフォルトは、C4D_HANG_TIMEOUT パラメーターを設定することで変更できます。 | ログ内のノードは自動的に隔離されず、手動での確認が必要です。 |
非通信レイヤーのジョブハングが 10 秒を超えると、ジョブが失敗する可能性があります。 | ログ内のノードは自動的に隔離されず、手動での確認が必要です。 | |
Info | 通信レイヤーの低速化と非通信レイヤーの低速化。 | これらの診断ログは主にパフォーマンスの問題に関するものであり、手動での確認が必要です。 |
DLC ジョブの実行が遅い、またはハングしていることがわかった場合は、DLC ジョブリストに移動し、ジョブ名をクリックして ジョブ詳細ページに移動します。下部の [インスタンス] セクションで、AIMaster ノードのログを表示して C4D の診断結果を確認します。診断結果の詳細については、「診断結果の例」をご参照ください。
診断結果の例
RankCommHang:ノードの通信レイヤーでのハングを示します。

RankNonCommHang:通信レイヤー外 (例:計算プロセス内) のノードでのハングを示します。

RankCommSlow:ノードの通信レイヤーでの低速化を示します。
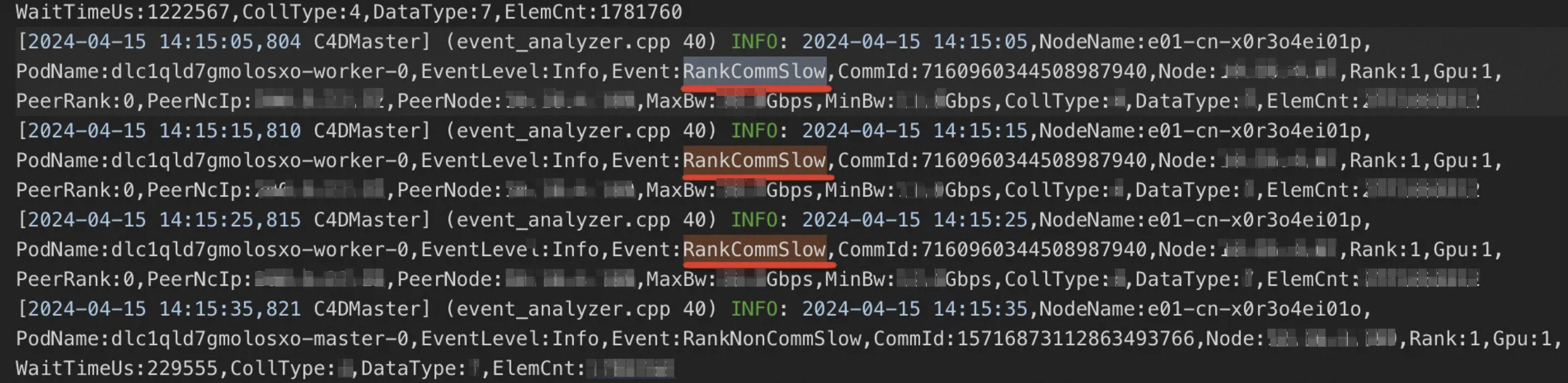
RankNonCommSlow:通信レイヤー外のノードでの低速化を示します。

よくある質問
特定の Python バージョン (3.6、3.8、または 3.10) 用の AIMaster SDK をインストールする方法
ご利用の Python 環境に一致する wheel (.whl) ファイルの直接 URL を使用して、pip で AIMaster SDK をインストールします。ご利用の Python バージョンに対応するコマンドを選択してください:
# Python 3.6
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp36-cp36m-linux_x86_64.whl
# Python 3.8
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp38-cp38-linux_x86_64.whl
# Python 3.10
pip install -U http://odps-release.cn-hangzhou.oss.aliyun-inc.com/aimaster/pai_aimaster-1.2.1-cp310-cp310-linux_x86_64.whl