Machine Learning Designer の Python スクリプトコンポーネントを使用して、依存パッケージをインストールし、カスタム Python 関数を実行します。
コンポーネントの場所
Python スクリプトは、Machine Learning Designer コンポーネントリストの UserDefinedScript フォルダにあります。
前提条件
-
Deep Learning Containers (DLC) に必要な権限を付与します。詳細については、「クラウドサービスの依存関係と権限付与:DLC」をご参照ください。
-
Python スクリプトコンポーネントは DLC 計算リソース上で実行されます。DLC 計算リソースをワークスペースに関連付けます。詳細については、「ワークスペースの管理」をご参照ください。
-
Python スクリプトコンポーネントは、コードを Object Storage Service (OSS) に保存します。OSS バケットを作成します。詳細については、「バケットの作成」をご参照ください。
重要OSS バケットは、Machine Learning Designer および DLC と同じリージョンにある必要があります。
-
このコンポーネントを使用する RAM ユーザーは、ワークスペースで Algorithm Development ロールを持っている必要があります。詳細については、「ワークスペースメンバーの管理」をご参照ください。RAM ユーザーがデータソースとして MaxCompute も使用する必要がある場合は、[MaxCompute 開発者] ロールを付与します。
コンポーネントの設定
-
入力ポート
Python スクリプトコンポーネントには 4 つの入力ポートがあります。これらを OSS パスまたは MaxCompute テーブルからのデータに接続します。
-
OSS パス入力
上流コンポーネントの OSS パスからの入力は、Python スクリプトが実行されるノードにマウントされます。システムはマウントされたファイルパスを引数として自動的に渡します。たとえば、
--input1 /ml/input/data/input1は、最初の入力ポートのパスを指定します。スクリプトでは、マウントされたファイルを/ml/input/data/input1からローカルファイルのように読み取ります。 -
MaxCompute テーブル入力
MaxCompute テーブル入力はマウントされません。代わりに、システムはテーブル情報を URI 引数としてスクリプトに自動的に渡します。たとえば、
python main.py --input1 odps://some-project-name/tables/tableは、最初の入力ポートの MaxCompute テーブルを示します。URI ベースの入力の場合、コンポーネントのコードテンプレートの `parse_odps_url` 関数を使用して、ProjectName、TableName、Partition などのメタデータを解析します。詳細については、「使用例」をご参照ください。
-
-
出力ポート
Python スクリプトコンポーネントには 4 つの出力ポートがあります。[OSS 出力ポート 1] と [OSS 出力ポート 2] は OSS パス出力用です。[テーブル出力ポート 1] と [テーブル出力ポート 2] は MaxCompute テーブル出力用です。
-
OSS パス出力
[コード設定] タブの [ジョブ出力パス] パラメーターに設定された OSS パスは、自動的に
/ml/output/にマウントされます。コンポーネントの [OSS 出力ポート 1] と [OSS 出力ポート 2] は、それぞれサブディレクトリ/ml/output/output1と/ml/output/output2に対応します。スクリプトでは、下流コンポーネントに渡す必要があるファイルを、ローカルファイルのようにこれらのディレクトリに書き込みます。 -
MaxCompute テーブル出力
現在のワークスペースに MaxCompute プロジェクトが設定されている場合、システムは一時テーブル URI を Python スクリプトに自動的に渡します。例:
python main.py --output3 odps://<some-project-name>/tables/<output-table-name>。PyODPS を使用して、一時テーブル URI で指定されたテーブルを作成し、Python スクリプトで処理されたデータをこのテーブルに書き込み、コンポーネント接続を介してテーブルを下流コンポーネントに渡します。詳細については、以下の例をご参照ください。
-
-
パラメーター
コード設定
パラメーター
説明
ジョブ出力パス
ジョブ出力用の OSS パス。
-
設定された OSS ディレクトリは、ジョブコンテナの
/ml/output/パスにマウントされます。/ml/output/パスに書き込まれたデータは、対応する OSS ディレクトリに永続化されます。 -
コンポーネントの出力ポート [OSS 出力-1] と [OSS 出力-2] は、それぞれ
/ml/output/パスのサブパスoutput1とoutput2に対応します。コンポーネントの OSS 出力ポートが下流コンポーネントに接続されると、下流コンポーネントは対応するサブパスからデータを受信します。
コードソース
(いずれかを選択)
リテラルコード
-
Python コード:コードが保存される OSS パス。エディタで記述されたコードはこの OSS パスに保存されます。Python コードのデフォルトのファイル名は
main.pyです。重要初めて [保存] をクリックする前に、指定された OSS パスに同じ名前のファイルが含まれていないことを確認してください。そうしないと、既存のファイルが上書きされます。
-
Python コードエディタ:コードエディタはデフォルトでサンプルコードを提供します。詳細については、「使用例」をご参照ください。エディタに直接コードを記述します。
Git 設定の指定
-
Git リポジトリのアドレス:Git リポジトリのアドレス。
-
コードブランチ:コードブランチ。デフォルト値は master です。
-
コードコミット:コミット ID。このパラメーターはブランチよりも優先度が高くなります。このパラメーターを指定すると、ブランチ設定は無視されます。
-
Git ユーザー名:プライベートリポジトリにアクセスする必要がある場合に必須です。
-
Git アクセストークン:プライベートコードリポジトリにアクセスするために必要です。詳細については、「付録:GitHub アカウントトークンの取得」をご参照ください。
コードソースの選択
-
コードソースリポジトリの選択:作成したコード設定を選択します。詳細については、「コード設定」をご参照ください。
-
コードブランチ:コードブランチ。デフォルト値は master です。
-
コードコミット:コミット ID。このパラメーターはブランチよりも優先度が高くなります。このパラメーターを指定すると、ブランチ設定は無視されます。
OSS パスの選択
[OSS コードパス] フィールドで、コードがアップロードされているパスを選択します。
コマンド
実行するコマンド。例:
python main.py。説明システムは、スクリプト名とコンポーネントのポート接続に基づいて実行コマンドを自動的に生成します。手動での設定は不要です。
詳細オプション
-
サードパーティの依存関係:Python の
requirements.txt形式を使用してインストールするサードパーティライブラリを指定します。システムは、ノードが実行される前にこれらのライブラリを自動的にインストールします。cycler==0.10.0 # via matplotlib kiwisolver==1.2.0 # via matplotlib matplotlib==3.2.1 numpy==1.18.5 pandas==1.0.4 pyparsing==2.4.7 # via matplotlib python-dateutil==2.8.1 # via matplotlib, pandas pytz==2020.1 # via pandas scipy==1.4.1 # via seaborn -
コンテナ監視を有効にする:このオプションを選択すると、設定用のテキストボックスが表示されます。テキストボックスでフォールトトレランス監視のパラメーターを指定します。
実行設定
パラメーター
説明
Select Resource Group
パブリック DLC リソースグループを選択します:
-
パブリックリソースグループを選択した場合は、[インスタンスタイプ] パラメーターを設定します。[CPU] または [GPU] インスタンスを選択します。デフォルト値は
ecs.c6.largeです。
デフォルトでは、現在のワークスペース内の DLC クラウドネイティブリソースのデフォルトリソースグループが使用されます。
VPC Settings
既存の Virtual Private Cloud (VPC) を選択します。
Security Group
既存のセキュリティグループを選択します。
高度なオプション
このオプションを選択した場合は、次のパラメーターを設定します:
-
インスタンス数:インスタンスの数。デフォルト値は 1 です。
-
ジョブイメージ URI:ジョブイメージの URI。デフォルトのイメージは、オープンソースの XGBoost 1.6.0 を使用します。深層学習フレームワークを使用する必要がある場合は、イメージを変更してください。
-
ジョブタイプ:送信したコードが分散実行用に実装されている場合にのみ、このパラメーターを変更してください。次の値がサポートされています:
-
XGBoost/LightGBM ジョブ
-
TensorFlow ジョブ
-
PyTorch ジョブ
-
MPI ジョブ
-
-
使用例
デフォルトのサンプルコード
Python スクリプトコンポーネントは、デフォルトで次のサンプルコードを提供します。
import os
import argparse
import json
"""
Python スクリプトコンポーネントのサンプルコード
"""
# 現在のワークスペースのデフォルトの MaxCompute 実行環境。MaxCompute プロジェクト名とエンドポイントが含まれます。
# この環境は、現在のワークスペースに MaxCompute プロジェクトが存在する場合にのみ挿入されます。
# 例:{"endpoint": "http://service.cn.maxcompute.aliyun-inc.com/api", "odpsProject": "lq_test_mc_project"}
ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION"
def init_odps():
from odps import ODPS
# 現在のワークスペースのデフォルトの MaxCompute プロジェクトに関する情報。
mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION])
o = ODPS(
access_id="<YourAccessKeyId>",
secret_access_key="<YourAccessKeySecret>",
# プロジェクトが配置されているリージョンに基づいてエンドポイントを選択します。例:http://service.cn-shanghai.maxcompute.aliyun-inc.com/api
endpoint=mc_execution["endpoint"],
project=mc_execution["odpsProject"],
)
return o
def parse_odps_url(table_uri):
from urllib import parse
parsed = parse.urlparse(table_uri)
project_name = parsed.hostname
r = parsed.path.split("/", 2)
table_name = r[2]
if len(r) > 3:
partition = r[3]
else:
partition = None
return project_name, table_name, partition
def parse_args():
parser = argparse.ArgumentParser(description="PythonV2 component script example.")
parser.add_argument("--input1", type=str, default=None, help="Component input port 1.")
parser.add_argument("--input2", type=str, default=None, help="Component input port 2.")
parser.add_argument("--input3", type=str, default=None, help="Component input port 3.")
parser.add_argument("--input4", type=str, default=None, help="Component input port 4.")
parser.add_argument("--output1", type=str, default=None, help="Output OSS port 1.")
parser.add_argument("--output2", type=str, default=None, help="Output OSS port 2.")
parser.add_argument("--output3", type=str, default=None, help="Output MaxComputeTable 1.")
parser.add_argument("--output4", type=str, default=None, help="Output MaxComputeTable 2.")
args, _ = parser.parse_known_args()
return args
def write_table_example(args):
# 例:PAI が提供するパブリックテーブルから、テーブル出力ポート 1 (--output3) に指定された一時テーブルにデータをコピーする SQL ステートメントを実行します。
output_table_uri = args.output3
o = init_odps()
project_name, table_name, partition = parse_odps_url(output_table_uri)
o.run_sql(f"create table {project_name}.{table_name} as select * from pai_online_project.heart_disease_prediction;")
def write_output1(args):
# 例:マウントされた OSS パス (OSS 出力ポート 1 のサブディレクトリ) にデータ結果を書き込みます。結果は接続を介して下流コンポーネントに渡すことができます。
output_path = args.output1
os.makedirs(output_path, exist_ok=True)
p = os.path.join(output_path, "result.text")
with open(p, "w") as f:
f.write("TestAccuracy=0.88")
if __name__ == "__main__":
args = parse_args()
print("Input1={}".format(args.input1))
print("Output1={}".format(args.output1))
# write_table_example(args)
# write_output1(args)
一般的な関数の説明:
-
init_odps():MaxCompute テーブルデータを読み取るための ODPS インスタンスを初期化します。ご利用の AccessKeyId と AccessKeySecret を指定してください。AccessKey ペアの取得方法の詳細については、「AccessKey ペアの取得」をご参照ください。 -
parse_odps_url(table_uri):入力された MaxCompute テーブル URI を解析し、プロジェクト名、テーブル名、パーティションを返します。table_uriの形式はodps://${your_projectname}/tables/${table_name}/${pt_1}/${pt_2}/です。たとえば、odps://test/tables/iris/pa=1/pb=1の場合、pa=1/pb=1は複数レベルのパーティションです。 -
parse_args():スクリプトに渡された引数を解析します。入力データと出力データは、実行されるスクリプトに引数として渡されます。
例 1:他のコンポーネントとの連携
この例では、心臓病予測テンプレートを変更して、Python スクリプトコンポーネントを他の Machine Learning Designer コンポーネントと組み合わせて使用する方法を示します。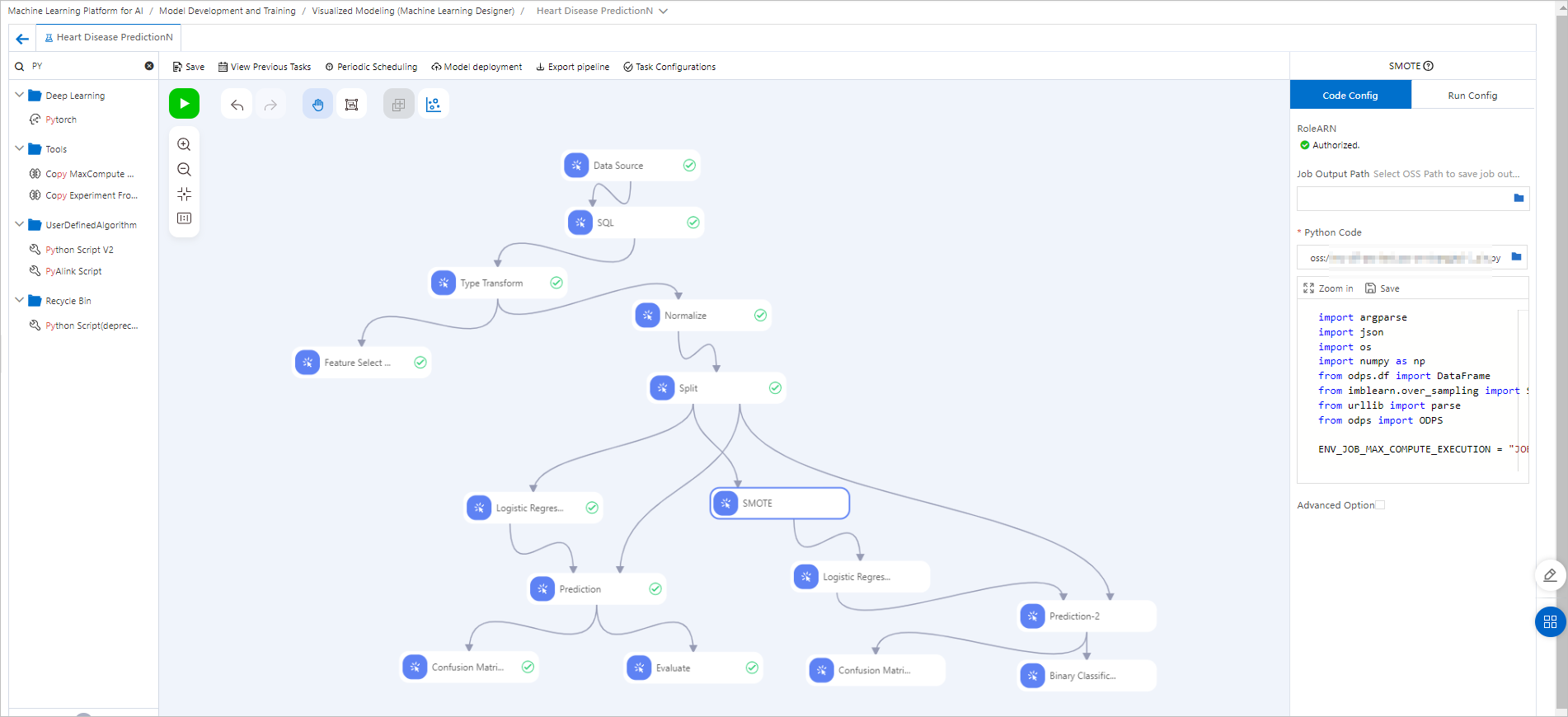 パイプライン設定:
パイプライン設定:
-
心臓病予測テンプレートからパイプラインを作成して開きます。詳細については、「心臓病予測」をご参照ください。
-
Python スクリプトコンポーネントをキャンバスにドラッグし、名前を `SMOTE` に変更して、次のコードを設定します。
重要imblearnライブラリはイメージに含まれていません。[コード設定] タブの [サードパーティの依存関係] フィールドに `imblearn` を追加してください。ライブラリは、ノードが実行される前に自動的にインストールされます。import argparse import json import os from odps.df import DataFrame from imblearn.over_sampling import SMOTE from urllib import parse from odps import ODPS ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION" def init_odps(): # 現在のワークスペースのデフォルトの MaxCompute プロジェクトに関する情報。 mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION]) o = ODPS( access_id="<Your_AccessKeyId>", secret_access_key="<Your_AccessKeySecret>", # プロジェクトが配置されているリージョンに基づいてエンドポイントを選択します。例:http://service.cn-shanghai.maxcompute.aliyun-inc.com/api endpoint=mc_execution["endpoint"], project=mc_execution["odpsProject"], ) return o def get_max_compute_table(table_uri, odps): parsed = parse.urlparse(table_uri) project_name = parsed.hostname table_name = parsed.path.split('/')[2] table = odps.get_table(project_name + "." + table_name) return table def run(): parser = argparse.ArgumentParser(description='PythonV2 component script example.') parser.add_argument( '--input1', type=str, default=None, help='Component input port 1.' ) parser.add_argument( '--output3', type=str, default=None, help='Component input port 1.' ) args, _ = parser.parse_known_args() print('Input1={}'.format(args.input1)) print('output3={}'.format(args.output3)) o = init_odps() imbalanced_table = get_max_compute_table(args.input1, o) df = DataFrame(imbalanced_table).to_pandas() sm = SMOTE(random_state=2) X_train_res, y_train_res = sm.fit_resample(df, df['ifhealth'].ravel()) new_table = o.create_table(get_max_compute_table(args.output3, o).name, imbalanced_table.schema, if_not_exists=True) with new_table.open_writer() as writer: writer.write(X_train_res.values.tolist()) if __name__ == '__main__': run()コード内の <Your_AccessKeyId> と <Your_AccessKeySecret> を、ご自身の AccessKeyId と AccessKeySecret に置き換えてください。AccessKey ペアの取得方法の詳細については、「AccessKey ペアの取得」をご参照ください。
-
SMOTE コンポーネントを Split コンポーネントの下流に接続します。SMOTE アルゴリズムを使用してトレーニングデータをオーバーサンプリングし、マイノリティクラスの合成サンプルを作成することでクラス分布のバランスを取ります。
-
SMOTE コンポーネントからの新しいデータを 二項分類ロジスティック回帰 コンポーネントに接続してトレーニングを行います。
-
トレーニング済みのモデルを、左側のブランチのモデルと同じ予測データおよび評価コンポーネントに接続して、並べて比較します。コンポーネントが正常に実行された後、可視化アイコン (
 ) をクリックして最終的な評価結果を表示します。
) をクリックして最終的な評価結果を表示します。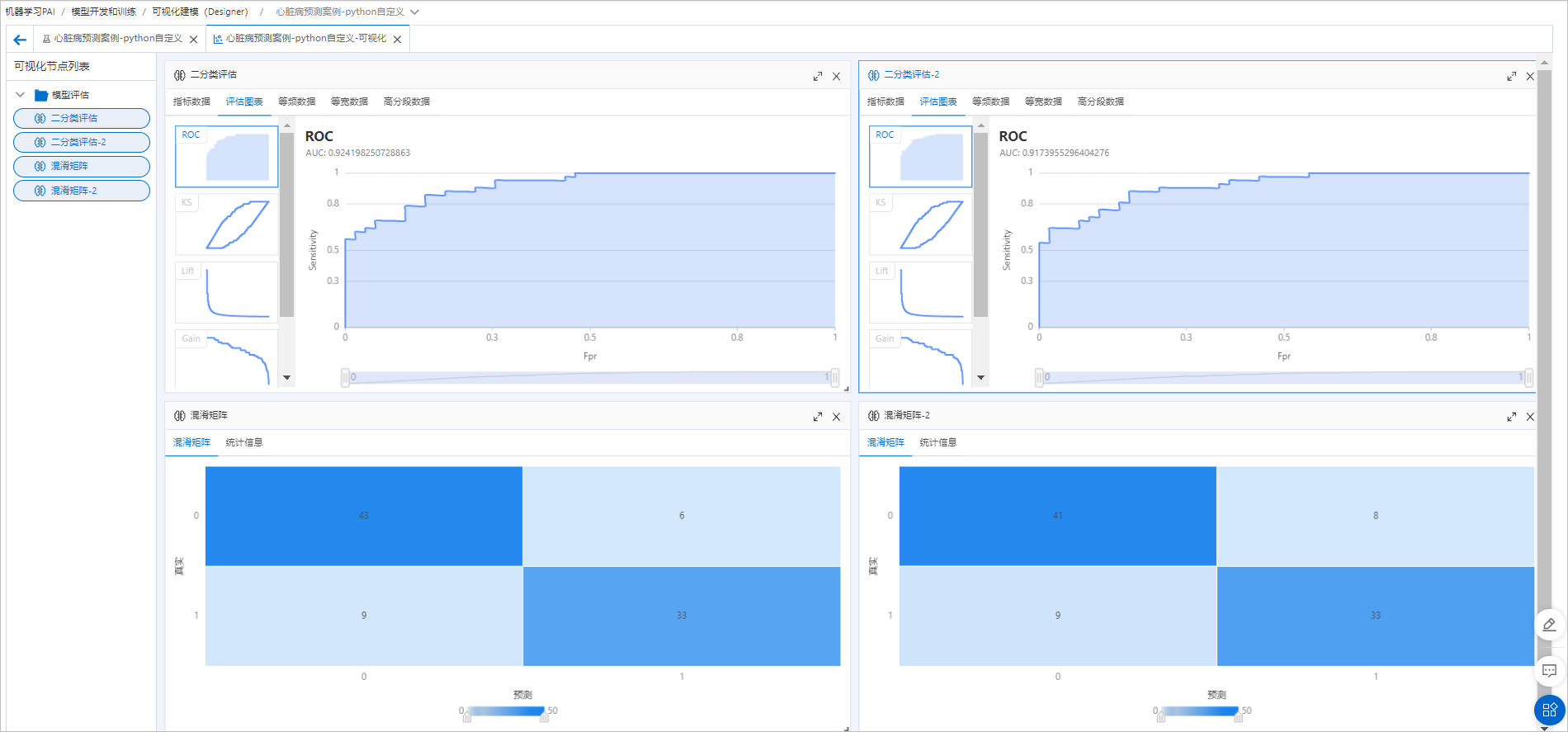
追加のオーバーサンプリングではモデルのパフォーマンスが大幅に向上しないことから、元のサンプル分布とモデルがすでに効果的であったことがわかります。
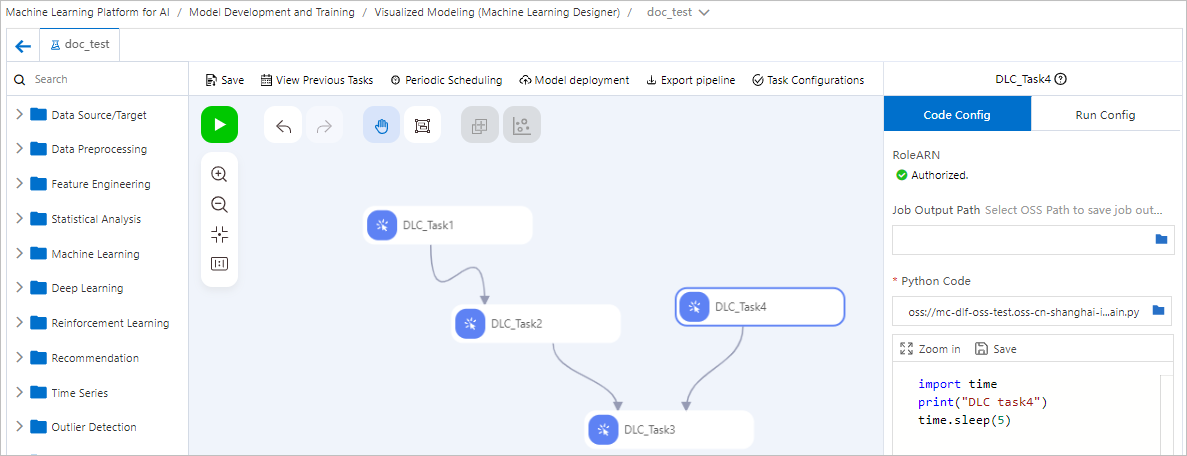
例 2:DLC ジョブのオーケストレーション
Machine Learning Designer で複数の Python スクリプトコンポーネントを接続して、DLC ジョブのパイプラインをオーケストレーションおよびスケジューリングします。次の図は、有向非巡回グラフ (DAG) で配置された 4 つの DLC ジョブを開始して、その実行順序を制御する例を示しています。
DLC ジョブの実行コードが上流ノードからデータを読み取ったり、下流ノードにデータを渡したりする必要がない場合、ノード間の接続はスケジューリングの依存関係と実行順序のみを表します。
 Machine Learning Designer で開発したパイプライン全体を DataWorks にデプロイして、スケジュール実行します。詳細については、「DataWorks を使用した Machine Learning Designer パイプラインのオフライン実行のスケジューリング」をご参照ください。
Machine Learning Designer で開発したパイプライン全体を DataWorks にデプロイして、スケジュール実行します。詳細については、「DataWorks を使用した Machine Learning Designer パイプラインのオフライン実行のスケジューリング」をご参照ください。
例 3:グローバル変数の受け渡し
-
グローバル変数の設定
ビジュアルモデリングのパイプラインページで、キャンバスの空白のエリアをクリックし、右側のペインの[グローバル変数] タブで変数を設定します。
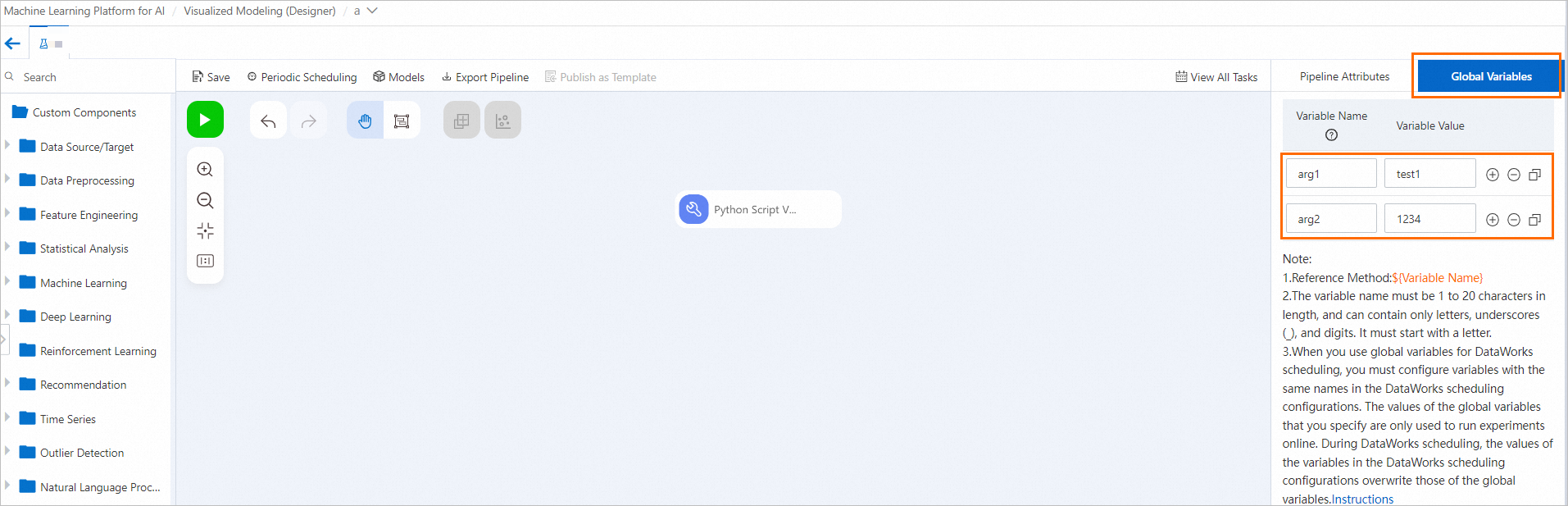
-
設定したグローバル変数を Python スクリプトコンポーネントに渡すには、2 つの方法があります。
-
Python スクリプトコンポーネントノードをクリックします。右側のペインの [コード設定] タブで、[詳細オプション] を選択し、[コマンド] フィールドでグローバル変数を入力パラメーターとして設定します。
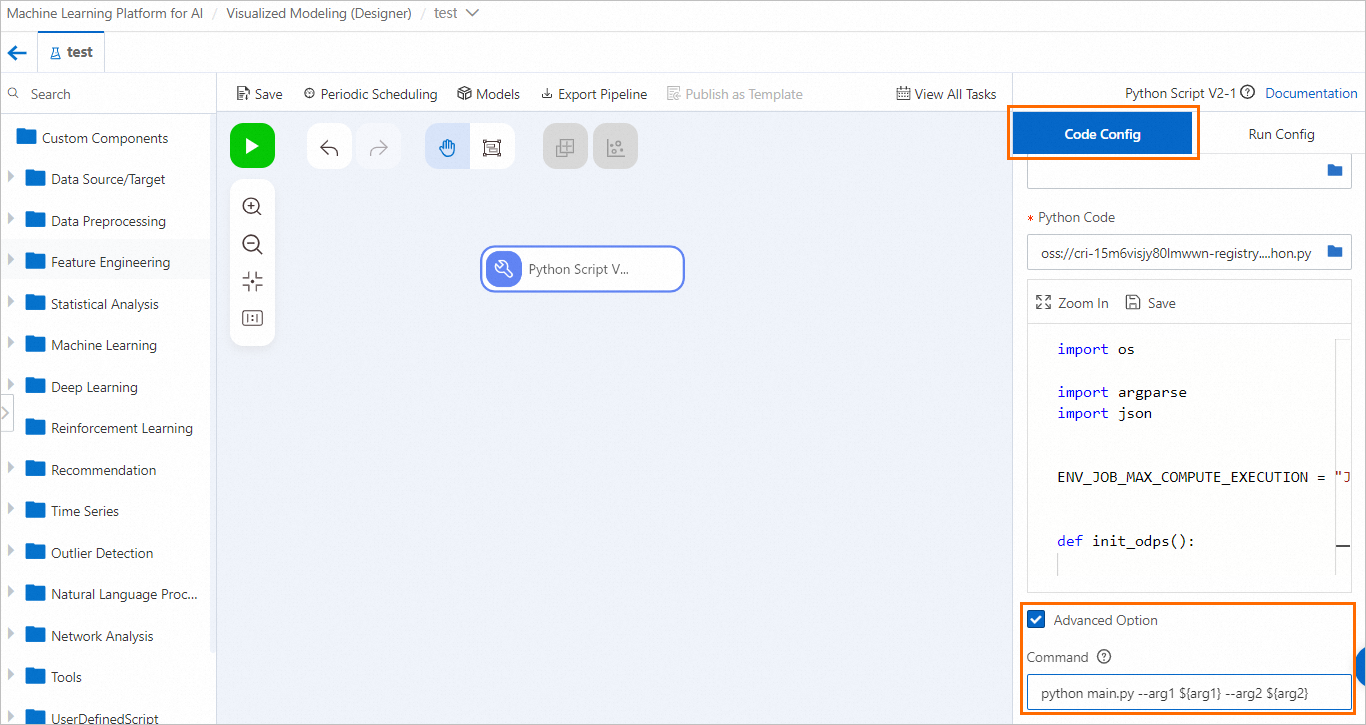
-
Python コードを変更して、`argparse` を使用して引数を解析します。
更新された Python コードは次のとおりです。このコードは、ステップ 1 で設定したグローバル変数を例として使用しています。実際のグローバル変数に応じてコードを更新してください。Python スクリプトコンポーネントノードの [コード設定] タブのコード編集エリアでコードを置き換えます。
import os import argparse import json """ Python スクリプトコンポーネントのサンプルコード """ ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION" def init_odps(): from odps import ODPS mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION]) o = ODPS( access_id="<YourAccessKeyId>", secret_access_key="<YourAccessKeySecret>", endpoint=mc_execution["endpoint"], project=mc_execution["odpsProject"], ) return o def parse_odps_url(table_uri): from urllib import parse parsed = parse.urlparse(table_uri) project_name = parsed.hostname r = parsed.path.split("/", 2) table_name = r[2] if len(r) > 3: partition = r[3] else: partition = None return project_name, table_name, partition def parse_args(): parser = argparse.ArgumentParser(description="PythonV2 component script example.") parser.add_argument("--input1", type=str, default=None, help="Component input port 1.") parser.add_argument("--input2", type=str, default=None, help="Component input port 2.") parser.add_argument("--input3", type=str, default=None, help="Component input port 3.") parser.add_argument("--input4", type=str, default=None, help="Component input port 4.") parser.add_argument("--output1", type=str, default=None, help="Output OSS port 1.") parser.add_argument("--output2", type=str, default=None, help="Output OSS port 2.") parser.add_argument("--output3", type=str, default=None, help="Output MaxComputeTable 1.") parser.add_argument("--output4", type=str, default=None, help="Output MaxComputeTable 2.") # 設定されたグローバル変数に基づいてコードを追加します。 parser.add_argument("--arg1", type=str, default=None, help="Argument 1.") parser.add_argument("--arg2", type=int, default=None, help="Argument 2.") args, _ = parser.parse_known_args() return args def write_table_example(args): output_table_uri = args.output3 o = init_odps() project_name, table_name, partition = parse_odps_url(output_table_uri) o.run_sql(f"create table {project_name}.{table_name} as select * from pai_online_project.heart_disease_prediction;") def write_output1(args): output_path = args.output1 os.makedirs(output_path, exist_ok=True) p = os.path.join(output_path, "result.text") with open(p, "w") as f: f.write("TestAccuracy=0.88") if __name__ == "__main__": args = parse_args() print("Input1={}".format(args.input1)) print("Output1={}".format(args.output1)) # 設定されたグローバル変数に基づいてコードを追加します。 print("Argument1={}".format(args.arg1)) print("Argument2={}".format(args.arg2)) # write_table_example(args) # write_output1(args)
-