Dataset Accelerator (DatasetAcc) は、Alibaba Cloud が提供する Platform as a Service (PaaS) サービスであり、クラウド上の AI ワークロード向けにデータセットのアクセスを高速化します。機械学習のトレーニングシナリオにおいて、DatasetAcc はご利用のトレーニングデータセットを事前に分析・処理し、さまざまなクラウドネイティブなトレーニングエンジンに対して統一されたアクセス高速化ソリューションを提供することで、全体的なトレーニング効率を向上させます。
アーキテクチャ
以下の図は、データセットアクセラレータのアーキテクチャを示しています。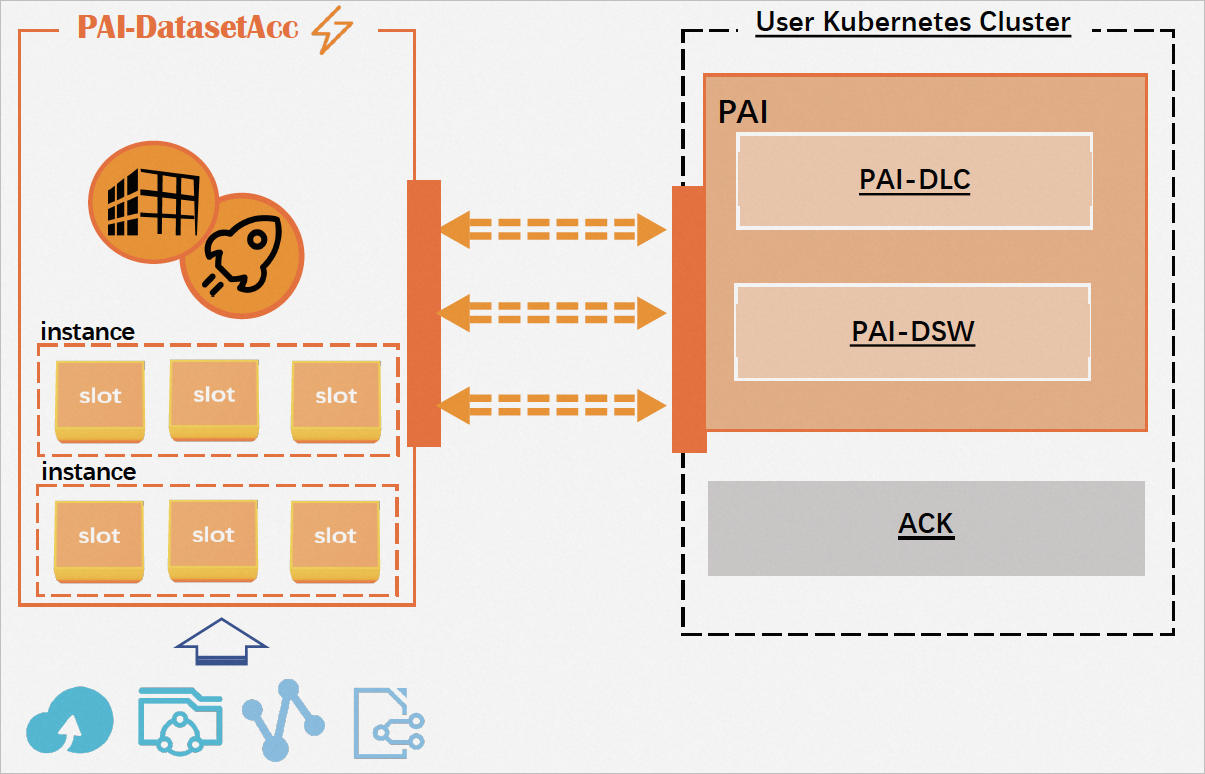
制限事項
データセットアクセラレータをご利用になる前に、以下の制限事項をご確認ください。
-
加速対象となるデータセットは、Alibaba Cloud 上に保存されているものに限られます(例:Object Storage Service (OSS) や Cloud Parallel File System (CPFS) に格納されたデータセット)。
-
データセットは暗号化されておらず、Alibaba Cloud 上に保存されている必要があります。
-
データセットアクセラレータ内のデータは読み取り専用です。動的なデータ書き込みはサポートされていません。
-
単一のデータセットアクセラレータインスタンスで加速可能なデータセットの合計サイズは最大 100 TB です。
課金
データセットアクセラレータは、購入した容量および利用期間に基づいて課金されます。詳細については、「データセットアクセラレータ (DatasetAccelerator) の課金」をご参照ください。
主な機能
-
多数の小ファイルに対する最適化されたトレーニング
データセットアクセラレータは、画像、テキスト、動画など多数の小ファイルを含むトレーニングシナリオにおけるパフォーマンスを向上させます。ディープ ラーニングのトレーニングで使用されるモデルの種類やネットワーク構造に応じて、データを事前にパッケージ化・処理します。
-
フルマネージドですぐに使える
これはフルマネージドなクラウドサービスであり、有効化後すぐに利用可能で、操作も簡単です。
-
柔軟かつスケーラブル
Infrastructure as a Service (IaaS) レイヤーの機能を活用し、迅速なリソースのスケーリングと弾力性を実現します。
-
共有アクセス
複数のトレーニングクラスターが、データセットアクセラレータ内で同一のデータセットを共有してトレーニングできます。
-
セキュアなマルチテナント対応
異なるユーザー間でのデータセキュリティを確保するため、マルチテナントデータ分離を提供します。
用語
データセットアクセラレータをご利用になる前に、以下の基本概念をご理解ください。
-
データセットアクセラレータインスタンス(インスタンス)
インスタンスは、データセットアクセラレータの課金および管理単位です。サブスクリプションインスタンスを作成すると、システムが対応するクラウドリソースを予約し、課金が即時開始されます。従量課金インスタンスの場合は、アクセラレーションスロットの使用量に基づいて課金されます。
-
アクセラレーションスロット(スロット)
スロットは、単一のデータセットに対するサービス単位です。1 つのデータセットアクセラレータインスタンス内に複数のアクセラレーションスロットを作成できます。各スロットは 1 つのデータセットを加速します。これにより、複数のディープ ラーニングトレーニングタスクが異なるデータセットを用いて同時トレーニングを実行できます。
-
インスタンスとスロットの関係
複数のデータセットアクセラレータインスタンスを作成できます。各インスタンスに対して、異なる容量の複数のアクセラレーションスロットを作成できます。インスタンスとそのスロットの関係は 1 対 n です。各アクセラレーションスロットは 1 つのデータセットストレージにアタッチされます。

操作手順
データセットアクセラレータの利用手順は、以下のとおりです。
-
ビジネスニーズ、チーム規模、トレーニング頻度、データセットサイズに応じてデータセットアクセラレータインスタンスを作成します。1 つのインスタンスで、複数のアクセラレーションスロットを用いて、異なるトレーニングタスク向けに複数のデータセットを同時に加速できます。
データセットアクセラレータは追加のクラウドリソースを消費します。重要なトレーニングタスクの加速に必要なリソースを確実に確保するため、データセットアクセラレータインスタンスのリソースを事前に確保できるサブスクリプション課金方法をご利用いただくことを推奨します。
-
選択したデータセットアクセラレータインスタンス内で、トレーニングに使用するデータセットのサイズに応じてアクセラレーションスロットを作成します。1 つのインスタンスには複数のスロットを含めることができますが、すべてのスロットの合計ストレージ容量は、インスタンスの容量を超えてはなりません。
スロットを作成すると、システムはデータの型、データサイズ、トレーニングフレームワークおよびモデルなどの要因に基づいて、関連付けられたデータセットを事前処理します。初期化が完了すると、データセットアクセラレータはトレーニングタスクから直接利用可能なインターフェイスを提供します。
-
PAI プラットフォーム上でのデータセットアクセラレータの利用
PAI プラットフォーム上でデータセットを作成する際に、データセットアクセラレーションを有効化できます。その後、Data Science Workshop (DSW) インスタンスを作成する際や、DLC ジョブを送信する際に、高速化されたデータセットを利用することで、データ読み取り効率を向上させることができます。