Platform for AI (PAI) を使用すると、カスタムアルゴリズムコンポーネントを構築し、それらをビジュアルモデリングの組み込みコンポーネントと組み合わせて、柔軟なトレーニングパイプラインを作成できます。このトピックでは、PAI コンソールでカスタムコンポーネントを作成する手順について説明します。
仕組み
カスタムコンポーネントは、Alibaba Cloud のオープンソース Kubernetes ベースの AI ワークロード管理フレームワークである KubeDL で実行されます。
カスタムコンポーネントを作成する際は、ジョブタイプ (TensorFlow、PyTorch、XGBoost、または ElasticBatch) を選択し、入力パイプラインと出力パイプラインを定義し、ハイパーパラメーターを構成します。コンポーネントが作成されたら、それをビジュアルモデリングパイプラインにドラッグして、ランタイム設定を構成できます。
KubeDL は、ジョブタイプに基づいて環境変数を挿入します。これらの変数を使用して、インスタンス数とトポロジー情報にアクセスします。詳細については、「付録 1: ジョブタイプ」をご参照ください。
環境変数を通じてパイプラインデータとハイパーパラメーターにアクセスするには、「パイプラインデータとハイパーパラメーターデータの取得」をご参照ください。
コンテナのマウントパスから直接入力データと出力データにアクセスするには、「入力および出力ディレクトリ構造」をご参照ください。
前提条件
開始する前に、以下を確保してください。
ワークスペース。カスタムコンポーネントはワークスペースに関連付けられています。ワークスペースを作成するには、「ワークスペースの作成と管理」をご参照ください。
カスタムコンポーネントの作成
[カスタムコンポーネント] ページに移動します。
またはPAI コンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。[ワークスペース] ページで、お使いのワークスペースの名前をクリックします。
左側のナビゲーションウィンドウで、AI アセット管理 > カスタムコンポーネント を選択します。
[コンポーネントの作成] をクリックし、次のパラメーターを設定します。
イメージ要件
ご利用のアルゴリズムの依存関係に基づいてイメージタイプを選択します。
ご利用のアルゴリズムの依存関係が
pipでインストールできる場合は、Alibaba Cloud 公式イメージを使用し、コードディレクトリにrequirements.txtファイルを提供します。PAI は起動時にpip install -r requirements.txtを自動的に実行します。ご利用のアルゴリズムに特定のシステムレベルの依存関係が必要な場合は、カスタムイメージを使用します。
追加要件:
最高の信頼性を得るには、ジョブと同じリージョンの Alibaba Cloud Container Registry (ACR) を使用します。
Container Registry Personal Edition のみがサポートされています。Enterprise Edition はサポートされていません。イメージアドレスは
registry-vpc.${region}.aliyuncs.com形式で指定します。カスタムイメージの場合: ジョブ起動時のイメージキャッシュの遅延を防ぐため、同じコンポーネントバージョン内でイメージを更新することは避けてください。
イメージには
shシェルコマンドを含める必要があります。PAI はsh -cを使用してコマンドを実行します。カスタムイメージには、Python 環境と
pipを含める必要があります。
コード: OSS パスのマウント要件
起動の遅延を防ぐため、必要なアルゴリズムファイルのみを OSS パスに保存します。
コードディレクトリに
requirements.txtファイルが存在する場合、PAI は起動時にpip install -r requirements.txtを自動的に実行します。
パイプラインとパラメーター
 アイコンをクリックして、入力パイプライン、出力パイプライン、およびハイパーパラメーターを追加します。
アイコンをクリックして、入力パイプライン、出力パイプライン、およびハイパーパラメーターを追加します。すべてのパイプラインとパラメーターの名前要件:
名前はグローバルに一意である必要があります。
名前には数字、文字、アンダースコア (
_)、およびハイフン (-) を含めることができますが、アンダースコアで始めることはできません。
PAI が環境変数名を生成する際、すべての文字を大文字に変換し、ハイフン (
-) を含むサポートされていない文字をアンダースコア (_) に置き換えます。たとえば、test_modelとtest-modelは両方ともPAI_HPS_TEST_MODELになり、競合が発生します。これを避けるために、異なる名前を使用してください。基本情報
パラメーター 説明 コンポーネント名 カスタムコンポーネントの名前。同じ Alibaba Cloud アカウントとリージョン内で一意である必要があります。 コンポーネントの説明 カスタムコンポーネントの説明。 コンポーネントバージョン バージョン番号。 x.y.z形式を使用します。マイナーな修正の場合はパッチバージョン (例:1.0.0から1.0.1) を増分し、機能更新の場合はマイナーバージョン (例:1.0.0から1.1.0) を増分します。バージョンの説明 このバージョンの説明。例: initial version。実行構成
パラメーター 説明 ジョブタイプ コンポーネントを実行するためのフレームワーク。オプション: TensorFlow (TFJob)、PyTorch (PyTorchJob)、XGBoost (XGBoostJob)、および ElasticBatch (KubeDL の ElasticBatchJob)。各ジョブタイプは、分散トレーニング用に異なる環境変数を挿入します。詳細については、「付録 1: ジョブタイプ」をご参照ください。 イメージ 使用するコンテナイメージ。オプション: [コミュニティイメージ]、[Alibaba Cloud イメージ]、および [カスタムイメージ]。ドロップダウンリストからイメージを選択するか、[イメージアドレス] を選択してイメージ URL を入力します。詳細については、以下の「イメージ要件」をご参照ください。 コード ご利用のアルゴリズムコードのソース。オプション: **[OSS パスのマウント]** (ファイルはランタイム時に /ml/usercode/にダウンロードされます) および **[Git]** (Git コードリポジトリ)。コマンド コンテナが実行するコマンド。詳細については、以下の「コマンドの構成」をご参照ください。 次の図は、パイプラインとパラメーターの構成がビジュアルモデリングのコンポーネント設定にどのようにマッピングされるかを示しています。
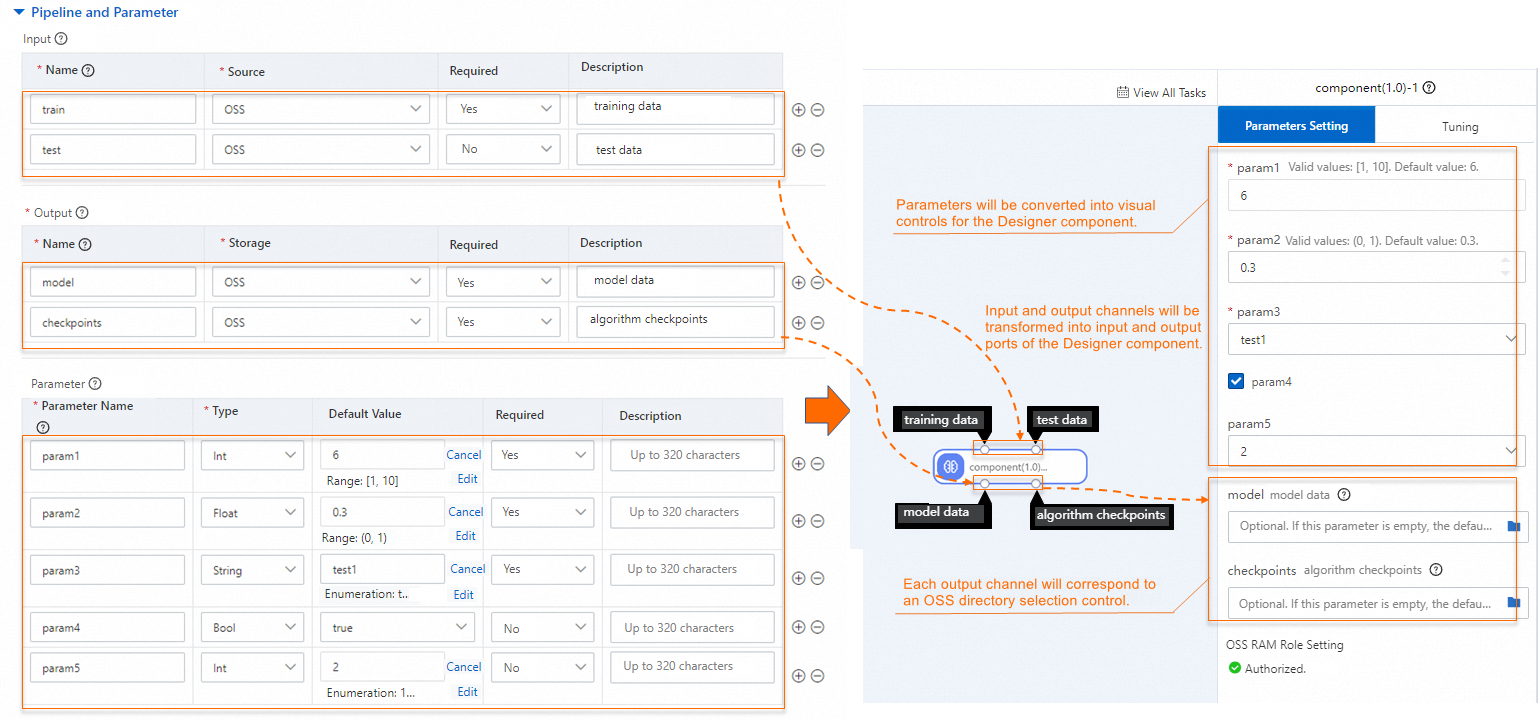
パラメーター 説明 Input コンポーネントが入力データまたはモデルを読み取る場所を定義します。以下の項目を設定します:Name(チャンネル名)およびSource(Object Storage Service (OSS) パス、File Storage NAS (NAS) パス、または MaxCompute パス)。入力データは、トレーニングコンテナ内の /ml/input/data/{channel_name}/にマウントされます。Output コンポーネントが学習済みモデルやチェックポイントなどの結果を書き込む場所を定義します。以下の項目を設定します:Name(チャンネル名)およびStorage(OSS または MaxCompute のディレクトリ)。出力データは、トレーニングコンテナ内の /ml/output/{channel_name}/にマウントされます。Parameter ジョブのハイパーパラメーターを定義します。以下の項目を設定します:Parameter name、Type( Int、Float、String、またはBool)、および必要に応じてConstraint(Int、Float、またはStringに対して)。制約の種類は、Range(最小値/最大値)またはEnumeration(許容値の列挙)です。制約
「[制約を有効化]」をオンにして、コンポーネントに必要な計算リソースを指定します。次の図は、ビジュアルモデリングにおけるトレーニング制約とコンポーネントのチューニングパラメーターの対応関係を示しています。
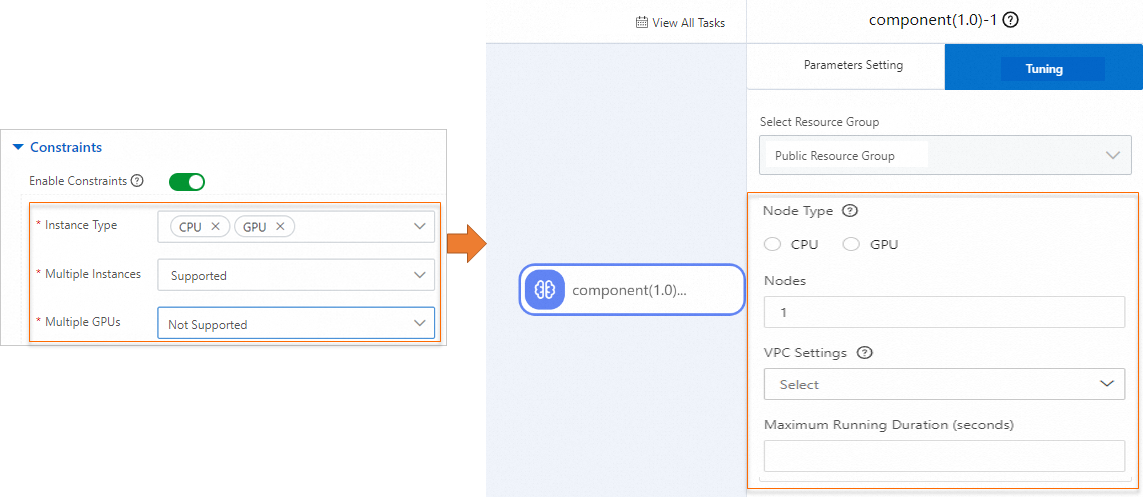
パラメーター 説明 インスタンスタイプ CPUまたはGPU。複数インスタンス コンポーネントが分散トレーニングをサポートしているかどうか。サポート:インスタンス数はランタイムで設定可能です。未サポート:インスタンス数は 1 に固定されます。 複数 GPU インスタンスタイプ が GPUの場合に利用可能です。サポート:シングル GPU およびマルチ GPU のインスタンスタイプの両方が利用可能です。未サポート:シングル GPU のインスタンスタイプのみ利用可能です。[送信]をクリックします。
このコンポーネントは、[カスタム コンポーネント] ページに表示されます。
コマンドの構成
[コマンド] フィールドは、コンポーネントの実行時に PAI が実行するシェルコマンドを指定します。スクリプトにパイプラインパスとハイパーパラメーターを渡すには、次の環境変数を使用します:
$PAI_USER_ARGS— すべてのハイパーパラメーターをコマンドライン引数としてフォーマット$PAI_INPUT_{CHANNEL_NAME}— 入力パイプラインのローカルマウントパス (チャンネル名は大文字)$PAI_OUTPUT_{CHANNEL_NAME}— 出力パイプラインのローカルマウントパス (チャンネル名は大文字)
コマンド形式:
python main.py $PAI_USER_ARGS --{CHANNEL_NAME} $PAI_INPUT_{CHANNEL_NAME} --{CHANNEL_NAME} $PAI_OUTPUT_{CHANNEL_NAME}例: train と test という名前の入力パイプライン、および model と checkpoints という名前の出力パイプラインの場合:
python main.py $PAI_USER_ARGS --train $PAI_INPUT_TRAIN --test $PAI_INPUT_TEST --model $PAI_OUTPUT_MODEL --checkpoints $PAI_OUTPUT_CHECKPOINTS && sleep 150 && echo "job finished"次の例は、main.py がこれらの引数をどのように解析できるかを示しています。
import os
import argparse
import json
def parse_args():
"""Parse the arguments."""
parser = argparse.ArgumentParser(description="PythonV2 component script example.")
# Input and output channels
parser.add_argument("--train", type=str, default=None, help="input channel train.")
parser.add_argument("--test", type=str, default=None, help="input channel test.")
parser.add_argument("--model", type=str, default=None, help="output channel model.")
parser.add_argument("--checkpoints", type=str, default=None, help="output channel checkpoints.")
# Hyperparameters
parser.add_argument("--param1", type=int, default=None, help="param1")
parser.add_argument("--param2", type=float, default=None, help="param2")
parser.add_argument("--param3", type=str, default=None, help="param3")
parser.add_argument("--param4", type=bool, default=None, help="param4")
parser.add_argument("--param5", type=int, default=None, help="param5")
args, _ = parser.parse_known_args()
return args
if __name__ == "__main__":
args = parse_args()
print("Input channel train={}".format(args.train))
print("Input channel test={}".format(args.test))
print("Output channel model={}".format(args.model))
print("Output channel checkpoints={}".format(args.checkpoints))
print("Parameters param1={}".format(args.param1))
print("Parameters param2={}".format(args.param2))
print("Parameters param3={}".format(args.param3))
print("Parameters param4={}".format(args.param4))
print("Parameters param5={}".format(args.param5))ジョブの実行時、解決されたパスとパラメーター値がログに表示されます。
Input channel train=/ml/input/data/train
Input channel test=/ml/input/data/test/easyrec_config.config
Output channel model=/ml/output/model/
Output channel checkpoints=/ml/output/checkpoints/
Parameters param1=6
Parameters param2=0.3
Parameters param3=test1
Parameters param4=True
Parameters param5=2
job finished次のステップ
カスタムコンポーネントを作成したら、ビジュアルモデリングで使用します。詳細については、「カスタムコンポーネントの使用」をご参照ください。
付録 1: ジョブタイプ
KubeDL は、選択したジョブタイプに応じて異なる環境変数を挿入します。これらの変数をご利用のトレーニングコードで使用して、分散ロジックを実装します。
TensorFlow (TFJob)
TensorFlow ジョブの場合、KubeDL はクラスタートポロジーを含む TF_CONFIG 環境変数を挿入します。
{
"cluster": {
"chief": [
"dlc17****iui3e94-chief-0.t104140334615****.svc:2222"
],
"evaluator": [
"dlc17****iui3e94-evaluator-0.t104140334615****.svc:2222"
],
"ps": [
"dlc17****iui3e94-ps-0.t104140334615****.svc:2222"
],
"worker": [
"dlc17****iui3e94-worker-0.t104140334615****.svc:2222",
"dlc17****iui3e94-worker-1.t104140334615****.svc:2222",
"dlc17****iui3e94-worker-2.t104140334615****.svc:2222",
"dlc17****iui3e94-worker-3.t104140334615****.svc:2222"
]
},
"task": {
"type": "chief",
"index": 0
}
}| フィールド | 説明 |
|---|---|
cluster | TensorFlow クラスタートポロジー。各キーはロール (chief、worker、evaluator、ps) であり、各値はそのロールのネットワークアドレスのリストです。 |
task.type | 現在のインスタンスのロール。 |
task.index | ロールのアドレスリスト内の現在のインスタンスのインデックス。 |
PyTorch (PyTorchJob)
PyTorch ジョブの場合、KubeDL は次の環境変数を挿入します。
| 変数 | 説明 |
|---|---|
RANK | インスタンスのロール。0 = マスターノード。その他の値 = ワーカーノード。 |
WORLD_SIZE | ジョブ内のインスタンスの総数。 |
MASTER_ADDR | マスターノードのネットワークアドレス。 |
MASTER_PORT | マスターノードのポート。 |
例 (2 インスタンス分散ジョブ):
RANK=0
WORLD_SIZE=2
MASTER_ADDR=train1pt84cj****-master-0
MASTER_PORT=9999XGBoost (XGBoostJob)
XGBoost ジョブの場合、KubeDL は次の環境変数を挿入します。
| 変数 | 説明 |
|---|---|
RANK | インスタンスのロール。0 = マスターノード。その他の値 = ワーカーノード。 |
WORLD_SIZE | ジョブ内のインスタンスの総数。 |
MASTER_ADDR | マスターノードのネットワークアドレス。 |
MASTER_PORT | マスターノードのポート。 |
WORKER_ADDRS | すべてのワーカーノードのアドレス。RANK でソートされます。シングルインスタンスジョブでは利用できません。 |
WORKER_PORT | ワーカーノードのポート。シングルインスタンスジョブでは利用できません。 |
例: 分散ジョブ (6 インスタンス)
WORLD_SIZE=6
RANK=0
MASTER_ADDR=train1pt84cj****-master-0
MASTER_PORT=9999
WORKER_ADDRS=train1pt84cj****-worker-0,train1pt84cj****-worker-1,train1pt84cj****-worker-2,train1pt84cj****-worker-3,train1pt84cj****-worker-4
WORKER_PORT=9999例: シングルインスタンスジョブ
WORLD_SIZE=1
RANK=0
MASTER_ADDR=train1pt84cj****-master-0
MASTER_PORT=9999シングルインスタンス XGBoost ジョブの場合、WORKER_ADDRSとWORKER_PORTは挿入されません。
ElasticBatch (ElasticBatchJob)
ElasticBatch は、次の機能を備えた分散オフライン推論ジョブタイプです。
高い並列性でスループットを倍増。
ジョブの待機時間を短縮。ワーカーノードはリソースが割り当てられた直後に実行できます。
起動の遅いインスタンスをバックアップワーカーで自動的に置き換え、ロングテール遅延やジョブのハングを防ぎます。
グローバルな動的データシャードディストリビューション — より高速なワーカーは、より低速なワーカーよりも多くのデータを処理します。
ジョブの早期終了 — すべてのデータが処理されると、未開始のワーカーノードは起動されません。
シングルワーカーのフォールトトレランス — 1 つのワーカーが失敗した場合、システムは自動的に再起動します。
ElasticBatch ジョブは、次の 2 つのノードタイプで構成されます。
AIMaster: コントロールノード。グローバルジョブ調整、動的データシャードディストリビューション、スループットモニタリング、およびフォールトトレランスを管理します。
Worker: 計算ノード。AIMaster からデータシャードをフェッチし、処理して、結果を書き戻します。
ご利用のコードはワーカーノードで実行されます。KubeDL は、各ワーカーに ELASTICBATCH_CONFIG 環境変数を挿入します。
{
"task": {
"type": "worker",
"index": 0
},
"environment": "cloud"
}| フィールド | 説明 |
|---|---|
task.type | 現在のインスタンスのロール (worker)。 |
task.index | ロール内の現在のインスタンスのインデックス。 |
付録 2: コンポーネントへのデータの渡し方
パイプラインデータとハイパーパラメーターデータの取得
入力パイプラインデータ
PAI は、PAI_INPUT_{CHANNEL_NAME} 環境変数 (チャンネル名は大文字) を使用して、各入力パイプラインのローカルパスを挿入します。
例: train と test という名前の 2 つの入力パイプラインを持つコンポーネントの場合:
PAI_INPUT_TRAIN=/ml/input/data/train/
PAI_INPUT_TEST=/ml/input/data/test/test.csv出力パイプラインデータ
PAI は、PAI_OUTPUT_{CHANNEL_NAME} (チャンネル名は大文字) を使用して、各出力パイプラインのローカルパスを挿入します。
例: model と checkpoints という名前の出力パイプラインの場合:
PAI_OUTPUT_MODEL=/ml/output/model/
PAI_OUTPUT_CHECKPOINTS=/ml/output/checkpoints/ハイパーパラメーターデータ
PAI は、3 つの環境変数を通じてハイパーパラメーターを提供します。
PAI_USER_ARGS — すべてのハイパーパラメーターを --name value 形式の単一のコマンドライン文字列として。
{"epochs": 10, "batch-size": 32, "learning-rate": 0.001} のハイパーパラメーターの場合:
PAI_USER_ARGS="--epochs 10 --batch-size 32 --learning-rate 0.001"PAI_HPS_{HYPERPARAMETER_NAME} — 各ハイパーパラメーターを個別の変数として。名前に含まれるサポートされていない文字 (ハイフンを含む) はアンダースコアに置き換えられ、大文字に変換されます。
{"epochs": 10, "batch-size": 32, "train.learning_rate": 0.001} のハイパーパラメーターの場合:
PAI_HPS_EPOCHS=10
PAI_HPS_BATCH_SIZE=32
PAI_HPS_TRAIN_LEARNING_RATE=0.001PAI_HPS — すべてのハイパーパラメーターを JSON 文字列として。
{"epochs": 10, "batch-size": 32} のハイパーパラメーターの場合:
PAI_HPS={"epochs": 10, "batch-size": 32}入力および出力ディレクトリ構造
ジョブがコンテナで実行されると、PAI は次のディレクトリ構造を作成します。
| パス | 説明 |
|---|---|
/ml/usercode/ | ご利用のアルゴリズムコード (作業ディレクトリでもあります。PAI_WORKING_DIR 経由でアクセス可能)。 |
/ml/input/config/ | ジョブ構成ファイル (PAI_CONFIG_DIR 経由でアクセス可能)。 |
/ml/input/config/hyperparameters.json | ハイパーパラメーター構成。 |
/ml/input/config/training_job.json | トレーニングジョブ構成。 |
/ml/input/data/{channel_name}/ | 入力パイプラインデータ。入力パイプラインごとに 1 つのディレクトリ。 |
/ml/output/{channel_name}/ | 出力パイプラインデータ。出力パイプラインごとに 1 つのディレクトリ。PAI_OUTPUT_{OUTPUT_CHANNEL_NAME} 経由でアクセス可能。 |
ディレクトリレイアウトの例:
/ml
|-- usercode # Algorithm code and working directory
| |-- requirements.txt
| |-- main.py
|-- input
| |-- config # Job configuration files
| | |-- training_job.json
| | |-- hyperparameters.json
| |-- data # Input pipelines
| |-- test_data
| | |-- test.csv
| |-- train_data
| |-- train.csv
|-- output # Output pipelines
|-- model
|-- checkpointsGPU の可用性の検出
ジョブの開始後、NVIDIA_VISIBLE_DEVICES 環境変数を使用して GPU の可用性を確認します。たとえば、NVIDIA_VISIBLE_DEVICES=0,1,2,3 は、インスタンスに 4 つの GPU があることを示します。