このトピックでは、AI ポートレートソリューションで推論用のスケーラブルジョブサービスを使用する方法について説明します。このアプローチにより、スケールイン操作中のリソースの利用率低下やリクエストの中断を防ぐことができます。
前提条件
VPC (Virtual Private Cloud) が作成され、VPC のインターネットアクセスが有効になっていること。
VPC、vSwitch、およびセキュリティグループが作成されていること。詳細については、「IPv4 CIDR ブロックを持つ VPC の作成」および「セキュリティグループの作成」をご参照ください。
VPC にインターネット NAT ゲートウェイが作成されていること。Elastic IP アドレス (EIP) がゲートウェイに関連付けられ、SNAT エントリがゲートウェイに構成されていること。詳細については、「インターネット NAT ゲートウェイの SNAT 機能を使用してインターネットにアクセスする」をご参照ください。
OSS バケットを作成すること。詳細については、「バケットの作成」をご参照ください。
制限事項
AI ポートレートソリューションは、中国 (北京) リージョンとシンガポールリージョンでのみサポートされています。
推論用のスケーラブルジョブサービスのデプロイ
検証サービスのデプロイ
PAI コンソールにログインします。 ページの上部でリージョンを選択します。 次に、目的のワークスペースを選択し、[Elastic Algorithm Service (EAS)] をクリックします。
-
[サービスのデプロイ] をクリックします。[カスタムモデルのデプロイメント] セクションで、[カスタムデプロイメント] をクリックします。
Custom Deployment ページで、次の主要なパラメーターを設定し、その他についてはデフォルト値を使用します。 パラメーターの詳細については、「カスタムデプロイメント」をご参照ください。
「Basic Information」セクションで、サービス名を設定します。たとえば、
photog_checkに設定します。「Environment Information」セクションで、以下のパラメーターを設定します:
パラメーター
説明
Deployment Method
Image-based Deployment と Asynchronous Queue を選択します。
Image Configuration
Image Address を選択し、イメージアドレスを入力します。有効な値:
中国 (北京):
registry.cn-beijing.aliyuncs.com/mybigpai/photog_pub:check.1.0.0.pub。シンガポール:
registry.ap-southeast-1.aliyuncs.com/mybigpai/photog_pub:check.1.0.0.pub。
Code Build
マウントタイプとして OSS を選択し、次のパラメーターを設定します。
Uri: ご利用の OSS バケットパスを指定します。例:
oss://examplebucket/。Mount Path:
/photog_ossに設定します。
Command to Run
python app.pyに設定します。Port Number
7860 に設定します。
「Resource Information」セクションで、以下のパラメーターを設定します。
パラメーター
説明
Resource Type
Public Resources を選択します。
Deployment
[GPU] タブから GU30 シリーズのインスタンスタイプを選択します。
ml.gu7i.c32m188.1-gu30の使用を推奨します。Configure a system disk
サイズを 120 GiB に設定します。
Asynchronous Queue セクションでは、次のパラメーターを設定します。
パラメーター
説明
Resource Type
Public Resourcesを選択します。
Deployment
レプリカ数: 1
CPU (コア): 8
メモリ (GB): 64
Maximum Data for A Single Input Request
キュー内の各リクエストに十分なストレージスペースを確保するために、これを 20480 KB に設定します。
Maximum Data for A Single Output
「Service Access」セクションで、作成した [VPC]、[vSwitch]、および [セキュリティグループ] を選択します。
Service Configurations セクションに、以下の構成を追加します。新しいパラメーターを追加する際は、以下の完全な構成例を参照できます。
フィールド
新しいパラメーター
metadata
次のパラメーターを追加します。
{ "metadata": { "name": "photog_check", "instance": 1, "rpc": { "keepalive": 3600000, "worker_threads": 1 }, "type": "Async" }, "cloud": { "computing": { "instance_type": "ml.gu7i.c32m188.1-gu30", "instances": null }, "networking": { "vswitch_id": "vsw-2ze4o9kww55051tf2****", "security_group_id": "sg-2ze0kgiee55d0fn4****", "vpc_id": "vpc-2ze5hl4ozjl4fo7q3****" } }, "features": { "eas.aliyun.com/extra-ephemeral-storage": "100Gi" }, "queue": { "cpu": 8, "max_delivery": 1, "min_replica": 1, "memory": 64000, "resource": "", "source": { "max_payload_size_kb": 20480 }, "sink": { "max_payload_size_kb": 20480 } }, "storage": [ { "oss": { "path": "oss://examplebucket/", "readOnly": false }, "properties": { "resource_type": "code" }, "mount_path": "/photog_oss" } ], "containers": [ { "image": "registry.cn-beijing.aliyuncs.com/mybigpai/photog_pub:check.1.0.0.pub", "script": "python app.py", "port": 7860 } ] }keepalive: 単一リクエストの最大処理時間 (ミリ秒単位)。これを 3600000 に設定します。
worker_threads: EAS インスタンスあたりの並行処理スレッド数。
デフォルトでは 5 です。これは、キューに入った最初の 5 つのタスクが同じインスタンスに割り当てられることを意味します。リクエストを順次処理するには、これを 1 に設定します。
queue
障害後の繰り返し配信を防ぐために、パラメーター
"max_delivery": 1を追加します。
Deploy をクリックします。
トレーニングサービスのデプロイ
PAI コンソールにログインします。 ページの上部でリージョンを選択します。 次に、目的のワークスペースを選択し、[Elastic Algorithm Service (EAS)] をクリックします。
-
「サービスのデプロイ」をクリックします。「カスタムモデルデプロイメント」セクションで、「カスタムデプロイメント」をクリックします。
Custom Deployment ページで、次のキーパラメーターを設定し、残りのパラメーターにはデフォルト値を使用します。パラメーターの詳細については、「カスタムデプロイメント」をご参照ください。
Basic Information セクションで、サービス名を設定します。たとえば、
photog_train_pmmlに設定します。Environment Information セクションで、以下のパラメーターを設定します:
パラメーター
説明
Deployment Method
Image-based Deployment を選択し、Asynchronous Queue を選択します。
Image Configuration
Image Address を選択し、イメージアドレスを入力します。有効な値:
中国 (北京):
registry.cn-beijing.aliyuncs.com/mybigpai/photog_pub:train.1.0.0.pub。シンガポール:
registry.ap-southeast-1.aliyuncs.com/mybigpai/photog_pub:train.1.0.0.pub。
コード構成
マウントタイプとして OSS を選択し、次のパラメーターを設定します。
Uri: ご利用の OSS バケットへのパスを指定します。これは検証サービスに指定されたパスと同じである必要があります。例:
oss://examplebucket/。Mount Path:
/photog_ossに設定します。
Command to Run
python app.pyに設定します。Port Number
7860 に設定します。
Resource Information セクションで、次のパラメーターを設定します。
パラメーター
説明
Resource Type
Public Resources を選択します。
Deployment
GPU タブから GU30 シリーズのインスタンスタイプを選択します。
ml.gu7i.c32m188.1-gu30の使用を推奨します。Configure a system disk
サイズを 120 GiB に設定します。
「Asynchronous Queue」セクションで、次のパラメーターを設定します。
パラメーター
説明
Resource Type
Public Resources を選択します。
Deployment
レプリカ数: 1
CPU (コア): 8
メモリ (GB): 64
Maximum Data for A Single Input Request
キュー内の各リクエストに十分なストレージスペースを確保するために、これを 20480 KB に設定します。
Maximum Data for A Single Output
[Service Access] セクションで、作成した VPC、vSwitch、および セキュリティグループ を選択します。
Service Configurations セクションに、以下の構成を追加します。以下の完全な構成例を参照して、新しいパラメーターを追加できます。
フィールド
新しいパラメーター
autoscaler
(オプション) 水平オートスケーリングの構成。詳細については、「水平オートスケーリング」をご参照ください。
{ "autoscaler": { "behavior": { "scaleDown": { "stabilizationWindowSeconds": 60 } }, "max": 5, "min": 1, "strategies": { "queue[backlog]": 1 } }, "metadata": { "name": "photog_train_pmml", "instance": 1, "rpc": { "keepalive": 3600000, "worker_threads": 1 }, "type": "Async" }, "cloud": { "computing": { "instance_type": "ml.gu7i.c32m188.1-gu30", "instances": null }, "networking": { "vswitch_id": "vsw-2ze4o9kww55051tf2****", "security_group_id": "sg-2ze0kgiee55d0fn4****", "vpc_id": "vpc-2ze5hl4ozjl4fo7q3****" } }, "features": { "eas.aliyun.com/extra-ephemeral-storage": "120Gi" }, "queue": { "cpu": 8, "max_delivery": 1, "min_replica": 1, "memory": 64000, "resource": "", "source": { "max_payload_size_kb": 20480 }, "sink": { "max_payload_size_kb": 20480 } }, "storage": [ { "oss": { "path": "oss://examplebucket/", "readOnly": false }, "properties": { "resource_type": "code" }, "mount_path": "/photog_oss" } ], "containers": [ { "image": "registry.cn-beijing.aliyuncs.com/mybigpai/photog_pub:train.1.0.0.pub", "script": "python app.py", "port": 7860 } ] }metadata
次のパラメーターを追加します。
{ "metadata": { "name": "photog_check", "instance": 1, "rpc": { "keepalive": 3600000, "worker_threads": 1 }, "type": "Async" }, "cloud": { "computing": { "instance_type": "ml.gu7i.c32m188.1-gu30", "instances": null }, "networking": { "vswitch_id": "vsw-2ze4o9kww55051tf2****", "security_group_id": "sg-2ze0kgiee55d0fn4****", "vpc_id": "vpc-2ze5hl4ozjl4fo7q3****" } }, "features": { "eas.aliyun.com/extra-ephemeral-storage": "100Gi" }, "queue": { "cpu": 8, "max_delivery": 1, "min_replica": 1, "memory": 64000, "resource": "", "source": { "max_payload_size_kb": 20480 }, "sink": { "max_payload_size_kb": 20480 } }, "storage": [ { "oss": { "path": "oss://examplebucket/", "readOnly": false }, "properties": { "resource_type": "code" }, "mount_path": "/photog_oss" } ], "containers": [ { "image": "registry.cn-beijing.aliyuncs.com/mybigpai/photog_pub:check.1.0.0.pub", "script": "python app.py", "port": 7860 } ] }keepalive: 単一リクエストの最大処理時間 (ミリ秒単位)。これを 3600000 に設定します。
worker_threads: EAS インスタンスあたりの並行処理スレッド数。
デフォルトでは 5 です。これは、キューに入った最初の 5 つのタスクが同じインスタンスに割り当てられることを意味します。リクエストを順次処理するには、これを 1 に設定します。
queue
障害後の複数回の再配信を防ぐために、パラメーター
"max_delivery": 1を追加します。
Deploy をクリックします。
予測サービスのデプロイ
このソリューションでは、予測サービスがスケーラブルジョブサービスとしてデプロイされます。次の手順に従います。
Deploy Service をクリックします。Custom Model Deployment セクションで、JSON Deployment をクリックします。
JSON エディターに構成情報を入力します。
{ "metadata": { "name": "photog_pre_pmml", "instance": 1, "rpc": { "keepalive": 3600000, "worker_threads": 1 }, "type": "ScalableJob" }, "cloud": { "computing": { "instance_type": "ecs.gn6v-c8g1.2xlarge", "instances": null }, "networking": { "vswitch_id": "vsw-2ze4o9kww55051tf2****", "security_group_id": "sg-2ze0kgiee55d0fn4****", "vpc_id": "vpc-2ze5hl4ozjl4fo7q3****" } }, "features": { "eas.aliyun.com/extra-ephemeral-storage": "120Gi" }, "queue": { "cpu": 8, "max_delivery": 1, "min_replica": 1, "memory": 64000, "resource": "", "source": { "max_payload_size_kb": 20480 }, "sink": { "max_payload_size_kb": 20480 } }, "storage": [ { "oss": { "path": "oss://examplebucket/", "readOnly": false }, "properties": { "resource_type": "code" }, "mount_path": "/photog_oss" } ], "containers": [ { "image": "registry.cn-beijing.aliyuncs.com/mybigpai/photog_pub:infer.1.0.0.pub", "env": [ { "name": "URL", "value": "http://127.0.0.1:8000" }, { "name": "AUTHORIZATION", "value": "=" } ], "script": "python app.py", "port": 7861 }, { "image": "eas-registry-vpc.cn-beijing.cr.aliyuncs.com/pai-eas/stable-diffusion-webui:3.2", "port": 8000, "script": "./webui.sh --listen --port 8000 --skip-version-check --no-hashing --no-download-sd-model --skip-install --api --filebrowser --sd-dynamic-cache --data-dir /photog_oss/webui/" } ] }次の表に主要パラメーターを示します。その他のパラメーターの詳細については、「JSON デプロイメント」をご参照ください。
パラメーター
説明
metadata
Name
サービス名。リージョン内で一意である必要があります。
Type
これを ScalableJob に設定します。これにより、非同期推論サービスがスケーラブルジョブサービスとしてデプロイされます。
containers
Image
AI 縦画像予測サービスおよび WebUI 予測サービスのイメージアドレスを、それぞれのコンテナ定義設定します。以下のリストに、サポートされているイメージを示します。このソリューションでは、中国(北京)リージョンのイメージアドレスを使用します。
中国 (北京) のイメージアドレス:
AI ポートレート予測サービス:
registry.cn-beijing.aliyuncs.com/mybigpai/photog_pub:infer.1.0.0.pub。WebUI 予測サービス:
eas-registry-vpc.cn-beijing.cr.aliyuncs.com/pai-eas/stable-diffusion-webui:3.2。
シンガポールのイメージアドレス:
AI ポートレート予測サービス:
registry.ap-southeast-1.aliyuncs.com/mybigpai/photog_pub:infer.1.0.0.pub。WebUI 予測サービス:
eas-registry-vpc.ap-southeast-1.cr.aliyuncs.com/pai-eas/stable-diffusion-webui:3.2。
storage
Path
この例では OSS マウントを使用します。ご利用の OSS バケットパスを設定します。検証サービス用に構成した OSS バケットパスと同じパスを使用します。例:
oss://examplebucket/。WebUI で必要なモデルファイルをダウンロードして抽出し、以下の図に示すディレクトリ構造に従って、ご利用の OSS バケットのパス
oss://examplebucket/photog_oss/webuiに保存する必要があります。OSS バケットパスにファイルをアップロードする方法の詳細については、「コマンドラインツール ossutil 1.0」をご参照ください。NAS パスにファイルをアップロードする方法の詳細については、「クイックスタート (Linux)」および「ワークベンチを使用して ECS インスタンス上のファイルを管理する」をご参照ください。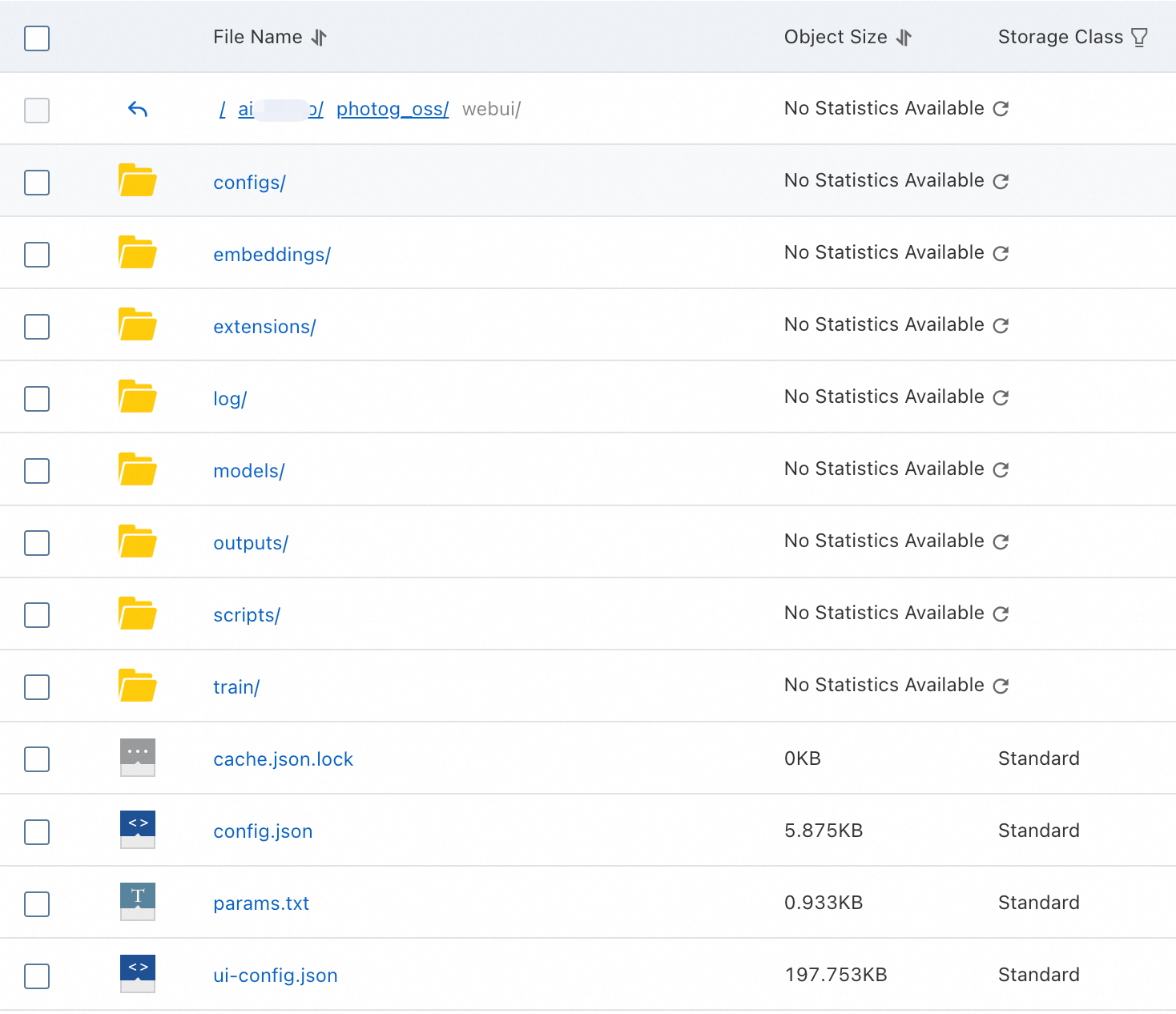
Mount path
/photog_ossに設定します。Deploy をクリックします。
スケーラブルジョブサービスをデプロイすると、キューサービスが自動的に作成され、水平オートスケーリングがデフォルトで有効になります。
サービスの呼び出し
サービスがデプロイされたら、それを呼び出して AI ポートレートを生成します。
サービスを呼び出す際は、サービスの呼び出しで説明されているように、推論リクエストを行うために taskType パラメーターを query に設定します。次のサンプルコードを使用します。
import json
from eas_prediction import QueueClient
# 入力データを書き込むための入力キュークライアントを作成します。
input_queue = QueueClient('182848887922****.cn-shanghai.pai-eas.aliyuncs.com', 'photog_check')
input_queue.set_token('<token>')
input_queue.init()
datas = json.dumps(
{
'request_id' : 12345,
'images' : ["xx.jpg", "xx.jpg"], # urls, a list
'configure' : {
'face_reconize' : True, # すべての画像が同じ人物のものであるかを確認します。
}
}
)
# taskType を query として指定します。
tags = {"taskType": "query"}
index, request_id = input_queue.put(f'{datas}', tags)
print(index, request_id)
# 入力キューの詳細を表示します。
attrs = input_queue.attributes()
print(attrs)関連ドキュメント
トレーニング用のスケーラブルジョブサービスを使用する方法の詳細については、「スケーラブルな Kohya トレーニングサービスのデプロイ」をご参照ください。
スケーラブルジョブサービスの詳細については、「スケーラブルジョブサービスの概要」をご参照ください。