モデルギャラリーでは、オープンソースの事前学習済み画像分類モデルを直接デプロイできます。カスタムシナリオでは、独自のデータセットを使用して事前学習済みモデルをファインチューニングし、そのファインチューニング済みモデルを使用して画像をカスタムカテゴリに分類することもできます。このトピックでは、モデルギャラリーを使用して画像を分類する方法について説明します。
前提条件
OSS バケットを作成します。詳細については、「バケットの作成」をご参照ください。
ステップ 1:モデル詳細への移動
モデルギャラリーページに移動します。
PAI コンソールにログインします。
左上隅でリージョンを選択します。
左側のナビゲーションウィンドウで、Workspaces をクリックします。開きたいワークスペースの名前をクリックします。
左側のナビゲーションウィンドウで、Quick Start > [モデルギャラリー] を選択します。
モデルギャラリーページで、Computer Vision セクションの Image Classification をクリックします。次に、ViT Image Classification-General モデルカードをクリックして、モデル詳細ページを開きます。
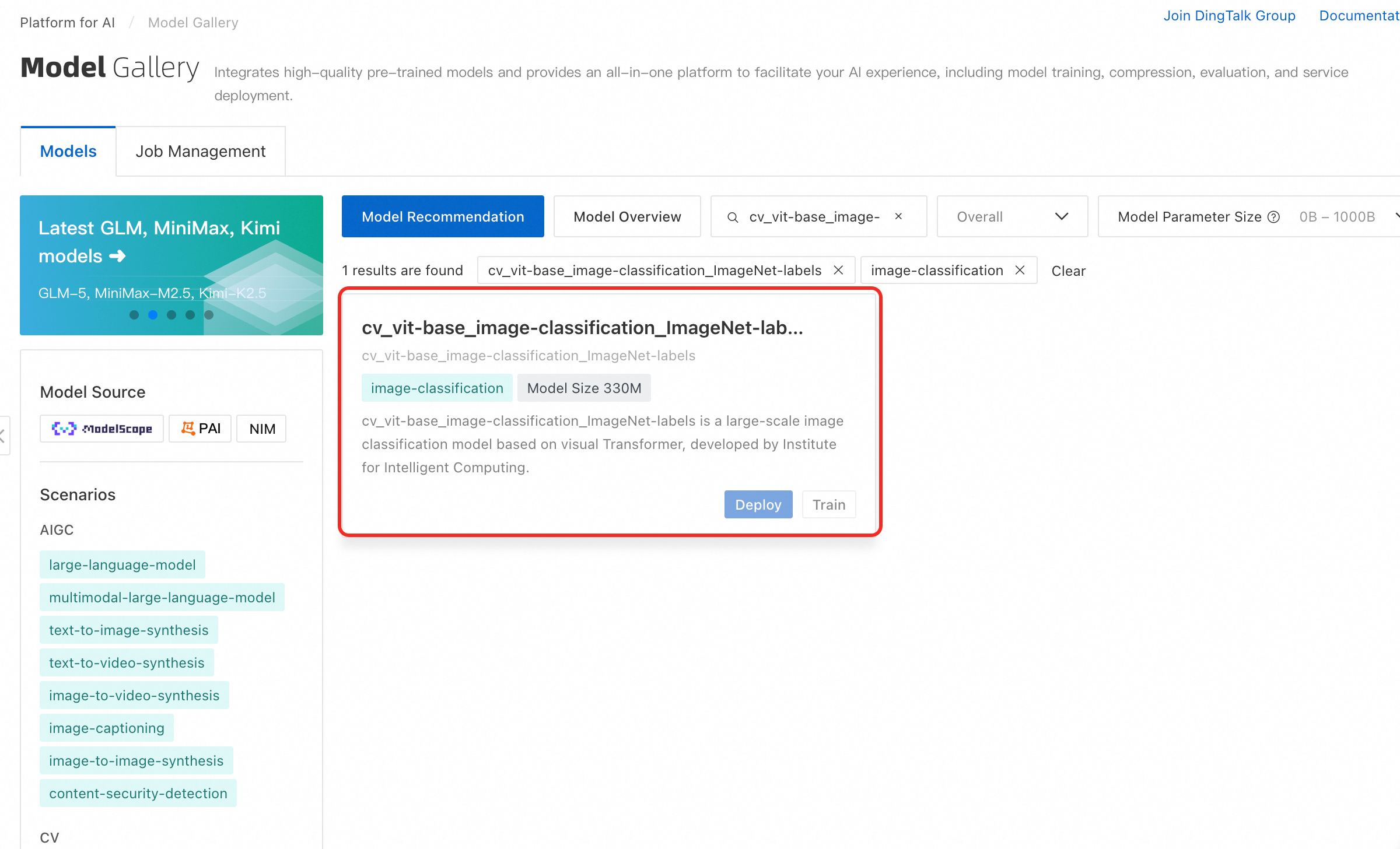
モデルリストページでは、さまざまなオープンソースコミュニティの主流モデルを多数見つけることができます。ビジネス要件に合ったモデルを選択してください。
一般的に、パラメーターが多いモデルほどパフォーマンスは高くなります。しかし、ファインチューニングにはより多くのデータが必要となり、オンラインサービングのコストも高くなります。
事前学習済みデータセットが実際のユースケースに近いほど、モデルは直接デプロイとファインチューニングの両方で優れたパフォーマンスを発揮します。モデルの事前学習済みデータセットに関する詳細情報は、各モデルの詳細ページで確認できます。
ステップ 2:モデルの直接デプロイ
モデルギャラリーの cv_vit-base_image-classification_ImageNet-labels モデルは、ModelScope コミュニティの ViT Image Classification-General モデルです。これは Transformer ViT Base アーキテクチャに基づく画像分類モデルであり、ImageNet-1K データセットでトレーニングされています。ImageNet-1K ラベルでカバーされる画像分類タスクに直接使用できます。モデルギャラリーを使用すると、このモデルを Elastic Algorithm Service (EAS) にデプロイし、画像分類の推論タスク用のモデルサービスを作成できます。次の手順に従ってください:
サービスをデプロイします。
モデル詳細ページで、Deploy をクリックします。
Model service info と Deployment info を確認します。
モデルギャラリーは、各モデルの特性に基づいて、コンピューティングリソースとサービス名を事前に構成します。この例では、デフォルトの構成を使用します。ビジネスニーズに応じてデプロイ設定を変更することもできます。パラメーターの設定方法の詳細については、「モデルのデプロイとデバッグ」をご参照ください。
Deployをクリックします。Billing Notification ダイアログボックスで、OK をクリックします。
ページが自動的に Service details ページにリダイレクトされます。 Basic Information セクションで、モデルサービスのデプロイステータスを確認します。 Status が Running に変わると、デプロイメントは完了です。
モデルサービスを呼び出します。
モデルサービスがデプロイされると、その HTTP API に予測リクエストを送信できます。モデルサービスは Base64 エンコードされた画像を受け入れ、予測結果を JSON フォーマットで返します。次の手順に従ってください:
Service details ページで、Resource Information セクションで、View Call Information をクリックします。

Call Information ダイアログボックスの Public network address call タブで、Endpoint と [トークン] を確認し、保存します。
Python の Requests ライブラリを使用してモデルサービスを呼び出します。以下のコードはその一例です。
import requests import base64 image_path = "<PathToLocalImage>" url = "<PredictionServiceURL>" token = "<PredictionServiceAccessToken>" def encode_file_to_base64(f): with open(f, "rb") as file: encoded_string = base64.b64encode(file.read()) base64_str = str(encoded_string, "utf-8") return base64_str base64_string = encode_file_to_base64(image_path) request_body = { "image": base64_string } headers = {"Authorization": token} resp = requests.post(url=url, headers=headers, json=request_body) print(resp.content.decode()) print("status code:", resp.status_code)urlを前のステップで取得した [エンドポイント] に、tokenを [トークン] に置き換えます。image_path をローカルの画像ファイル (.png または .jpg) のパスに置き換えます。呼び出しが成功すると、画像に対して最も可能性の高い上位 5 つのラベルと、それに対応するスコアが返されます。次の例に出力を示します:
{ "scores": [ 0.4078965485095978, 0.24673610925674438, 0.1930493414402008, 0.0026617543771862984, 0.0009246605914086103 ], "labels": [ "tiger cat", "tabby, tabby cat", "Egyptian cat", "lynx, catamount", "tiger, Panthera tigris" ] }
ステップ 3:モデルのファインチューニング
cv_vit-base_image-classification_ImageNet-labels モデルは、ImageNet-1K ラベルでカバーされる画像分類タスクに適しています。ターゲットの画像ドメインが ImageNet-1K ラベルでカバーされていない場合は、特定のドメイン用にラベル付けされた画像の小さなセットでモデルをファインチューニングできます。次の手順に従ってモデルをファインチューニングし、結果のモデルをデプロイします。
データを準備します。
次のディレクトリ構造に従ってデータセットを準備します:
モデルは、OSS バケットの画像データを使用してトレーニングされます。データセットをルートディレクトリに整理し、カテゴリごとに 1 つのサブディレクトリを作成する必要があります。各サブディレクトリの名前がカテゴリラベルとして機能し、そのカテゴリの画像ファイルを直接その中に入れる必要があります。たとえば、入力トレーニングデータセットが
oss://{YourOssBucket}.{OssEndpoint}/{PathToTrainData}/にある場合、そのディレクトリ内のデータ構造は次のようになります:├── category-1 │ ├── image1.jpeg │ └── image2.jpeg ├── category-2 │ ├── image3.jpeg │ └── image4.jpeg |... |... └── category-n ├── imagexxx.jpeg └── imageyyy.jpegモデルのパフォーマンスを向上させるために、同じディレクトリ構造を持つ検証データセットを準備することを推奨します。このデータセットは、モデルのパフォーマンスを評価し、ハイパーパラメーターを調整するために使用されます。
上記で説明したディレクトリ構造を使用して、データセットを OSS バケットにアップロードします。OSS バケットへのデータのアップロード方法の詳細については、「ファイルのアップロード」をご参照ください。
トレーニングジョブを送信します。
データセットを準備した後、Model Details ページで Fine-tune をクリックします。構成ページで、Training dataset、Validate dataset、および Output Path のパスを指定します。
モデルギャラリーは、モデルの特性に基づいて コンピューティングリソース や ハイパーパラメーター などのパラメーターを事前に構成します。デフォルト設定を使用するか、ビジネスニーズに合わせて変更することができます。詳細については、「モデルのデプロイとトレーニング」をご参照ください。
説明デフォルトでは、cv_vit-base_image-classification_ImageNet-labels モデルは、ファインチューニングに MiniImageNet-100 データセット を使用するように構成されており、トレーニングプロセスを迅速に試すことができます。
Fine-tune をクリックします。

ページは自動的に Task details ページにリダイレクトされます。トレーニングジョブの進捗状況、ログ、およびモデル評価結果を表示できます。トレーニングジョブが完了すると、生成されたモデルは、前のステップで設定した Output Path に保存されます。

ファインチューニング済みモデルをデプロイします。
PAI は、トレーニング済みのモデルを AI アセット - モデル管理に自動的に登録し、そこで表示またはデプロイできます。詳細については、「モデルの登録と管理」をご参照ください。