マルチモーダル大規模言語モデル (MLLM) は、複数のデータモダリティを同時に処理し、テキスト、画像、音声などのさまざまな種類の情報を統合して、複雑なコンテキストとタスクを包括的に理解できます。クロスモーダルな理解と生成を必要とするシナリオに適しています。EAS を通じて、5 分でワンクリックで MLLM 推論サービスアプリケーションをデプロイし、LLM の推論機能を取得できます。このトピックでは、EAS を使用してワンクリックで MLLM 推論サービスをデプロイおよび呼び出す方法について説明します。
背景情報
近年、さまざまな LLM が言語タスクで前例のない結果を達成しています。LLM は自然言語テキストの生成に使用され、感情分析、機械翻訳、テキスト要約など、複数のタイプのタスクで強力な機能を発揮します。ただし、これらのモデルはテキストデータに限定されており、画像、音声、ビデオなどの他の形式のデータを処理することはできません。マルチモーダルな理解を持つモデルのみが、人間の脳の認知能力に近づくことができます。
そのため、マルチモーダル MLLM は研究ブームを巻き起こしました。業界で GPT-4o などの LLM が広く適用されるにつれて、MLLM は現在の人気のあるアプリケーションの 1 つになりました。この新しいタイプの LLM は、複数のデータモダリティを同時に処理し、テキスト、画像、音声などのさまざまな種類の情報を統合して、複雑なコンテキストとタスクを包括的に理解できます。
MLLM のデプロイメントを自動化する必要がある場合、EAS はワンクリックソリューションを提供します。EAS を通じて、5 分でワンクリックで人気の MLLM 推論サービスアプリケーションをデプロイし、LLM 推論機能を取得できます。
前提条件
Platform for AI (PAI) が有効化され、デフォルトのワークスペースが作成されていること。詳細については、「PAI のアクティブ化とデフォルトワークスペースの作成」をご参照ください。
RAM ユーザーを使用してモデルをデプロイする場合、RAM ユーザーに EAS の管理権限を付与する必要があります。詳細については、「クラウド製品の依存関係と権限付与: EAS」をご参照ください。
EAS でのモデルサービスのデプロイ
PAI コンソールにログインします。ページ上部でリージョンを選択します。次に、目的のワークスペースを選択し、[Elastic Algorithm Service (EAS)] をクリックします。
[サービスのデプロイ] をクリックします。[カスタムモデルのデプロイ] セクションで、[カスタムデプロイ] をクリックします。
[カスタムデプロイ] ページで、次の主要なパラメーターを設定します。その他のパラメーターについては、「コンソールでのカスタムデプロイのパラメーター」をご参照ください。
パラメーター
説明
環境コンテキスト
デプロイ方法
[イメージベースのデプロイ] と [Web アプリを有効にする] を選択します。
イメージ設定
[Alibaba Cloud イメージ] > [chat-mllm-webui] > [chat-mllm-webui:1.0] を選択します。
説明モデルサービスをデプロイする際は、最新バージョンのイメージを選択することをお勧めします。
コマンド
イメージを選択すると、システムが自動的にこのパラメーターを設定します。model_type パラメーターを変更して、さまざまなモデルをデプロイできます。次の表に、サポートされている モデルタイプ を示します。
リソース情報
リソースのデプロイ
GPU タイプを選択します。最もコスト効率の高い ml.gu7i.c16m60.1-gu30 インスタンスタイプを選択することをお勧めします。
パラメーターを設定したら、[デプロイ] をクリックします。
サービスの呼び出し
Web UI を使用したモデル推論の実行
[Elastic Algorithm Service (EAS)] ページで、対象のサービスの名前をクリックし、ページの右上隅にある [Web アプリの表示] をクリックし、コンソールの指示に従って WebUI ページを開きます。
Web UI ページで、モデル推論を実行します。
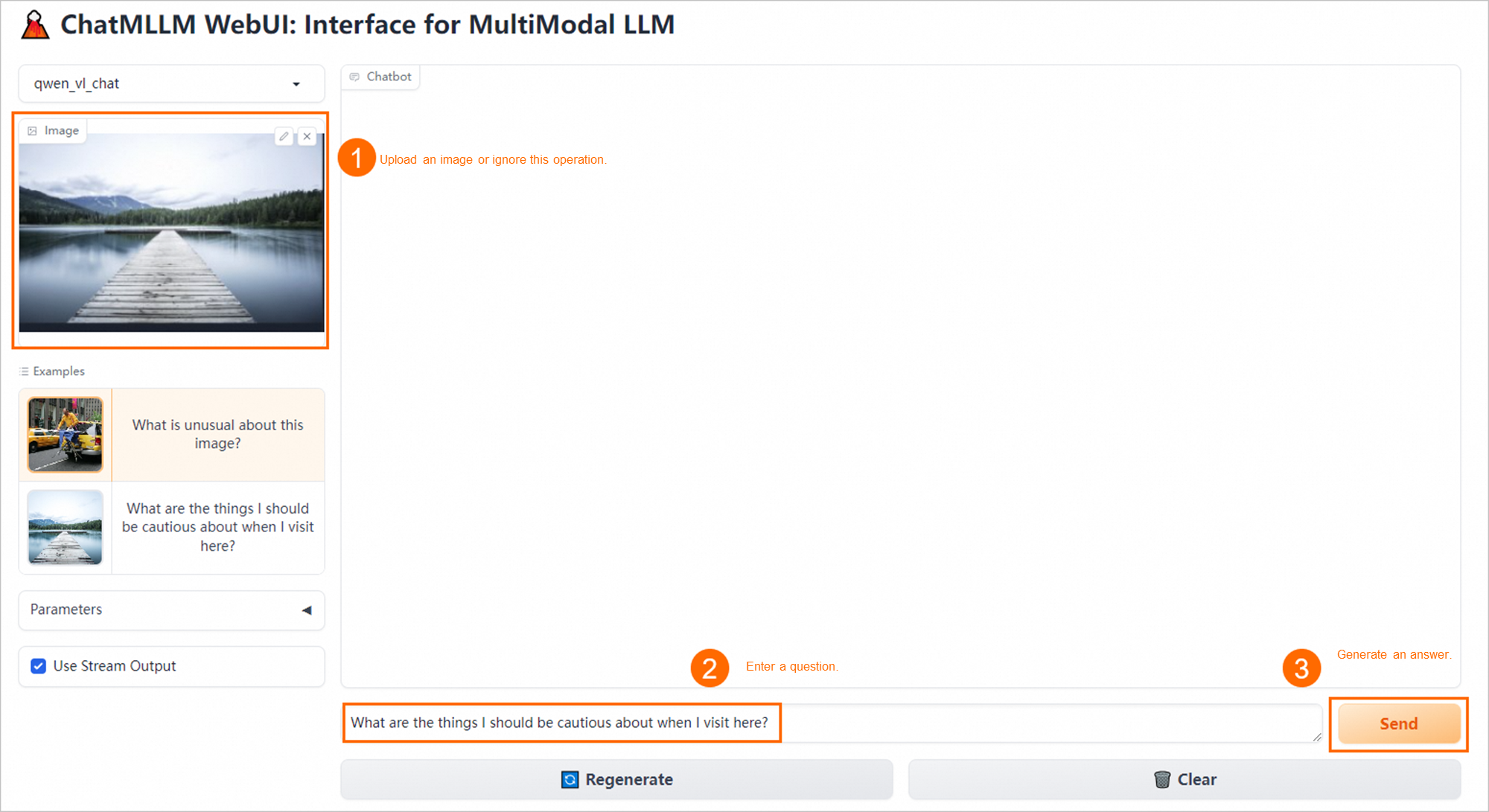
API 操作を呼び出してモデル推論を実行する
サービスのエンドポイントとトークンを取得します。
[Elastic Algorithm Service (EAS)] ページで、対象のサービス名をクリックします。次に、[基本情報] セクションで、[呼び出し情報の表示] をクリックします。
[呼び出し情報] ペインで、サービスのトークンとエンドポイントを取得します。
API 操作を呼び出してモデル推論を実行します。
PAI は次の API を提供します:
infer forward
推論結果を取得します。
説明WebUI と API 呼び出しは同時に使用できません。すでに WebUI を使用して呼び出しを行った場合は、まず
clear chat historyコードを実行してチャット履歴をクリアし、次にinfer forwardコードを実行して推論結果を取得します。サンプルコードで置き換える必要がある主要なパラメーターは次のとおりです:
パラメーター
説明
hosts
ステップ 1 で取得したエンドポイント。
authorization
ステップ 1 で取得したサービストークン。
prompt
質問の内容。英語での質問を推奨します。
image_path
イメージが存在するオンプレミスのパス。
次のサンプルコードは、Python を使用してモデル推論を実行する方法の例を示しています:
import requests import json import base64 def post_get_history(url='http://127.0.0.1:7860', headers=None): r = requests.post(f'{url}/get_history', headers=headers, timeout=1500) data = r.content.decode('utf-8') return data def post_infer(prompt, image=None, chat_history=[], temperature=0.2, top_p=0.7, max_output_tokens=512, use_stream = True, url='http://127.0.0.1:7860', headers={}): datas = { "prompt": prompt, "image": image, "chat_history": chat_history, "temperature": temperature, "top_p": top_p, "max_output_tokens": max_output_tokens, "use_stream": use_stream, } if use_stream: headers.update({'Accept': 'text/event-stream'}) response = requests.post(f'{url}/infer_forward', json=datas, headers=headers, stream=True, timeout=1500) if response.status_code != 200: print(f"Request failed with status code {response.status_code}") return process_stream(response) else: r = requests.post(f'{url}/infer_forward', json=datas, headers=headers, timeout=1500) data = r.content.decode('utf-8') print(data) def image_to_base64(image_path): """ イメージファイルを Base64 エンコードされた文字列に変換します。 :param image_path: イメージへのファイルパス。 :return: イメージの Base64 エンコードされた文字列表現。 """ with open(image_path, "rb") as image_file: # イメージのバイナリデータを読み取る image_data = image_file.read() # バイナリデータを Base64 にエンコードする base64_encoded_data = base64.b64encode(image_data) # バイトを文字列に変換し、末尾の改行文字を削除する base64_string = base64_encoded_data.decode('utf-8').replace('\n', '') return base64_string def process_stream(response, previous_text=""): MARK_RESPONSE_END = '##END' # 変更しないでください buffer = previous_text current_response = "" for chunk in response.iter_content(chunk_size=100): if chunk: text = chunk.decode('utf-8') current_response += text parts = current_response.split(MARK_RESPONSE_END) for part in parts[:-1]: new_part = part[len(previous_text):] if new_part: print(new_part, end='', flush=True) previous_text = part current_response = parts[-1] remaining_new_text = current_response[len(previous_text):] if remaining_new_text: print(remaining_new_text, end='', flush=True) if __name__ == '__main__': # <service_url> をサービスエンドポイントに置き換えます。 hosts = '<service_url>' # <token> をサービストークンに置き換えます。 head = { 'Authorization': '<token>' } # チャット履歴を取得 chat_history = json.loads(post_get_history(url=hosts, headers=head))['chat_history'] # 質問の内容。英語での質問を推奨します。 prompt = 'Please describe the image' # path_to_your_image をイメージのローカルパスに置き換えます。 image_path = 'path_to_your_image' image_base_64 = image_to_base64(image_path) post_infer(prompt = prompt, image = image_base_64, chat_history = chat_history, use_stream=False, url=hosts, headers=head)get chat history
チャット履歴を取得します。
サンプルコードで置き換える必要がある主要なパラメーターは次のとおりです:
パラメーター
説明
hosts
ステップ 1 で取得したサービスエンドポイントを設定します。
authorization
ステップ 1 で取得したサービストークンを設定します。
入力パラメーターは必要ありません。
次の表に、出力パラメーターを示します。
パラメーター
タイプ
注
chat_history
List[List]
会話履歴。
次のサンプルコードは、Python を使用してモデル推論を実行する方法の例を示しています:
import requests import json def post_get_history(url='http://127.0.0.1:7860', headers=None): r = requests.post(f'{url}/get_history', headers=headers, timeout=1500) data = r.content.decode('utf-8') return data if __name__ == '__main__': # <service_url> をサービス URL に置き換えます。 hosts = '<service_url>' # <token> をサービストークンに置き換えます。 head = { 'Authorization': '<token>' } chat_history = json.loads(post_get_history(url=hosts, headers=head))['chat_history'] print(chat_history)clear chat history
チャット履歴をクリアします。
サンプルコードで置き換える必要がある主要なパラメーターは次のとおりです:
パラメーター
説明
hosts
ステップ 1 で取得したエンドポイントを設定します。
authorization
ステップ 1 で取得したサービストークンを設定します。
入力パラメーターは必要ありません。
返される結果は success です。
次のサンプルコードは、Python を使用してモデル推論を実行する方法の例を示しています:
import requests import json def post_clear_history(url='http://127.0.0.1:7860', headers=None): r = requests.post(f'{url}/clear_history', headers=headers, timeout=1500) data = r.content.decode('utf-8') return data if __name__ == '__main__': # <service_url> をサービスエンドポイントに置き換えます。 hosts = '<service_url>' # <token> をサービストークンに置き換えます。 head = { 'Authorization': '<token>' } clear_info = post_clear_history(url=hosts, headers=head) print(clear_info)