オープンソースの Kohya_ss サービスを EAS 上にデプロイし、LoRA モデルの学習を行い、Stable Diffusion に適用して AI アート生成の品質を向上させます。
前提条件
-
EAS を有効化し、デフォルトのワークスペースを作成します。詳細については、「PAI の有効化とデフォルトワークスペースの作成」をご参照ください。
-
Resource Access Management (RAM) ユーザーを使用してモデルをデプロイする場合は、当該 RAM ユーザーに EAS の管理権限を付与します。詳細については、「クラウド製品の依存関係と権限:EAS」をご参照ください。
-
学習用素材、出力モデルファイル、およびログを格納するため、同一リージョンに Object Storage Service (OSS) バケットおよびフォルダを作成します。ファイルのアップロード方法については、「ファイルのアップロード」をご参照ください。
事前準備
-
OSS コンソール にログインし、同一リージョン内のバケットパスに移動します。例:
oss://kohya-demo/kohya/。 -
現在のバケットパス内に新しいプロジェクトフォルダを作成します。例:
KaraDetroit_loar。このプロジェクトフォルダ内に、Image、Log、Modelという名前の 3 つのフォルダを作成します。任意で、このプロジェクトフォルダに JSON 構成ファイルをアップロードできます。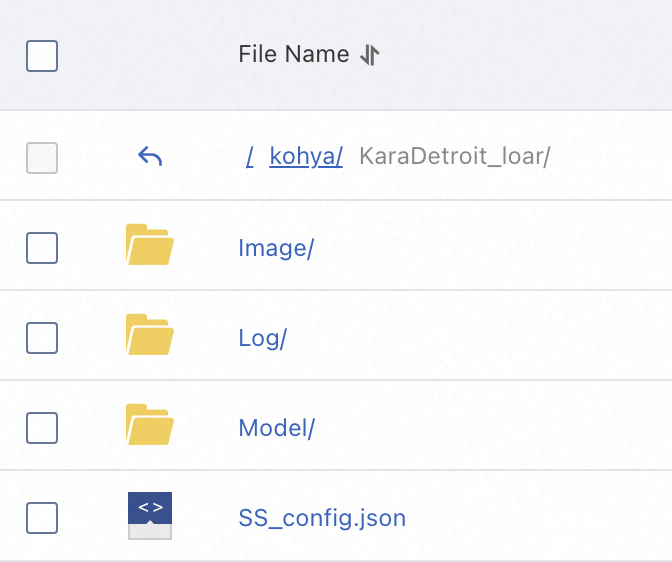
-
Image:学習用素材のソースファイルを格納します。
-
Model:学習完了後のモデルファイルを格納します。
-
Log:ログを格納します。
-
SS_config.json:パラメーターのバッチ構成用 JSON ファイルです(任意)。フォルダパスや出力モデル名などのパラメーターを JSON ファイル内で変更してください。構成の詳細については、GitHub をご参照ください。サンプルファイルについては、「SS_config.json」をご参照ください。
-
-
準備済みの画像を
Imageフォルダにアップロードします。本トピックでは、画像および説明ファイルを含むサンプルパッケージ(100_pic.zip)を使用します。このファイルをダウンロード・解凍し、得られたフォルダを OSS にアップロードします。結果は以下の図のとおりです。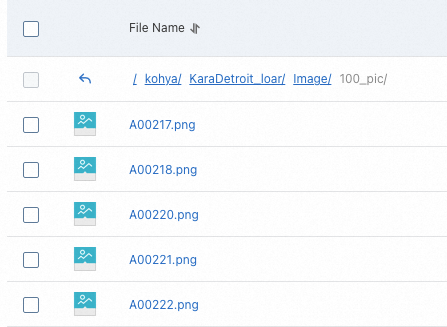 重要
重要-
サポートされる画像フォーマットは、
.png、.jpg、.jpeg、.webp、.bmpです。 -
各画像には、同じ名前で
.txt拡張子を持つ説明ファイルが必要です。説明文はファイルの 1 行目に記述してください。画像に複数の説明がある場合は、カンマで区切ってください。 -
画像フォルダ名は「数字_名前」の形式である必要があります(例:100_pic)。名前は OSS のファイル命名規則に準拠した任意の文字列で構いません。数字は、各画像を何回繰り返し学習するかを示します。通常は 100 以上が推奨されます。総学習反復回数は、一般的に 1,500 を超える必要があります。
-
フォルダに 10 枚の画像が含まれる場合、各画像は
1500/10=150回学習されます。画像フォルダ名の数字には「150」を指定できます。 -
フォルダに 20 枚の画像が含まれる場合、各画像は
1500/20=75 (<100)回学習されます。画像フォルダ名の数字には「100」を指定できます。
-
-
Kohya_ss サービスのデプロイ
-
PAI コンソール にログインします。ページ上部からリージョンを選択し、目的のワークスペースを選択して、Elastic Algorithm Service (EAS) をクリックします。
-
サービスのデプロイ をクリックします。カスタムモデルデプロイメント セクションで、カスタムデプロイメント をクリックします。
-
Custom Deployment ページで、フォームまたは JSON 構成を指定してパラメーターを設定します。
フォームによるパラメーター設定
パラメーター
説明
Basic Information
Service Name
任意のサービス名を指定します。本トピックでは例として kohya_ss_demo を使用します。
Environment Information
Deployment Method
Image-based Deployment を選択し、Enable Web App を選択します。
Image Configuration
Alibaba Cloud Image リストから kohya_ss > kohya_ss:2.2 を選択します。
説明バージョンは頻繁に更新されます。デプロイ時には最新のイメージバージョンを選択してください。
Storage Mount
マウントタイプとして OSS を選択し、以下のパラメーターを設定します:
-
Uri:同一リージョン内の OSS パスを選択します。本トピックでは
oss://kohya-demo/kohya/を使用します。 -
マウントパス:任意のパスを指定します。本トピックでは
/workspaceを使用します。重要読み取り専用 スイッチをオフにしてください。オンの場合、モデルファイルを OSS に書き込めません。
Command to Run
ランタイムイメージを選択すると、システムが自動的に実行コマンドを構成します。本トピックでは
python -u kohya_gui.py --listen=0.0.0.0 --server_port=8000 --headlessを使用します。-
--listen:プログラムを指定されたローカル IP アドレスにバインドし、外部リクエストの受信および処理を行います。 -
--server_port:リスニングポート番号です。
Resource Information
Resource Type
Public Resources を選択します。
Deployment
リソース仕様については、コストパフォーマンス最適化の観点から ml.gu7i.c16m60.1-gu30 GPU を推奨します。本トピックでは現行最小仕様である ml.gu7i.c8m30.1-gu30 を使用します。
JSON によるパラメーター設定
Service Configurations セクションで、Edit をクリックし、JSON 形式で構成を入力します。
以下に JSON 構成のサンプルを示します。
重要以下の例では、4 行目("name")および 18 行目("oss")の構成を要件に応じて変更してください。
{ "metadata": { "name": "kohya_ss_demo", "instance": 1, "enable_webservice": true }, "cloud": { "computing": { "instance_type": "ecs.gn6e-c12g1.12xlarge", "instances": null } }, "storage": [ { "oss": { "path": "oss://kohya-demo/kohya/", "readOnly": false }, "properties": { "resource_type": "model" }, "mount_path": "/workspace" }], "containers": [ { "image": "eas-registry-vpc.cn-hangzhou.cr.aliyuncs.com/pai-eas/kohya_ss:1.2", "script": "python -u kohya_gui.py --listen=0.0.0.0 --server_port=8000 --headless", "port": 8000 }] } -
-
構成内容を確認後、Deploy をクリックします。モデルのデプロイには数分かかります。「サービスステータス」が 実行中 に変わると、サービスのデプロイが完了します。
LoRA モデルの学習
-
サービスの Overview ページで、Web applications をクリックして Kohya_ss サービスページを開きます。
-
LoRA (LoRA) を選択します。

-
構成ファイル を設定します。このステップは任意です。
SS_config.jsonファイルが存在しない場合は、このステップをスキップしてください。 説明
説明構成ファイルのパスは、フォームによるパラメーター設定 セクションの マウントパス、OSS で作成したフォルダパス、および SS_config.json で構成されます。本トピックでは、パスは
/workspace/KaraDetroit_loar/SS_config.jsonです。 -
SourceModel を設定します。本トピックでは、checkpoint よりもセキュリティ性が高い safetensors を使用します。

-
フォルダ パラメーターを設定します。OSS で作成した
Image、Log、Modelフォルダのパスを入力し、出力ファイル名を指定します。
パラメーター
説明
画像フォルダ
学習用画像を格納するフォルダのパスです。フォームによるパラメーター設定 セクションの Mount Path と、OSS で作成した
Imageパスを連結したものになります。本トピックでは、パスは/workspace/KaraDetroit_loar/Imageです。ログフォルダ
ログ出力用フォルダのパスです。フォームによるパラメーター設定 セクションの Mount Path と、OSS で作成した
Logパスを連結したものになります。本トピックでは、パスは/workspace/KaraDetroit_loar/Logです。出力フォルダ
モデル出力用フォルダのパスです。フォームによるパラメーター設定 セクションの Mount Path と、OSS で作成した
Modelパスを連結したものになります。本トピックでは、パスは/workspace/KaraDetroit_loar/Modelです。モデル出力名
モデルの出力名です。例:my_model。
-
パラメーター を設定します。サンプル値については、事前準備 ステップの
SS_config.jsonファイルの内容をご参照ください。パラメーター
説明
LoRA タイプ
LoRA タイプ:
-
LoCON:Res、Block、Transformerなどの SD の各レイヤーを調整できます。 -
LoHA:同一サイズでより多くの情報を処理します。
LoRA ネットワーク重み
LoRA ネットワーク重みです。継続学習を行う場合は、最後に学習された LoRA を選択します。このパラメーターは任意です。
学習バッチサイズ
学習時のバッチサイズです。値が大きいほど VRAM を多く消費します。
エポック
学習エポック数です。1 エポックは、全学習データを 1 回通過することを意味します。この値は手動で計算してください。一般的な計算式は以下のとおりです:
-
Kohya における総学習反復回数 = 学習画像数 × 繰り返し回数 × エポック数 / 学習バッチサイズ -
WebUI における総学習反復回数 = 学習画像数 × 繰り返し回数
クラス画像を使用する場合、Kohya および WebUI ともに総学習反復回数は 2 倍になり、Kohya でのモデル保存回数は半分になります。
N エポックごとに保存
N エポックごとにモデルを保存します。たとえば 2 を指定した場合、2 エポックごとに学習結果が保存されます。
キャプション拡張機能
キャプションファイルのファイル名拡張子(例:.txt)。このパラメーターは任意です。
混合精度
混合精度です。GPU の性能に依存します。デフォルトの選択肢は no、fp16、bf16 です。VRAM が 30 GB を超える GPU の場合は、bf16 を指定してください。
保存精度
保存精度です。上記と同じです。
コアあたりの CPU スレッド数
コアあたりの CPU スレッド数です。主に VRAM に影響します。購入済みのインスタンスおよび要件に応じて調整してください。
学習率
学習率です。デフォルト値は 0.0001 です。
学習率スケジューラ
学習率スケジューラです。必要に応じて
cosineやcosine with restartなどの関数を選択してください。LR Warmup(ステップ数の %)
プリフェッチステップ数を設定します。必要に応じてこの値を調整してください。デフォルト値は 10 です。プリフェッチが不要な場合は、0 を選択してください。
オプティマイザ
オプティマイザです。必要に応じて選択してください。デフォルト値は
AdamW8bitです。DAdaptationは自動操作を表します。最大解像度
最大解像度です。画像の特性に応じて設定してください。
ネットワークランク(次元)
モデルの複雑さです。ほとんどのシナリオでは、値 128 で十分です。
ネットワーク Alpha
通常はネットワークランク(次元)以下または等しい値を設定します。一般的な設定例は、ネットワークランク 128、ネットワーク Alpha 64 です。
畳み込み ランク (次元)
およびコンボリューション アルファ
畳み込みの次数です。これは LoRA がモデルに対して行うファインチューニングの範囲を示します。LoRA タイプに応じて調整してください。
Kohya 公式の推奨設定:
-
LoCon:dim <= 64、alpha = 1(またはそれ以下) -
LoHA:dim <= 32、alpha = 1
clip skip
CLIP モデルの使用回数です。値の範囲は 1~12 です。値が小さいほど、生成画像は元の画像または入力画像に近くなります。
-
リアリスティックなモデルの場合は、1 を選択してください。
-
アニメ風のモデルの場合は、2 を選択してください。
N エポックごとにサンプル取得
N エポックごとにサンプルを取得します。数エポックごとにサンプルを保存します。
サンプルプロンプト
サンプルプロンプトです。以下のパラメーターを含むコマンドを使用します:
-
--n:プロンプト、否定的なプロンプト。 -
--w:画像幅。 -
--h:画像高さ。 -
--d:画像シード。 -
--l:プロンプト関連性(cfg)。 -
--s:反復ステップ数(steps)。
-
-
ページ下部で 学習開始 をクリックします。

-
EAS ページのサービス一覧で、サービス名をクリックしてサービス詳細ページに移動します。Log をクリックして、リアルタイムで学習進捗を確認します。

ログに
model savedが表示されたら、学習が完了しています。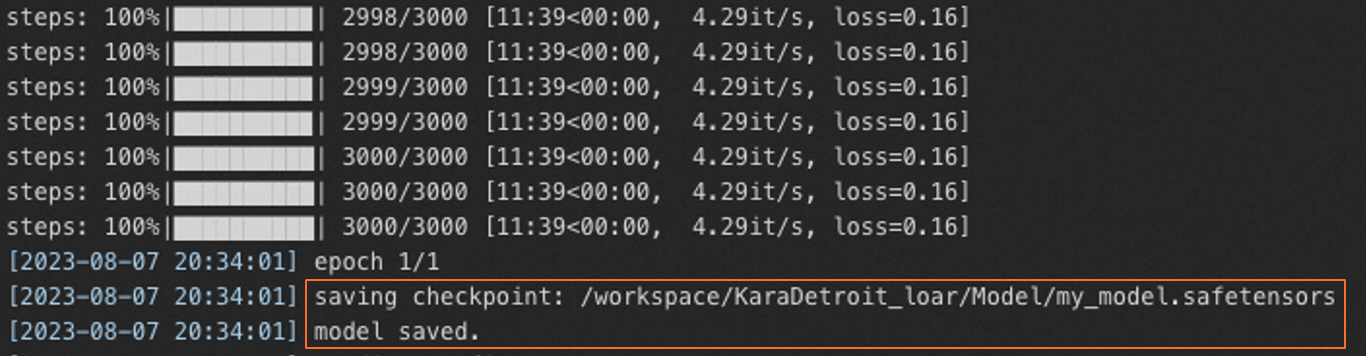
-
学習が完了したら、構成済みのモデルフォルダ(
Model)から学習済み LoRA モデルファイルを取得します。例:my_model.safetensors。
Stable Diffusion を使用した学習済み LoRA モデルによる AI アート生成
LoRA モデルの学習が完了したら、そのモデルファイルを対応する Stable Diffusion WebUI ディレクトリにアップロードし、マウントすることで、学習済み LoRA モデルを用いた画像生成が可能になります。Stable Diffusion サービスのデプロイ方法については、「EAS を使用して 5 分で Stable Diffusion サービスをデプロイし、テキストから画像を生成する」をご参照ください。
以下では、LoRA モデルファイルを Stable Diffusion WebUI にアップロードする方法について説明します。
Stable Diffusion WebUI Cluster Edition
-
Stable Diffusion WebUI のランタイムイメージを構成します。stable-diffusion-webui:4.2-cluster-webui のようなクラスター版を選択します。サービスが起動すると、マウントされた OSS パス内に
/data-{current_user_ID}/models/Loraパスが自動的に作成されます。 -
Command to Run セクションで、以下のパラメーターを追加します:
-
--lora-dir:このパラメーターは任意です。-
--lora-dirパラメーターを指定しない場合、すべてのユーザーのモデルファイルは分離されます。読み込まれるのは{OSS_path}/data-{current_user_ID}/models/Loraパス内のモデルファイルのみです。 -
--lora-dirパラメーターを指定した場合、すべてのユーザーが指定されたディレクトリおよび{OSS_path}/data-{current_user_ID}/models/Loraディレクトリからモデルファイルを読み込みます。例:--lora-dir /code/stable-diffusion-webui/data-oss/models/Lora。
-
-
--data-dir {OSS_mount_path}(例:--data-dir /code/stable-diffusion-webui/data-oss)。
-
-
LoRA モデルファイルを
{OSS_path}/data-{current_user_ID}/models/Loraにアップロードします。例:oss://bucket-test/data-oss/data-1596******100/models/Lora。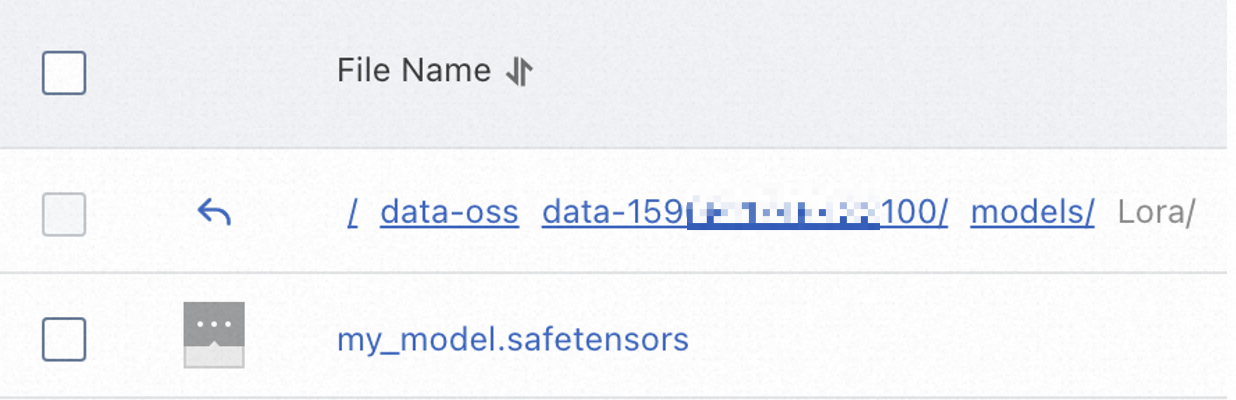 説明
説明OSS 内の
/data-{current_user_ID}/models/Loraパスは、サービス起動後に自動的に作成されます。LoRA モデルファイルは、サービス起動後にアップロードしてください。{current_user_ID}は、ページ右上隅のプロフィール画像をクリックすることで確認できます。
Stable Diffusion WebUI Basic Edition
-
Stable Diffusion WebUI のランタイムイメージを構成します。stable-diffusion-webui:4.2-standard のように
-clusterを含まないバージョンを選択します。サービスが起動すると、マウントされた OSS パス内に/models/Loraパスが自動的に作成されます。 -
Command to Run セクションで、
--data-dir {OSS_mount_path}パラメーターを追加します。例:--data-dir /code/stable-diffusion-webui/data-oss。 -
LoRA モデルファイルを
{OSS_path}/models/Loraにアップロードします。例:oss://bucket-test/data-oss/models/Lora。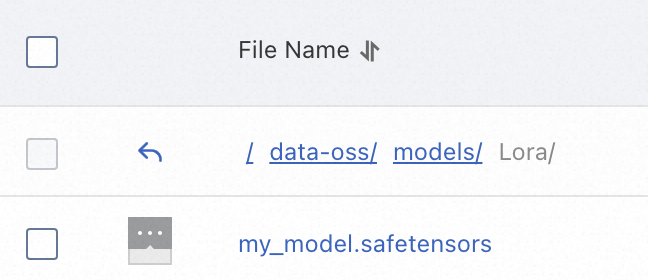 説明
説明マウントされた OSS バケット内の
/models/Loraパスは、サービス起動後に自動的に作成されます。LoRA モデルファイルは、サービス起動後にアップロードしてください。