このトピックでは、Machine Learning Platform for AI (PAI) が提供するテキスト分析コンポーネントを使用して、ニュース分類モデルを構築する方法について説明します。
背景情報
ニュース分類は、テキストマイニングにおける一般的なシナリオです。多くのメディアやコンテンツプロデューサーは、手動でニュースにラベルを付けてニュースを分類しますが、これには手間がかかります。PAI が提供するインテリジェントなテキストマイニングアルゴリズムを使用して、ニュース分類タスクを自動化できます。タスクには、単語分割、品詞変換、ストップワードのフィルタリング、トピックモデリング、クラスタリングが含まれます。このトピックで説明するパイプラインでは、Partially Labeled Dirichlet Allocation (PLDA) アルゴリズムを使用してトピックモデリングを実行し、重みに基づいてトピックをクラスター化してニュースを分類します。
このトピックで使用されるデータセットは、実験目的でのみ使用されます。
前提条件
Machine Learning Designer がアクティブ化され、ワークスペースが作成されていること。詳細については、「PAI をアクティブ化してデフォルトのワークスペースを作成する」をご参照ください。
MaxCompute リソースがワークスペースに関連付けられていること。詳細については、「ワークスペースの管理」をご参照ください。
テキスト分析に基づくニュースの分類
Machine Learning Designer ページに移動します。
PAI コンソールにログインします。
左側のナビゲーションウィンドウで、[Workspaces] をクリックします。[Workspaces] ページで、管理するワークスペースの名前をクリックします。
左側のナビゲーションウィンドウで、 を選択します。
パイプラインを作成します。
[ビジュアル化モデリング (Designer)] ページで、[プリセットテンプレート] タブをクリックします。
[プリセットテンプレート] タブの [テキスト分析-ニュース分類] セクションで、[作成] をクリックします。
[パイプラインの作成] ダイアログボックスで、パラメーターを設定します。デフォルト値を使用できます。
[パイプラインデータパス] パラメーターに指定された値は、パイプラインのランタイム中に生成される一時的なデータとモデルの Object Storage Service (OSS) バケットパスです。
[OK] をクリックします。
パイプラインの作成には約 10 秒かかります。
パイプラインリストで、[テキスト分析-ニュース分類] パイプラインをダブルクリックしてパイプラインを開きます。
次の図に示すように、キャンバス上でパイプラインのコンポーネントを表示します。システムは、プリセットテンプレートに基づいてパイプラインを自動的に作成します。
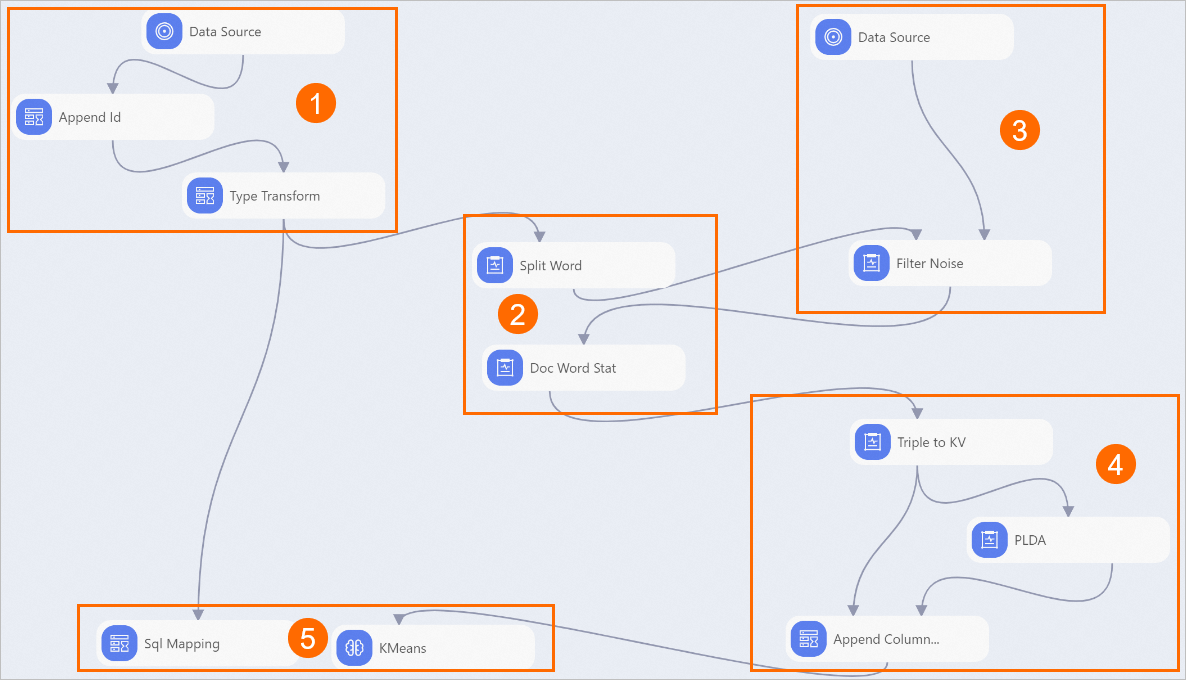
コンポーネント
説明
①
Append Id コンポーネントは、データセットから読み取られたデータに ID 列を追加します。データセット内の各データレコードは、1 つのニュースです。各データレコードを一意に識別するために ID 列を追加する必要があります。これにより、後続のアルゴリズムの計算が容易になります。
②
このセクションに表示されるコンポーネントは、ニュースのコンテンツを単語に分割し、各単語の出現回数をカウントします。Split Word コンポーネントは、ニュースのコンテンツ (content フィールドの値) を単語に分割します。Doc Word Stat コンポーネントは、ストップワードが除外されたテキスト内の各単語の出現回数をカウントします。
③
Filter Noise コンポーネントは、ニュースのコンテンツからストップワードを除外します。ストップワードには、ニュースの意味に寄与しない句読点や文法上の助詞が含まれます。
④
このセクションに表示されるコンポーネントは、トピックモデリングを実行します。
[Triple To KV] コンポーネントは、単語の周波数データを PLDA コンポーネントでサポートされているフォーマットに変換します。このフォーマットは、テキストの単語を数値に変換します。
パラメーター:
append_id: ニュースの一意の ID。
key_value: 単語の周波数を示すキーと値のペア。コロン (:) の前の数字は単語の数値 ID です。コロン (:) の後の数字は単語の出現回数です。
[PLDA] コンポーネントはトピックモデルをトレーニングします。
PLDA アルゴリズムはトピックモデリングアルゴリズムです。このアルゴリズムは、各ニュースのトピックを示す単語を見つけることができます。このパイプラインでは 50 個のトピックが設定されています。[PLDA] コンポーネントの 5 番目の出力ポートは、各ニュースが 50 個のトピックのいずれかに属する確率を示すデータを生成します。
⑤
このセクションに表示されるコンポーネントは、分類結果を分析および評価します。前述のステップが実行された後、ニュースのトピックはベクターに変換されます。ベクター間の距離に基づいてクラスタリングを実行し、ニュースを分類できます。
パイプラインを実行して結果を表示します。
キャンバスの左上隅にある [実行] ボタンをクリックします。
パイプラインを実行した後、キャンバスで KMeans を右クリックし、 を選択して分類結果を表示します。
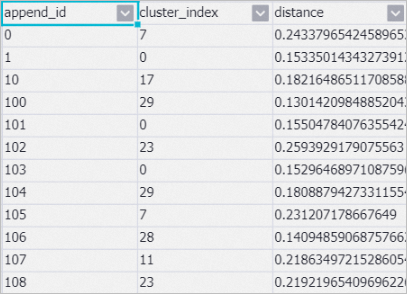
cluster_index: カテゴリの名前。
append_id: ニュースの一意の ID。
キャンバスで Sql Mapping を右クリックし、 を選択して、append_id 115、292、248、166 で識別されるニュースを表示します。
このパイプラインの分類結果は満足のいくものではありません。たとえば、2 つのスポーツニュース、1 つの金融ニュース、1 つの科学技術ニュースが同じカテゴリに分類されます。次のメソッドを使用して結果を改善できます。
パイプラインに、より大きなデータセットを使用します。
データセットに対して特徴量エンジニアリングまたはパラメーターチューニングを実行します。
パイプラインでは、[Sql Mapping] コンポーネントの [フィルター条件] パラメーターは、append_id115、292、248、166 で識別されるニュースを表示するようにプリセットされています。他のニュースを表示するには、次の例のフォーマットに基づいて [フィルター条件] パラメーターを設定できます。
append_id=292 or append_id=115 or append_id=248 or append_id=166 ;