Cloud Native Application Performance Optimizer (CNP) は、クラウドネイティブアプリケーションのパフォーマンスを評価・分析・最適化するためのプラットフォームです。CNP は LINGJUN クラスター向けのトレーニングパフォーマンス評価を自動化し、最適化の提案を提供します。
CNP プラットフォームへのアクセス
-
LINGJUN クラスターコンソール にログインします。
-
左側のナビゲーションウィンドウで、パフォーマンス評価 > CNP パフォーマンス評価 をクリックします。
-
CNP プラットフォームでは、パフォーマンス評価を開始 したり、評価結果を表示 したりできます。
-
ページの左下隅にある [戻る] をクリックして、LINGJUN クラスターコンソールに戻ります。
評価の開始
ステップ 1:クラスターの選択
ウェルカムページで [評価を開始] をクリックします。または、パフォーマンス評価ページで [評価を開始] をクリックして、最初のステップである クラスターの選択 を開始します。
-
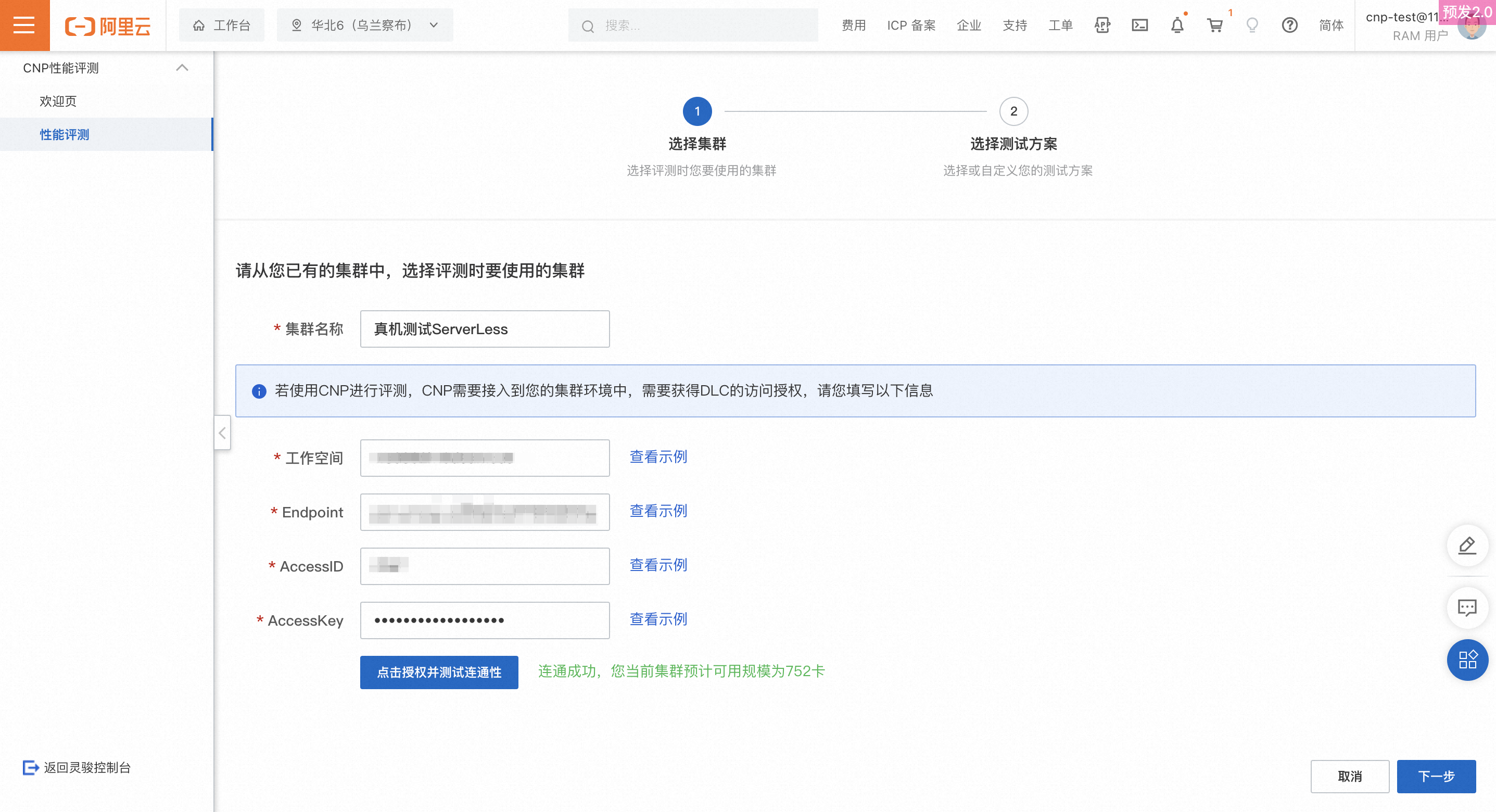
クラスター名:評価対象のクラスターを選択します。
-
DLC アクセス情報:必要な情報を入力し、[接続性テスト] をクリックします。接続が成功した場合は成功メッセージが表示されます。失敗した場合は、失敗理由が表示されます。一般的な失敗理由を次の表に示します。
失敗理由
推奨操作
接続タイムアウト
CNP をアクセスホワイトリストに追加して、再度試行してください。
情報が正しくない
AccessKey ID、AccessKey Secret、ワークスペース、エンドポイントのいずれかが正しくありません。情報を確認して、再度試行してください。
STS トークンの取得に失敗しました (D3001)
SLR の作成に失敗しました (D3002)
ARMS インスタンスの作成に失敗しました (D3003)
ARMS サービスのチェックに失敗しました (D3004)
ARMS を有効化してください。
ARMS 情報の取得に失敗しました (D3005)
SLR の作成権限がありません (D3006)
SLR 権限を付与してください。
接続性テストが成功したら、[次へ] をクリックして ステップ 2:テストプランの選択 に進みます。
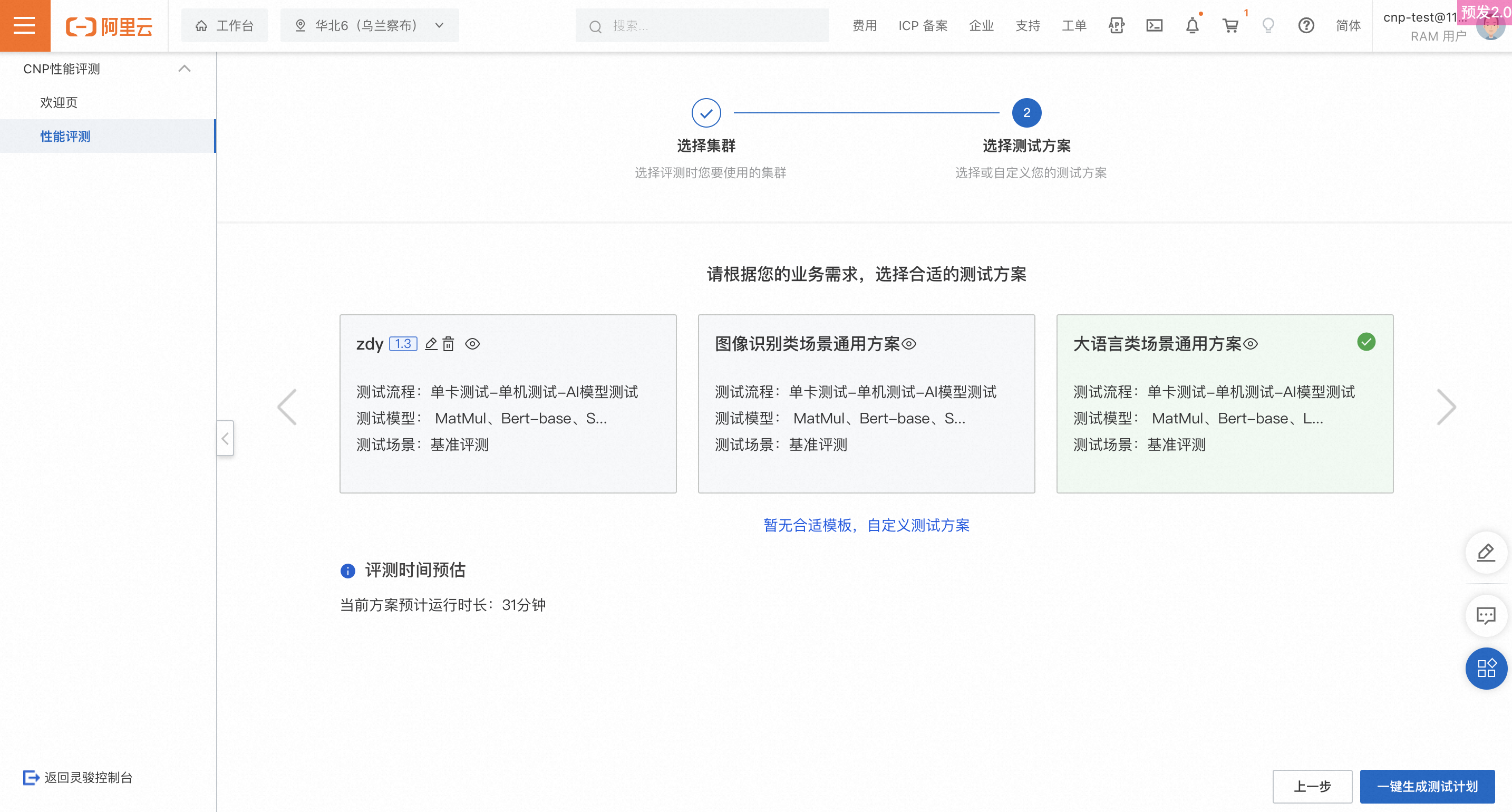
ステップ 2:テストプランの選択
テンプレートの使用
デフォルトのテストプランテンプレートが 2 種類用意されています。ビジネスシナリオに応じて選択してください。
|
プラン |
テスト内容 |
テスト対象クラスタースケール |
|
プラン A:大規模言語モデルシナリオ向け汎用プラン |
|
|
|
プラン B:画像認識シナリオ向け汎用プラン |
|
|
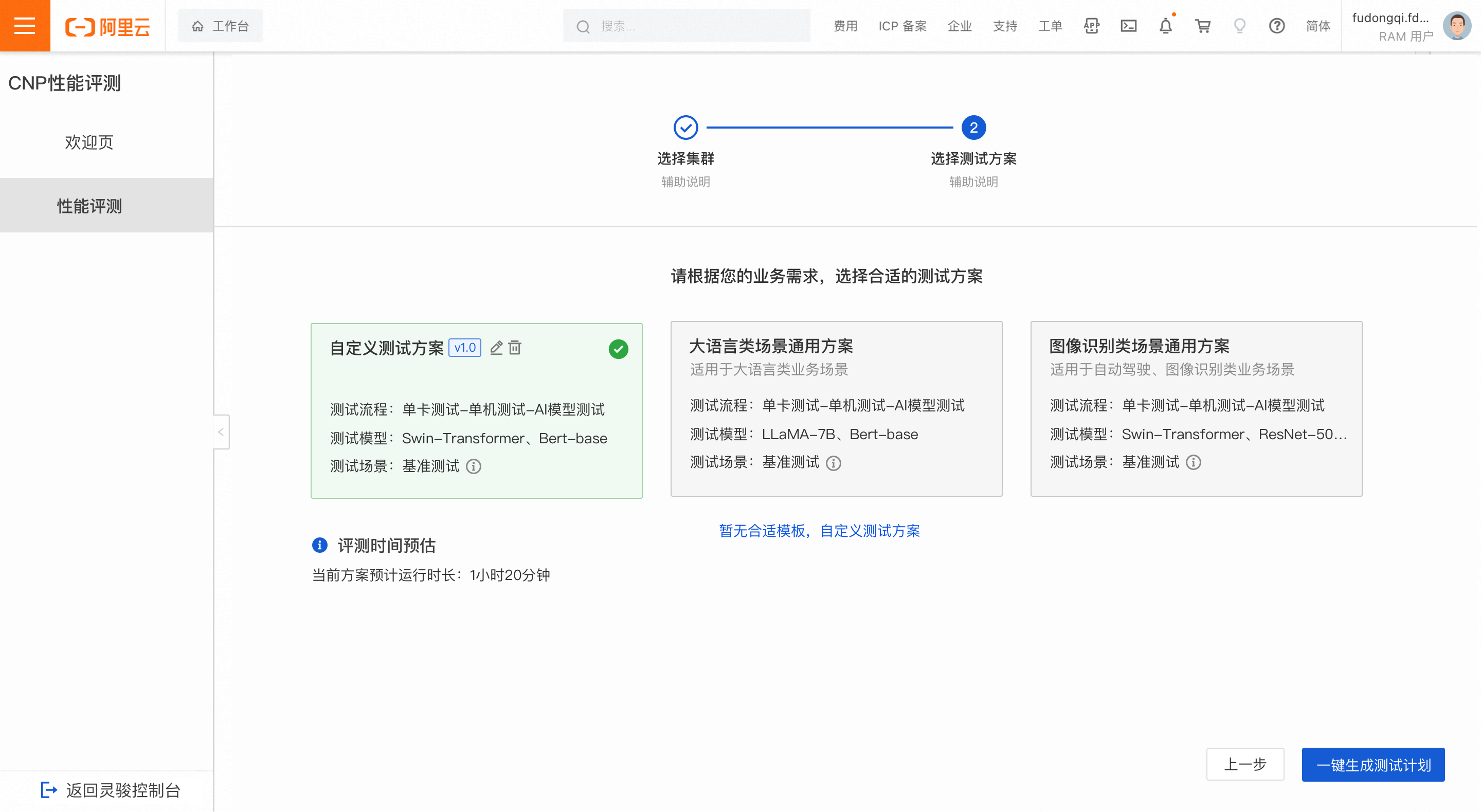
カスタムプラン
テンプレートが要件を満たさない場合は、カスタムテストプランを作成してください。
-
単一 GPU テスト:ノード数をカスタマイズできます。デフォルトのテストケースは MatMul です。
-
単一マシンテスト:ノード数をカスタマイズできます。デフォルトのテストケースは Bert-base です。
-
AI モデルテスト:評価対象の AI モデルおよび GPU 数をカスタマイズできます。
-
現在サポートされているモデルは、LLaMA-7B、Stable Diffusion、Swin-Transformer、Bert-base、UNet です。
-
デフォルトのパラメータ設定はベースライン構成を使用しています。具体的な構成はページ上でご確認いただけます。
評価時間の見積もり
テストプランを選択すると、システムはテスト内容およびステップ 1 で選択したクラスターの最大スケールに基づいて評価時間を見積もります。利用可能なノード数が最大値を下回る場合、実際の評価時間は見積もり時間を超えます。
ワンクリックで評価を開始
ステップ 1 およびステップ 2 を完了したら、[ワンクリックで評価を開始] をクリックして評価を開始します。
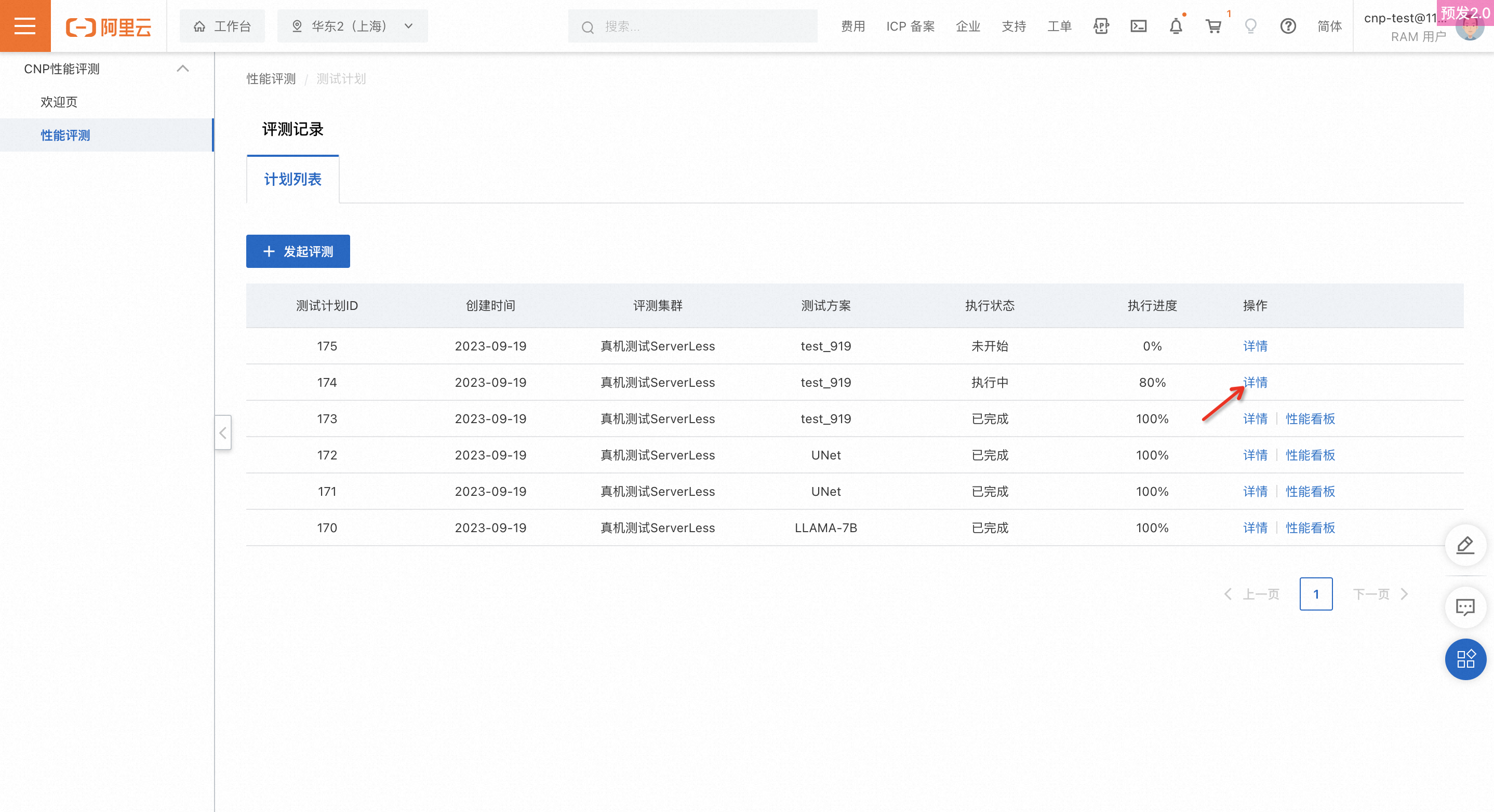
評価の進行状況と結果の表示
テストプランを作成後、テストプラン一覧ページでその実行ステータスと進行状況をリアルタイムで確認できます。[詳細] をクリックして、各ステージの進行状況を表示します。
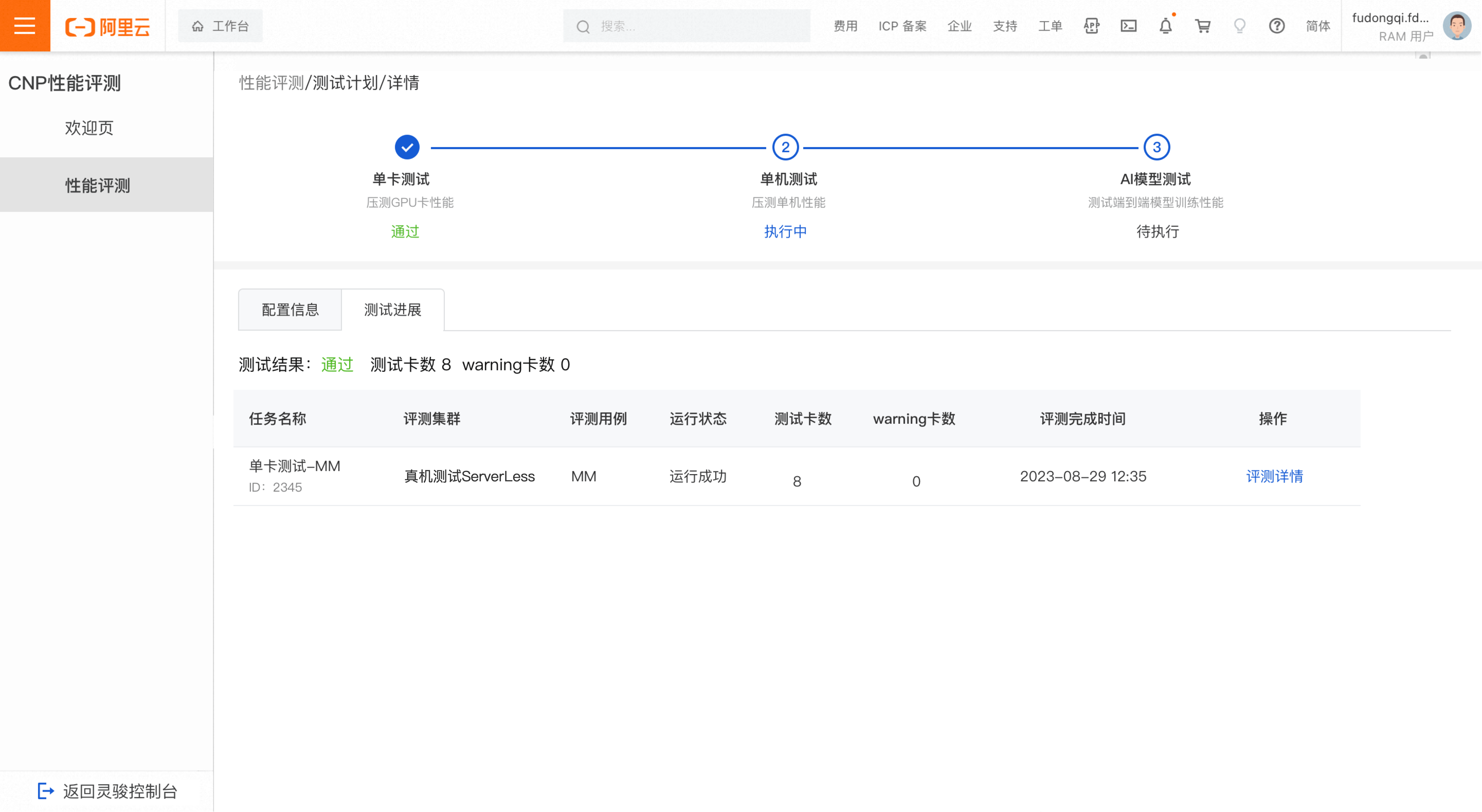
単一 GPU テスト
-
テスト合格
疑わしい故障 GPU または 警告 GPU が検出されない場合、単一 GPU テストは合格となります。
説明-
疑わしい故障カード:このカード上でタスクが失敗したことを示します。
-
警告カード:このカードの TFLOPS 変動が、反復の 5 % 以上で正常なしきい値範囲外となったことを示します。
-
正常なしきい値の計算ロジック:各反復におけるすべての GPU の中央値 TFLOPS をベースラインとして使用します。システムは、ベースライン ±3 % と 4 × シグマ(4 × 標準偏差)を比較し、大きい方の値を正常なしきい値範囲として使用します。
-
-
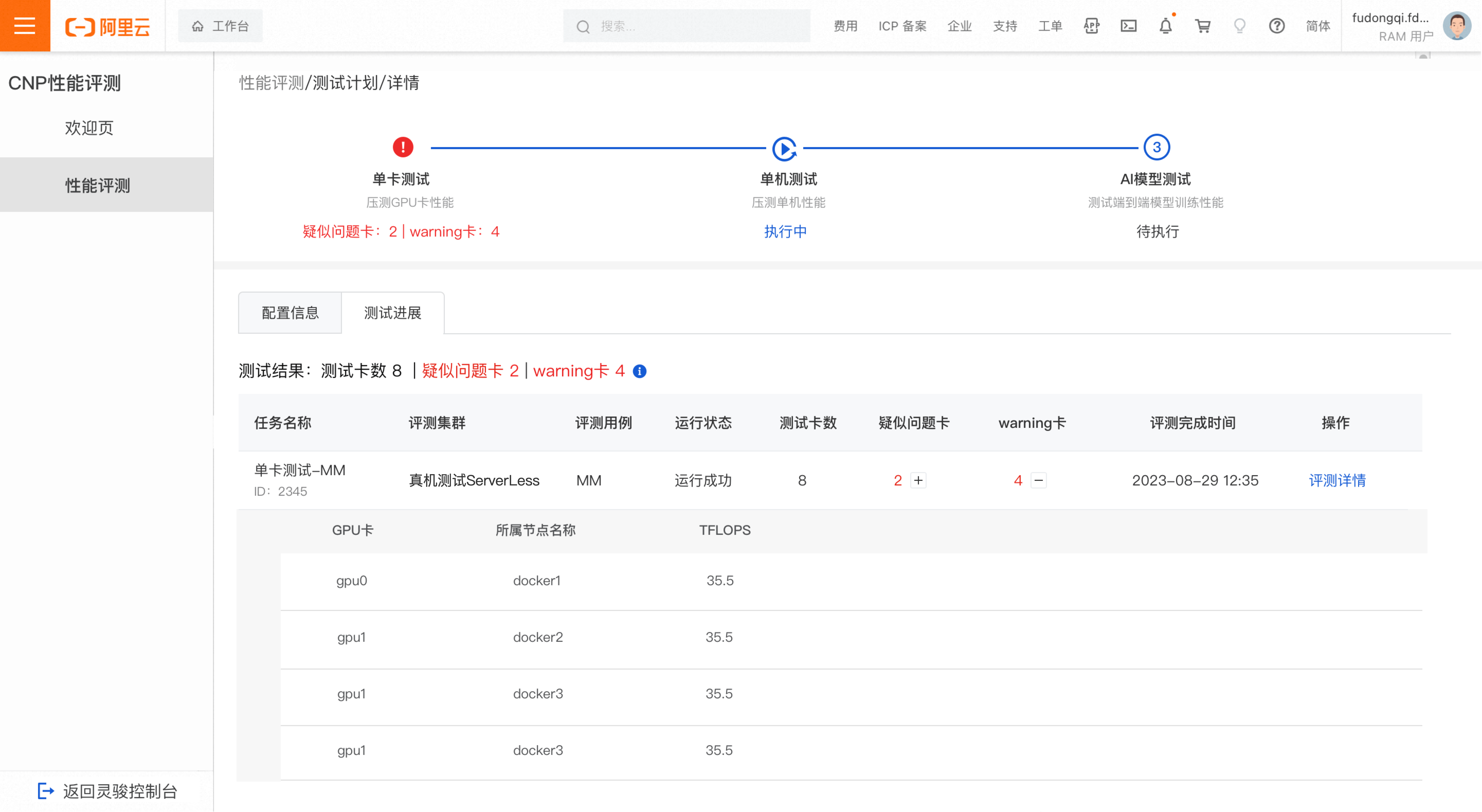
異常なテスト結果
疑わしい故障 GPU または 警告 GPU が検出された場合、単一 GPU テストの結果は異常となります。
評価タスク一覧でプラスアイコンをクリックして展開し、疑わしい故障 GPU または警告 GPU の詳細を表示します。異常なノードは O&M チームに報告して調査を依頼してください。[評価詳細] をクリックして、詳細な結果を表示します。
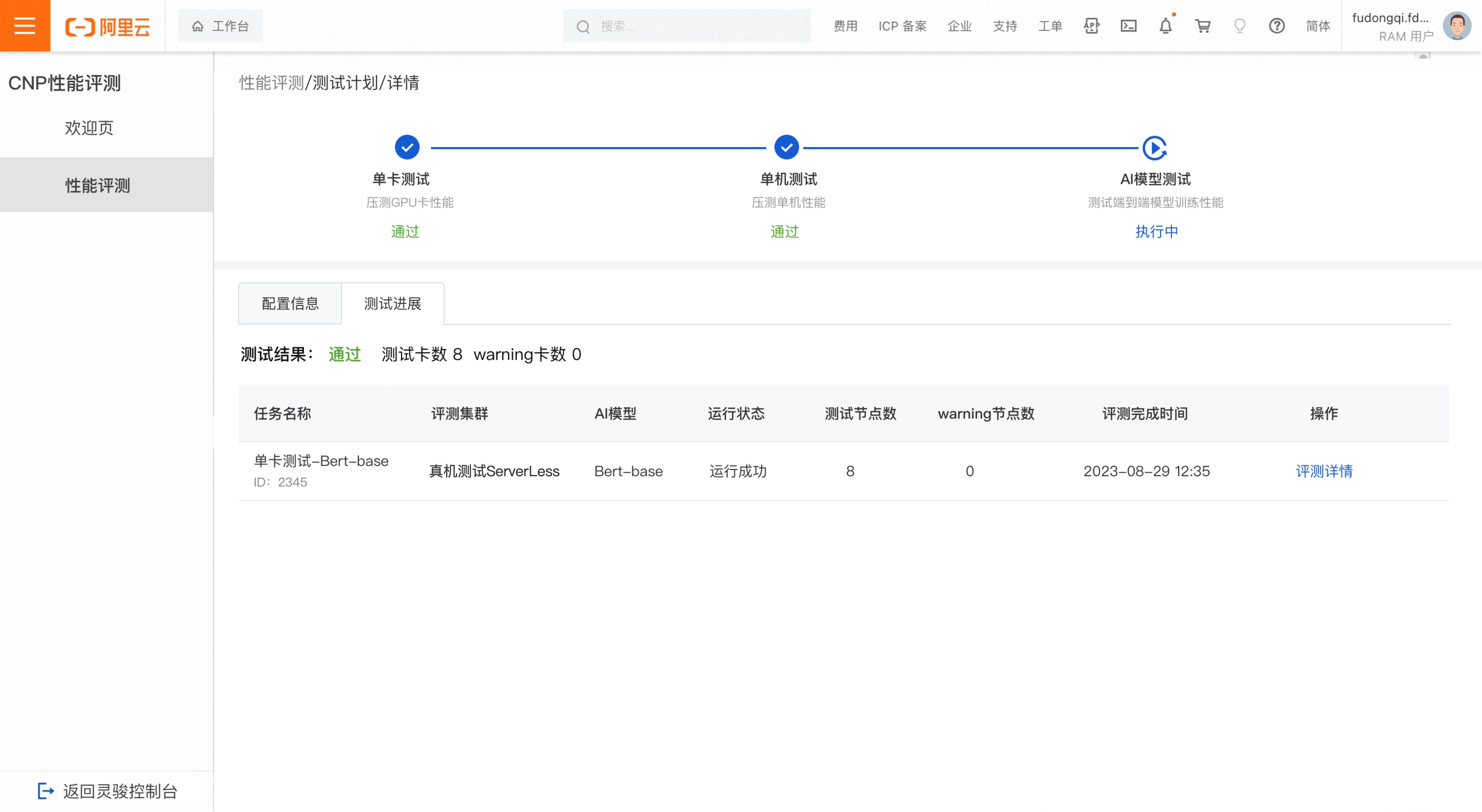
単一マシンテストの進行状況
-
テスト合格
疑わしい故障ノード または 警告ノード が検出されない場合、単一マシンテストは合格となります。
説明-
疑わしい故障ノード:このノード上の DLC job が失敗しており、ノードに障害がある可能性を示唆します。
-
警告ノード:このノードのスループットが、反復の 5 % 以上で正常なしきい値範囲外でした。
-
正常なしきい値の計算ロジック:各反復におけるすべてのノードの中央値スループットをベースラインとして使用します。システムは、ベースライン ±3 % と 4 × シグマ(4 × 標準偏差)を比較し、大きい方の値を正常なしきい値範囲として使用します。
-
-
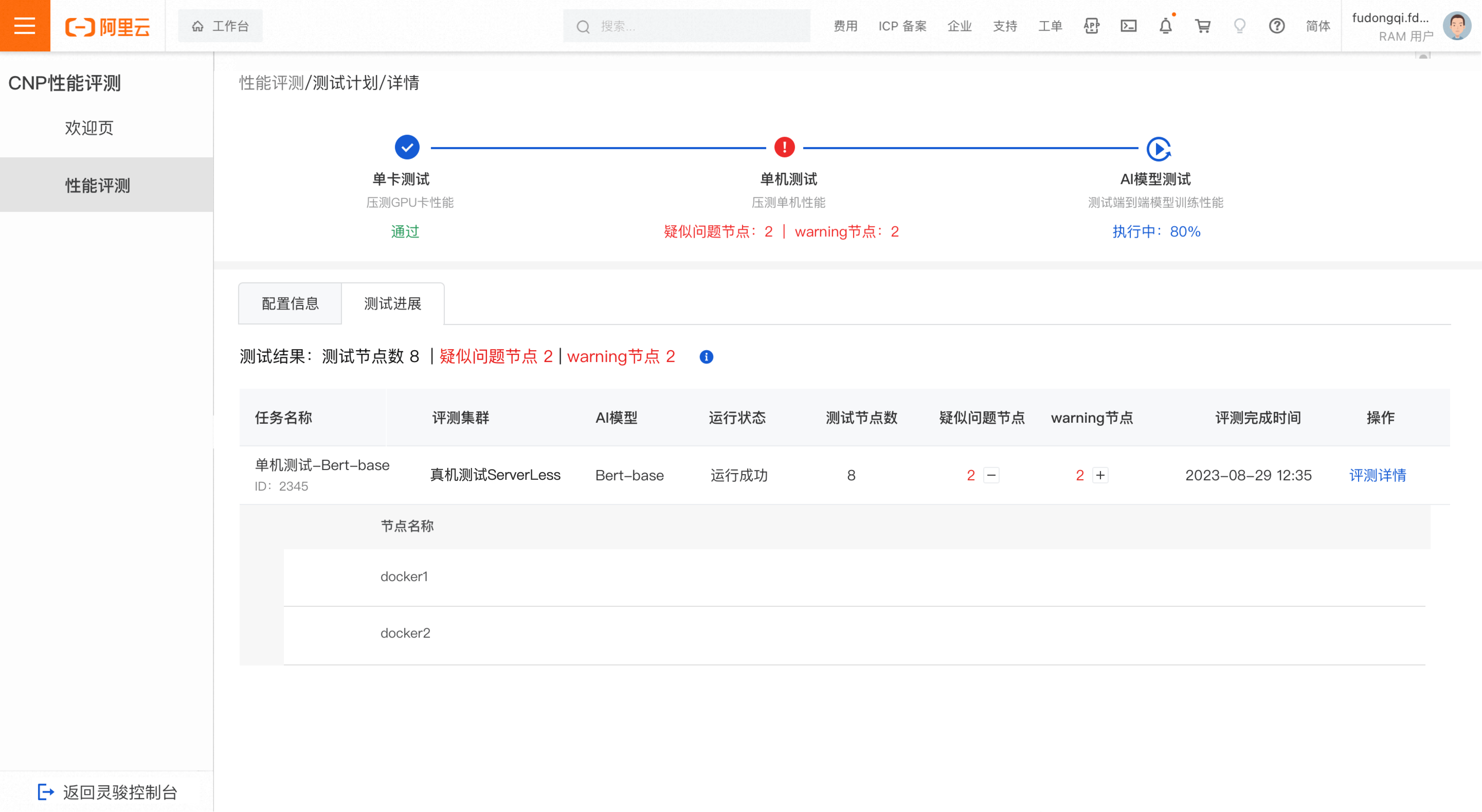
異常なテスト結果
疑わしい故障ノードまたは警告ノードが検出された場合、単一マシンテストの結果は異常となります。
評価タスク一覧で プラスアイコン をクリックして展開し、疑わしい故障ノードまたは警告ノードの詳細を表示します。異常なノードは O&M チームに報告して調査を依頼してください。[評価詳細] をクリックして、詳細な結果を表示します。
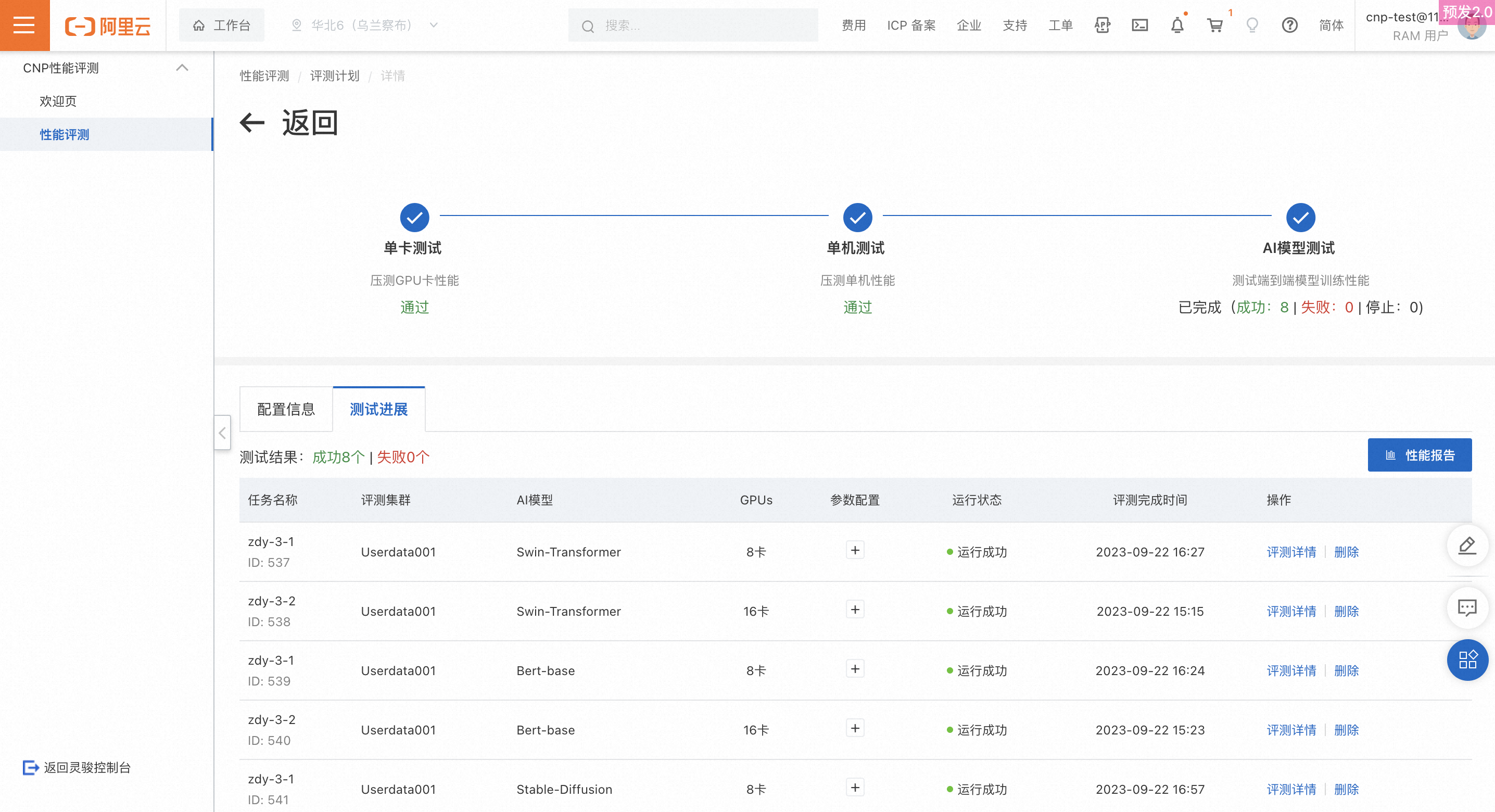
AI モデルテスト
-
テストの進行状況
保留中:すべてのタスクが実行待ちです。
完了:すべてのタスクが成功、失敗、または停止しました。
停止済み:すべてのタスクが停止しました。
実行中:一部のタスクが完了し、他のタスクが保留中または実行中です。
-
テストタスクリスト
現在のプランの AI モデルテストステージにおけるすべてのタスクを一覧表示します。実行中のタスクを終了するには、[停止] をクリックします。すべてのタスクを削除できます。
警告削除または失敗したタスクのデータはパフォーマンスダッシュボードに含まれません。タスクの削除は慎重に行ってください。
パフォーマンスダッシュボードの表示
ダッシュボードへのアクセス
完了 ステータスのテストプランについては、パフォーマンスダッシュボードを表示できます。AI モデルテストステージで正常に完了した評価タスクのデータが表示されます。
ダッシュボードの内容
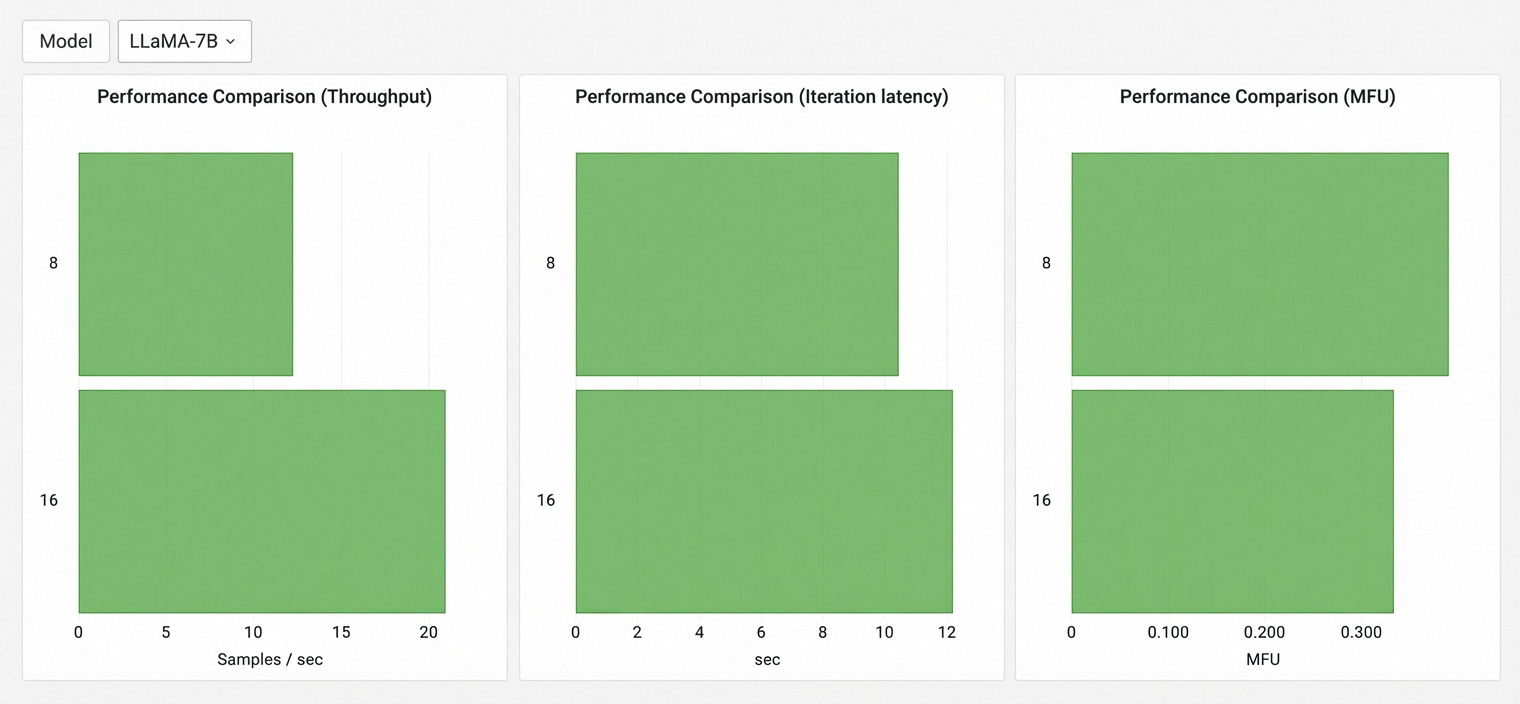
テストモデルのスケーラビリティ
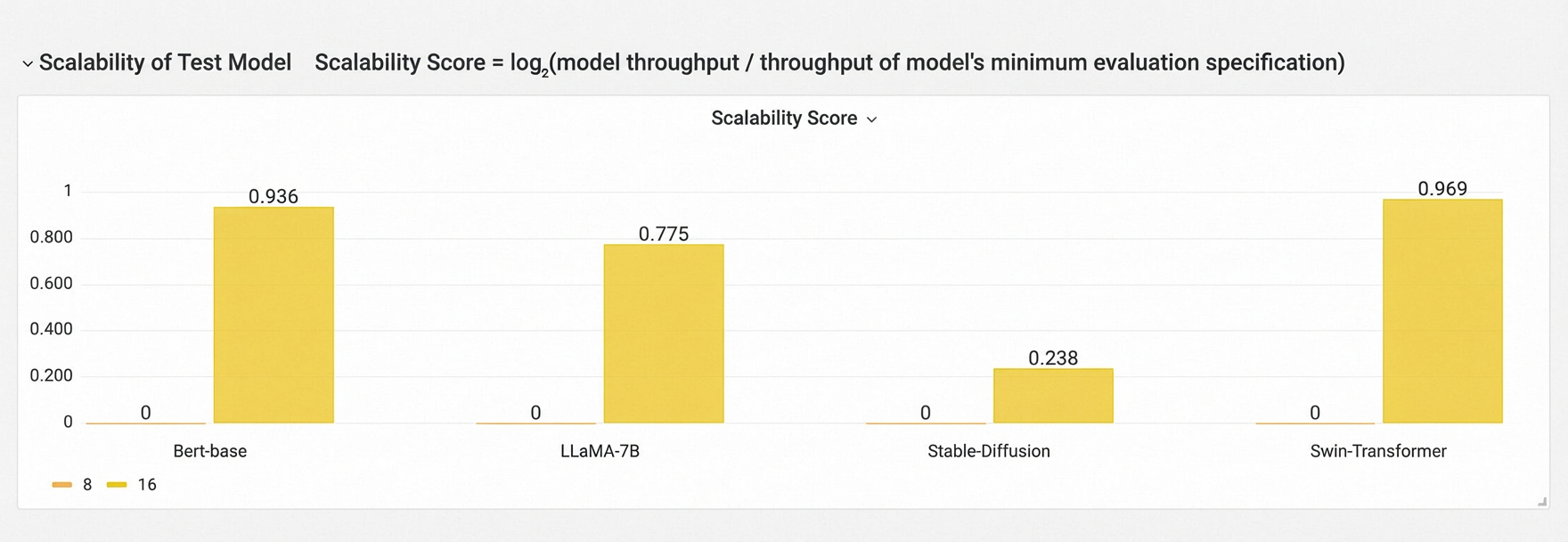
このチャートは、GPU 数が増加するにつれて各モデルのスループット傾向を示し、クラスター上でのモデルのスケーラビリティを反映しています。異なるモデル間の結果は比較されません。
式:スケーラビリティスコア = log₂(モデルスループット / 最小評価構成のスループット)
例:以下の例は説明目的でのみ GPT3-175B モデルとモックデータを使用しています。
|
GPU 数 |
スループット |
スケーラビリティスコア |
理論的スケーラビリティスコア |
|
64 |
10 |
||
|
128 |
18 |
log₂(18 / 10) |
log₂ 2 |
|
256 |
35 |
log₂(35 / 10) |
log₂ 4 |
|
512 |
69 |
log₂(69 / 10) |
log₂ 8 |
|
1024 |
137 |
log₂(137 / 10) |
log₂ 16 |
注:スケーラビリティスコアが理論的スケーラビリティスコアに近いほど、スケーラビリティは良好です。
詳細な評価結果
評価された GPU 数ごとに、各モデルのスループット、MFU、イテレーションレイテンシーのメトリックを表示します。Y 軸は GPU 数、X 軸はメトリック値を表します。