モデル圧縮は、量子化などの手法によりモデルサイズと計算量を削減し、予測性能への影響を最小限に抑えます。GPU メモリが限られている場合や、デプロイコストを削減したい場合に最適です。
仕組み
PAI モデルギャラリー は、重みのみの量子化手法によるモデル量子化をサポートしています。MinMax-8Bit または MinMax-4Bit ストラテジー を使用することで、モデルの浮動小数点重みパラメータを 8 ビットまたは 4 ビットの整数表現に量子化できます。これにより、モデルサイズと GPU メモリ使用量を削減しつつ、優れたパフォーマンスを維持します。
モデルの圧縮
-
モデルをトレーニングします。
モデルを圧縮する前に、トレーニングを完了する必要があります。詳細については、モデルデプロイとトレーニングをご参照ください。
-
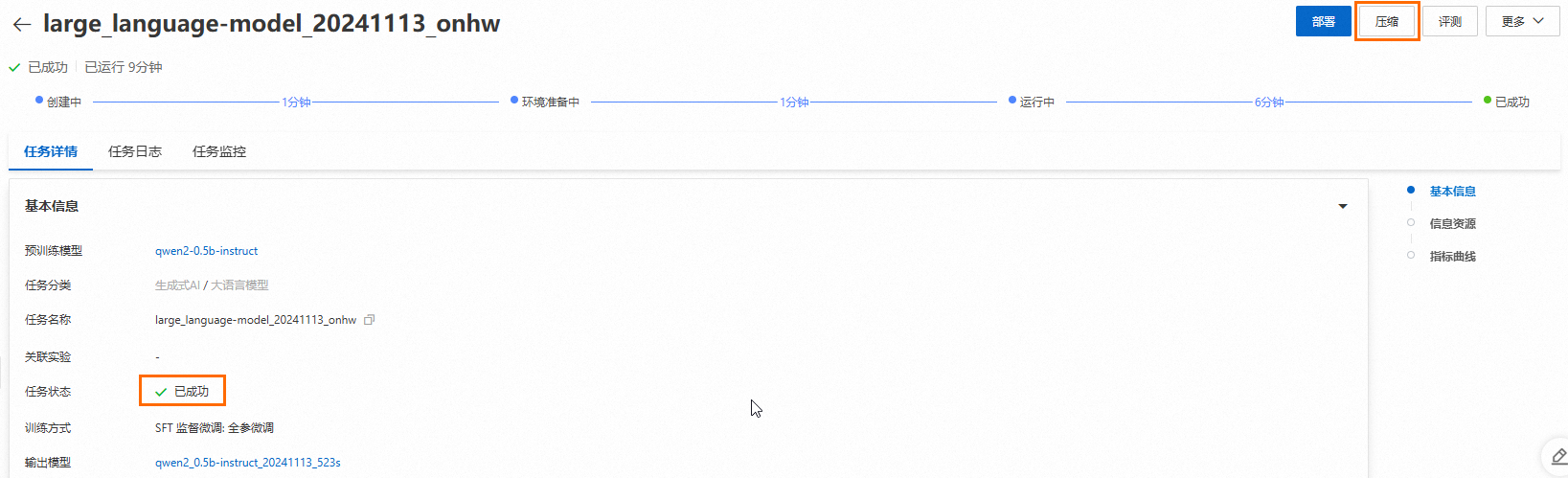
モデルトレーニングが完了したら、Task details ページの右上隅にある Compression をクリックします。
-
圧縮パラメータを設定します。
次の表に、主要なパラメータを示します。
パラメータ
説明
圧縮方法
モデル量子化 (重みのみの量子化) のみがサポートされています。これは、推論時の GPU メモリ使用量を削減するため、重みパラメータをより低いビット幅に変換します。
圧縮ストラテジー
-
MinMax-8Bit: Min-Max スケーリングを使用して、モデルの重みを 8 ビット整数に量子化します。
-
MinMax-4Bit: Min-Max スケーリングを使用して、モデルの重みを 4 ビット整数に量子化します。
その他のパラメータについては、モデルデプロイとトレーニングをご参照ください。
-
-
Compression をクリックします。
Task details ページにリダイレクトされ、そこで圧縮ジョブの基本情報、リアルタイムステータス、タスクログを表示できます。
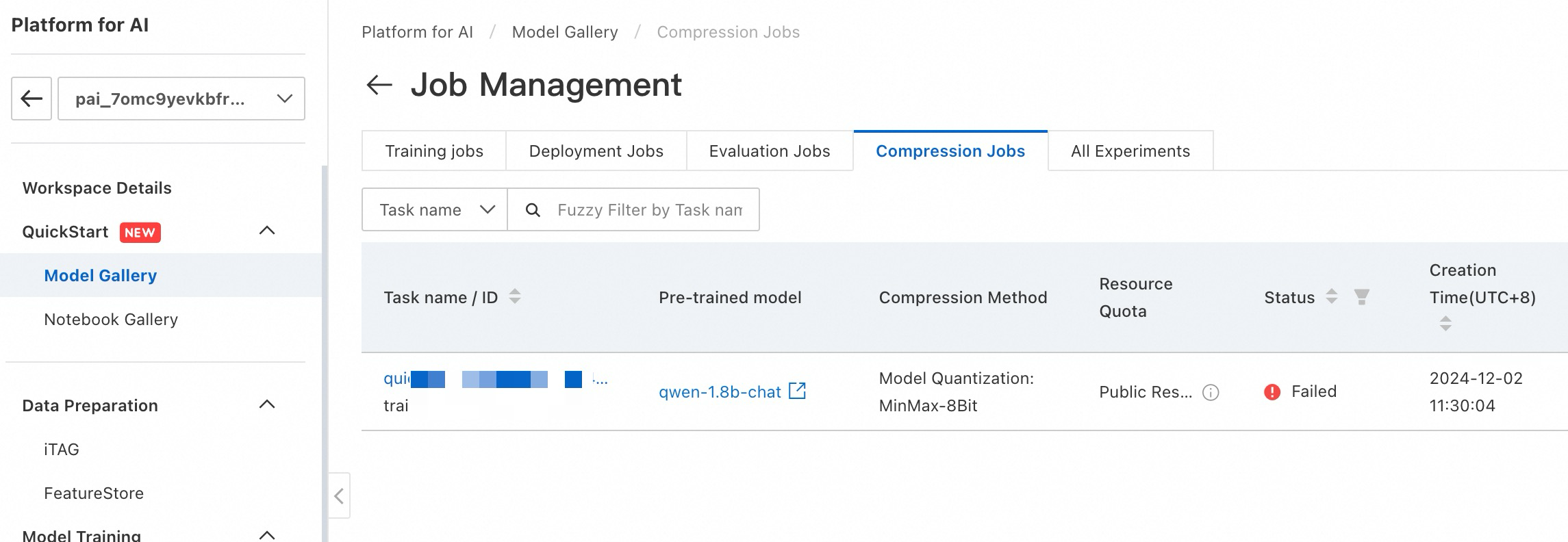
圧縮タスクの表示
圧縮ジョブを表示するには、PAI Model Gallery > Job Management > Compression Jobs に移動します。