EAS サービスがデプロイされると、デフォルトで共有ゲートウェイが提供されます。このゲートウェイを使用して、パブリックエンドポイントまたは VPC アドレス経由でデプロイされたモデル推論サービスを呼び出すことができます。
共有ゲートウェイは、開発環境およびテスト環境での使用を推奨します。本番環境では、専用ゲートウェイを使用してください。
呼び出しアドレスの選択
共有ゲートウェイがデプロイされると、デフォルトで 2 種類の呼び出しアドレスが提供されます。
呼び出しアドレス | 説明 | ユースケース |
パブリックエンドポイント | EAS 共有ゲートウェイは、リクエストをターゲットサービスに転送します。この方法は、パブリックインターネットにアクセスできるあらゆる環境に適しています。 |
|
VPC アドレス | アプリケーションと EAS サービスが同じリージョンにデプロイされているシナリオに適しています。 重要 パブリックインターネット経由の呼び出しと比較して、VPC 経由の呼び出しは、パブリックネットワークのオーバーヘッドを回避することでレイテンシーが低く、VPC 内のトラフィックは通常無料であるため、コスト効率が高くなります。 |
|
サービスの呼び出し
ステップ 1: エンドポイントとトークンの取得
サービスをデプロイすると、システムは自動的にエンドポイントと認証トークンを生成します。
コンソールはベースエンドポイントを提供します。完全なリクエスト URL を構築する際は、このベースエンドポイントに正しい API パスを追加する必要があります。 404 Not Found エラーの最も一般的な原因は、パスが正しくないことです。
Inference Service タブで、ターゲットサービスの名前をクリックして Overview ページに移動します。
Basic Information セクションで、View Endpoint Information をクリックします。
Invocation Method パネルで、エンドポイントとトークンをコピーします。
必要に応じて、[public endpoint] または [VPC address] を選択します。
以下の例では、エンドポイントのプレースホルダーとして <EAS_ENDPOINT> を、トークンのプレースホルダーとして <EAS_TOKEN> を使用します。

ステップ 2: リクエストの構築と送信
パブリックエンドポイントを使用する場合でも、VPC アドレスを使用する場合でも、リクエスト形式は同じです。標準的なリクエストには、以下の要素が含まれます。
要素 | 説明 |
メソッド | 最も一般的なメソッドは POST と GET です。 |
リクエストパス (URL) | フォーマット:<EAS_ENDPOINT> + API パス。例: |
Authorization (必須) |
|
Content-Type |
|
リクエスト本文 | デプロイされたモデルの API 仕様によってフォーマットが決まります。ゲートウェイ経由で送信する場合、リクエスト本文は 1 MB を超えることはできません。 |
呼び出し例
次の例は、vLLM でデプロイされた DeepSeek-R1-Distill-Qwen-7B モデルサービスを呼び出す方法を示しています。<EAS_ENDPOINT> が http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test であると仮定します。
リクエスト本文:
{
"model": "DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "hello!"
}
]
}コード例:
curl http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: *********5ZTM1ZDczg5OT**********" \
-X POST \
-d '{
"model": "DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "hello!"
}
]
}' import requests
# 実際のエンドポイントに置き換えてください。
url = 'http://16********.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/test/v1/chat/completions'
# Authorization ヘッダーの値は、実際のトークンに置き換えてください。
headers = {
"Content-Type": "application/json",
"Authorization": "*********5ZTM1ZDczg5OT**********",
}
# 特定のモデルで必要とされるデータ形式に基づいて、サービスリクエストを構築します。
data = {
"model": "DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "hello!"
}
]
}
# リクエストを送信します。
resp = requests.post(url, json=data, headers=headers)
print(resp)
print(resp.content)大規模言語モデル (LLM) サービスの呼び出しに関する詳細は、「LLM サービスの呼び出し」をご参照ください。
その他のデプロイシナリオ
モデルギャラリーからデプロイされたモデル:モデルの Overview ページには通常、完全な URL パスやリクエスト形式を含む API 呼び出しの例が記載されています。
cURL コマンド
共通パラメーター:
パラメーター
説明
例
-XHTTP メソッドを指定します。
-X POST-Hリクエストヘッダーを追加します。
-H "Content-Type: application/json"-dリクエスト本文を追加します。
-d '{"key": "value"}'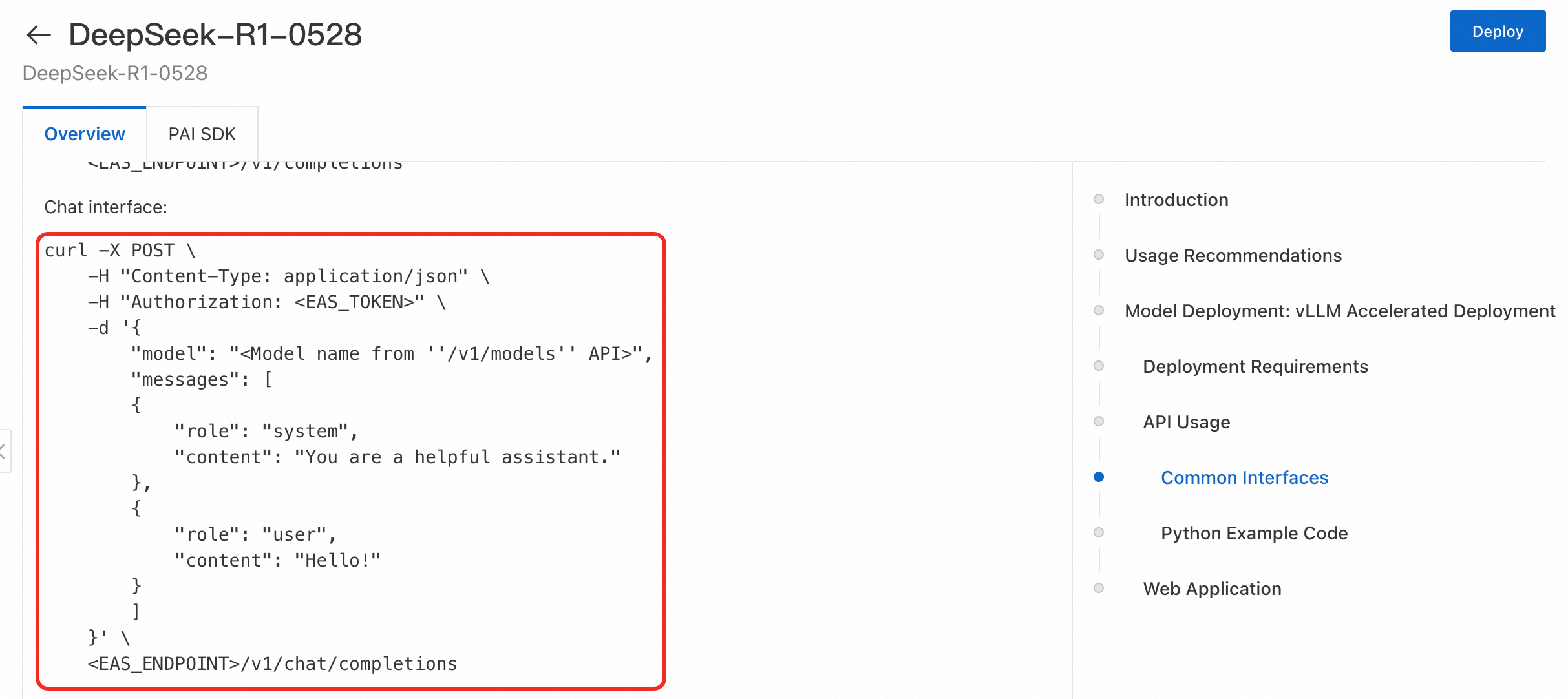
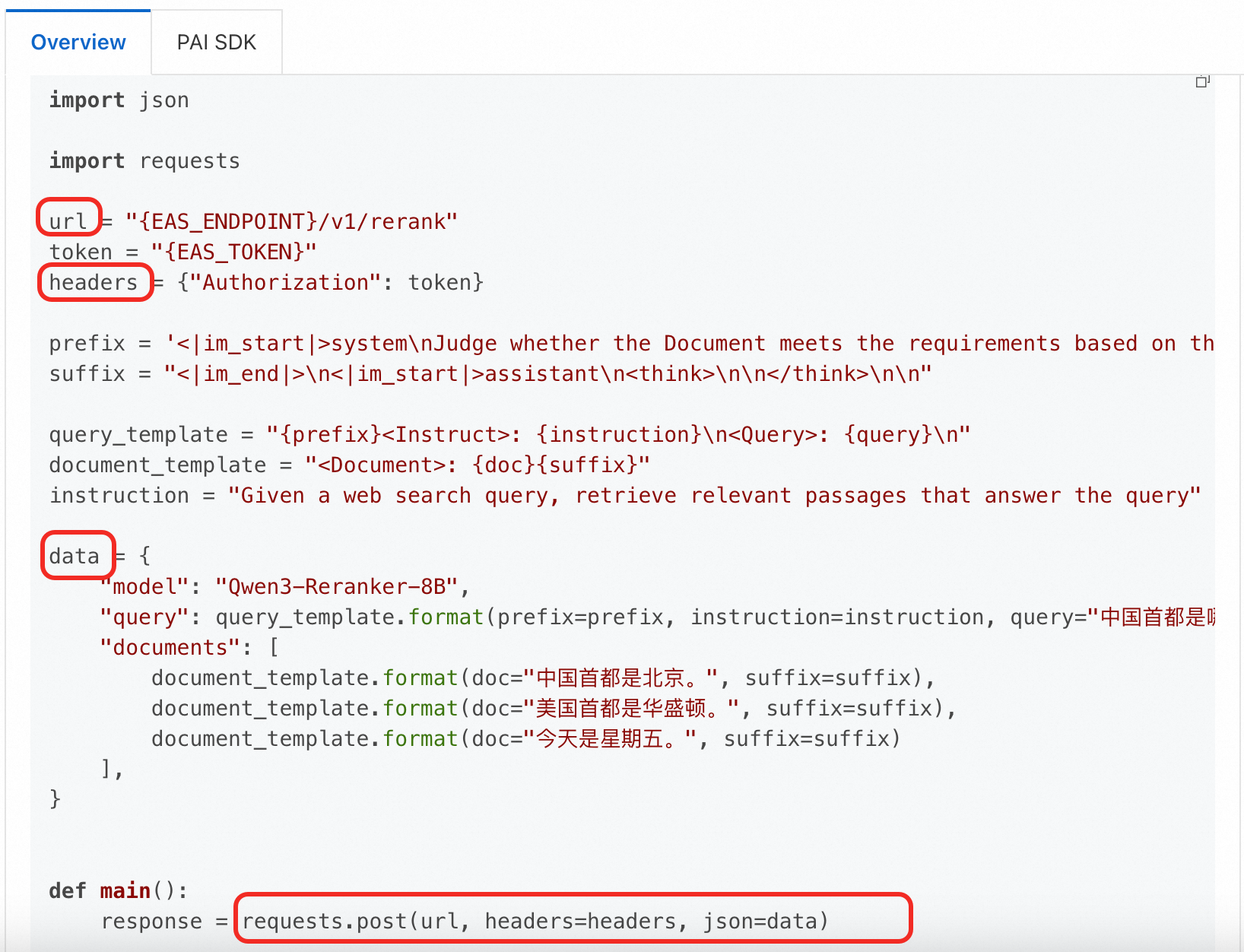
Python コード
次の例では、Qwen3-Reranker-8B モデルを使用して、Python コードでサービスを呼び出す方法を示します。URL とリクエスト本文が、前述の DeepSeek モデルの cURL の例とは異なることに注意してください。常にモデルの [Overview] ページの指示に従ってください。
シナリオベースのデプロイ:
汎用プロセッサ (TensorFlow、Caffe、PMML など) を使用してデプロイされたサービス:「汎用プロセッサに基づくサービスリクエストの構築」をご参照ください。
その他のカスタムサービス:リクエスト形式は、カスタムイメージまたはコードで定義されたデータ入力形式によって決まります。
独自にトレーニングしたモデル:呼び出し方法は、元のモデルと同じです。
よくある質問
サービス呼び出しに関する一般的な問題と解決策は、「サービス呼び出しに関するよくある質問」をご参照ください。