Elastic Algorithm Service (EAS) は、コンピューティングモニタリングとフォールトトレランス機能を提供します。この機能は、GPU コンピューティング能力やノード通信などのリソースの正常性を自動的にチェックし、診断効率を向上させ、大規模デプロイメントにおけるサービスの可用性と安定性を確保します。
適用範囲
コンピューティングモニタリングとフォールトトレランス機能は、Lingjun リソースにデプロイされたマルチノード分散推論サービスに適用されます。
基本概念
-
検出タイミング:
-
インスタンス起動前:サービスインスタンス (Pod) 内のアプリケーションが起動する前にチェックが実行されます。これにより、リソースの障害による起動失敗を防ぎ、ハードウェアやネットワークの問題を事前に特定できます。
-
インスタンスランタイム中:サービスの実行中に、チェックがバックグラウンドプロセスとして実行されます。
-
-
確認項目:
-
インスタンス起動前:コンピューティングパフォーマンスチェック、ノード通信チェック、およびコンピューティングと通信のクロスチェックをサポートします。
-
インスタンスランタイム中:C4D (GPU の正常性をチェック) のみがサポートされています。
-
確認項目の詳細については、「付録:確認項目」をご参照ください。
-
-
異常状態の処理:
-
インスタンス起動の失敗:問題が検出された場合、現在のインスタンスの起動は終了します。
-
アクションなし:問題が検出された場合、システムはイベントを記録するだけで、他のアクションは実行しません。
-
操作手順
コンピューティングモニタリングの有効化と設定
-
PAI コンソールにログインします。ページ上部でリージョンを選択します。次に、目的のワークスペースを選択し、Elastic Algorithm Service (EAS) をクリックします。
Deploy Service をクリックします。Custom Model Deployment セクションで、Custom Deployment をクリックします。
-
Features セクションの「安定性保証」カテゴリで、Compute monitoring & fault tolerance を有効にします。右側に表示されるパネルで、確認パラメーターを設定します。JSON ファイルを使用してパラメーターを設定する方法については、「付録:JSON ファイルパラメーター」をご参照ください。
説明「実行前」と「インスタンス実行中」の両方のチェックを追加できます。
-
実行前チェックの設定 (任意):
-
検出タイミング:Before running を選択します。
-
確認項目:必要に応じて、Run Compute Performance CheckやRun Node Communication Checkなどの確認項目を選択します。デフォルトでは、プラットフォームがGPU GEMM、[All-Reduce(シングルノード)]、および[All-Reduce(2ノード間)]のチェックを有効にします。
-
「確認項目」に記載されている推定所要時間を参照して、選択した確認項目に適切なタイムアウトを設定します。チェックは順次実行されます。デフォルトのタイムアウトは 5 分です。この時間内にチェックが完了しない場合、失敗と見なされます。
-
異常状態の処理:デフォルトのオプションは Instance startup failed です。ディザスタリカバリポリシーに基づいて Rebuild Instance を選択することもできます。
-
-
実行中チェックの設定 (任意):
-
検出タイミング: Instance running を選択します。
-
チェック項目: 現在、[C4D] のみがサポートされています。
-
異常状態の処理:現在、Ignore のみがサポートされています。
-
-
確認結果の表示
この機能を設定した後、2 つの方法で確認レポートを表示できます:
-
方法 1:インスタンスリストから
-
サービス詳細ページで、Overview タブに移動します。
-
「サービスインスタンス」セクションで、ターゲットインスタンスを見つけ、Actions 列の View results をクリックします。
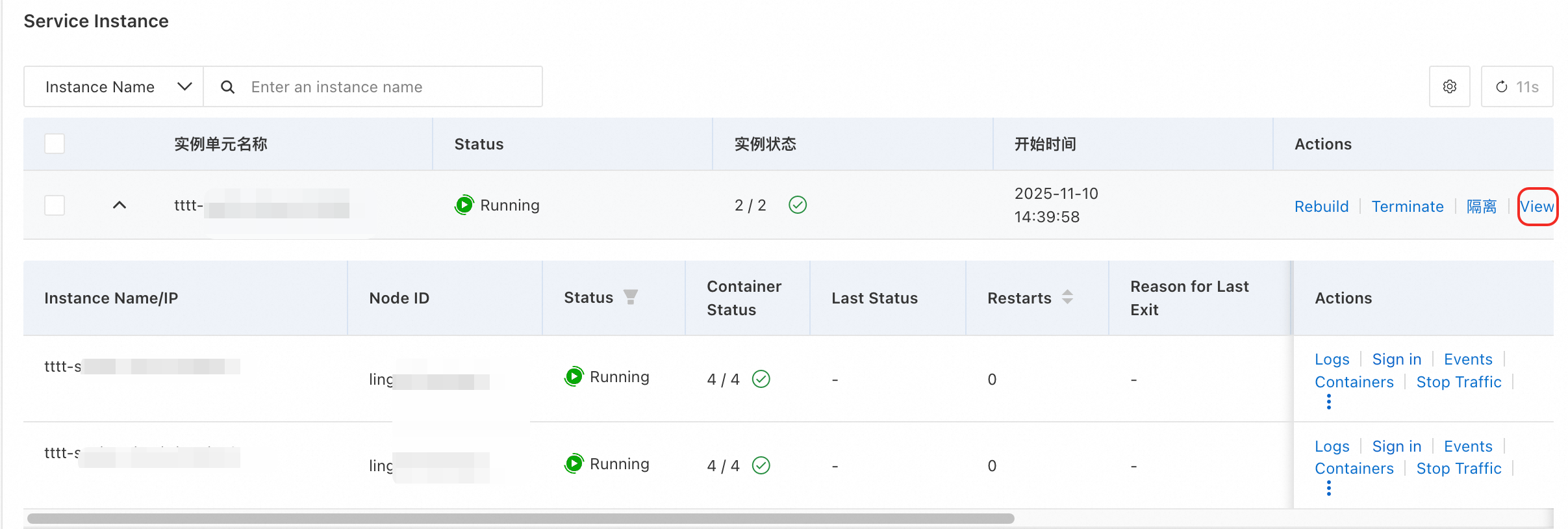
-
-
方法 2:デプロイイベントから
-
サービス詳細ページで、Deployment Events タブに移動します。
-
タイプが
SanityCheckSucceededまたはSanityCheckFailedのイベントを見つけ、Actions 列の View results をクリックします。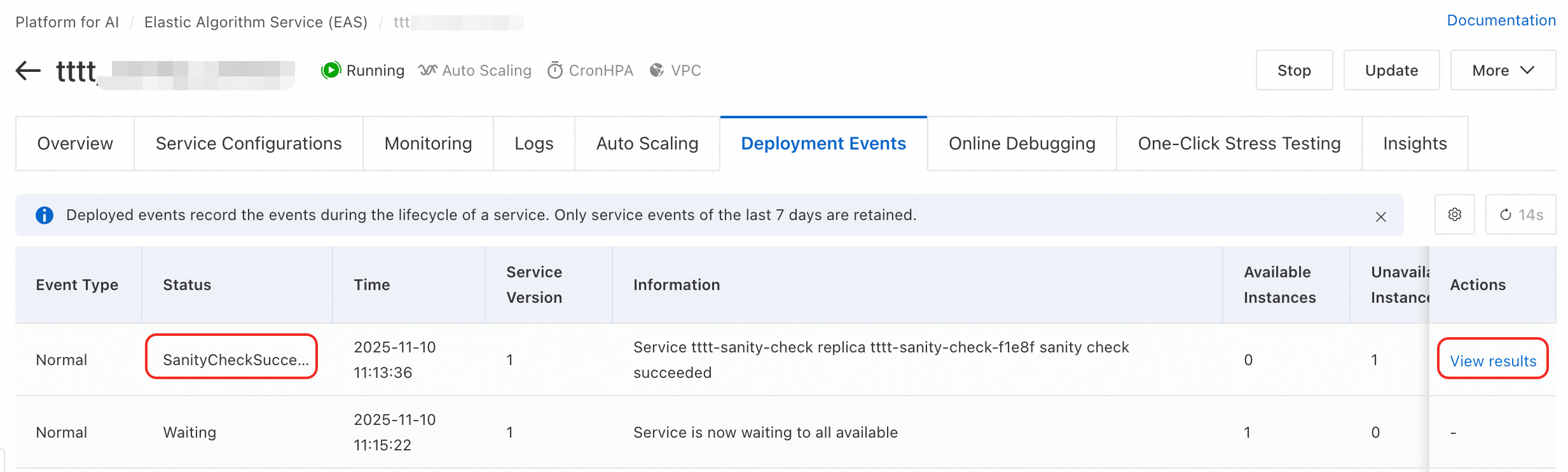
-
右側に Health check results ドロワーが表示されます。各確認項目の詳細なレポートを表示できます。
よくある質問
Q: All-Reduce チェックが失敗する一般的な原因は何ですか。
All-Reduce チェックの失敗は、通常、ネットワーク通信の問題を示します。これらの問題には、高いネットワーク遅延、深刻なパケット損失、またはノード間のリモートダイレクトメモリアクセス (RDMA) 設定の誤りが含まれます。レポートの詳細なデータを使用して、通信が遅いノードのトラブルシューティングに集中できます。
付録:確認項目
|
確認項目 |
説明 |
推定所要時間 |
|
|
インスタンス起動前 |
|||
|
コンピューティングパフォーマンスチェック |
GPU GEMM |
GPU GEMM のパフォーマンスを検出し、以下を特定します:
|
1 分 |
|
GPU カーネル起動 |
GPU カーネル起動レイテンシーを検出し、以下を特定します:
|
1 分 |
|
|
ノード通信チェック |
All-Reduce |
さまざまな通信パターンにおけるノード通信パフォーマンスを検出し、以下を特定します:
|
単一の集団通信チェック 5 分 |
|
All-to-All |
|||
|
All-Gather |
|||
|
Multi-All-Reduce |
|||
|
PyTorch-Gloo |
PyTorch Gloo を使用してノード通信をチェックし、障害のあるノードを特定します。 |
1 分 |
|
|
ネットワーク接続 |
ヘッドノードまたはテールノードのネットワーク接続をチェックし、接続に問題があるノードを特定します。 |
2 分 |
|
|
コンピューティングと通信のクロスチェック |
MatMul/All-Reduce Overlap |
通信カーネルと計算カーネルが重複する場合の単一ノードのパフォーマンスを検出し、以下を特定します:
|
1 分 |
|
インスタンスランタイム中 |
|||
|
C4D |
インスタンスの実行中に GPU の正常性をチェックします。 |
||
付録:JSON ファイルパラメーター
設定例
{
"aimaster": {
"runtime_check": {
"fail_action": "retain",
"micro_benchmarks": "c4d"
},
"sanity_check": {
"fail_action": "retain",
"micro_benchmarks": "gemm_flops,all_reduce_1,all_reduce_2,kernel_launch,all_reduce,all_to_all_2,all_gather_2,all_gather,multi_all_reduce_2,multi_all_reduce,pytorch_gloo_2,network_connectivity,comp_comm_overlap",
"timeout": 100
}
}
}パラメーター
|
パラメーター |
説明 |
||
|
aimaster |
runtime_check インスタンスランタイム中に実行されるチェックを指定します。 |
fail_action |
異常状態が検出されたときに実行するアクション。 |
|
micro_benchmarks |
確認項目。有効な値:C4D。 |
||
|
sanity_check インスタンス起動前に実行されるチェックを指定します。 |
fail_action |
異常状態が検出されたときに実行するアクション。 |
|
|
micro_benchmarks |
確認項目。複数の項目はカンマで区切ります。 |
||
|
timeout |
最大チェック時間 (分)。 |
||