概要
Alibaba Cloud OpenLake は、ビッグデータ、検索、人工知能 (AI) の統合シナリオに対応する次世代のオープンレイクハウスプラットフォームです。このプラットフォームは、Data Lake Formation (DLF) 上に統合メタデータカタログを構築します。構造化、半構造化、非構造化、ベクトルデータを組み合わせることで、単一のデータコピーを複数のエンジン、グローバル検索、エンドツーエンドのガバナンスで利用するエージェント型データアーキテクチャを構築します。
OpenLake は、Paimon、Iceberg、Lance などの一般的なオープンテーブルフォーマットをサポートしています。データインジェスト、特徴量エンジニアリング、ベクトル化から、検索拡張生成 (RAG)、モデルトレーニング、推論までの完全なワークフローを提供します。OpenLake は、マルチモーダルデータ向けに、高性能、低コスト、高可用性 (HA)、かつ管理が容易なインフラストラクチャを企業に提供します。
このプラットフォームは、インターネット、金融、小売、製造、教育、自動運転などの業界で、マルチモーダルデータを処理し、AI ネイティブアプリケーションを構築する必要がある企業に適しています。

利点
オープンスタンダードによるデータサイロの解消
Paimon、Iceberg、Lance などのオープンソースのテーブルフォーマットと完全な互換性があります。また、Parquet、ORC、Avro、CSV などのオープンファイル標準もサポートしています。
Spark、Flink、Trino、StarRocks、Hologres、MaxCompute などの一般的なコンピュートエンジンとシームレスに統合できます。これにより、データ移行やフォーマット変換のコストを回避できます。
DLF Omni Catalog を使用して、構造化、半構造化、非構造化、ベクトル、ストリーミングという 5 種類のデータに対応した統合カタログを作成します。これにより、一度データを取り込むだけで、どこでも利用できるようになります。
高性能なエンジン連携による効率的なコンピューティング
Spark、Flink、StarRocks、Hologres、MaxCompute などの複数のエンジンが、冗長なコピーなしで同じレイクデータにアクセスできます。
統合された DLF メタデータサービスにより、エンジン間で一貫した権限、スキーマ同期、トランザクション分離が保証されます。
バッチ処理、ストリームコンピューティング、インタラクティブクエリ、AI トレーニングが同じストレージを共有します。これにより、リソース使用率とエンドツーエンドの効率が大幅に向上します。
高同時実行性、低レイテンシーの混合ワークロードをサポートします。これにより、T+1 のバッチ処理と秒レベルのレイテンシーでのリアルタイム分析の両方が求められるシナリオの要件を満たします。
開発とガバナンスの統合による複雑性の軽減
DataWorks と統合された OpenLake Studio は、Notebook、SQL IDE、可視化スケジューリングによる統合開発体験を提供します。
メタデータ、データ権限、データリネージ、タスクオーケストレーション、品質モニタリングを一元管理することで、開発の初期段階からガバナンスを実現します。
大規模かつ高同時実行性のタスクスケジューリングをサポートし、エンタープライズグレードのサービスレベル契約 (SLA) と安定性を保証します。
データパイプライン全体がトレーサブルかつ監査可能であり、コンプライアンス要件を満たすためのロールバックをサポートします。
データ、検索、AI の統合によるデータ価値の解放
構造化テーブル、非構造化ファイル (画像、音声、動画、ドキュメントなど)、ベクトルデータを組み合わせて、統合されたマルチモーダルレイクハウスを構築します。
SQL クエリ、全文検索 (OpenSearch または Elasticsearch)、ベクトル類似性検索 (Milvus または PgVector) をネイティブにサポートします。
大規模言語モデル (LLM) の検索拡張生成 (RAG) やインテリジェントエージェントに、高品質で検索可能かつガバナンスの効いたデータパイプラインを提供します。
データインジェスト、特徴量エンジニアリング、ベクトル化から、検索拡張、モデル推論までのワークフロー全体を合理化します。これにより、AI アプリケーションの実装を加速します。
主な特徴
特徴 | 説明 | 関連ドキュメント |
統合メタデータとテーブル管理 | DLF を使用して、Paimon、Iceberg、Lance、Parquet などのフォーマットに対応した統合カタログをサポートします。 | |
ストレージコストの最適化 | OSS のインテリジェント階層化、圧縮、ライフサイクルポリシーを使用してストレージコストを削減します。 | |
データレイクとストリームのリアルタイム統合 | Flink、Streaming Storage Fluss、DLF により、数秒でのデータインジェストと数分でのデータの可視性を実現します。 | |
エンタープライズグレードの高性能エンジン | Serverless Spark、Flink、Hologres、MaxCompute などのクラウドネイティブエンジンを統合します。 | EMR Serverless Spark とは、Realtime Compute for Apache Flink とは、Hologres とは、MaxCompute とは |
ビッグデータと AI の協調開発 | OpenLake Studio は、Notebook、SQL、可視化スケジューリングを組み合わせます。 | |
エージェントと Copilot の統合 | OpenLake Agent / MCP プロトコルにより、マルチモーダルインテリジェントエージェントがレイクハウスに直接アクセスできます。 |
代表的なアーキテクチャソリューション
ソリューション 1:クラシックレイクハウスアーキテクチャ (Serverless Spark + StarRocks + DLF)
シナリオ:このソリューションは、主に T+1 のバッチ処理を対象としており、レポート、ビジネスインテリジェンス、ユーザーペルソナなど、コスト効率の高いフルマネージドのバッチ分析シナリオ向けに設計されています。
コンポーネント:EMR Serverless Spark (バッチ処理) + StarRocks (サブ秒クエリ) + DLF (統合メタデータ)。
代替ソリューション:AWS Redshift + Glue、Databricks (バッチ処理)、Hive + Presto。
利点:コストを 30% 以上削減し、クエリパフォーマンスを 3~5 倍向上させ、フルマネージドで運用できます。
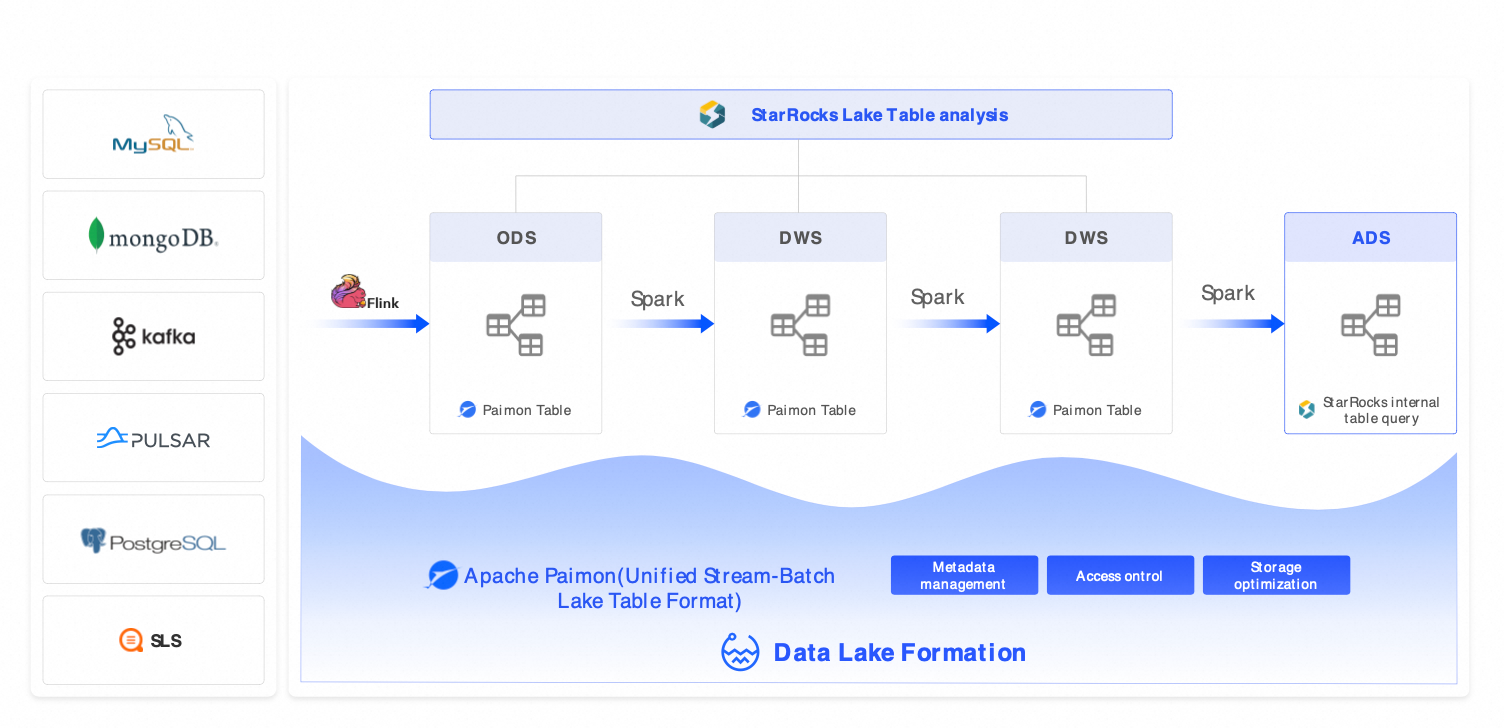
ソリューション 2:ストリーミングレイクハウスアーキテクチャ (Flink + Hologres + DLF)
シナリオ:このソリューションは、リアルタイムのリスク管理、広告パフォーマンスモニタリング、IoT デバイスモニタリングなど、秒から分レベルのレイテンシーでの準リアルタイム分析を対象としています。
コンポーネント:Flink (ストリーミング抽出、変換、ロード (ETL)) + Hologres (リアルタイムサービング) + DLF (エンジン間の連携)。
代替ソリューション:Kafka + ClickHouse + Hive、AWS Kinesis + Redshift。
利点:エンドツーエンドのデータ可視性を 10 分以内に実現し、クエリレイテンシーは 1 秒未満です。

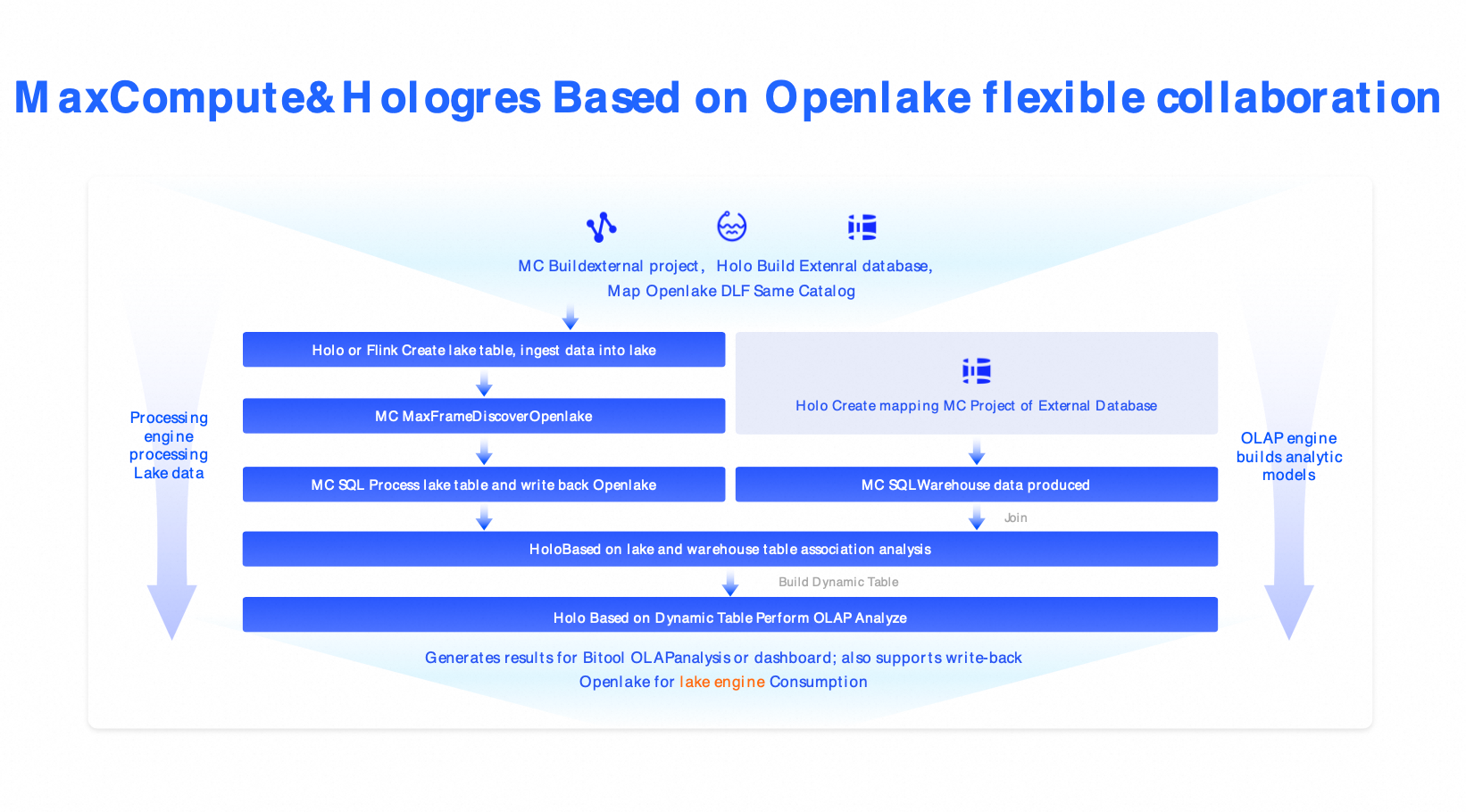
ソリューション 3:クラウドネイティブレイクハウスアーキテクチャ (MaxCompute + Hologres + DLF)
シナリオ:このソリューションは、金融や政府など、セキュリティ、コンプライアンス、大規模処理に関する厳しい要件を持つ業界を対象としています。
コンポーネント:MaxCompute (ペタバイト規模のバッチ処理) + Hologres (ミリ秒単位の書き込み) + DLF (ガバナンス)。
代替ソリューション:Snowflake、Azure Synapse、Databricks 商用版。
利点:エンタープライズグレードのセキュリティ、弾力的なスケーリング、RPO=0、RTO < 30 分。
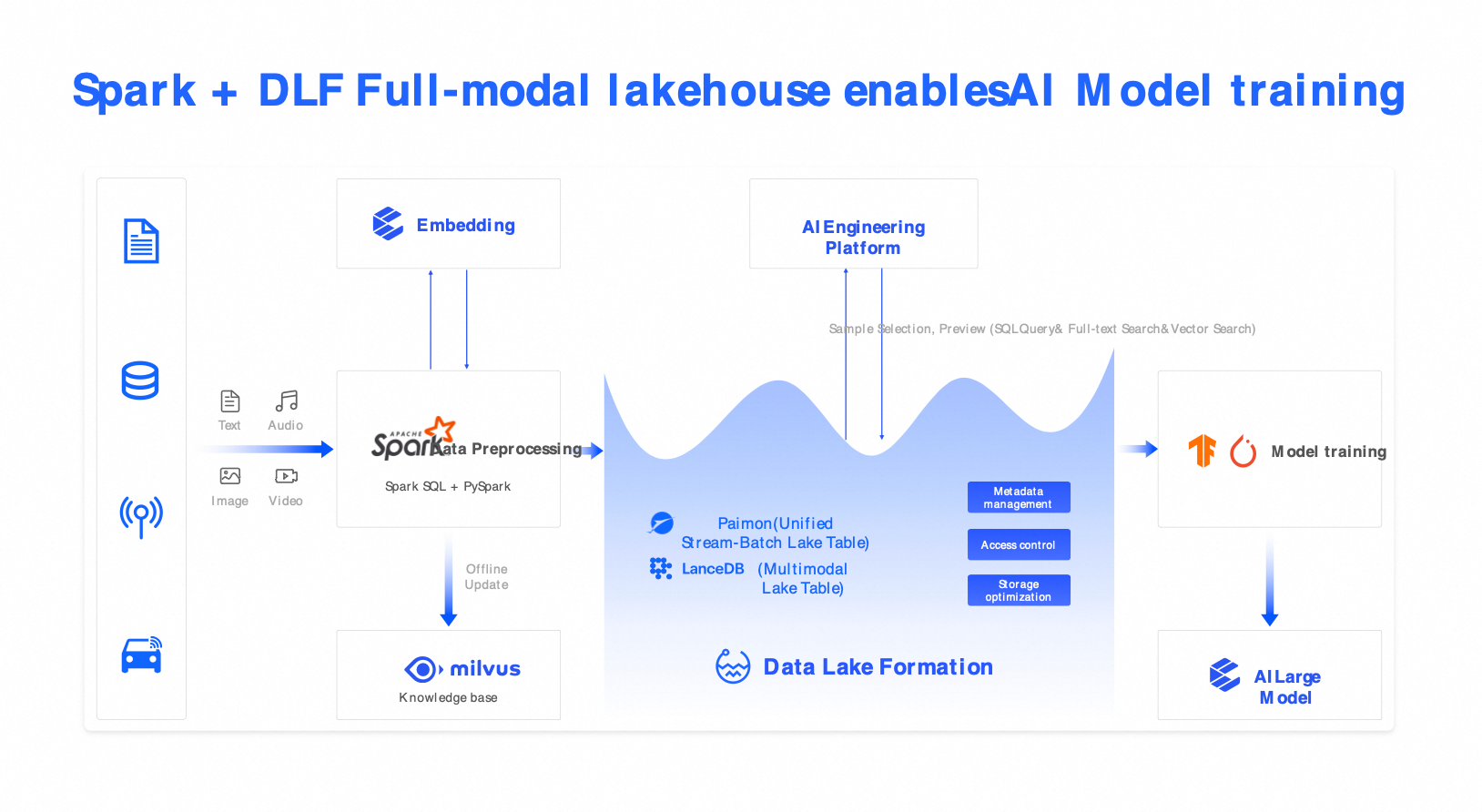
ソリューション 4:オムニモーダルベクトルレイク (Spark + Milvus + DLF)
シナリオ:このソリューションは、AI トレーニング、マルチモーダルセマンティック検索、RAG アプリケーション、インテリジェントカスタマーサービス、自動運転の知覚データ管理を対象としています。
コンポーネント:Spark (マルチモーダル前処理)、Milvus (ベクトル検索)、DLF (統合カタログ)。
機能:SQL とベクトルクエリの組み合わせにより、テキスト、画像、音声、動画にまたがるハイブリッド検索をサポートします。
利点:サンプル選択効率を 5 倍向上させ、LLM の高品質なファインチューニングをサポートします。
ユースケース:AI トレーニング、マルチモーダルセマンティック検索、RAG アプリケーション、インテリジェントカスタマーサービス、自動運転の知覚データ管理。