DataWorks ノートブックは、データ分析および開発のためのインタラクティブでモジュール化された環境です。Python、SQL、Markdown の各セルを組み合わせて使用し、MaxCompute、EMR、AnalyticDB などのコンピュートエンジンに接続することで、データ処理や探索的分析から可視化、モデル開発までを一貫して実行できます。
最初のノートブックを実行する
このセクションでは、ノートブックの作成、Python から SQL への変数の渡し方、および MaxCompute テーブルからのデータ照会手順について説明します。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
ワークスペースで新しい Data Studio が有効化されていること
ノートブックを本番環境で実行するために必要な、サーバーレスリソースグループが作成済みであること
ノートブックを開発環境で実行およびデバッグするために必要な、個人開発環境インスタンスが作成済みであること。まだ作成していない場合は、「個人開発環境インスタンスの作成」をご参照ください。
操作手順
ノートブックノードを作成する Data Studio で、ワークスペースディレクトリ の下にノートブックノードを作成します。名前として
hello_notebookのような名前を入力し、送信します。個人開発環境を選択する 画面上部のナビゲーションバーで 個人開発環境 をクリックし、ドロップダウンリストからご利用の個人開発環境インスタンスを選択します。
Python 変数を定義する Python セルを追加し、以下のコードを入力します。これにより、次のステップで SQL クエリで使用する
city変数が定義されます。# 後続の SQL クエリで使用する変数を定義 city = '北京' print(f"city 変数を定義しました:city = {city}")変数を参照する SQL セルを作成する Python セルの直後に SQL セルを追加します。セルの右下隅で SQL の種類を MaxCompute SQL に切り替え、以下の内容を入力します。
-- Python で定義した変数を使用したクエリ SELECT '${city}' AS city;${city}構文により、上記の Python セルで定義された値が自動的に取得されます。すべてのセルを実行して出力を確認する ノートブックツールバーの すべて実行 をクリックします。以下の 2 つの動作が行われます。
Python セルで
city 変数を定義しました:city = 北京と表示されます。SQL セルでクエリ結果がその下の表形式で表示されます。
Python と SQL の間でデータをやり取りするノートブックの作成および実行が完了しました。
基本概念
以下の概念を理解しておくことで、ノートブックを開発環境から本番環境へ移行する際に予期せぬ問題を回避できます。
開発環境と本番環境の違い
| 開発環境 | 本番環境 | |
|---|---|---|
| ランタイム | 個人開発環境インスタンス | リソースグループとイメージは、[スケジューリング] |
| 用途 | インタラクティブなデバッグ;Python ライブラリを自由にインストール可能 | Data Studio からの定期スケジュール実行および手動トリガーワークフロー |
| ネットワーク | VPC(仮想プライベートクラウド)にアタッチされていない個人開発環境インスタンスには、帯域幅が制限されたランダムなパブリック IP アドレスが割り当てられます | リソースグループの VPC によって決定されるネットワーク構成。NAT Gateway が設定されていない限り、デフォルトでパブリックネットワークアクセスは許可されません |
| 一貫性を保つ方法 | 開発環境で pip install を使用してパッケージをインストールした場合、その環境から DataWorks イメージを作成し、スケジューリング | スケジューリング でカスタムイメージを選択し、実行時に同じ依存関係が利用可能であることを保証します |
環境間のネットワークの一貫性を確保するには、個人開発環境インスタンスに同じサーバーレスリソースグループをアタッチしてください。
計算リソースとカーネル
計算リソース:ノートブックに接続されるバックエンドのコンピュートエンジン(例:MaxCompute、EMR Serverless Spark)。SQL セルを実行するには、必ず計算リソースにバインドする必要があります。
Python カーネル:Python コードを実行するバックエンド環境 — 通常はご利用の個人開発環境インスタンスです。Python セル内で
%odpsなどのマジックコマンドを使用すると、計算リソースへの接続、タスクの送信、データ操作などが可能です。
フォルダーの種類
ノートブックを作成する場所によって、共同作業モデル、権限、デプロイメントパスが決まります。
| フォルダーの種類 | 推奨用途 | 共同作業およびデプロイメント |
|---|---|---|
| ワークスペースディレクトリ | チームでの共同作業および定期タスク | ワークスペース全体で共有される;定期実行するには、本番環境へのデプロイメントが必要です |
| 個人ディレクトリ | 個人での開発およびデバッグ | ご自身のみが閲覧可能;ノードをスケジュールするには、まずワークスペースディレクトリへコミットし、その後デプロイメントを行ってください |
ノートブックの開発およびデバッグ
Data Studio ではコードが自動保存されません。開発中に頻繁に保存するか、または 設定項目 > ファイル:自動保存 から自動保存を有効化してください。
ノートブックが応答しなくなった場合は、ツールバーの 再起動 をクリックしてカーネルを再起動します。
セルの管理
| 操作 | 方法 |
|---|---|
| セルを追加する | セルの上端または下端にマウスを合わせ、+ SQL などのボタンをクリックするか、ツールバーのボタンを使用します |
| セルの種類を切り替える | セルの右下隅にある種類ラベル(例:Python)をクリックし、新しい種類を選択します。既存のコードは保持されますが、新しい種類に合わせて手動で更新する必要があります |
| セルの並び順を変更する | セルの左側にある青い縦線にマウスを合わせ、新しい位置までドラッグします |
セルの実行
実行する対象に応じて、適切な実行オプションを選択してください。
単一セルを実行する — 対象のセルの 実行 をクリックします。アクティブな開発中に特定のセルを反復的に編集・実行する場合に使用します。
すべてのセルを実行する — ノートブックツールバーの すべて実行 をクリックします。ノートブックを共有またはスケジュールする前に、すべてのセルがエンドツーエンドで正しく実行されることを確認するために使用します。
セル間でのパラメーターの受け渡し
Python から SQL への受け渡し
Python セルで定義した変数は、後続の SQL セルで ${variable_name} 構文を使用して利用できます。
例:
# Python セル
table_name = "dwd_user_info_d"
limit_num = 10-- SQL セル
SELECT * FROM ${table_name} LIMIT ${limit_num};SQL から Python への受け渡し
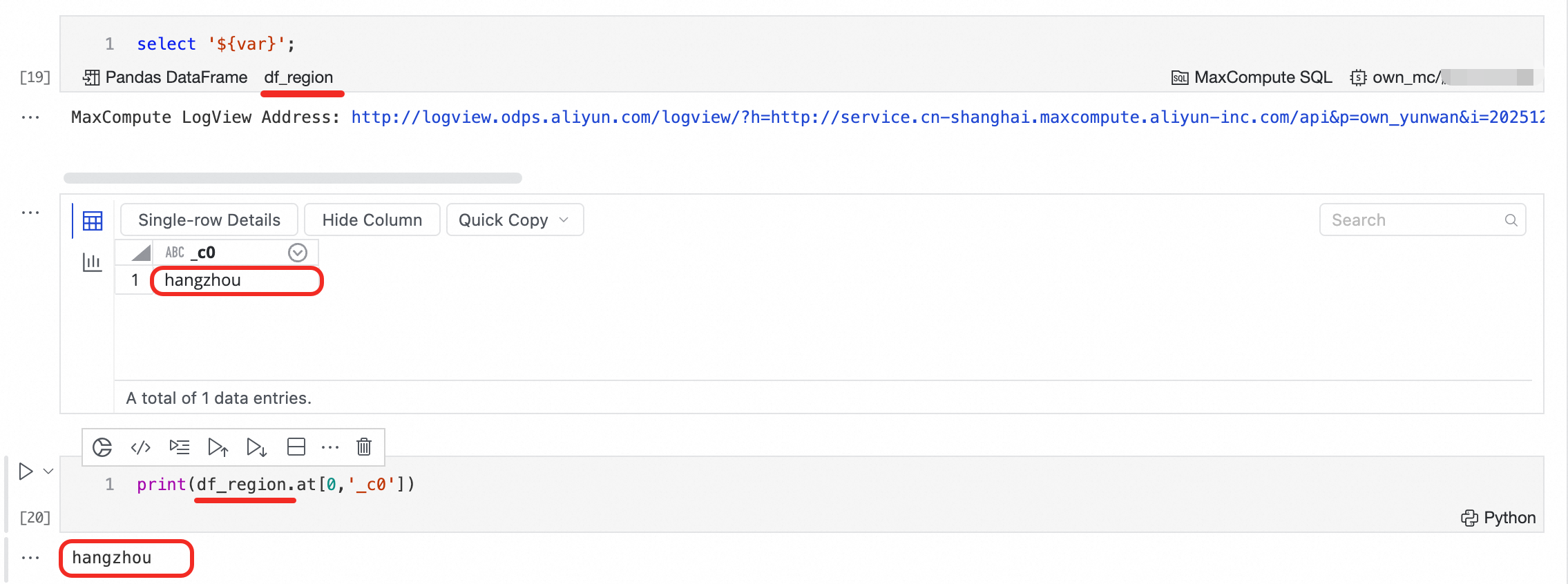
SQL セルで SELECT クエリを実行すると、その結果が自動的に DataFrame 変数として保存されます。以降の任意の Python セルでこの変数にアクセスできます。
変数名:デフォルトでは
df_で始まります。SQL セルの左下隅に表示される名前をクリックすると、変数名を変更できます。変数の型:使用する SQL エンジンによって異なります。SQL セルの左下隅に表示される DataFrame ラベルをクリックすると、サポートされている複数の型の間で切り替えることができます。
| SQL エンジン | サポートされる型 |
|---|---|
| MaxCompute SQL | Pandas DataFrame、MaxCompute MaxFrame |
| AnalyticDB for Spark SQL | Pandas DataFrame、PySpark MaxFrame |
| その他の SQL 種別 | Pandas DataFrame |
セルに複数の SQL ステートメントが含まれる場合、最後のステートメントの結果のみが DataFrame 変数に保存されます。
例:
DataWorks Copilot の使用
DataWorks Copilot は、コードの生成および説明を支援する組み込み AI プログラミングアシスタントです。起動するには、以下のいずれかの方法を使用します。
選択中のセルの左上隅にある Copilot
 アイコンをクリックします。
アイコンをクリックします。SQL セル内を右クリックし、Copilot を選択します。
Cmd+I(Mac)またはCtrl+I(Windows)を押します。
ノートブックのスケジュール設定およびデプロイメント
ノートブックを定期スケジュールで実行するには、スケジュール設定を構成し、本番環境へデプロイメントする必要があります。
1. パラメーター化スケジュールの設定
パラメーター化スケジュールにより、ノートブックは実行ごとに異なる値を受け取ることができます。コードを変更せずに、異なる日次パーティションのデータを処理する場合などに便利です。
使用するタイミング:ノートブックが実行ごとに異なるデータスライス(例:毎日昨日のパーティションを読み込む)を処理する必要がある場合に、パラメーター化スケジュールを設定します。
パラメーター定義を含む Python セルの右上隅にある ... をクリックし、セルをパラメーターとしてマーク を選択します。
parametersタグが表示され、これがパラメーターの入力ポイントとしてマークされます。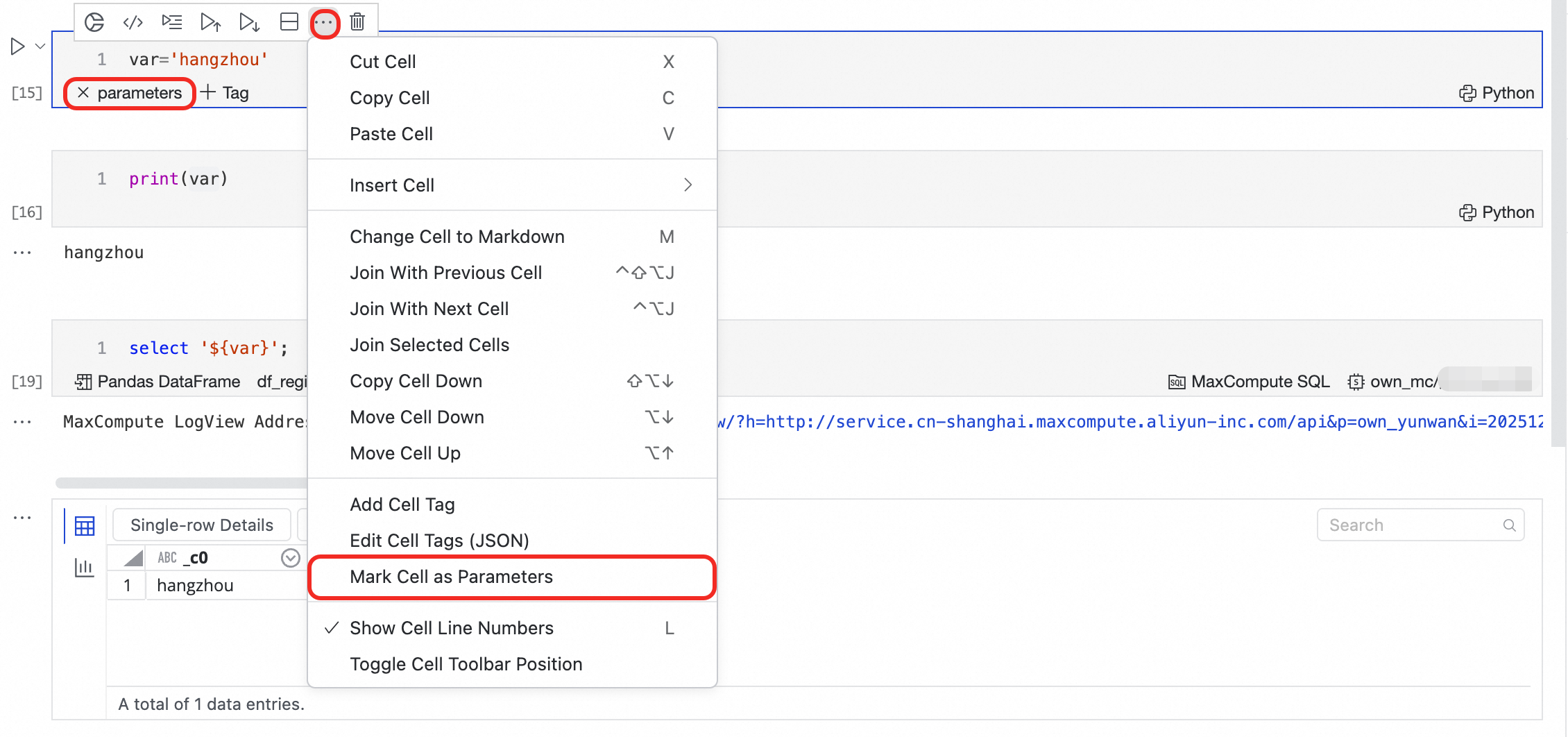
右ペインで スケジューリング をクリックし、スケジューリングパラメーター を展開します。コード内で定義した変数(例:
var)に値を割り当てます。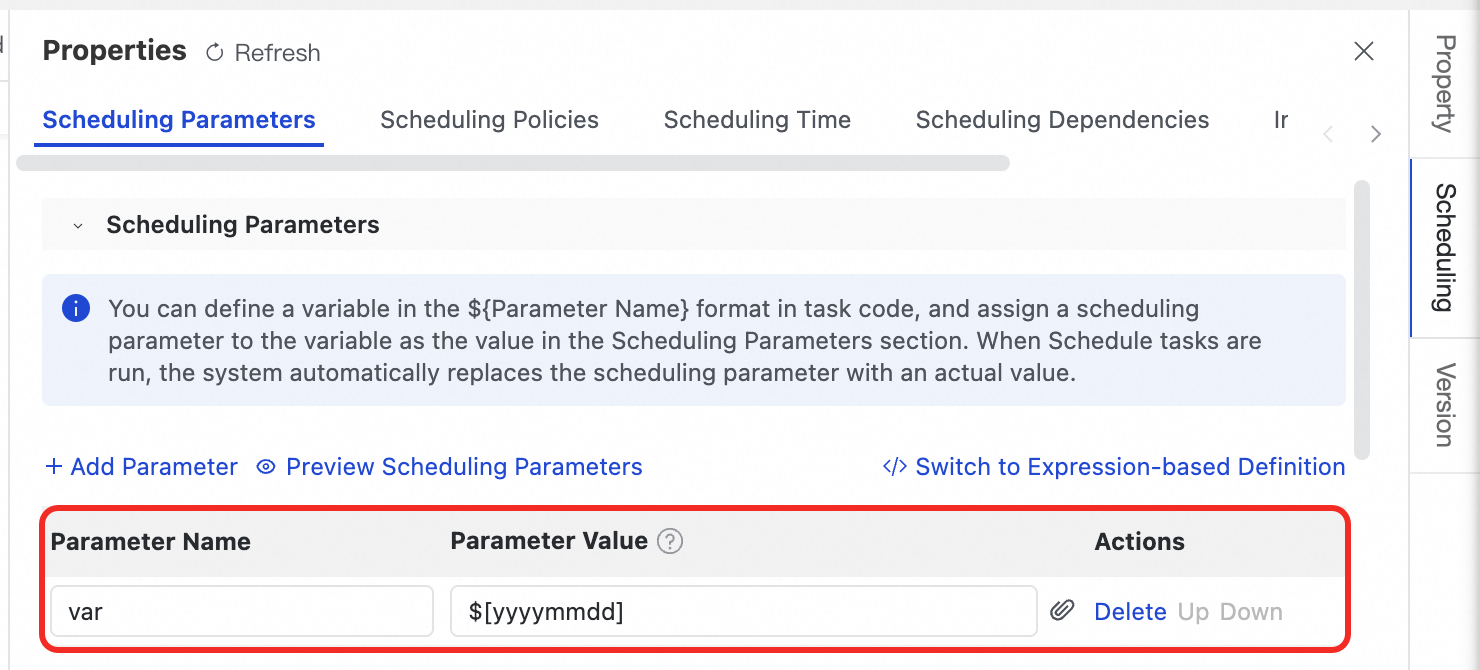
実行時には、スケジューリングシステムがコード内の変数を設定された値に置き換えます。
2. 実行環境の構成
イメージの選択:スケジューリング で、ノートブックに必要なすべての Python 依存関係を含むイメージを選択します。個人開発環境インスタンスで
pip installを使用してパッケージをインストールした場合、その環境から DataWorks イメージを作成し、ここで選択します。リソースグループの選択:タスク実行に使用するリソースグループを選択します。サーバーレスリソースグループの場合、起動失敗を回避するため、最大 16 CU までに設定してください。単一タスクでは最大 64 CU をサポートします。
RAM ロールの関連付け(任意):詳細な権限制御を適用するには、ノードに関連付けられた Resource Access Management (RAM) ロールを設定します。ノードはそのロールの ID で実行されます。詳細については、「ノードへの関連ロールの設定」をご参照ください。
3. ノードのデプロイメント
ワークスペースディレクトリ内にあるノードのみがデプロイメントおよび定期スケジュール実行可能です。
ワークスペースディレクトリ内のノートブック:ツールバーの デプロイ をクリックします。
個人ディレクトリ内のノートブック:保存 をクリックし、次に ワークスペースディレクトリへコミット をクリックしてから、デプロイメントを行います。
デプロイメント後は、オペレーションセンター の 自動トリガーされたノード ページで、ノートブックタスクをモニターおよび管理できます。
よくある質問
開発中はパブリックネットワークにアクセスできましたが、スケジュール実行時に失敗するのはなぜですか?
環境ごとのネットワークポリシーが異なります。開発中は、VPC にアタッチされていない個人開発環境インスタンスに対して、デフォルトで帯域幅が制限されたパブリックネットワークアクセスが許可されます(パッケージのインストールや外部 API の呼び出しには十分です)。一方、本番環境では、リソースグループの VPC 内でタスクが実行されるため、NAT Gateway が設定されていない限り、パブリックネットワークアクセスは許可されません。これを解決するには、個人開発環境インスタンスとサーバーレスリソースグループを同一の VPC 内に設定してください。
開発中は正常に動作していたサードパーティ製パッケージが、スケジュール実行時に見つからないのはなぜですか?
本番環境では、スケジューリング で選択したイメージが使用され、ローカルの開発環境インスタンスは使用されません。すべての Python 依存関係をカスタムイメージにパッケージ化し、スケジューリング でそのイメージを指定してください。「個人開発環境から DataWorks イメージを作成する」をご参照ください。
Python カーネルのバージョンを変更するにはどうすればよいですか?
個人開発環境のターミナル ![]() で、必要な Python バージョンをインストールします。その後、ノートブックツールバーの右側にある
で、必要な Python バージョンをインストールします。その後、ノートブックツールバーの右側にある ![]() をクリックして、そのカーネルバージョンに切り替えます。複数の追加 Python カーネルをインストールしないでください。新しいバージョンには、SQL セルで必要な依存関係が不足しており、機能停止を引き起こす可能性があります。
をクリックして、そのカーネルバージョンに切り替えます。複数の追加 Python カーネルをインストールしないでください。新しいバージョンには、SQL セルで必要な依存関係が不足しており、機能停止を引き起こす可能性があります。