この Topic では、Flink を使用して Data Lake Formation (DLF) で Paimon カタログを作成し、MySQL Change Data Capture (CDC) データを読み取り、そのデータを DLF に書き込む方法について説明します。その後、MaxCompute 外部プロジェクトを使用してデータレイクで統合クエリと分析を実行し、結果を DLF に書き戻すことができます。この Topic は、DLF の旧バージョンとは異なる、DLF の新バージョンに適用されます。DLF の新バージョンの詳細については、「Data Lake Formation」をご参照ください。
前提条件
OSS サービスが有効化されていること。
DLF サービスが有効化されていること。
Flink サービスが有効化されていること。
MaxCompute プロジェクトが作成されており、プロジェクトレベルのメタデータに対するスキーマスイッチが有効化されていること。
ApsaraDB RDS for MySQL インスタンスが作成されていること。
操作手順
ステップ 1:ソースデータの準備
すでに MySQL のテストデータがある場合は、このステップをスキップできます。
このステップでは、業務システムからのリアルタイムデータ更新をシミュレートします。データは Flink を使用して Paimon フォーマットでデータレイクに書き込まれます。
左側のナビゲーションウィンドウで、[インスタンス] をクリックします。
インスタンスリストページで、ターゲットインスタンスの [インスタンス ID/名前] をクリックしてインスタンス詳細ページを開きます。
左側のナビゲーションウィンドウで、[データベース] をクリックします。
[データベースの作成] をクリックします。次のパラメーターを設定します。
パラメーター
必須
説明
例
データベース名
必須
名前の長さは 2~64 文字である必要があります。
先頭は英字、末尾は英字または数字である必要があります。
小文字の英字、数字、アンダースコア (_)、ハイフン (-) を含めることができます。
データベース名はインスタンス内で一意である必要があります。
データベース名にハイフン (
-) が含まれている場合、作成されたデータベースフォルダの名前のハイフン (-) は@002dに置き換えられます。
dlf25_paimonサポートされる文字セット
必須
必要に応じて文字セットを選択します。
utf8権限付与
任意
このデータベースにアクセスする必要があるアカウントを選択します。このパラメーターを空のままにして、データベース作成後にアカウントをアタッチすることもできます。
ここには標準アカウントのみが表示されます。権限を持つアカウントはすべてのデータベースに対するすべての権限を持っており、権限付与は不要です。
Default説明
任意
将来の管理のためにデータベースに関する備考を入力します。備考は最大 256 文字です。
Create a test database for the external project DLF 2.5.[データベースにログオン] をクリックします。左側のナビゲーションウィンドウで、[データベースインスタンス] を選択します。作成したデータベースをダブルクリックします。右側に表示される [SQL コンソール] ページで、次のステートメントを実行してテストテーブルを作成し、テストデータを挿入します。
インスタンスを展開した後に目的のデータベースが見つからない場合、原因は次のいずれかである可能性があります:
ログインアカウントにターゲットデータベースへのアクセス権限がありません:RDS インスタンスの [アカウント] ページで、アカウントの権限を変更するか、ログインデータベースアカウントを変更することができます。
メタデータが同期されていない:インスタンスの上にマウスポインターを合わせます。インスタンス名の横にある
 アイコンをクリックして、データベースリストを更新します。
アイコンをクリックして、データベースリストを更新します。
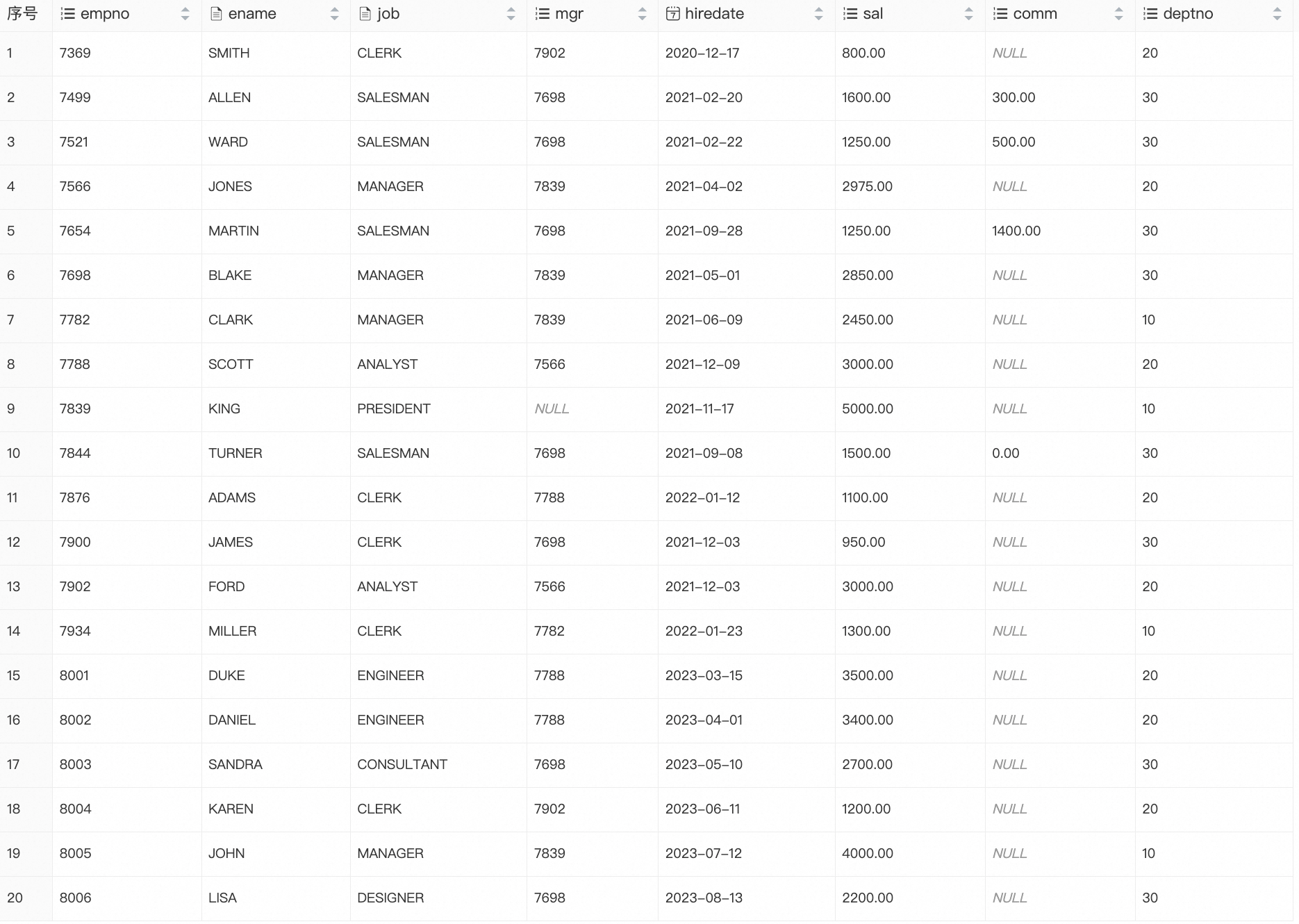
CREATE TABLE emp ( empno INT PRIMARY KEY, ename VARCHAR(20), job VARCHAR(20), mgr INT, hiredate DATE, sal DECIMAL(10,2), comm DECIMAL(10,2), deptno INT ); INSERT INTO emp VALUES (7369,'SMITH','CLERK',7902,'2020-12-17', 800.00,NULL,20), (7499,'ALLEN','SALESMAN',7698,'2021-02-20',1600.00,300.00,30), (7521,'WARD','SALESMAN',7698,'2021-02-22',1250.00,500.00,30), (7566,'JONES','MANAGER',7839,'2021-04-02',2975.00,NULL,20), (7654,'MARTIN','SALESMAN',7698,'2021-09-28',1250.00,1400.00,30), (7698,'BLAKE','MANAGER',7839,'2021-05-01',2850.00,NULL,30), (7782,'CLARK','MANAGER',7839,'2021-06-09',2450.00,NULL,10), (7788,'SCOTT','ANALYST',7566,'2021-12-09',3000.00,NULL,20), (7839,'KING','PRESIDENT',NULL,'2021-11-17',5000.00,NULL,10), (7844,'TURNER','SALESMAN',7698,'2021-09-08',1500.00,0.00,30), (7876,'ADAMS','CLERK',7788,'2022-01-12',1100.00,NULL,20), (7900,'JAMES','CLERK',7698,'2021-12-03', 950.00,NULL,30), (7902,'FORD','ANALYST',7566,'2021-12-03',3000.00,NULL,20), (7934,'MILLER','CLERK',7782,'2022-01-23',1300.00,NULL,10), (8001,'DUKE','ENGINEER',7788,'2023-03-15',3500.00,NULL,20), (8002,'DANIEL','ENGINEER',7788,'2023-04-01',3400.00,NULL,20), (8003,'SANDRA','CONSULTANT',7698,'2023-05-10',2700.00,NULL,30), (8004,'KAREN','CLERK',7902,'2023-06-11',1200.00,NULL,20), (8005,'JOHN','MANAGER',7839,'2023-07-12',4000.00,NULL,10), (8006,'LISA','DESIGNER',7698,'2023-08-13',2200.00,NULL,30);テストテーブルのデータをクエリします。
SELECT * FROM emp;次の結果が返されます:
ステップ 2:DLF メタデータベースの準備
Data Lake Formation (DLF) コンソールにログインし、左上隅でリージョンを選択します。
左側のナビゲーションウィンドウで、Catalog List を選択します。
「カタログ」ページで、[カタログの作成] をクリックします。
[Data Lake Formation (DLF)] ページで、次のパラメーターを入力し、[カタログの作成] をクリックします:
パラメーター
必須
説明
カタログ名
必須
カスタムのカタログ名。名前は英字で始まり、長さは 1~256 文字である必要があります。英字、数字、アンダースコア (_) を含めることができます。例:
db_dlf25_oss。説明
任意
カスタムの説明。
ストレージタイプ
必須
標準。
ストレージ冗長タイプ
必須
ローカル冗長ストレージ:データは単一ゾーンに保存されます。データが保存されているゾーンが利用できなくなると、データにアクセスできなくなります。ゾーン冗長ストレージの使用を推奨します。
ゾーン冗長ストレージ:同一リージョン内のマルチゾーン冗長メカニズムです。単一ゾーンが利用できなくなっても、データは利用可能なままです。カタログ作成後、ストレージ冗長タイプをゾーン冗長からローカル冗長に変更することはできません。ゾーン冗長ストレージはローカル冗長ストレージよりも高いデータ可用性を提供しますが、コストが高くなります。高い可用性が必要なデータにはゾーン冗長ストレージを推奨します。
ステップ 3:Flink を使用した Paimon および MySQL カタログの作成
Paimon カタログの作成
Flink コンソールにログインし、左上隅でリージョンを選択します。
対象のワークスペース名をクリックします。左側のナビゲーションウィンドウで、[カタログ] を選択します。
[カタログリスト] ページで、右側の [カタログの作成] をクリックします。[カタログの作成] ダイアログボックスで、Apache Paimon を選択し、[次へ] をクリックして、次のパラメーターを設定します。
パラメーター
必須
説明
metastore
必須
メタストアのタイプ。この例では、
dlfを選択します。catalog name
必須
関連付けるバージョンの DLF カタログを選択します。DLF V2.5 を選択します。この例では、DLF で作成された
db_dlf25_ossです。
MySQL カタログの作成
Flink コンソールにログインし、左上隅でリージョンを選択します。
ホワイトリストに IP アドレスを追加します。
対象のワークスペースの [アクション] 列で、[詳細] をクリックします。
[ワークスペース詳細] パネルで、vSwitch の [CIDR ブロック] をコピーします。
左側のナビゲーションウィンドウで、[インスタンス] をクリックします。
「インスタンス一覧」ページで、対象のインスタンスの [インスタンス ID/名前] をクリックして、「インスタンス詳細」ページを開きます。
左側のナビゲーションウィンドウで、[ホワイトリストとセキュリティグループ] をクリックします。
[ホワイトリスト設定] タブで、[変更] をクリックします。
[ホワイトリストの編集] ダイアログボックスで、コピーしたネットワークセグメントを [IP アドレス] フィールドに追加し、[OK] をクリックします。
Flink コンソールにログインし、左上隅でリージョンを選択します。
目的のワークスペースの名前をクリックします。左側のナビゲーションウィンドウで、[カタログ] を選択します。
右側の [カタログリスト] で、[カタログを作成] をクリックします。[カタログを作成] ダイアログボックスで MySQL を選択し、[次へ] をクリックして、次のパラメーターを設定します:
パラメーター
必須
説明
catalog name
必須
MySQL カタログのカスタム名。例:
mysql-catalog-dlf25。hostname
必須
MySQL データベースの IP アドレスまたはホスト名。
RDS MySQL コンソールにログインできます。 データベースインスタンスの詳細ページで、[データベース接続] をクリックすると、データベースの [内部エンドポイント]、[パブリックエンドポイント]、および [内部ポート] を表示できます。
VPC をまたいで、またはインターネット経由でアクセスする場合は、ネットワーク接続を確立する必要があります。詳細については、「ネットワーク接続」をご参照ください。
port
デフォルト
サーバーへの接続に使用されるポート。デフォルト値は 3306 です。
default database
必須
デフォルトのデータベース名。例:
dlf25_paimon。username
必須
MySQL データベースサーバーへの接続に使用されるユーザー名。RDS for MySQL コンソールにログインできます。インスタンス詳細ページで、[アカウント管理] をクリックしてユーザー名を表示します。
password
必須
MySQL データベースサーバーへの接続に使用されるパスワード。RDS for MySQL コンソールにログインできます。インスタンス詳細ページで、[アカウント管理] をクリックしてパスワードを表示します。
ステップ 4:Flink を使用した MySQL データの読み取りと DLF の Paimon テーブルへの書き込み
Flink コンソールにログインし、左上隅でリージョンを選択します。
対象のワークスペース名をクリックし、左側のナビゲーションウィンドウで を選択します。
[下書き] タブで、
 をクリックして新しいフォルダを作成します。
をクリックして新しいフォルダを作成します。フォルダを右クリックして、[新規空白ストリームドラフト]を選択します。[新規ドラフト] ダイアログボックスで、[名前]を入力し、[エンジンバージョン]を選択します。
ファイルに次の SQL ステートメントを記述して実行します。実際の環境に基づいてコード内の名前を変更してください。
CREATE TABLE IF NOT EXISTS `db_dlf25_oss`.`default`.`emp` WITH ( 'bucket' = '4', 'changelog-producer' = 'input' ) AS TABLE `mysql-catalog-dlf25`.`dlf25_paimon`.`emp`;(任意) 右上隅にある [検証] をクリックして、ジョブの Flink SQL 文の構文を検証します。
右上隅にある [デプロイ] をクリックします。[ドラフトのデプロイ] ダイアログボックスで、[コメント]、[ラベル]、[デプロイ先] を指定し、[確認] をクリックします。
対象のワークスペース名をクリックします。左側のナビゲーションウィンドウで、を選択します。
[デプロイメント] ページで、対象のジョブ名をクリックすると、その [設定] ページが開きます。
対象のジョブのデプロイメント詳細ページの右上隅で、[開始]をクリックし、[初期モード]を選択し、次に[開始]をクリックします。
Paimon データのクエリ
左側のナビゲーションウィンドウで、 を選択します。
[新規スクリプト] タブで、
 をクリックして新しいクエリスクリプトを作成できます。
をクリックして新しいクエリスクリプトを作成できます。SELECT * FROM `db_dlf25_oss`.`default`.`emp`;次の結果が返されます:
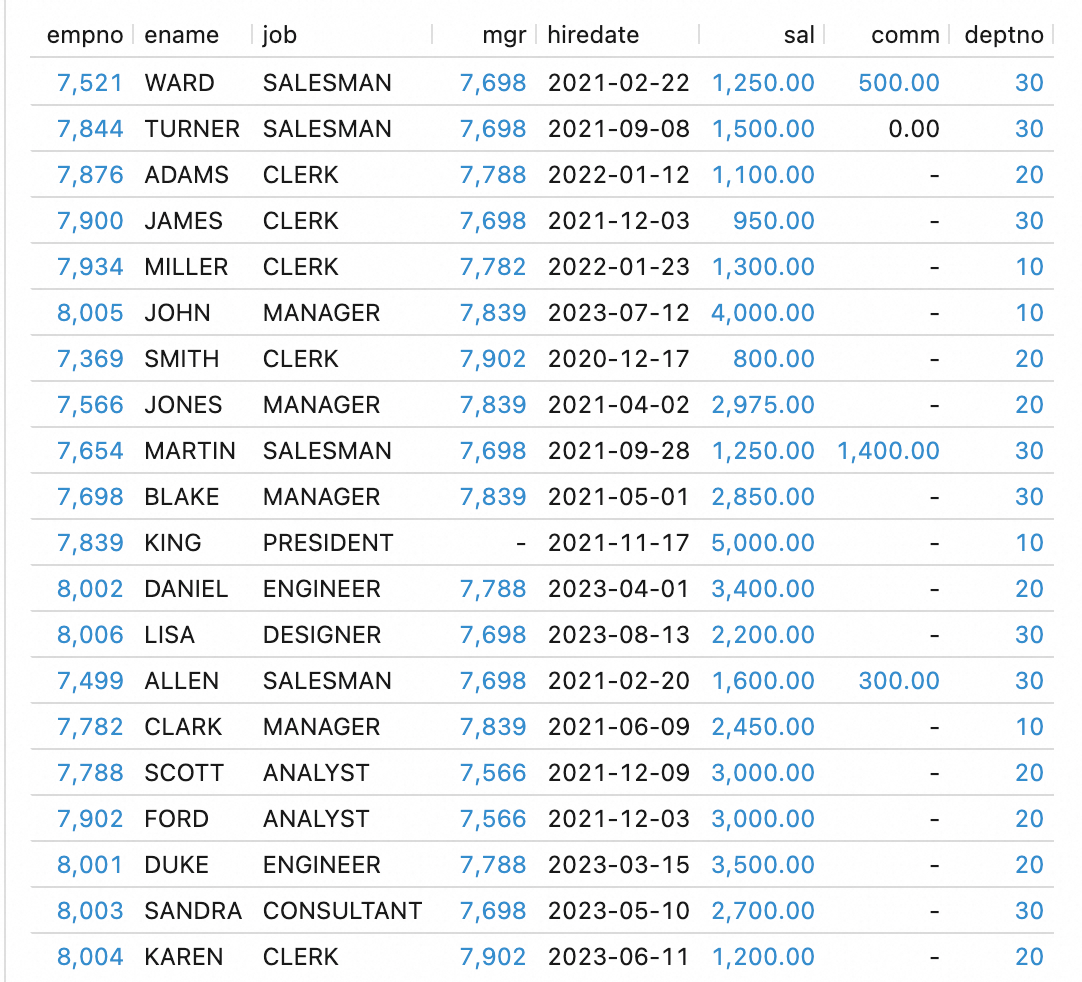
Data Lake Formation (DLF) コンソールにログインします。 を選択し、データカタログをクリックしてデータベースに移動し、同期されたテーブルの詳細を表示します。

ステップ 5:MaxCompute での Paimon_DLF 外部データソースの作成
MaxCompute コンソールにログインし、左上隅でリージョンを選択します。
左側のナビゲーションウィンドウで、 を選択します。
外部データソース ページで、外部データソースの作成 をクリックします。
外部データソースの追加 ダイアログボックスで、パラメーターを設定します。次の表にパラメーターを示します。
パラメーター
必須
説明
外部データソースタイプ
必須
[DLF+OSS] を選択します。
外部データソース名
必須
カスタム名。命名規則は次のとおりです:
名前は英字で始まり、小文字の英字、アンダースコア (_)、数字のみを含めることができます。
名前の長さは 128 文字を超えることはできません。
例:
mysql_paimon_dlf25。外部データソースの説明
任意
必要に応じて説明を入力します。
地理
必須
デフォルト値は現在のリージョンです。
DLF エンドポイント
必須
デフォルト値は現在のリージョンの DLF エンドポイントです。
OSS エンドポイント
必須
デフォルト値は現在のリージョンの OSS エンドポイントです。
RoleARN
必須
RAM ロールの Alibaba Cloud リソースネーム (ARN)。このロールには DLF と OSS の両方にアクセスする権限が必要です。
左側のナビゲーションウィンドウで、 を選択します。
[基本情報] セクションで、[Amazon リソースネーム (ARN)] を確認できます。
例:
acs:ram::124****:role/aliyunodpsdefaultrole。外部データソースの追加プロパティ
任意
外部データソースの特別な属性。指定すると、この外部データソースを使用するタスクは、定義された動作に従ってソースシステムにアクセスできます。
説明サポートされているパラメーターについては、公式ドキュメントをご参照ください。プロダクトの進化に伴い、より多くのパラメーターがサポートされる予定です。
[OK] をクリックして外部データソースを作成します。
外部データソース ページで、対象のデータソースを見つけ、操作 列の 詳細 をクリックします。
ステップ 6:MaxCompute での Paimon_DLF 外部プロジェクトの作成
MaxCompute コンソールにログインし、左上隅でリージョンを選択します。
左側のナビゲーションウィンドウで、 を選択します。
External Project タブで、新しいプロジェクト をクリックします。
新しいアイテム ダイアログボックスで、パラメーターを設定し、[確認] をクリックしてプロジェクトを作成します。
パラメーター
必須
説明
プロジェクトタイプ
必須
デフォルト値は外部プロジェクトです。
地理
必須
デフォルト値は現在のリージョンです。ここでは変更できません。
プロジェクト名 (ネットワーク全体で一意)
必須
名前は英字で始まり、英字、数字、アンダースコア (_) を含み、長さは 3~28 文字である必要があります。
MaxCompute外部データソース型
任意
デフォルト値は Paimon_DLF です。
MaxCompute外部データソース
任意
既存の選択:作成済みの外部データソースのリストが表示されます。
新しい外部データソース:新しい外部データソースを作成して使用します。
MaxCompute外部データソース名
必須
既存のものを選択:ドロップダウンリストから作成済みの外部データソースの名前を選択します。
外部データソースの作成:新しい外部データソースの名前が使用されます。
認証と認可
必須
タスクエグゼキュータの ID。サービスリンクロールが存在しない場合は、このモードを使用する前に作成する必要があります。
関連サービスの役割
必須
デフォルトで生成されます。
エンドポイント
必須
デフォルトで生成されます。
データディレクトリ
必須
DLF データカタログ。
コンピューティングリソース支払いタイプ
必須
年と月 または ボリュームで支払う。
デフォルトクォータ
必須
既存のクォータを選択します。
説明
任意
カスタムのプロジェクト説明。
ステップ 7:データの分析
接続ツールを使用して外部プロジェクトにログインします。
外部プロジェクト内のスキーマをリスト表示します。
-- セッションレベルでスキーマ構文を有効にします。 SET odps.namespace.schema=true; SHOW schemas; -- 次の結果が返されます。 ID = 20250919****am4qb default system OK外部プロジェクトのスキーマ内のテーブルをリスト表示します。
USE schema default; SHOW tables; -- 次の結果が返されます。 ID = 20250919****am4qb acs:ram::<uid>:root emp OKDLF の Paimon テーブルからデータを読み取ります。
SELECT * FROM emp; -- 次の結果が返されます。 +------------+------------+------------+------------+------------+------------+------------+------------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +------------+------------+------------+------------+------------+------------+------------+------------+ | 7521 | WARD | SALESMAN | 7698 | 2021-02-22 | 1250 | 500 | 30 | | 7844 | TURNER | SALESMAN | 7698 | 2021-09-08 | 1500 | 0 | 30 | | 7876 | ADAMS | CLERK | 7788 | 2022-01-12 | 1100 | NULL | 20 | | 7900 | JAMES | CLERK | 7698 | 2021-12-03 | 950 | NULL | 30 | | 7934 | MILLER | CLERK | 7782 | 2022-01-23 | 1300 | NULL | 10 | | 8005 | JOHN | MANAGER | 7839 | 2023-07-12 | 4000 | NULL | 10 | | 7369 | SMITH | CLERK | 7902 | 2020-12-17 | 800 | NULL | 20 | | 7566 | JONES | MANAGER | 7839 | 2021-04-02 | 2975 | NULL | 20 | | 7654 | MARTIN | SALESMAN | 7698 | 2021-09-28 | 1250 | 1400 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 2021-05-01 | 2850 | NULL | 30 | | 7839 | KING | PRESIDENT | NULL | 2021-11-17 | 5000 | NULL | 10 | | 8002 | DANIEL | ENGINEER | 7788 | 2023-04-01 | 3400 | NULL | 20 | | 8006 | LISA | DESIGNER | 7698 | 2023-08-13 | 2200 | NULL | 30 | | 7499 | ALLEN | SALESMAN | 7698 | 2021-02-20 | 1600 | 300 | 30 | | 7782 | CLARK | MANAGER | 7839 | 2021-06-09 | 2450 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 2021-12-09 | 3000 | NULL | 20 | | 7902 | FORD | ANALYST | 7566 | 2021-12-03 | 3000 | NULL | 20 | | 8001 | DUKE | ENGINEER | 7788 | 2023-03-15 | 3500 | NULL | 20 | | 8003 | SANDRA | CONSULTANT | 7698 | 2023-05-10 | 2700 | NULL | 30 | | 8004 | KAREN | CLERK | 7902 | 2023-06-11 | 1200 | NULL | 20 | +------------+------------+------------+------------+------------+------------+------------+------------+empテーブルをクエリして、各部門で給与が最も高い従業員と最も低い従業員の完全な情報を取得します。WITH ranked AS ( SELECT e.*, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC) AS rn_desc, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal ASC) AS rn_asc FROM emp e ) SELECT * FROM ranked WHERE rn_desc = 1 OR rn_asc = 1 ORDER BY deptno, sal DESC; -- 次の結果が返されます。 +-------+--------+-----------+------+------------+------+------+--------+------------+------------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | rn_desc | rn_asc | +-------+--------+-----------+------+------------+------+------+--------+------------+------------+ | 7839 | KING | PRESIDENT | NULL | 2021-11-17 | 5000 | NULL | 10 | 1 | 4 | | 7934 | MILLER | CLERK | 7782 | 2022-01-23 | 1300 | NULL | 10 | 4 | 1 | | 8001 | DUKE | ENGINEER | 7788 | 2023-03-15 | 3500 | NULL | 20 | 1 | 8 | | 7369 | SMITH | CLERK | 7902 | 2020-12-17 | 800 | NULL | 20 | 8 | 1 | | 7698 | BLAKE | MANAGER | 7839 | 2021-05-01 | 2850 | NULL | 30 | 1 | 8 | | 7900 | JAMES | CLERK | 7698 | 2021-12-03 | 950 | NULL | 30 | 8 | 1 | +-------+--------+-----------+------+------------+------+------+--------+------------+------------+
ステップ 8:分析結果の DLF への書き戻し
前のステップの外部プロジェクトで、SQL 分析結果を保存するためのテーブルを作成します。
CREATE TABLE emp_detail ( empno INT, ename VARCHAR(20), job VARCHAR(20), mgr INT, hiredate DATE, sal DECIMAL(10,2), comm DECIMAL(10,2), deptno INT );ステップ 7 の分析結果を新しいテーブルに書き込みます。
WITH ranked AS ( SELECT e.*, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC) AS rn_desc, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal ASC) AS rn_asc FROM emp e ) insert into emp_detail SELECT empno,ename,job,mgr, hiredate,sal,comm,deptno FROM ranked WHERE rn_desc = 1 OR rn_asc = 1 ORDER BY deptno, sal DESC;新しいテーブルをクエリします。
SELECT * FROM emp_detail; -- 次の結果が返されます。 +------------+------------+------------+------------+------------+------------+------------+------------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +------------+------------+------------+------------+------------+------------+------------+------------+ | 7839 | KING | PRESIDENT | NULL | 2021-11-17 | 5000 | NULL | 10 | | 7934 | MILLER | CLERK | 7782 | 2022-01-23 | 1300 | NULL | 10 | | 8001 | DUKE | ENGINEER | 7788 | 2023-03-15 | 3500 | NULL | 20 | | 7369 | SMITH | CLERK | 7902 | 2020-12-17 | 800 | NULL | 20 | | 7698 | BLAKE | MANAGER | 7839 | 2021-05-01 | 2850 | NULL | 30 | | 7900 | JAMES | CLERK | 7698 | 2021-12-03 | 950 | NULL | 30 | +------------+------------+------------+------------+------------+------------+------------+------------+Data Lake Formation (DLF) コンソールにログインします。左側のナビゲーションウィンドウで、Catalog List を選択します。新しく作成された
emp_detailテーブルが表示されます。