背景情報
生成 AI 技術は急速に普及しており、AI の発展トレンドを示し、中国の AI 産業を活性化しています。より多くの企業が、生成 AI を実際のビジネスシナリオに適用する方法に注目しています。生成 AI 技術は一般的なタスクでは優れたパフォーマンスを発揮しますが、垂直領域ではまだ正確な回答を提供できません。垂直領域における生成 AI の成功の鍵は、特定の知識に基づいて専用のエンタープライズ会話型ソリューションを構築し、制御可能な結果を生成することです。
Alibaba Cloud OpenSearch は、インテリジェント検索のためのワンストップ開発プラットフォームであり、高性能なベクトル検索機能を提供します。 ベクトル検索機能と大規模言語モデル(LLM)に基づいて、垂直領域向けの信頼性が高くインテリジェントな会話型検索ソリューションを構築し、実際のビジネスシナリオに適用できます。
このトピックでは、OpenSearch Vector Search Edition と LLM に基づいて、企業向けのインテリジェントな会話型検索システムを構築する方法について説明します。
専用のエンタープライズモデルベースのソリューション
1. 概要
OpenSearch Vector Search Edition と LLM に基づいて会話型検索ソリューションを構築するには、2 つのステップを実行する必要があります。最初のステップでは、ビジネスデータをベクトル化します。2 番目のステップでは、オンライン検索サービスを使用して必要なコンテンツを検索し、結果を返します。
1.1. ビジネスデータのベクトル化
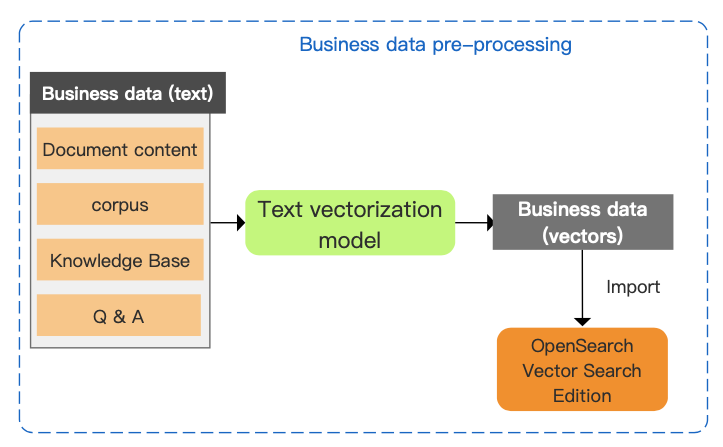
ビジネスデータをベクトル化し、ベクトルインデックスを構築する必要があります。
ステップ 1:TEXT 形式のビジネスデータをテキストベクトル化モデルにインポートし、ベクトル形式のビジネスデータを取得します。
ステップ 2:ベクトル形式のビジネスデータを OpenSearch Vector Search Edition にインポートし、ベクトルインデックスを構築します。
1.2. オンライン検索サービスを使用した検索の実行
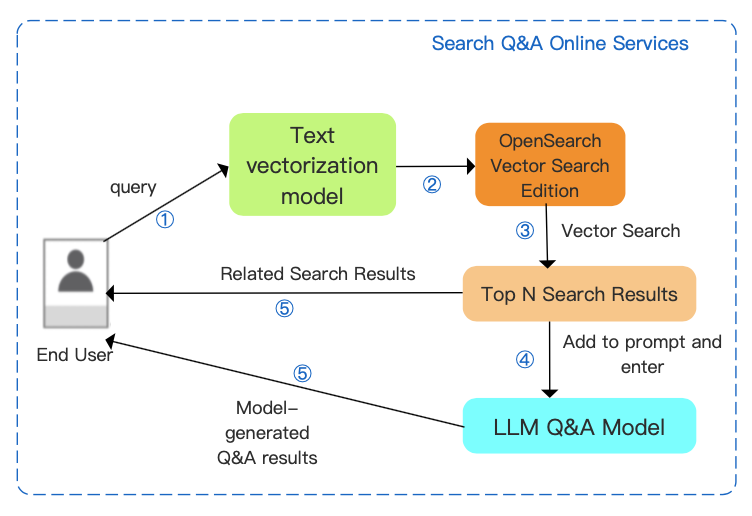
検索機能を実装すると、システムは上位 N 件の検索結果と LLM に基づいて回答を返すことができます。
ステップ 1:エンドユーザーのクエリをテキストベクトル化モデルにインポートし、ベクトル形式のクエリを取得します。
ステップ 2:ベクトル形式のクエリを OpenSearch Vector Search Edition にインポートします。
ステップ 3:OpenSearch Vector Search Edition の組み込みベクトル検索エンジンが、ビジネスデータから上位 N 件の検索結果を返します。
ステップ 4:上位 N 件の検索結果をプロンプトとして統合し、統合された LLM にインポートします。
ステップ 5:LLM によって生成された回答と、ベクトルに基づいて取得された検索結果をエンドユーザーに返します。
2. メリット
高性能:Alibaba Cloud が開発した高性能ベクトル検索エンジン
OpenSearch Vector Search Edition は、数百億件のデータレコードをミリ秒以内に取得し、データをリアルタイムで更新し、結果を数秒以内に表示できます。
OpenSearch Vector Search Edition の検索パフォーマンスは、オープンソースのベクトル検索エンジンの数倍です。高クエリ/秒(QPS)のシナリオでは、OpenSearch Vector Search Edition の取得率はオープンソースのベクトル検索エンジンよりも大幅に高くなっています。
中規模データシナリオにおける OpenSearch Vector Search Edition とオープンソースベクトル検索エンジンの比較
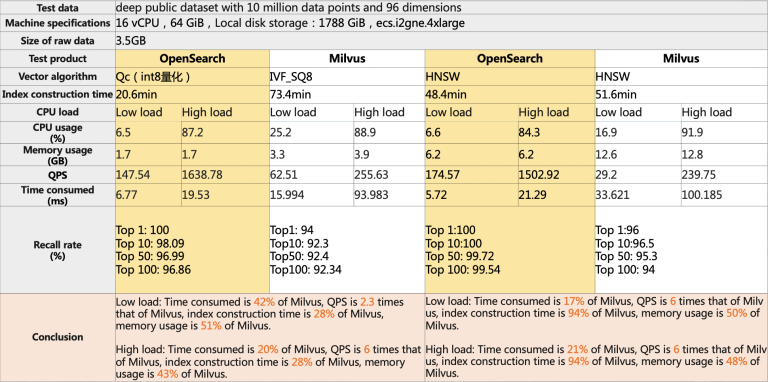
出典:Alibaba インテリジェントエンジンチーム、2022 年 11 月。
大規模データシナリオにおける OpenSearch Vector Search Edition とオープンソースベクトル検索エンジンの比較
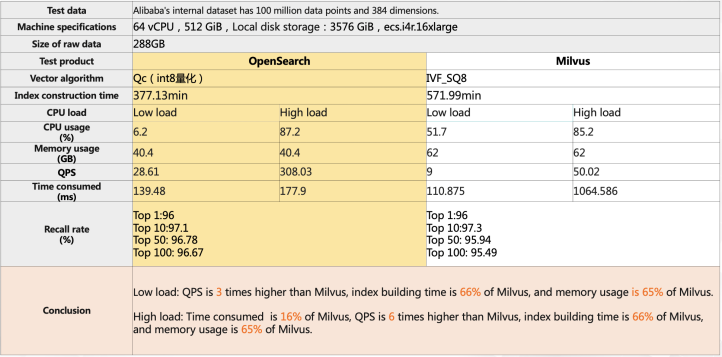
出典:Alibaba インテリジェントエンジンチーム、2022 年 11 月。
低コスト:ストレージコストとリソース消費を削減するための複数の方法
データ圧縮:OpenSearch Vector Search Edition は、生データを FLOAT データ型に変換して保存し、ZSTD などの効率的なアルゴリズムを使用してデータを圧縮できます。これにより、ストレージコストが削減されます。
きめ細かいインデックススキーマ設計:さまざまなインデックスのインデックスサイズを削減するための最適化戦略が提供されています。
部分インデックスの読み込み:mmap 読み込みポリシーを使用することで、インデックスをメモリにロックせずに読み込むことができ、メモリオーバーヘッドを効果的に削減できます。
フル機能のエンジン:オープンソースのベクトル検索エンジンと比較して、OpenSearch Vector Search Edition のエンジンはより小さいサイズのインデックスを構築でき、GPU リソースの消費量も少なくなります。同じデータ条件下では、OpenSearch Vector Search Edition はオープンソースのベクトル検索エンジンが占有するメモリの約 50% しか占有しません。
柔軟性:企業向けのインテリジェントな会話型検索システムを柔軟かつ迅速に構築
安定性と信頼性:システムは公開データではなくビジネスデータを使用してコンテンツを生成します。出力結果はより安定して信頼性があります。
アップグレードされたインタラクション:システムは検索と Q&A の要件を満たすことができます。エンドユーザーは、従来の方法ではなく会話形式でコンテンツを検索できます。
手順
1. OpenSearch Vector Search Edition インスタンスを購入する
詳細については、「一般的なシナリオの開始方法」をご参照ください。後で使用するために、指定されたユーザー名とパスワードを記録する必要があります。
2. OpenSearch Vector Search Edition インスタンスを構成する
購入したインスタンスの詳細ページで、インスタンスが「構成保留中」状態であり、インスタンスに対して空のクラスタが自動的にデプロイされていることを確認できます。 クラスタ内のクエリ結果サーチャー(QRS)ワーカーとサーチャーワーカーの数と仕様は、インスタンスの購入時に指定したものです。 検索サービスを使用する前に、データソースとインデックススキーマを構成し、クラスタのインデックスを再構築する必要があります。

2.1 API データソースを構成します。
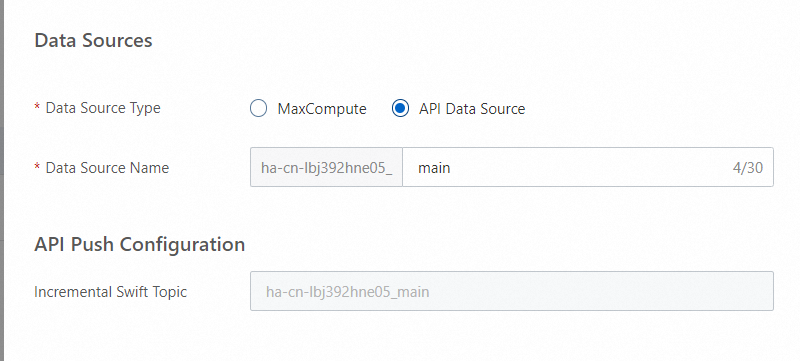
データソースが構成された後、[次へ] をクリックしてインデックススキーマを構成します。

2.2 インデックステーブルを追加します。

2.3 作成したデータソースを選択し、インデックステーブルを構成します。「テンプレートを選択」で「共通テンプレート」を選択します。

2.4 フィールドを構成します。少なくともプライマリキーフィールドとベクトルフィールドを定義する必要があります。ベクトルフィールドは複数値 FLOAT 型である必要があります。
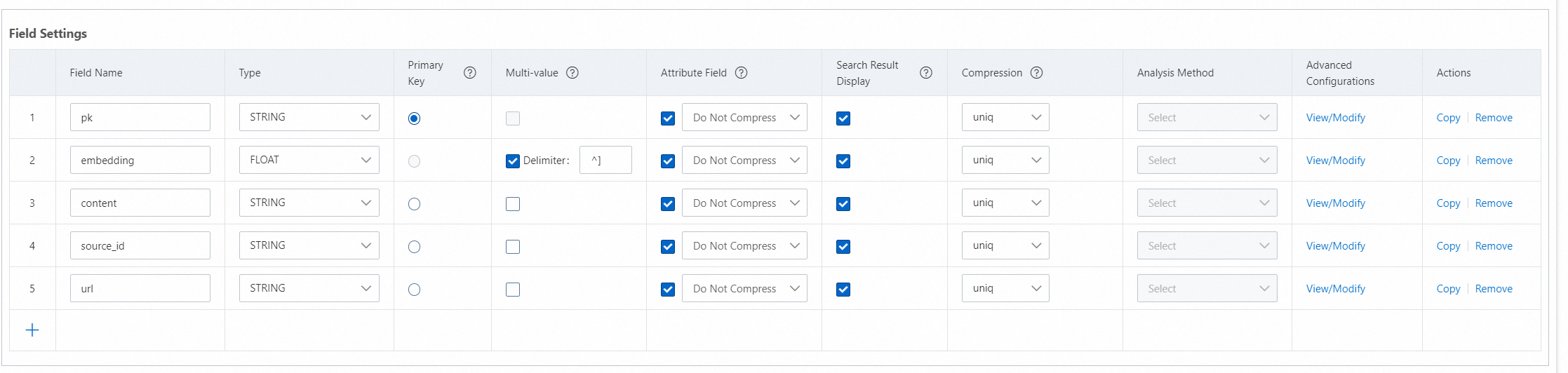
注:上記の図に基づいてフィールド名と型を構成する必要があります。そうしないと、データは自動的にプッシュされません。
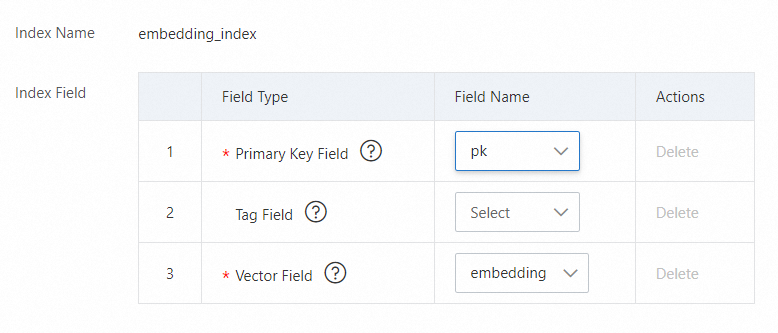
2.5 プライマリキー フィールドの Type パラメーターを PRIMARYKEY64 に設定します。ベクター フィールドの Type パラメーターを CUSTOMIZED に設定します。

注:ベクトルインデックスの名前は embedding_index である必要があります。
ベクトルフィールドにフィールドを追加します。
2.6 ベクトルインデックスの高度な設定を構成します。次の図に示すパラメータ設定を参照して、ベクトルインデックスを構成できます。詳細については、「ベクトルインデックス」をご参照ください。
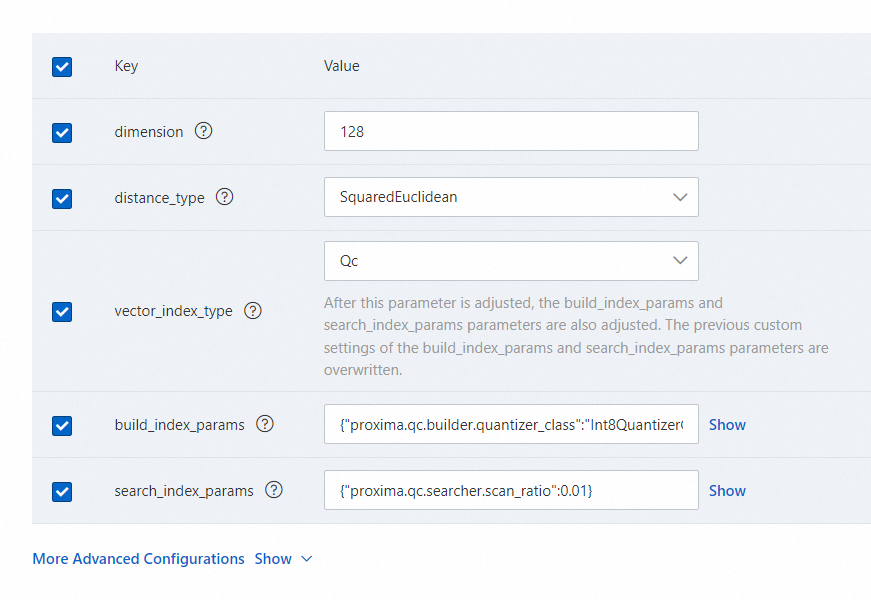
使用するベクトルモデルに基づいて dimension パラメータを構成します。この例では、text-embedding-ada-002 LLM を使用し、dimension パラメータを 1536 に設定し、enable_rt_build パラメータを true に設定します。これにより、OpenSearch はリアルタイムでインデックスを構築できます。
2.7 前の手順を実行した後、[保存版] をクリックします。表示されるダイアログボックスで、ビジネス要件に基づいて [説明] パラメーターを構成します。次に、[公開] をクリックします。
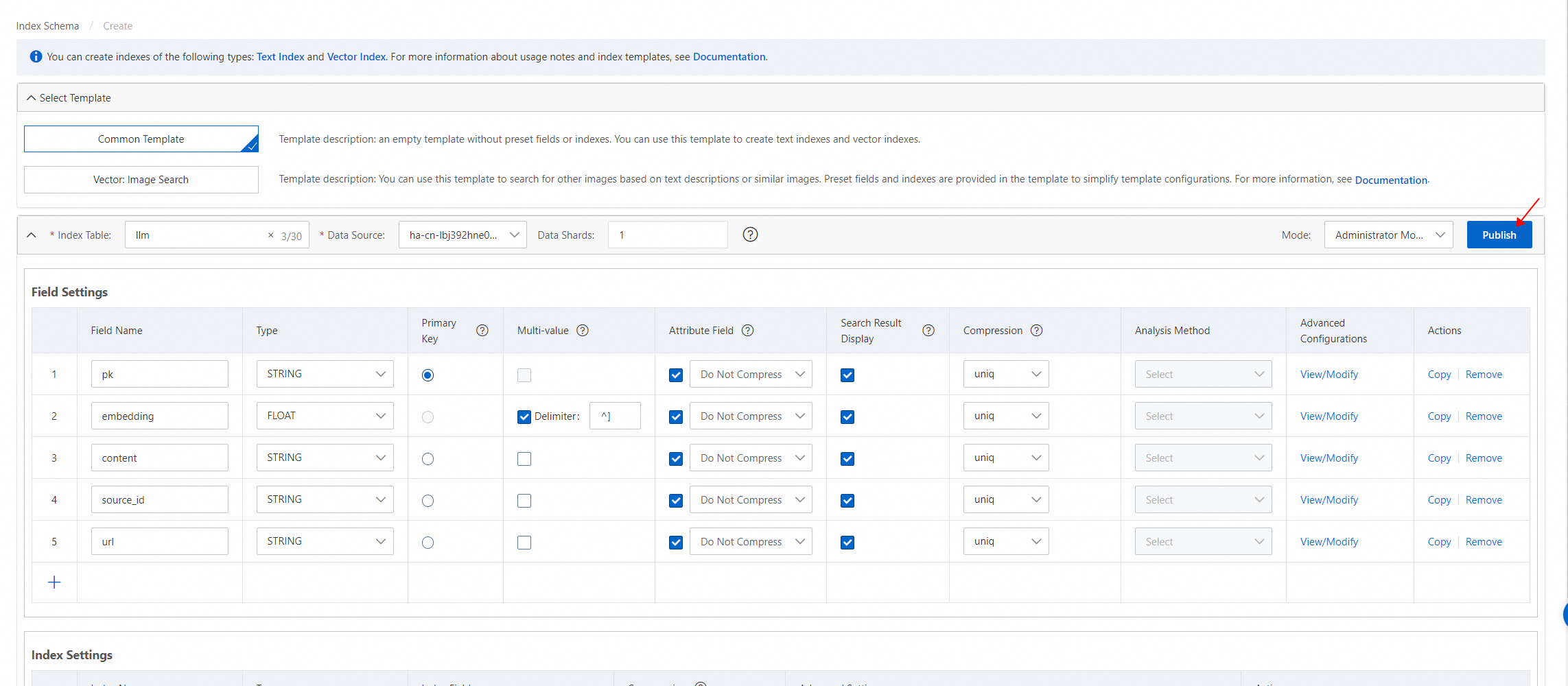
インデックスが公開されたら、[次へ] をクリックしてインデックスを再構築します。

2.8 インデックスの再構築に必要なパラメータを構成します。次に、[次へ] をクリックします。
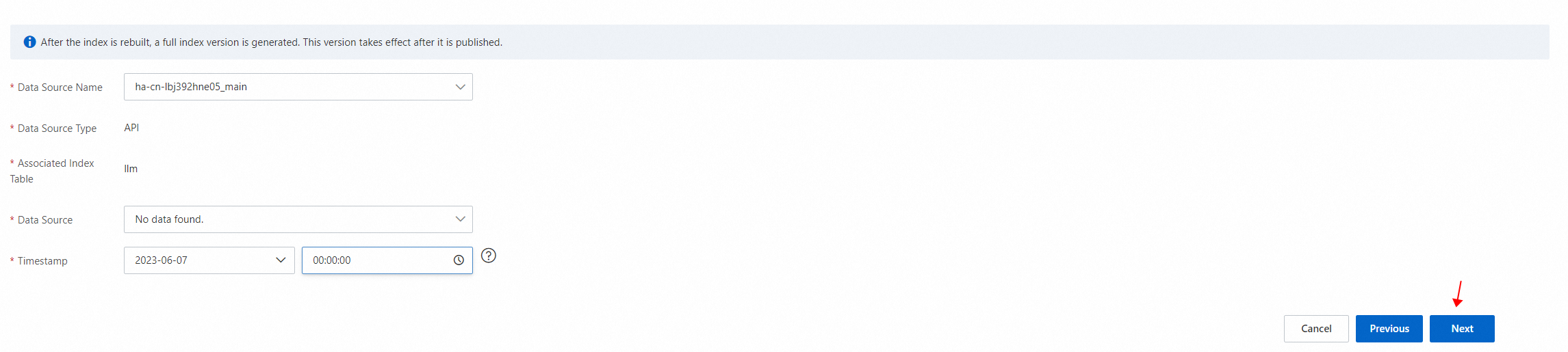
2.9 左側のナビゲーションウィンドウで、[O&M センター] > [変更履歴] を選択します。表示されるページで、O&M センター > 変更履歴 タブをクリックします。表示されるページで再構築の進捗状況を確認できます。インデックスが再構築されたら、クエリテストを実行できます。
3. OpenSearch Vector Search Edition と LLM に基づく検索サービスの構築
3.1 OpenSearch-LLM をダウンロードし、モデルを llm ディレクトリに解凍します。
3.2 llm ディレクトリの .env ファイルで、チャットに関連するパラメータを構成します。パラメータを構成する前に、チャットサービスを購入する必要があります。
チャットを使用する
LLM_NAME=OpenAI
OPENAI_API_KEY=***
OPENAI_API_BASE=***
OPENAI_EMBEDDING_ENGINE=text-embedding-ada-002
OPENAI_CHAT_ENGINE=gpt-3.5-turbo
VECTOR_STORE=OpenSearch
# OpenSearch 情報
OPENSEARCH_ENDPOINT=ha-cn-wwo38nf8q01.ha.aliyuncs.com
OPENSEARCH_INSTANCE_ID=ha-cn-wwo38nf8q01
OPENSEARCH_TABLE_NAME=llm
OPENSEARCH_DATA_SOURCE=ha-cn-wwo38nf8q01_data
OPENSEARCH_USER_NAME=opensearch # OpenSearch Vector Search Edition インスタンスの購入時に指定したユーザー名。
OPENSEARCH_PASSWORD=chat001 # OpenSearch Vector Search Edition インスタンスの購入時に指定したパスワード。Azure OpenAI を使用する
LLM_NAME=OpenAI
OPENAI_API_KEY=***
OPENAI_API_BASE=***
OPENAI_API_VERSION=2023-03-15-preview
OPENAI_API_TYPE=azure
# Azure での OpenAI モデルのデプロイを指定します。
OPENAI_EMBEDDING_ENGINE=embedding_deployment_id
OPENAI_CHAT_ENGINE=chat_deployment_id
VECTOR_STORE=OpenSearch
# OpenSearch 情報
OPENSEARCH_ENDPOINT=ha-cn-wwo38nf8q01.ha.aliyuncs.com
OPENSEARCH_INSTANCE_ID=ha-cn-wwo38nf8q01
OPENSEARCH_TABLE_NAME=llm
OPENSEARCH_DATA_SOURCE=ha-cn-wwo38nf8q01_data
OPENSEARCH_USER_NAME=opensearch # OpenSearch Vector Search Edition インスタンスの購入時に指定したユーザー名。
OPENSEARCH_PASSWORD=chat001 # OpenSearch Vector Search Edition インスタンスの購入時に指定したパスワード。注:
購入した OpenSearch Vector Search Edition インスタンスに基づいて、OpenSearch に関連するパラメータを指定する必要があります。
OPENSEARCH_ENDPOINT パラメータは、インターネット経由で OpenSearch Vector Search Edition インスタンスにアクセスするために使用するエンドポイントを指定します。インスタンスにアクセスするために使用する IP アドレスを、インスタンスの IP アドレスホワイトリスト に追加する必要があります。 OPENSEARCH_ENDPOINT パラメータの値には、 http:// プレフィックスを含めることはできません。
3.3 データの処理とプッシュ
llm ディレクトリの embed_files.py スクリプトを使用して、データファイルを処理します。Markdown ファイルと PDF ファイルのみがサポートされています。ファイルが処理されると、上記の OpenSearch Vector Search Edition インスタンスにプッシュされます。次の例では、${doc_dir} ディレクトリ内のファイルが処理されて ha-cn-wwo38nf8q01 インスタンスにプッシュされ、インデックスが自動的に構築されます。
python -m script.embed_files -f ${doc_dir}-f パラメータを構成して、処理するファイルが配置されているディレクトリを指定できます。
3.4 インテリジェントな会話型サービスを開始します。
cd ~/llm
python api_demo.py3.5 curl コマンドを使用してサービスをテストします。
次のコマンドを実行してテストクエリを送信します。
curl -H "Content-Type: application/json" http://127.0.0.1:8000/chat -d '{"query": "OpenSearch について紹介してください。"}'返された結果:
{
"success": true,
"result": "OpenSearch は、Alibaba によって開発された分散検索エンジンです。 OpenSearch は、大規模データの保存、処理、分析に使用でき、高可用性、スケーラビリティ、パフォーマンスを備えています。",
"prompt": "Human: 検索結果に基づいて質問に答えてください。 検索結果:OpenSearch は、Alibaba によって開発された分散検索エンジンです。 OpenSearch は SQL クエリ文をサポートし、組み込みのユーザー定義関数(UDF)を提供します。 OpenSearch では、プラグイン形式で独自の UDF を開発することもできます。 OpenSearch は、大規模データの保存、処理、分析に使用でき、高可用性、スケーラビリティ、パフォーマンスを備えています。 分散 O&M ツールを使用して OpenSearch をデプロイできます。物理マシンに分散クラスタをデプロイしたり、クラウドネイティブアーキテクチャを使用してクラウドプラットフォームに OpenSearch をデプロイしたりできます。 \n\n 上記の情報に基づいて、簡潔かつ専門的に質問に答えてください。答えがわからない場合は、「わかりません」と返してください。偽の答えを作成しないでください。 \n クエリ:OpenSearch について紹介してください。 Assistant: "
}4. 参照プロンプト
{
"prompt": "Human: 検索結果に基づいて質問に答えてください。 検索結果:OpenSearch Industry Algorithm Edition と OpenSearch High-performance Search Edition の比較:概要:OpenSearch は、Alibaba Cloud が独自に開発した大規模分散検索エンジンに基づくワンストップインテリジェント検索開発プラットフォームです。大規模データシナリオでは、OpenSearch は数百億件のデータをミリ秒以内に取得できます。 OpenSearch は、注文、物流、保険などの複数のシナリオの検索ソリューションを提供できます。 OpenSearch は、サービスとしてのソフトウェア(SaaS)プラットフォームです。 OpenSearch コンソールまたは API 操作を使用してシステムと対話できます。 アプリケーションインスタンスを作成することで、シナリオを簡単に構成できます。データソース、フィールド構造、検索属性を構成したら、OpenSearch SDK または OpenSearch コンソールを使用して検索テストを実行できます。大規模データ検索に関して、OpenSearch High-performance Search Edition は複雑な業界アルゴリズム機能を削除し、OpenSearch Industry Algorithm Edition と比較して一般的な検索機能をサポートしています。一般的な検索機能は、アナライザとソート機能に基づいています。 OpenSearch High-performance Search Edition は、ビジネスクエリと書き込みのスループットに重点を置いています。これにより、OpenSearch は数秒以内に応答でき、大規模データ検索シナリオでデータをリアルタイムでクエリできます。 OpenSearch は高いスループットを提供します。単一のテーブルは 1 万件の書き込みトランザクション/秒(TPS)をサポートし、数秒以内に更新できます。 OpenSearch は、チケットと電話を使用してサービスの安定性とセキュリティを確保するために、24 時間 365 日のサポートを提供しています。 OpenSearch は、障害監視、自動アラート、迅速なトラブルシューティング、迅速な回復など、包括的な障害および緊急対応メカニズムを提供します。 Alibaba Cloud は、ユーザーに AccessKey ID と AccessKey シークレットを割り当てて、OpenSearch の権限を制御します。これにより、異なるユーザーのデータを分離することでデータセキュリティが確保されます。 OpenSearch は、冗長データとバックアップデータを使用してデータ損失を防ぎます。 クエリ:OpenSearch には何エディションありますか? Assistant: ",
}デモ

まとめと展望
このトピックでは、OpenSearch Vector Search Edition と LLM を使用して企業固有の会話型検索システムを構築する方法について説明しました。検索ソリューションの詳細については、OpenSearch 製品ページをご覧ください。
今後、OpenSearch は会話型検索のエディションをリリースする予定です。さらに、ワンストップトレーニングを使用する SaaS ベースの企業固有の LLM を使用して、インテリジェントな会話型検索システムを構築できるようになります。
このソリューションで使用されているオープンソースのベクトルモデルと LLM はサードパーティモデルです。Alibaba Cloud は、サードパーティモデルのコンプライアンスと正確性を保証するものではなく、サードパーティモデル、またはサードパーティモデルを使用するお客様の行動と結果について一切の責任を負いません。したがって、サードパーティモデルにアクセスしたり使用したりする前に、注意して進めてください。さらに、サードパーティモデルには「オープンソースライセンス」や「ライセンス」などの契約が付属しているため、これらの契約の条項をよく読んで厳守する必要があります。